- The paper introduces a formal framework that ties hidden state geometry to dual inference modes—Bayesian retrieval for memorized tasks and extrapolative learning for novel tasks.
- It demonstrates that additive separability and simplex interpolation enable transformers to align hidden state projections with Bayesian task posteriors, validated by high R² scores.
- Controlled synthetic experiments reveal that increasing task diversity instigates a sharp geometric phase transition, with distinct subspaces sustaining in-distribution versus out-of-distribution generalization.
Overview and Motivation
Transformers exhibit robust generalization across numerous tasks, operating via in-context learning (ICL) mechanisms that are well documented empirically but incompletely understood mechanistically. The paper "Task Vector Geometry Underlies Dual Modes of Task Inference in Transformers" (2605.03780) addresses two open questions: (1) How is task information encoded in hidden representations, and what geometric structures support memorized vs novel task inference? (2) Under what conditions and through what mechanisms can transformers generalize to tasks outside the training distribution? Through a suite of controlled synthetic experiments and a principled property-based framework, the authors elucidate a dual-mode inference picture—Bayesian task retrieval and extrapolative task learning—anchored in a near-orthogonal subspace emergence of task vectors.
Task Vectors, Representation Geometry, and the Property Framework
The authors introduce a formal mathematical framework for characterizing hidden state geometry in terms of task vectors—directions in representation space encoding latent tasks discovered from context. This framework formalizes four key properties:
- P0—Long-Context Stability: In the limit of large context, hidden states become deterministic functions of the latent and the current token.
- P1—Additive Separability: Hidden state means decompose additively into global mean, task vector, and token-encoding vector components, with negligible task-token interaction.
- P2—Simplex Interpolation: At finite context lengths, hidden states are convex combinations of task vectors, parameterized by context-dependent coefficients βt,k.
- P3—Bayesian Posterior Alignment: These coefficients βt,k align with the Bayesian posterior P(z=k∣context).
This framework moves beyond heuristic notions of task vectors and enables precise reasoning about the statistical and geometric underpinnings of ICL.

Figure 1: The synthetic biased dice experiment illustrates how the data distribution and latent variable structure induce two near-orthogonal subspaces in the model's representation, dictating inference mode and generalization.
Synthetic Experimental Paradigm
The empirical study leverages synthetic tasks—rolling biased dice (E1), in-context noisy linear regression (E2), and mixtures of Markov chains (E3)—to control and probe the emergence of hidden state geometry. In each case, sequences are generated from latent variables, with z controlling the outcome distribution or functional mapping. The experiments focus on two scenarios:
- In-Distribution (ID): Tasks seen during training—supports analysis of Bayesian retrieval behavior.
- Out-of-Distribution (OOD): Novel latent tasks—probes extrapolative inference.
Probing hidden states, the authors estimate task vectors by averaging representations over sequences associated with each latent, and perform intervention and decomposition analyses across network layers and training regimes.
Bayesian Task Retrieval: Simplex Interpolation and Posterior Alignment
For ID tasks, the dominant inference mode is Bayesian task retrieval, with hidden states tracking Bayesian posteriors over task vectors. Empirically, hidden state decomposition achieves high R2 according to the additive model, and the simplex-projected coefficients βt,k closely track the true posteriors αt,k.
