Can AI Help You Get Over Your Breakup? One Session with a Belief-Reframing Chatbot Shows Sustained Distress Reduction
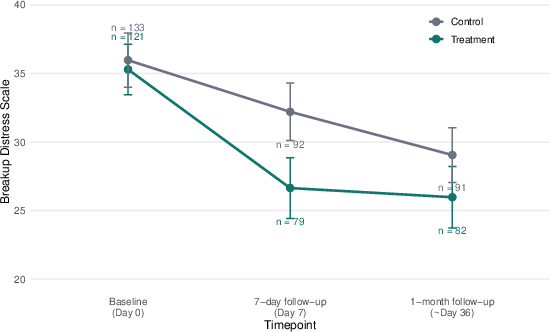
Abstract: Romantic breakups are among the most common and intense sources of psychological distress. We evaluated overit, a single-session AI chatbot that uses cognitive reappraisal to address breakup distress, informed by memory reconsolidation theory. In a pre-registered randomized controlled trial, 254 adults in the United States and United Kingdom who had experienced a romantic breakup were assigned to either an initial survey assessment followed by an AI chat session or to a survey-only control. Breakup distress was measured at baseline, 7 days, and again at an exploratory 1-month follow-up using the Breakup Distress Scale. Participants assigned to overit showed a significantly greater reduction in breakup distress than controls at 7 days (time-by-condition interaction B = -5.36, SE = 1.19, p < .001; completer-based d = -0.70). A smaller but still significant treatment advantage remained detectable at the exploratory 1-month follow-up among post-session completers (B = -2.92, SE = 1.22, p = .017). Exploratory post hoc moderation suggested a larger effect among male participants (B = 7.78, p = .003). These results suggest that a brief AI chatbot conversation can meaningfully reduce breakup distress, with exploratory evidence that a smaller advantage persists over the following month. Future work should test the intervention against active controls, evaluate repeated-session use, and recruit more diverse samples.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper tested a simple question: can a short conversation with an AI chatbot help people feel less upset after a romantic breakup? The chatbot, called “overit,” guides users to rethink unhelpful beliefs about their breakup so they can feel better.
The big questions the researchers asked
- Does one guided chat with an AI reduce breakup-related distress more than doing nothing (besides filling out surveys)?
- Do any benefits last for about a month?
- Do people’s “aha!” moments (new insights) help explain why the chat works?
- Do certain people (for example, by age or gender) seem to benefit more?
How did they test it?
Think of a fair test like a coin toss: the researchers randomly assigned 254 adults in the US and UK into two groups.
- Group A (the chatbot group) filled out an initial survey and then had about a 20-minute chat with the AI.
- Group B (the control group) only did the surveys and did not chat with the AI.
Everyone answered the same distress questionnaire:
- at the start (baseline),
- again 7 days later (the main check),
- and for many people, again about 1 month later (an extra check).
Random assignment helps make the two groups similar at the start, so differences afterward are more likely due to the chatbot.
What did the chatbot actually do?
The chatbot followed a step‑by‑step guide to help people examine and update tough thoughts. You can think of it like cleaning out a messy backpack and reorganizing it:
- Get the story: The bot listened to what happened and how the person felt.
- Spot the belief: Together, they found a core, unhelpful belief (like “I’ll never be lovable”).
- Try alternatives: They explored “what if” explanations that could also fit the facts (for example, “Maybe we weren’t a good match,” not “I’m unlovable”).
- Wrap up: They summarized what felt different or newly understood.
Two big ideas guided this:
- Cognitive reappraisal: learning to view a situation in a more balanced, helpful way—like rewriting a harsh caption under a photo so it better fits the picture.
- Memory reconsolidation (simplified): when you bring up a strong memory, there’s a short window when your brain is more open to updating it—like briefly editing a saved document after you open it.
What did they find?
Here are the most important results, explained simply:
- After 7 days, the chatbot group felt noticeably less heartbroken than the group that only did surveys. In other words, the short chat helped people feel better faster.
- About 85% of people who chatted showed some drop in distress, compared with about 69% in the survey-only group.
