- The paper introduces DiCLIP, which integrates diffusion models with CLIP to overcome limitations in dense feature localization for weakly supervised semantic segmentation.
- It presents Visual Correlation Enhancement (VCE) and Text Semantic Augmentation (TSA) modules that work with a cache-based retrieval system to generate precise CAMs.
- Experiments on VOC 2012 and MS COCO demonstrate significant mIoU improvements, reduced training costs, and superior mask accuracy compared to prior methods.
DiCLIP: Leveraging Diffusion Models to Enhance CLIP’s Dense Representations for Weakly Supervised Semantic Segmentation
Introduction
Weakly supervised semantic segmentation (WSSS) with only image-level annotations presents significant challenges in dense prediction, primarily due to the lack of pixel-level supervision. Class Activation Maps (CAMs) have traditionally been leveraged to bridge this supervision gap, but their accuracy is often restricted by the limited granularity of global image-level features. Recently, CLIP, trained on extensive vision-language paired data, has been adapted for WSSS through patch-text alignment; however, its inherent global supervision limits fine localization capabilities. The "DiCLIP: Diffusion Model Enhances CLIP's Dense Knowledge for Weakly Supervised Semantic Segmentation" (2605.04593) addresses this bottleneck by integrating Stable Diffusion (SD), a powerful generative model, to enrich CLIP’s dense knowledge at both the visual and textual representation levels. DiCLIP proposes Visual Correlation Enhancement (VCE) and Text Semantic Augmentation (TSA) modules, fundamentally reformulating CAM generation in WSSS by aligning CLIP’s representations with strong spatial and semantic priors from diffusion models.
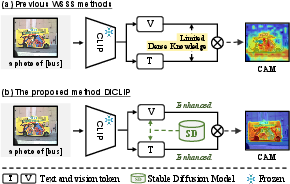
Figure 1: Motivation for DiCLIP: Compared to previous CLIP-based WSSS methods limited in dense understanding, DiCLIP harnesses Stable Diffusion to supply fine-grained dense knowledge in both vision and text modalities, resulting in more comprehensive and accurate CAMs.
DiCLIP Framework Overview
DiCLIP is structured around two synergistic modules—VCE for visual feature enhancement and TSA for semantic augmentation of text representations—coupled with a visual key-value cache model that supports both training-free and training-efficient dense knowledge retrieval paradigms.
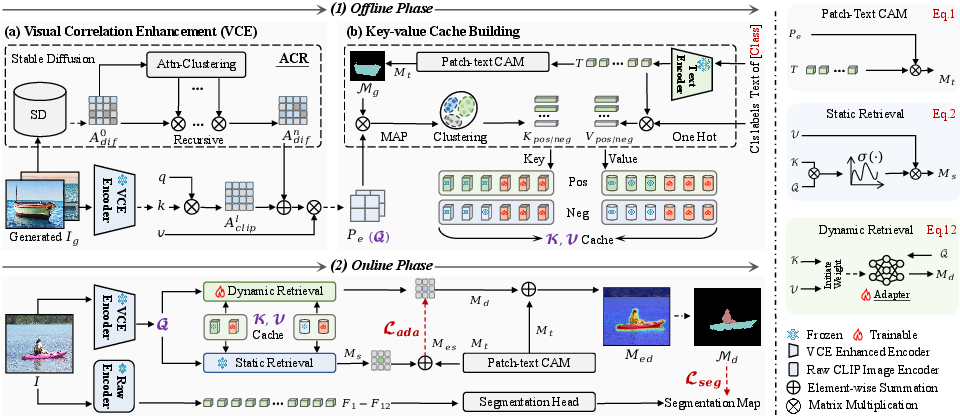
Figure 2: Framework of DiCLIP showing the offline/online phases, VCE and TSA modules, and the cache-based knowledge retrieval for efficient and effective CAM generation.
- Offline phase: SD-generated or real images are processed through SD’s UNet to extract self-attention maps, which are recursively refined using the Attention Clustering Refinement (ACR) module. The resulting spatial priors are injected into CLIP’s intermediate attention layers, forming the VCE encoder for enhanced visual feature extraction. These features, along with text embeddings, produce patch-text CAMs, which are used to generate pseudo-label masks. These, in turn, are used to build the key-value cache for dense knowledge retrieval.
- Online phase: The VCE-enhanced encoder and the cache model are used for static and dynamic dense retrieval, refining CLIP’s patch-text alignment. A learnable adapter is trained using the cache’s priors, supporting efficient, dynamic knowledge retrieval for robust CAM and segmentation mask generation.
Visual Correlation Enhancement: Addressing CLIP’s Attention Limitations
Although CLIP employs transformers for vision understanding, its attention maps (due to training objectives focused on image-text matching) are overly smoothed and lack local, semantically variant structure critical for dense prediction.