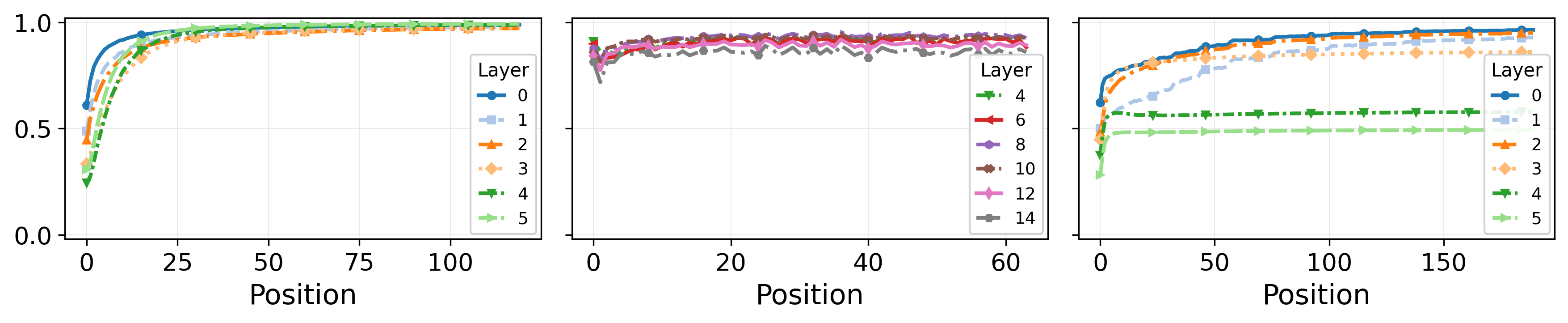
Figure 2: The R2 of the interpolation model remains high across layers and positions in all experiments, supporting the property of finite-context convex interpolation in the task-vector basis.
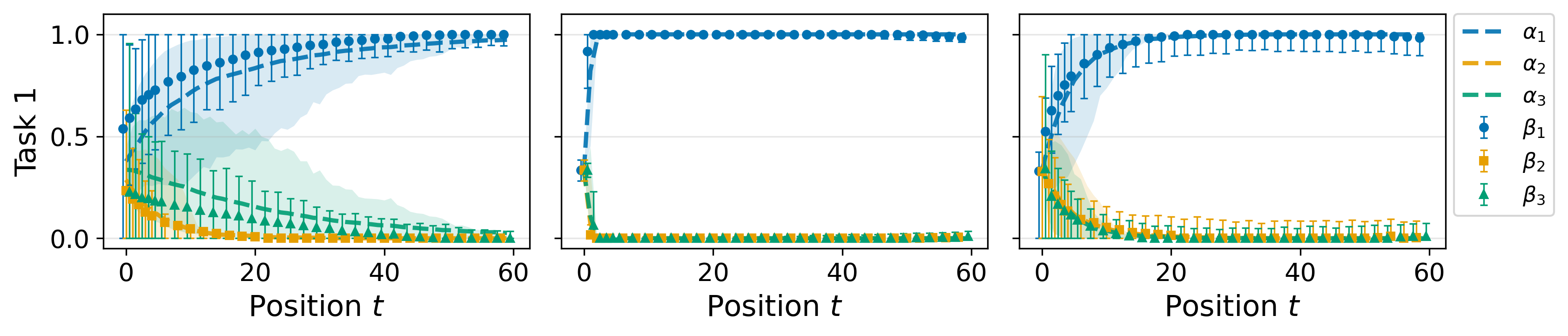
Figure 3: The simplex-projected model coefficients βt,k (markers, error bars) track the Bayesian posterior αt,k (dashed lines, shading), confirming that hidden state geometry matches Bayesian belief updating.
Causal intervention—steering hidden states to arbitrary points of the task-vector simplex—demonstrates that the model output is controlled by convex mixtures of remembered task behaviors, decisively outperforming hard-selection (nearest-neighbor) baselines. For example, under the simplex steering intervention, KL divergence from theoretical mixture predictions drops by up to a factor of βt,k0.

Figure 4: Substituting βt,k1 with random simplex points directly steers outputs to the corresponding mixture predictions, substantiating the causal role of task subspace.
Emergence of Dual Inference Modes and Near-Orthogonal Subspaces
With increasing task diversity in training, distinct geometric phases manifest, characterized by a transition from retrieval to extrapolative learning—the latter required for high-dimensional novelty. This transition is quantified via KL divergence metrics comparing the Bayesian (retrieval, M1) and extrapolative (M2) predictors. A sharp phase boundary emerges, signaled by a drop in the explanatory power (βt,k2) of OOD hidden states projected onto the major task subspace.

Figure 5: Transition in KL preference between Bayesian task retrieval (M1, blue) and extrapolative learning (M2, red) as task diversity and training progress grow. High task diversity promotes emergence of extrapolative inference.

Figure 6: The βt,k3 of OOD hidden-state projections onto the major task subspace decreases with task diversity, supporting the near-orthogonal subspace hypothesis for OOD computation.