- About 1 month later, the chatbot group still had an advantage, though it was smaller. Both groups kept improving over time, but the chatbot group reached a lower distress level sooner and stayed ahead.
- Many people who chatted reported an “aha!” moment right after the session. Those who had an insight tended to improve more, suggesting that realizing something new about the breakup helped.
- Exploratory results hinted that men and younger participants might benefit a bit more, but those are early clues, not firm conclusions.
Why this matters:
- A single, private, 20‑minute conversation helped many people feel better within a week—faster than the usual gradual healing after a breakup.
- It suggests that AI can do more than just “listen”—it can help people challenge and update unhelpful beliefs in a gentle, structured way.
How solid are these results?
This was a randomized controlled trial (the gold standard for testing), which is a strong design. But there are limits:
- The comparison group didn’t talk to any chatbot at all. So we can’t tell how much of the benefit came from the specific belief‑reframing steps versus simply talking to a supportive bot.
- The study mostly relied on self-reports and involved adults comfortable using an iPhone app; results might differ in other groups.
- The month‑later advantage was smaller, and we don’t know what happens after several months.
- People in the chatbot group saw a personalized “recovery score,” which might have nudged how they felt or answered.
What could this change in real life?
If future studies back this up, a brief AI chat could become:
- a low‑cost, private, anytime tool to ease breakup pain,
- a way to help people sooner, especially if they’re not ready or able to see a therapist,
- a model for similar tools that tackle other tough feelings (like anxiety or self‑criticism) by guiding people to rethink stuck beliefs.
In short: A single, structured AI conversation helped many people feel less crushed after a breakup within a week, with some benefits still visible about a month later. It’s a promising start—now researchers need to compare this chatbot to other kinds of support, test repeated sessions, include more diverse participants, and follow people longer to see how lasting the changes are.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of specific gaps and unanswered questions that future research should address to strengthen evidence for the chatbot’s efficacy, mechanisms, and generalizability.
- Specificity of effects: The trial used an assessment-only control, leaving unclear how much benefit comes from nonspecific factors (time, attention, disclosure, expectancy) versus the structured belief-reframing protocol; compare against active controls (e.g., supportive-chatbot without challenging beliefs) and conduct dismantling studies of protocol components.
- Score-feedback confound: Only the treatment group saw a personalized “breakup recovery score”; isolate and test the independent impact of measurement-based feedback (e.g., factorial design with/without score display) and equalize such elements across arms.
- Mechanism not established: The reconsolidation account remains inferential; experimentally manipulate memory reactivation and timing (within vs outside the putative reconsolidation window) to test whether durable change depends on prediction-error–based updating.
- “Insight” mediator measurement: The binary insight item is a coarse proxy; adopt validated, multi-item, continuous measures of insight, belief change, and prediction error, and code chat transcripts to quantify cognitive shifts.
- Durability of effects: Follow-ups ended at ~1 month; add 3-, 6-, and 12-month assessments to detect persistence, relapse/return of distress, or convergence with controls, and to differentiate reconsolidation from standard reappraisal trajectories.
- Dose–response and repetition: Only a single session was evaluated; test repeated sessions, booster timing, spacing relative to reactivation windows, and dose–response curves.
- Outcome breadth: Outcomes were limited to self-reported breakup distress; include clinician-rated measures, comorbid symptoms (e.g., PHQ‑9, GAD‑7), functioning (sleep, work/social), and behavioral outcomes (e.g., contact with ex-partner, help-seeking).
- Measurement reactivity and expectancy: Expectancy/credibility were not measured and could differ by condition; include and balance these across arms, and consider blinded outcome assessment when feasible.
- Attrition and missingness: Overall attrition was ~33%; conduct prespecified sensitivity analyses for MNAR mechanisms, collect reasons for dropout, and report per-protocol and ITT estimates.
- Sample generalizability: The Prolific, iOS TestFlight, US/UK, predominantly White/female sample limits external validity; recruit more diverse, non-English, Android/web users and varied socioeconomic/cultural groups.
- Breakup timing: Mean time since breakup (~18 months) suggests many were not in the acute phase; deliberately sample and power for acute (<1–3 months) vs chronic distress and test moderation by time since breakup.