Figure 3: CLIP produces excessively smoothed attention; SD generates sharper, spatially diverse attention maps more conducive to fine-grained localization.
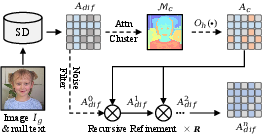
Figure 4: The ACR module clusters SD’s attention maps, propagating reliable semantic affinities for progressive refinement of spatial priors.
In DiCLIP, SD’s UNet-based attention—rich in spatial coherence due to denoising objectives—is extracted and recursively clustered (ACR) to suppress noise and amplify consistent semantics. By fusing these with CLIP’s own attention via an additive strategy, DiCLIP achieves diversified, spatially finer attention distributions, enabling robust patch-level feature representation.
Text Semantic Augmentation and Visual Key-Value Cache
CAM generation from pure patch-text matching is suboptimal due to insufficient semantic diversity in text categories and CLIP’s training bias. DiCLIP circumvents this with a cache model constructed from SD-generated single-category images: visual embeddings are mapped as keys, and text embeddings govern value assignment, capturing intra/inter-class variance and supporting both static and learnable (dynamic) retrieval.
Key strategies include:
- Generating synthetic foreground/background prototypes for every class by masking and clustering attention to build the cache keys.
- Using text-weighted one-hot vectors as cache values, enabling fine-grained semantic differentiation.
- Integrating a learnable adapter (MLP) initialized with these cache priors to promote dynamic adaptation during segmentation.
This dual-branch cache model supports high-quality CAM generation even without additional training and delivers further gains when fine-tuned.
VOC 2012 and MS COCO 2014 experiments reveal that DiCLIP establishes new state-of-the-art accuracy under both image-level and vision-language supervision regimes:
- On VOC12 val, DiCLIP achieves 78.8% mIoU, surpassing WeCLIP and POT by 2.4% and 2.7% respectively.
- On COCO14 val, DiCLIP outperforms leading baselines by a substantial margin.
DiCLIP is notably competitive both in training-free (static) and training-efficient (dynamic adapter) modes, setting a strong precedent for cache-augmented weak supervision.

Figure 5: DiCLIP generates more accurate and complete segmentation masks than prior SOTA CLIP-based and transformer-based methods on VOC 2012.

Figure 6: On COCO 2014, DiCLIP better localizes challenging and co-occurring categories, especially for small and ambiguous objects.
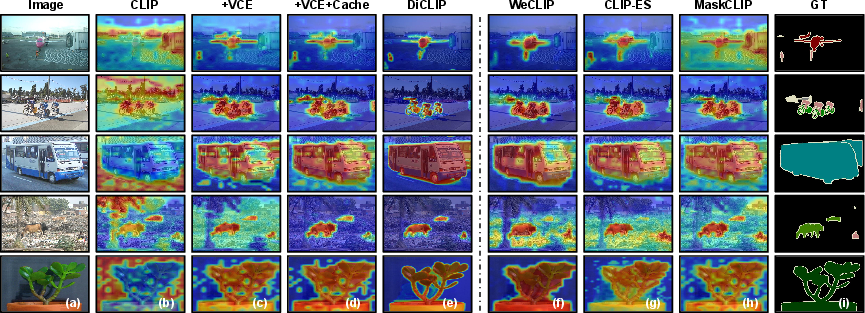
Figure 7: CAM visualizations reveal that DiCLIP’s VCE and TSA modules significantly improve mask completeness and focus, where baselines often fail.
Qualitative evaluation demonstrates superior localization, especially for small or off-center objects, and in regions with category co-occurrence where competing methods’ confusion ratios increase but DiCLIP remains stable (Figure 8).
Efficiency: DiCLIP drastically reduces training cost (GPU time/memory) compared to multi-stage and single-stage SOTAs and converges faster (Figure 9).
Component Analysis and Ablations
Ablation studies show that every module—VCE, key-value cache, ACR refinement, adapter learning—contributes notably to final segmentation quality. The fusion of SD attention via ACR outperforms normalization, scaling, or hard gating approaches for biasing CLIP’s attention distributions (Figure 10 and Table 12).
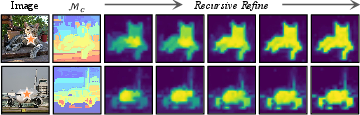
Figure 11: Progressive ACR refinement on SD attention maps enhances spatial reliability over iterations.
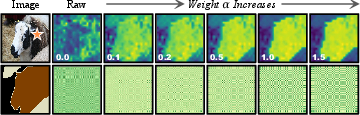
Figure 10: Higher α amplifies the corrective impact of SD attention, with optimal performance for intermediate fusion values.

Figure 12: Applying ACR to SD’s (not CLIP’s) attention is crucial due to SD’s inherent spatial diversity, as reflected in both qualitative attention maps and quantitative CAM quality.
Cache model design: Using semantically pure synthetic prototypes (Figure 13) aligns cache feature distributions closely with those from real images, mitigating model/genre bias. The adapter’s initialization with cache priors is instrumental for fast and reliable convergence.
Theoretical and Practical Implications
DiCLIP redefines the prevailing paradigm in WSSS:
- Theoretical: Demonstrates that combining diffusion-based spatial priors with patch-level CLIP representations overcomes the latter’s dense prediction deficiencies, and that dense, cache-based knowledge retrieval can unify semantic and spatial precision in low-supervision segmentation.
- Practical: Provides an efficient, rapidly converging method with modest hardware requirements and high performance in domains with limited dense annotations or in complex, co-occurrence-heavy scenes.
The methodology naturally generalizes across SD versions and is robust to the number of synthetic cache samples, supporting extensibility to new categories and datasets.
Limitations and Future Directions
While DiCLIP’s reliance on SD-generated cache prototypes facilitates broad coverage, it inherits biases from synthetic data; categories inadequately modeled by SD may experience degraded mask fidelity. The current offline cache could be improved by dynamically updating with representative real data during training, or through online adaptation during inference. Future research directions include the development of online, in-domain cache augmentation strategies and deeper integration of generative priors for even more data-efficient dense prediction.
Conclusion
DiCLIP presents a robust, scalable approach for WSSS, systematically enhancing CLIP’s dense representational capacity through SD-based visual spatial priors and cache-driven semantic augmentation. By marrying the generative strengths of diffusion models with the cross-modal prowess of CLIP and unifying them in a retrieval-based CAM generation paradigm, DiCLIP achieves superior weakly supervised segmentation—advancing both the theory and practice of dense prediction under minimal annotation.
(2605.04593)