- The paper introduces Budgeted LoRA, a distillation method that reallocates computation structurally for efficient inference.
- It utilizes a budget parameter F to dynamically control module-level dense retention, adaptive low-rank allocation, and post-training compression.
- Experiments reveal significant inference speedups and robust in-context learning retention compared to standard KD LoRA approaches.
Budgeted LoRA: Distillation as Structured Compute Allocation for Efficient Inference
Introduction
The paper "Budgeted LoRA: Distillation as Structured Compute Allocation for Efficient Inference" (2605.04341) interrogates the limitations of current parameter-efficient distillation, particularly LoRA-based approaches, in the context of compute-constrained LLM deployment. Standard LoRA reduces adaptation costs but retains the full inference cost of the dense backbone, failing to yield true structural efficiency post-distillation. The central thesis of this work is that distillation should be approached as a structured compute allocation problem, explicitly optimizing both dense and low-rank pathway usage under a hard global compute budget.
Methodology: Budgeted LoRA
Budgeted LoRA introduces a distillation paradigm where a global dense-compute budget, defined by a user-specified fraction F∈[0,1], orchestrates the redistribution of computation across the model’s projection modules.
Three distinct mechanisms are combined:
- Module-level dense retention: Each linear projection module (e.g., attention Q/K/V/O, MLP up/gate/down) is assigned a learned coefficient d∈[0,1] determining the fraction of dense computation retained.
- Adaptive low-rank allocation: LoRA updates are parameterized with dynamic per-rank gates, allowing the effective rank to vary per module, coupling low-rank adaptation capacity with the dense pathway’s reduction.
- Post-training compression: After distillation, inference cost is reduced by thresholding LoRA ranks, removing or SVD-approximating weakly retained dense modules, and retaining only highly utilized dense components.
This process yields a family of students of fixed depth but variable efficiency, parameterized by the single budget parameter F, which directly translates into a post-compression cost-quality trade-off.
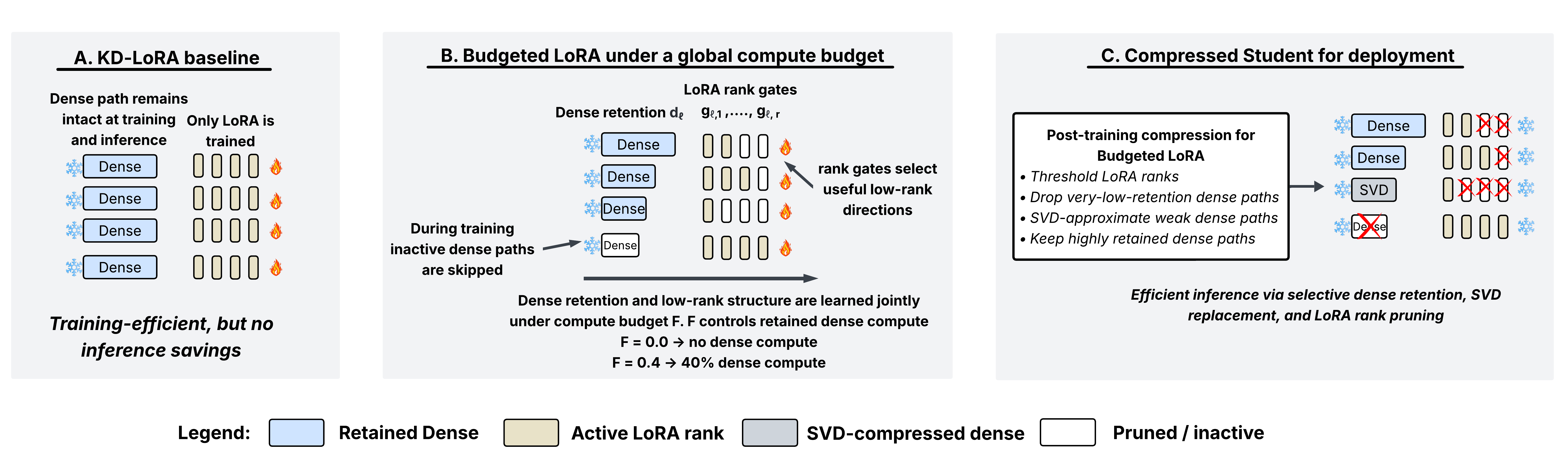
Figure 1: Schematic of the Budgeted LoRA pipeline—contrast between standard KD-LoRA, budgeted fusion and gating during distillation, and post-training structural consolidation for efficient deployment.
Experimental Setup
Experiments employ Mistral-style Transformer architectures from the Bi-Induct model family across three teacher scales (0.13B, 0.5B, 1B parameters), with students always fixed as 6-layer models (initialized via a mixed layer selection from a 12-layer 0.13B checkpoint). Distillation is performed with tightly controlled setups: all use the same corpus (The Pile), identical tokenization, held-out splits, and token budgets (2.55B tokens, sequence length 1024).
Baseline comparisons include:
- KD Full: Classical distillation with all student parameters trainable.
- KD LoRA: LoRA-based distillation on all linear projections, with a fixed rank.
- Budgeted LoRA: The proposed method with two different dense budgets (F=0.4, F=0.0).
Evaluation comprises language modeling perplexity and a battery of 19 function-style in-context learning (ICL) probes derived from the Function Vectors framework.
Results and Analysis
Quality-Efficiency Frontier
Budgeted LoRA delivers strong control over the quality-efficiency frontier. Setting the dense compute budget to F=0.4 achieves equivalent perplexity to classical KD LoRA, but with a 1.74× compressed-module inference speedup and significant training compute reduction. With F=0.0, the compressed inference speedup increases to 4.05×, incurring only moderate perplexity degradation.
