TheraMind: A Strategic and Adaptive Agent for Longitudinal Psychological Counseling
Abstract: LLMs in psychological counseling have attracted increasing attention. However, existing approaches often lack emotional understanding, adaptive strategies, and the use of therapeutic methods across multiple sessions with long-term memory, leaving them far from real clinical practice. To address these critical gaps, we introduce TheraMind, a strategic and adaptive agent for longitudinal psychological counseling. The cornerstone of TheraMind is a novel dual-loop architecture that decouples the complex counseling process into an Intra-Session Loop for tactical dialogue management and a Cross-Session Loop for strategic therapeutic planning. The Intra-Session Loop perceives the patient's emotional state to dynamically select response strategies while leveraging cross-session memory to ensure continuity. Crucially, the Cross-Session Loop empowers the agent with long-term adaptability by evaluating the efficacy of the applied therapy after each session and adjusting the method for subsequent interactions. We validate our approach in a high-fidelity simulation environment grounded in real clinical cases. Extensive evaluations show that TheraMind outperforms other methods, especially on multi-session metrics like Coherence, Flexibility, and Therapeutic Attunement, validating the effectiveness of its dual-loop design in emulating strategic, adaptive, and longitudinal therapeutic behavior. The code is publicly available at https://0mwwm0.github.io/TheraMind/.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces TheraMind, an AI “therapist” that chats with people over multiple sessions to give psychological support. Unlike many chatbots that treat every conversation as new, TheraMind remembers past sessions, understands emotions, and changes its strategy over time—more like a real human therapist.
What are the authors trying to figure out?
The authors wanted to solve three big problems with current AI counseling tools:
- They don’t truly understand feelings or attitudes in a deep, structured way.
- They often forget past conversations, so they can’t build long-term trust or progress.
- They stick to one therapy style and don’t adjust when it isn’t working.
In simple terms: Can an AI counselor act more like a real therapist—remembering the person, sensing their emotions, and changing its plan over time?
How does TheraMind work?
To make the AI act more like a therapist, the authors designed a system with two “loops,” like having both a play-by-play coach and a season planner:
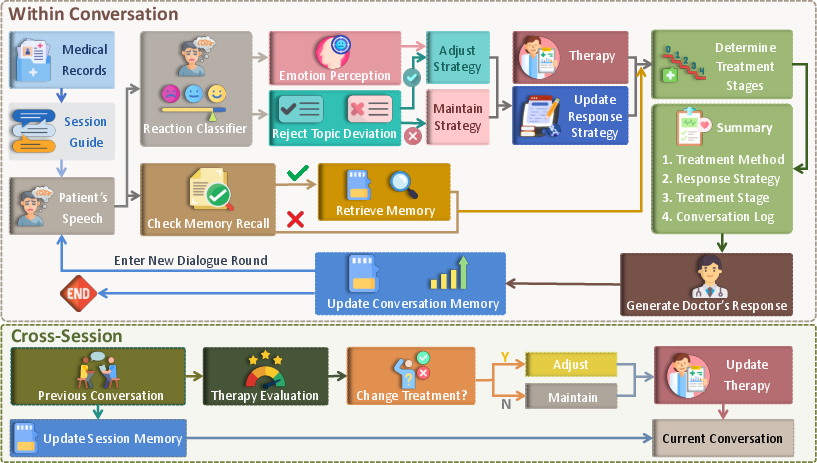
The Intra-Session Loop: What happens during the conversation
This part is about quick, smart choices inside a single chat.
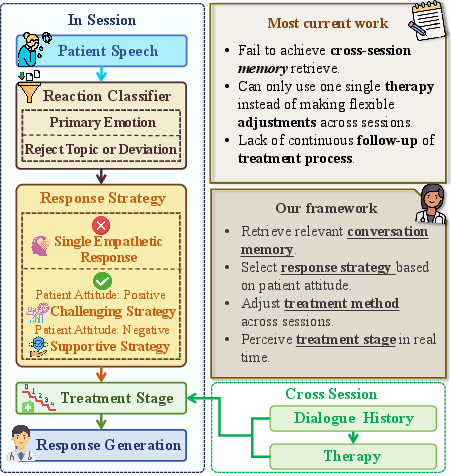
- Emotional understanding: The AI listens not just to words but also tries to “read the room,” figuring out the person’s emotion (like sadness or fear), how strong it is, and whether the person is cooperative or resistant.