Simplex trajectory analysis further reveals that, in high-diversity regimes, OOD hidden states drift outside the affine simplex defined by the major tasks, whereas ID hidden states converge to simplex vertices—demonstrating the functional and geometric dissociation of the two modes.
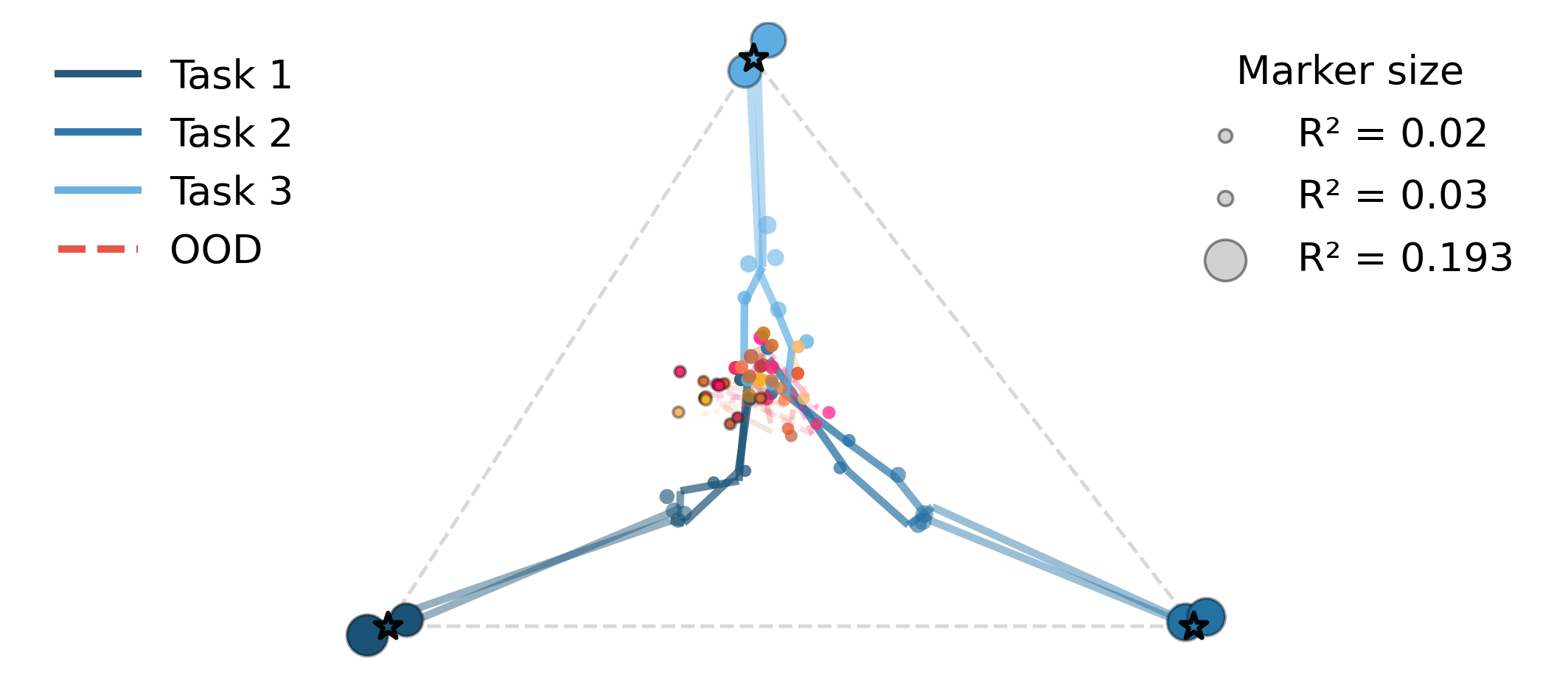
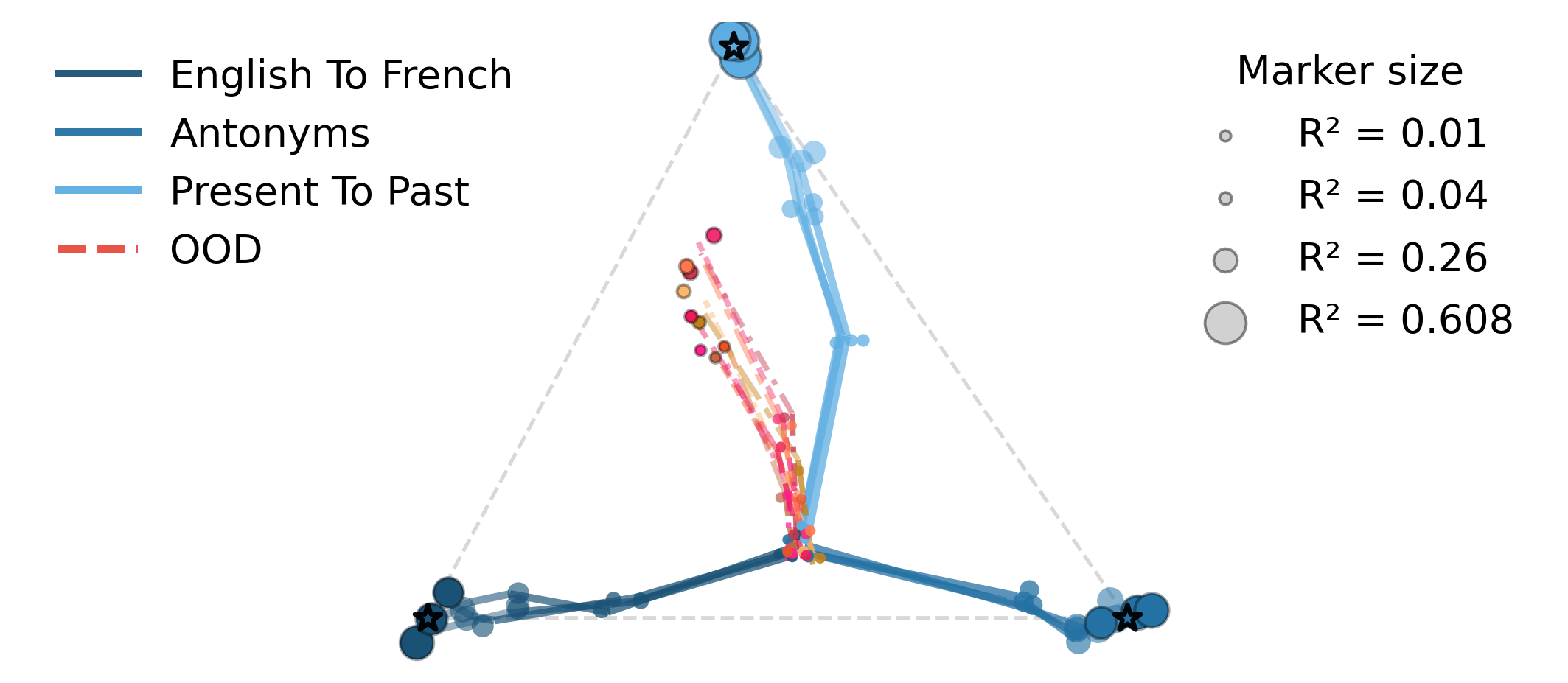
Figure 7: Left: E3, Right: Qwen2.5-7B. ID prompts’ hidden states move toward major task vertices; OOD prompts remain near-orthogonal, as reflected by small βt,k4.
Comprehensive subspace causal interventions confirm that the two modes are robustly disentangled: suppressing the task-vector subspace selectively impairs ID performance (exceeding 200% degradation in E1), while suppressing low-rank optimized directions in the orthogonal complement disproportionately devastates OOD and minor-task generalization, with negligible effect on ID performance.
Non-Markovian Counterexample: Breakdown of Summarization and Additivity
The analysis identifies critical limitations to additive task-vector representation. In a non-Markovian Dyck language (E4), with long-range dependencies for bracket matching, the conditional variance of hidden states remains substantial even after conditioning on the latent and a local window of context; clusters in the hidden representation directly encode the full Dyck prefix rather than any compressed summary.