Contrary to uniform dense removal methods (e.g., PC-LoRA), the budget dial enables continuous navigation between dense and low-rank deployment, outperforming fixed-architecture LoRA baselines in both flexibility and realized deployment efficiency.
In-Context Learning Retention
ICL probe performance demonstrates that probe accuracy is decoupled from perplexity in LoRA-constrained settings. While plain KD LoRA fails to capitalize on stronger, larger teachers (accuracy degrades with increasing teacher size), Budgeted LoRA recovers higher ICL-probe retention as teacher scale increases, mirroring full-parameter KD’s scaling trend.
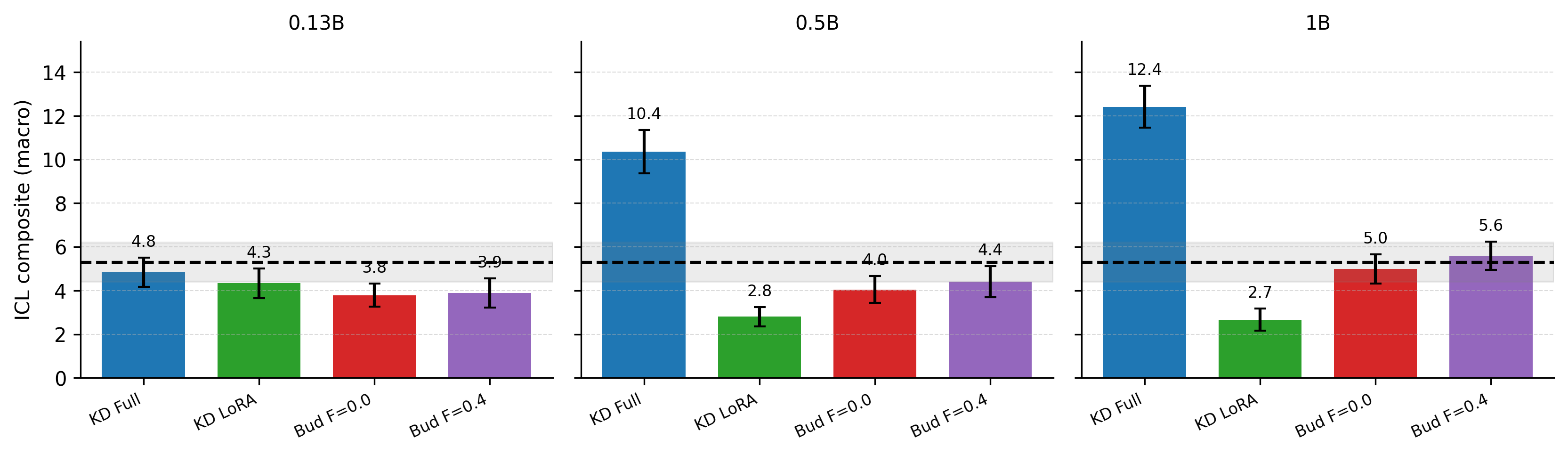
Figure 2: Macro-averaged ICL probe composite scores across teacher scales and budget settings. Budgeted LoRA achieves substantially higher probe retention than standard KD LoRA, particularly with large teacher models.
These results are consistent across probe families (selection, transformation, symbolic reasoning) and highlight that structure-preserving compression is essential for retaining behaviors related to contextual and compositional generalization.
Post-Training Compression and Emergent Behavior
Detailed analysis reveals coordinated adaptation:
- At aggressive budgets (F=0.0), dense modules are removed entirely post-training; LoRA effective rank remains maximized.
- At intermediate budgets (F=0.4), a subset of dense modules is retained while LoRA capacity remains high.
- At relaxed budgets (F=0.8), both SVD compression of weak dense modules and adaptive reduction in LoRA rank emerge, reflecting optimal capacity allocation under the budget.
No hyperparameter retuning is required across budgets—compression strategies self-organize from the global schedule.
Implications and Future Directions
Budgeted LoRA reframes LLM distillation as modular compute allocation, where post-training deployment efficiency is a direct product of training-time structured control. This is a substantial shift from parameter-count or naive modular pruning arguments toward a capacity-centric, inference-aware distillation regime. Practically, this method enables:
- Deployment of compact students with Pareto-optimal cost-quality trade-offs, critical for edge and resource-constrained inference.
- Budget-scheduled training, yielding smooth transfer of capacity to low-rank pathways for robust distillation under pruning.
- Behavioral robustness in ICL and algorithmic probe benchmarks, indicating that high-level reasoning abilities require retention of structural organization not accessible by pure LoRA or unstructured pruning.
Three important speculations arise:
- Transfer to large-scale LLMs: The method should generalize, though practice at scale will necessitate refinement of controller heuristics and efficient hardware-aware compression.
- AutoML and budget scheduling: Budgeted LoRA provides natural hooks for automatic quality-resource navigation, directly informing neural architecture search and deployment pipelines.
- Mechanistic interpretability: The smooth compute-transfer enabled by the budget schedule presents an opportunity to analyze the migration of circuits and ICL mechanisms from dense to low-rank parameterizations, with implications for mechanistic understanding of model behavior under compression.
Conclusion
Budgeted LoRA implements distillation as explicit, structured compute reallocation, operating at both the design and compression phase. It achieves strong, controllable quality-efficiency trade-offs, closes key behavioral gaps in ICL probe retention, and moves the field toward holistic, deployment-oriented distillation frameworks that foreground inference cost and structural integrity over mere parameter count minimization. Future research directions include scaling the method to very large LLMs, developing end-to-end hardware-optimized runtimes for dynamically compressed modules, and deeper study of behavioral and interpretability consequences of modular capacity budgeting.
(2605.04341)