- Memory: The AI looks back at important pieces from past sessions, like a therapist’s notes, so it can follow up on earlier topics.
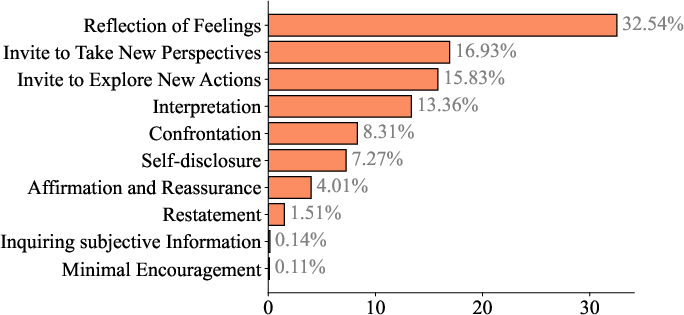
- Strategy choice: Based on the emotion and context, the AI picks a response style—such as supportive (validating feelings) or gently challenging (inviting new perspectives)—and stays aware of the current stage of therapy in that session.
Think of this like a thoughtful friend who remembers what you told them last time, notices how you sound today, and decides whether to comfort you or help you rethink something.
The Cross-Session Loop: What happens after the conversation
This part is about long-term planning across many sessions.
- Evaluate what worked: After each session, the AI reviews how effective the chosen therapy method was.
- Adapt the plan: For the next session, the AI keeps or changes the therapy style (for example, shifting from Cognitive Behavioral Therapy to a more person-centered approach) based on how the person responded.
This is like a coach watching game replays and then adjusting the training plan for the next game.
How did they test it?
The researchers built a realistic testing setup using anonymized real counseling cases. They:
- Simulated six-session arcs (like having six therapy appointments) for 100 different cases covering a variety of issues (such as anxiety, family problems, stress, social challenges).
- Used an AI “patient” that could respond in flexible and natural ways—sometimes cooperative, sometimes resistant—to mimic real life.
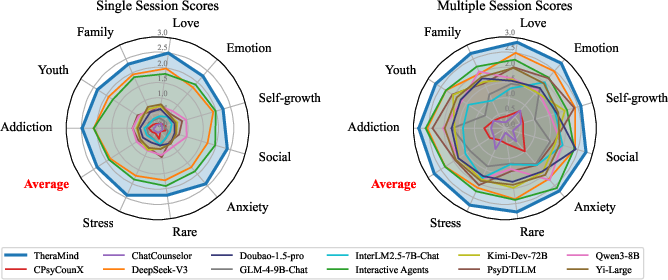
- Measured performance using both single-session and multi-session metrics:
- Single-session: How well the AI builds a bond and keeps a high-quality conversation.
- Multi-session: How well it stays coherent across sessions, adapts strategies (flexibility), shows consistent empathy over time, and “attunes” its actions to the right phase of therapy.
They also compared TheraMind to many other models and did human evaluations to check whether the AI’s decisions matched professional judgment.
What did they find and why is it important?