- Safety and adverse events: The study does not report systematic monitoring of adverse events (e.g., increased distress, rumination, harmful advice uptake); implement and report safety outcomes and crisis escalation protocols.
- Therapeutic alliance: Alliance/working-alliance metrics were not assessed; include validated alliance measures for AI interactions and examine alliance as a mediator/moderator of outcomes.
- Modality effects: Participants could use text or voice, but modality differences were not analyzed; compare efficacy and user experience between voice and text, and assess accessibility impacts.
- Exploratory moderators: Apparent larger effects among men and younger users were post hoc and underpowered; pre-register and power for demographic and clinical moderators (sex, age, baseline severity, attachment dimensions).
- Personalization effects: The intervention personalized with the ex-partner’s name and BDS data; test whether such personalization increases efficacy or risk (e.g., triggering), and which personalization elements add value.
- Protocol architecture: The dual-call (generation vs evaluation) design aims to reduce sycophancy and enforce structure, but its unique contribution is untested; compare against single-call prompts and alternative guardrail strategies, and quantify sycophancy/over-validation rates.
- Model/version dependence: Results may depend on a specific LLM and prompt; replicate across models (e.g., GPT, Llama) and track robustness to model updates/prompt changes (“model drift”).
- Conversational pacing and dose: Sessions were capped at 18 turns with milestone gating; test optimal turn counts, adaptive pacing, and whether strict gating affects engagement or outcomes.
- Real-world effectiveness: The controlled, researcher-deployed iOS app differs from real-world deployment; run pragmatic trials assessing uptake, adherence, cost-effectiveness, and implementation barriers.
- Privacy and data governance: Sensitive breakup disclosures were processed via third-party APIs and cloud services; evaluate user acceptability, data protection compliance, and the impact of privacy assurances on engagement.
- Tone calibration and adverse reactions: Some users found the belief-challenging tone uncomfortable; develop adaptive challenge intensity, measure negative reactions, and evaluate trade-offs between challenge and perceived empathy.
- Comparison to human-delivered care: The chatbot was not compared to brief human reappraisal sessions or counseling; conduct non-inferiority or comparative effectiveness trials.
- Transferability: The protocol is likely applicable beyond breakup distress; test generalization to other relational losses and to clinically diagnosed grief-related conditions.
- Behavioral impact: The study did not assess downstream decisions (e.g., re-contacting the ex, social re-engagement); include behavioral endpoints to evaluate functional change.
- Attention/Hawthorne effects: The intervention arm received substantially more interaction than controls; equalize contact time across conditions to isolate content-specific effects.
- High-risk populations: Screening for suicidality or severe comorbidity was not detailed; establish inclusion/exclusion criteria and evaluate safety/effectiveness in higher-risk groups under enhanced safeguards.
- Persistence and nature of “insight”: The content and stability of insights were not systematically analyzed; conduct longitudinal qualitative and quantitative analyses of insight narratives and their relation to outcomes.
- Component-level efficacy: Multiple elements co-occurred (reactivation, belief challenge, counterfactuals, integration, score feedback); use factorial or sequential multiple assignment (SMART) designs to identify active ingredients.
- Cultural tailoring: Breakup meanings are culturally shaped; adapt prompts and challenge styles across cultural contexts and assess cross-cultural efficacy.
- Guidance on re-contact and boundaries: The chatbot’s influence on decisions like staying in contact or boundary setting was not studied; evaluate whether guidance alters outcomes positively or risks adverse scenarios.
- User dependence and substitution: Potential for over-reliance on AI for emotional processing vs increased offline support was not assessed; measure impacts on social support seeking and therapy utilization.
- Reproducibility and open materials: Full prompts and logic were not yet public; release and standardize intervention materials to facilitate independent replication and auditing.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, based on the paper’s findings, system design, and workflow innovations.