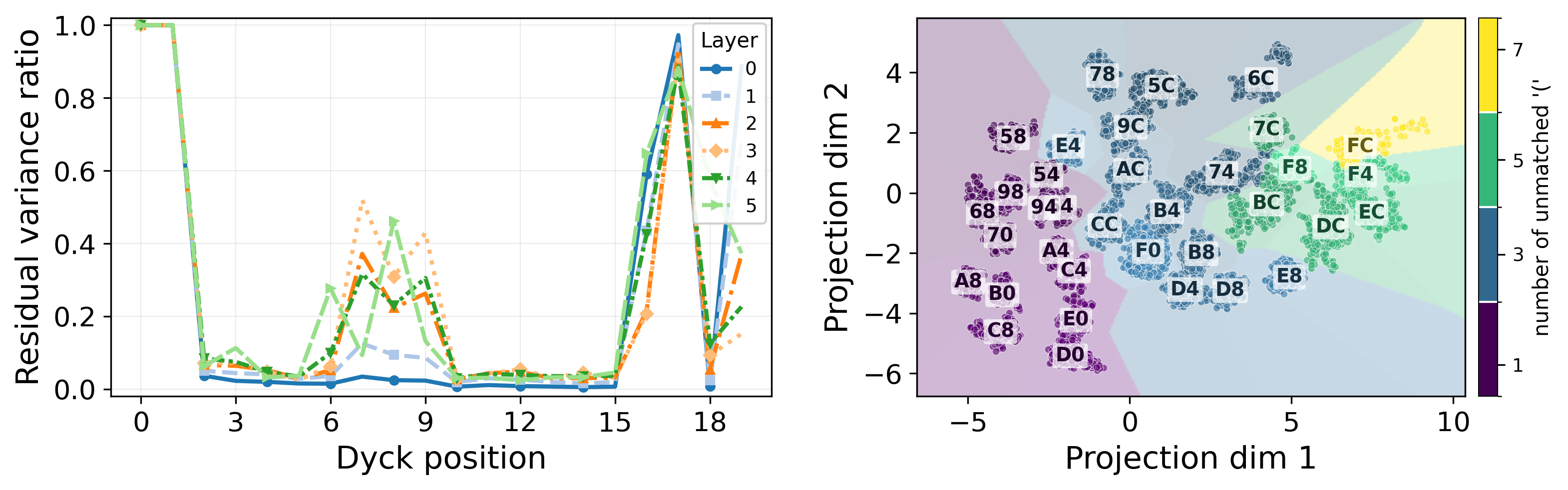
Figure 8: Left: Large residual variance at positions demanding non-local computation. Right: Hidden states form clusters corresponding to full Dyck prefix classes, refuting the possibility of additive summarization.
Implications and Future Directions
The identification and mechanistic disentanglement of Bayesian retrieval and extrapolative learning via near-orthogonal subspaces has significant theoretical and practical implications:
- Architecture/Representation Design: The evidence that transformer models internally partition computation into nearly orthogonal task-retrieval and extrapolative-generalization subspaces suggests directions for architectural regularization and interpretability.
- Robust Out-of-Distribution Generalization: The restriction that the task-vector subspace cannot support OOD generalization at high task diversity quantifies the geometric limitations of memorization mechanisms and motivates explicit modeling of context statistics as in emergent M2 representations.
- Mechanistic Interpretability: The formalization and validation of property-based frameworks (P0–P3) provide a template for analyzing and steering transformer internal computation, potentially extendable to natural tasks and larger LMs.
- Limits of Additivity and Markovianity: The necessity of Markovian structure for the additive summarization to hold signals important boundaries for the validity of current probe and intervention methodologies, warning against overgeneralization of geometric heuristics in non-local tasks.
The property-based approach, dual-mode framework, and their empirical validation set the stage for future work on theory-driven architectural interventions and deeper mechanistic analysis in both synthetic and real-world LMs.
Conclusion
Through a principled synthesis of statistical modeling, geometric representation analysis, and controlled experimentation, this work establishes a unified foundation for interpreting in-context learning in transformers. Bayesian task retrieval and extrapolative generalization modes are implemented via distinct, near-orthogonal subspaces whose emergence and utility are dictated by training data diversity and representational constraints. These findings provide both conceptual clarity and practical leverage for the design and interpretability of future transformer-based models (2605.03780).