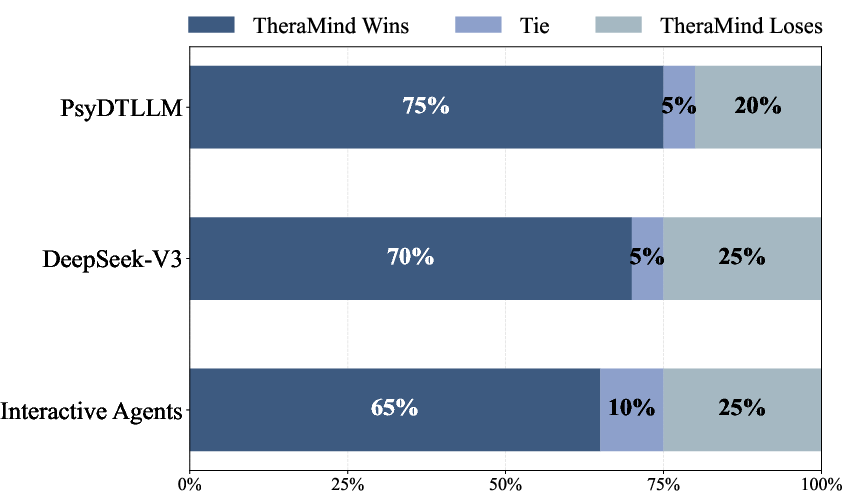
The authors found that TheraMind outperformed other systems, especially in multi-session measures. In everyday terms:
- It remembered and used past information, creating a more connected, meaningful long-term conversation.
- It adjusted its methods over time, which made therapy more personalized and effective.
- It showed strong empathy consistently, not just once.
- It picked the right kind of help at the right time, like building trust early and focusing on deeper change later.
This matters because real therapy happens over weeks or months. A chatbot that forgets past sessions or never changes its approach isn’t very helpful. TheraMind’s design makes AI counseling feel more continuous, caring, and goal-oriented—closer to what a trained therapist would do.
What’s the bigger picture?
If AI counselors can remember, understand feelings better, and adapt their strategies, they could:
- Provide more accessible mental health support to people who can’t easily see a therapist, especially where demand is high.
- Help with ongoing support in between human therapist sessions.
- Offer training tools for professionals or students to practice counseling skills.
However, this is not a replacement for human therapists. Safety, ethics, and supervision still matter a lot. TheraMind is a step toward AI that supports long-term emotional care in a smarter, more human-like way.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Real-world validation: No clinical trials with actual patients; conduct IRB-approved pilots comparing symptom outcomes (e.g., PHQ-9, GAD-7, OQ-45) against human therapists and strong baselines.
- Ecological validity of evaluation: Heavy reliance on LLM-simulated patients; quantify how simulated sessions differ from real patient interactions via side-by-side studies with standardized patient actors and clinical populations.
- Safety and risk management: No explicit crisis detection or escalation protocol (e.g., suicidality, self-harm, psychosis); develop, integrate, and benchmark safety modules with false-negative/false-positive rates and time-to-escalation metrics.
- Therapy selection governance: The LLM-driven therapy switching lacks guardrails; define decision thresholds, switch frequency caps, and pre-specified contraindications to prevent harmful or premature modality changes.
- Outcome-centric metrics: Current metrics emphasize conversational qualities; add hard clinical endpoints (symptom reduction, functional improvement, engagement, dropout) and follow-up measures beyond dialogue proxies.
- Fidelity to therapeutic modalities: Unclear whether generated interventions adhere to modality-specific competencies; measure treatment fidelity (e.g., CBT competence ratings, MI adherence, psychodynamic technique markers) and link to outcomes.
- Transparency of f_eval and f_select: Details of the Therapy Evaluation and Selection modules (criteria, priors, model prompts/training) are unspecified; publish decision schemas, calibration methods, and inter-rater reliability vs. expert judgments.
- Reaction Classifier provenance: Training data, labels, performance (accuracy/F1), calibration, and cross-cultural robustness for emotion, intensity, and attitude detection are not reported; provide benchmarks and error analyses.
- Attitude taxonomy granularity: Binary “Cooperative/Resistant” may be too coarse; evaluate richer interpersonal process codes (e.g., ambivalence, disengagement, reactance) and their utility for strategy selection.
- Phase detection validation: The method for identifying therapeutic phases is not empirically validated; report phase classification accuracy vs. expert annotations and effects on intervention quality.
- Memory mechanism specifics: Retrieval architecture (e.g., vector DB, RAG, summarization), update policies, and forgetting/overwrite rules are unclear; benchmark recall precision/coverage, error propagation, and “misremembering” rates.
- Memory safety and governance: No privacy policies for memory retention, consent, right-to-be-forgotten, encryption-at-rest/in-transit, or auditability; specify data governance aligned with HIPAA/GDPR-like standards.