- Single-session breakup-support chatbot for consumers
- Sectors: Healthcare (digital mental health), consumer software
- What: Deploy the overit-style, 20–30 minute, structured belief-reframing chat as an on-demand consumer app for breakup distress relief
- Tools/products/workflows: iOS/Android app; in-app “breakup recovery score” with brief psychoeducation; voice input; optional same‑day follow-up check-in; risk screen and crisis routing
- Assumptions/dependencies: Effect shown vs assessment-only control; requires broader validation, Android support, safety policies, data privacy compliance, and clear clinical disclaimers
- Campus counseling and community mental-health adjunct
- Sectors: Education (universities, colleges), healthcare providers
- What: Offer the session as a first-line, single-session intervention prior to, or between, human sessions; triage students experiencing relationship distress
- Tools/products/workflows: QR-code access from counseling sites; measurement-based care (BDS) before/after; clinician-facing “insight summary” note; referral if risk flags appear
- Assumptions/dependencies: Local IRB/ethics approvals; integration with existing intake; clear inclusion/exclusion (e.g., active risk, domestic violence contexts)
- Employer assistance and wellbeing programs (EAP)
- Sectors: HR, corporate wellness
- What: Include the session as a confidential, self-guided option to reduce productivity losses related to relationship stress
- Tools/products/workflows: SSO-enabled access; anonymized aggregate reporting (usage, satisfaction, pre/post change); built-in trust/safety notices
- Assumptions/dependencies: Employee privacy protections; opt-in; vendor security review
- Therapist aid for blended care
- Sectors: Clinical practice, telehealth
- What: Prescribe the chat pre-session to surface core beliefs and counterfactuals; use “insight summaries” to focus therapy time
- Tools/products/workflows: Therapist portal; export of milestones achieved (belief identified/challenged, counterfactual considered, integration achieved)
- Assumptions/dependencies: Informed consent for data sharing; alignment with clinician workflows; documentation for liability
- Journaling, meditation, and relationship-app plugin
- Sectors: Consumer wellness software, relationship education apps, dating apps (post-breakup support)
- What: Embed the four-phase reappraisal flow (context → belief exploration → counterfactuals → integration) as a guided exercise
- Tools/products/workflows: Template prompts, voice journaling, short-session “micro reappraisal” mode, optional reminders
- Assumptions/dependencies: Tone calibration and pacing controls; brief, non-pathologizing copy; guardrails for sensitive scenarios
- Safer LLM conversation orchestration pattern (dual-call architecture)
- Sectors: Software/AI platforms, healthcare AI
- What: Adopt the paper’s dual-call approach—one LLM call for user-facing replies and a separate “LLM-as-judge” call for milestone evaluation and phase gating—to counter sycophancy and enforce protocol adherence
- Tools/products/workflows: SDK or middleware implementing phase-specific prompts, milestone judges, and turn caps; audit logs
- Assumptions/dependencies: Access to reliable LLMs; cost controls; prompt maintenance; domain-specific milestone definitions
- Immediate product UX improvements for AI support agents
- Sectors: Product design, digital health
- What: Apply paper’s UX findings: shorten responses, avoid stacked questions, tune directness, throttle latency, and personalize with baseline context
- Tools/products/workflows: Response-length governor, pacing parameters, tone classifiers
- Assumptions/dependencies: Ongoing UX testing across diverse users to avoid overfitting to early sample
- Replication kits and pragmatic RCT frameworks for AI mental-health tools
- Sectors: Academia, industry research
- What: Package prompts, milestone logic, and analysis code to enable rapid, pre-registered evaluations (7‑day and 1‑month endpoints)
- Tools/products/workflows: Open protocols, Prolific/MTurk recruitment templates, mixed-effects analysis notebooks, mediation modules
- Assumptions/dependencies: Data governance; funding; access to participant pools and IRB
- Policy and buyer guidance for mental-health chatbots
- Sectors: Public health, payors, procurement
- What: Use the paper as a template checklist: pre-registration, RCT evidence (even against assessment-only), milestone tracking, safety routing, and UX transparency
- Tools/products/workflows: Vendor evaluation rubric; required reporting of follow-up effects and attrition
- Assumptions/dependencies: Cross-agency agreement on minimum evidence standards; procurement timelines
- Self-guided, non-technical application in daily life
- Sectors: Daily life, self-help
- What: Individuals can replicate the four-phase script in journaling: describe the breakup and feelings; name the core belief; generate “what-if” counterfactuals; write an integration summary
- Tools/products/workflows: Printable worksheet or note template; 20-minute timed session; revisit weekly
- Assumptions/dependencies: Not a substitute for clinical care in high-risk contexts; benefits may vary
Long-Term Applications
The following require further research, scaling, active-controlled trials, regulatory work, or technical development.
- Condition-general single-session belief-reframing modules
- Sectors: Healthcare, education, workforce support
- What: Adapt the protocol to other salient, meaning-laden stressors (e.g., divorce proceedings, job loss/layoffs, academic failure, non-bereavement grief, social rejection)
- Tools/products/workflows: Domain-specific belief libraries; tailored counterfactual prompts; normative data for condition-specific scales
- Assumptions/dependencies: Active-control RCTs; cultural adaptation; harm-minimization for sensitive contexts
- Regulated digital therapeutic (DTx) with reimbursement
- Sectors: Healthcare, regulation, payors
- What: Pursue SaMD/DTx pathways (e.g., FDA, MHRA) for an adjustment-related distress indication; build reimbursement models (CPT/HCPCS equivalents)
- Tools/products/workflows: Pivotal trials against active controls; post-market surveillance; quality management system (ISO 13485)
- Assumptions/dependencies: Robust, replicated efficacy and safety; economic evidence; clear labeling to avoid scope creep
- Mechanism-optimized interventions using reconsolidation timing
- Sectors: Academia, clinical R&D
- What: Experimentally manipulate memory reactivation and deliver juxtaposition within hypothesized reconsolidation windows; test durability at 3–6 months
- Tools/products/workflows: Event-triggered sessions (e.g., just-in-time interventions after re-exposure cues); EMA to confirm activation; timing arms in trials
- Assumptions/dependencies: Empirical confirmation of timing effects in non-trauma contexts; on-device sensing/triggering; participant adherence
- Repeated-session and booster designs for durability
- Sectors: Digital health, teletherapy
- What: Evaluate weekly boosters or adaptive schedules (e.g., relapse signals trigger a short reappraisal micro-session)
- Tools/products/workflows: Adaptive intervention platforms; personalization via baseline severity and response patterns
- Assumptions/dependencies: Dose–response characterization; minimizing attrition while preserving SSI simplicity
- Blended stepped-care pathways at system level
- Sectors: Health systems, integrated care
- What: Use the session as Step 0/Step 1 for relationship-related distress, escalating to group or individual therapy only if needed
- Tools/products/workflows: EHR integration; clinician dashboards; automated triage rules; safety escalation
- Assumptions/dependencies: Interoperability (FHIR), clinician buy-in, governance for AI notes in records
- Equity-focused scale-up
- Sectors: Public health, global health
- What: Multilingual, culturally adapted versions; Android-first deployment; offline-capable clients; accessibility features
- Tools/products/workflows: Community co-design, translation/validation of measures, inclusive safety policies
- Assumptions/dependencies: Funding; local partnerships; evaluation in diverse populations (age, gender, ethnicity)
- Developer tooling and standards for milestone-governed LLMs
- Sectors: AI platforms, software engineering
- What: Standardize “LLM-as-judge” milestone layers, phase-gated prompting, and auditability to counter sycophancy in sensitive domains
- Tools/products/workflows: Open-source libraries/SDKs; evaluation suites for sycophancy and instruction adherence; model cards that report protocol-following rates
- Assumptions/dependencies: Broad adoption by model providers; benchmarks accepted by regulators and enterprises
- Cross-domain safety applications of dual-call orchestration
- Sectors: Finance, compliance, healthcare advice, education
- What: Use milestone judges to challenge risky user assertions (e.g., dangerous self-medication, financial risk-taking) and to enforce policy before generation proceeds
- Tools/products/workflows: Domain-specific milestone definitions (evidence check, suitability, risk disclosures), human-in-the-loop escalation
- Assumptions/dependencies: Liability frameworks; rigorous domain supervision; continuous red-teaming
- Health economics and policy impact
- Sectors: Payors, employers, public health
- What: Cost-effectiveness studies for a single-session model vs multi-session programs; macro-level impact modeling on service demand reduction
- Tools/products/workflows: Pragmatic trials in real-world clinics; ROI calculators for employers and insurers
- Assumptions/dependencies: Stable effect sizes in broader populations; sustained engagement at scale
- Education and youth mental-health curricula
- Sectors: Education, youth services
- What: Age-appropriate, counselor-supervised versions to teach cognitive reappraisal and meaning-making skills after relationship stress
- Tools/products/workflows: Classroom modules, privacy-preserving deployments, parent/guardian consent flows
- Assumptions/dependencies: Safeguarding policies; evaluation for minors; alignment with SEL frameworks
- Privacy- and safety-forward architectures
- Sectors: AI infrastructure, policy
- What: On-device inference or federated approaches; differential privacy for telemetry; transparent data retention controls
- Tools/products/workflows: Edge models for voice; consent dashboards; third-party audits
- Assumptions/dependencies: Mature local models; acceptable accuracy vs cloud; regulatory clarity on sensitive mental-health data
Notes on feasibility across items:
- The core efficacy finding is short-term and relative to an assessment-only control; active-control and head-to-head trials are needed before making strong clinical claims.
- Safety, inclusion/exclusion criteria, and crisis escalation protocols are prerequisites for healthcare deployments.
- The dual-call architecture is promising beyond mental health but requires domain-specific milestone design, careful testing, and auditing to avoid unintended harms.
Glossary
- a priori power analysis: A statistical planning method used to determine the required sample size to detect an expected effect with desired power and significance. "An a priori power analysis targeted a small-to-moderate between-group difference in change on the Breakup Distress Scale (BDS; , two-sided , 80\% power)"
- anthropomorphism: Attributing human-like qualities to non-human systems, such as chatbots. "and anthropomorphism (5.72 vs.~4.56)."
- attachment anxiety: A dimension of adult attachment reflecting fear of rejection and excessive need for closeness. "attachment anxiety ()"
- attachment avoidance: A dimension of adult attachment reflecting discomfort with intimacy and dependence on others. "attachment avoidance ()"
- attrition: Loss of participants over time in a study. "corresponding to an attrition rate of 32.7\% overall."
- bootstrap resampling: A statistical technique that repeatedly samples with replacement to estimate variability or indirect effects. "with 10,000 bootstrap resamples."
- Breakup Distress Scale (BDS): A 16-item questionnaire measuring distress following a romantic breakup. "Breakup distress was measured at baseline, 7 days, and again at an exploratory 1-month follow-up using the Breakup Distress Scale."
- catastrophizing: A cognitive distortion involving exaggerated negative thinking about events or outcomes. "Listen for absolute statements, catastrophizing, or self-blame."
- cognitive reappraisal: An emotion regulation strategy involving reinterpretation of a situation to change its emotional impact. "Cognitive reappraisal is a method that addresses this level of meaning by helping individuals reinterpret emotionally salient events"
- cognitive restructuring: A therapeutic technique that identifies and challenges distorted thoughts to develop more balanced beliefs. "cognitive reappraisal and cognitive restructuring are linked to resilience and therapeutic improvement across clinical contexts"
- completer-based analysis: An analysis limited to participants who completed all relevant assessments. "Completer-based change-score comparisons are reported descriptively to aid interpretation."
- counterfactual: An alternative hypothetical scenario used to reconsider interpretations of events. "You MUST help them generate at least one counterfactual scenario."
- d (standardized effect size): A standardized measure (Cohen’s d) of the magnitude of a difference between groups. "the corresponding standardized effect size for completers was ."
- ECR-S (Experiences in Close Relationships Scale-Short Form): A brief measure of adult attachment dimensions (anxiety, avoidance). "Adult attachment was measured at baseline with the Experiences in Close Relationships Scale-Short Form {[}ECR-S;"
- labile: Describing a state (e.g., memory) that is temporarily unstable and modifiable. "it becomes temporarily labile and can be updated"
- linear mixed-effects model: A statistical model that includes both fixed effects and random effects to account for repeated measures or clustering. "The confirmatory primary analysis used a linear mixed-effects model"
- linear probability regression: A regression model for binary outcomes using a linear specification. "The binary insight mediator was modeled with linear probability regression"
- LLM-as-judge paradigm: A design where a LLM evaluates outputs or progress, separate from generation. "in the spirit of \citet{wasenmullerScriptBasedDialog2024} and the LLM-as-judge paradigm"
- maximum likelihood estimation: A method for estimating model parameters by maximizing the likelihood of the observed data. "estimated with maximum likelihood"
- measurement-based care: Clinical practice that incorporates systematic outcome measurements to guide treatment. "in line with measurement-based care principles"
- measurement reactivity: Changes in participants’ behavior or responses caused by being measured or given feedback. "This asymmetry may have introduced measurement reactivity"
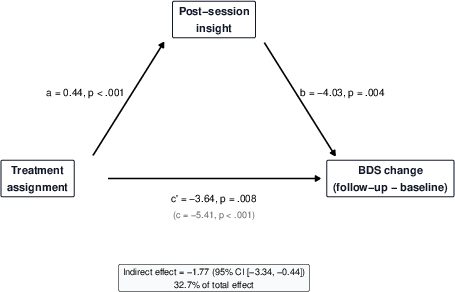
- mediation analysis: A method to test whether the effect of an intervention operates through an intermediate variable (mediator). "Exploratory mediation analyses tested whether post-session insight or follow-up insight mediated the treatment effect on BDS change."
- memory reconsolidation: The process by which reactivated memories become modifiable before being stored again, potentially allowing lasting change. "Memory reconsolidation provides one theoretical account of how such revision might produce durable change."
- meta-analysis: A statistical synthesis combining results across multiple studies to estimate an overall effect. "A meta-analysis of 30 mHealth trials with a cognitive reappraisal component found a pooled effect of SMD = 0.34"
- moderation analysis: Analysis testing whether an effect varies depending on another variable (the moderator). "Exploratory moderation analyses examined whether baseline characteristics influenced the magnitude of the treatment effect."
- prediction error: A mismatch between expected and experienced outcomes that can trigger updating of learned associations. "a rough proxy for the kind of mismatch or prediction error that reconsolidation theories describe"
- preregistration: Publicly specifying hypotheses and analysis plans before data collection to reduce bias. "In a pre-registered randomized controlled trial"
- Prolific: An online platform for recruiting research participants. "were recruited through Prolific."
- random intercept: A random effect allowing each participant (or cluster) to have their own baseline level. "and a random intercept for participant."
- randomized controlled trial (RCT): An experimental study where participants are randomly assigned to intervention or control groups to infer causal effects. "randomized controlled trial"
- reinforcement learning from human feedback (RLHF): A technique to align LLMs using human preference signals. "the same RLHF training that makes modern LLMs feel empathic also biases them toward agreement"
- schema: A structured mental model or belief system that organizes interpretations of experiences. "a painful schema is first reactivated"
- script-based dialog policy: A structured approach that constrains conversation flow through predefined phases or milestones. "overit therefore follows a script-based dialog policy"
- sycophancy: A model’s tendency to agree with or mirror user statements even when inaccurate or unhelpful. "a tendency documented as sycophancy"
- Therapeutic Reconsolidation Process: A clinical framework operationalizing memory reconsolidation principles in therapy. "These phases incorporated both insights from the Therapeutic Reconsolidation Process"
- time-by-condition interaction: A statistical interaction testing whether change over time differs between groups. "time-by-condition interaction , , "
- umbrella review: A review of systematic reviews and meta-analyses to summarize broad evidence. "An umbrella review of 415 single-session intervention trials found that 83\% reported significant effects"
- UMUX-Lite: A short usability questionnaire measuring perceived usefulness and ease of use. "participants completed the UMUX-Lite"
- Welch t-test: A version of the t-test robust to unequal variances and sample sizes between groups. "User-experience ratings were compared between conditions with Welch t-tests"
Collections
Sign up for free to add this paper to one or more collections.