- Hallucination control: Lack of mechanisms to detect/mitigate clinical hallucinations and confabulated memories; implement verification, confidence tagging, and counterfactual checks for recalled content.
- Long-horizon scalability: Evaluation is limited to six sessions; study performance, memory drift, strategy stability, and alliance trajectories across 20+ sessions.
- Modality coverage: No support for voice/prosody, pauses, or non-verbal cues which are critical in therapy; test multimodal inputs and their impact on perception and strategy choice.
- Generalization across languages/cultures: Experiments use Chinese cases; evaluate cross-lingual performance, cultural competence, and translation fidelity in diverse populations.
- Demographic fairness: No analysis of performance disparities across age, gender, socioeconomic status, or diagnostic categories; add bias audits and mitigation strategies.
- Severe/rare disorders: Inclusion of “Rare” cases (e.g., schizophrenia, autism) without documented safeguards; define exclusion/precaution criteria and supervise with clinician-in-the-loop policies.
- Alliance measurement validity: WAI-inspired alliance scores come from annotators rather than patient self-report; validate proxy measures against patient-reported alliance and adherence outcomes.
- Automatic evaluator bias: Reliance on Gemini-2.5-Flash for scoring risks evaluator-model bias; triangulate with multiple evaluators (human experts, diverse LLMs), adversarial tests, and report inter-evaluator agreement.
- Statistical rigor: Report sample sizes per test, confidence intervals, effect sizes, and significance testing for main and ablation results; include power analyses.
- Reproducibility: Release full prompts, patient simulator configurations, seeds, and annotation rubrics; document versioning of all LLMs used to mitigate drift.
- Compute and latency: No measurements of resource use, throughput, and latency under realistic session lengths; profile for deployment feasibility and cost.
- Integration into clinical workflows: Lacks clinician-in-the-loop controls, documentation standards, and audit trails; design interfaces for supervision, override, and case notes integration (EHR compatibility).
- Ethical and regulatory boundaries: Clarify scope of practice, licensing constraints, consent flows, and user disclosures for non-human therapy; map to local regulatory frameworks.
- Strategy repertoire coverage: The intervention taxonomy and mapping from perceived state to strategy are not fully enumerated; assess coverage vs. evidence-based techniques and measure incremental outcome effects per strategy.
- Switching effects on alliance: Unstudied impact of modality switches on therapeutic alliance and engagement; run controlled studies measuring alliance trajectories pre/post switch.
- Robustness to adversarial/noisy inputs: Evaluate resilience to incoherent, hostile, or manipulative patient utterances; add safeguards against prompt injection and toxic content.
- Dropout and retention: No analysis of patient dropout dynamics or retention correlates across sessions; investigate predictors and adaptive tactics to reduce attrition.
- Patient goals and treatment planning: Session Guides are LLM-generated; assess how automated planning aligns with patient-defined goals and how goal-setting affects outcomes.
- Explainability and auditability: Provide interpretable rationales for strategy and therapy selection decisions; log decision traces for clinical review and error diagnosis.
- Interoperability with tools: Unexplored integration with validated screening tools (PHQ-9, GAD-7), scheduling, crisis hotlines, or referral systems; measure benefits to care continuity.
- Comparative safety evaluation: No head-to-head safety benchmarking against safety-focused agents (e.g., EmoAgent); include standardized safety tests and red-team audits.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage TheraMind’s dual-loop agent design (intra-session state perception + cross-session memory; cross-session therapeutic planning) with today’s LLM capabilities.
- Sector: Healthcare (Telehealth, Behavioral Health Clinics)
- Application: Therapist copilot for longitudinal continuity (session summaries, memory retrieval of prior disclosures, stage-aware prompts, suggested interventions)
- Tools/Workflows: “Longitudinal Memory Vault” (retrieval-augmented case memory), “Therapeutic Phase Tracker,” “Clinical Reflection Report” (post-session efficacy notes), EHR/FHIR plugins for progress notes
- Assumptions/Dependencies: Human-in-the-loop; HIPAA/GDPR/PIPL compliance; reliable retrieval; model guardrails for safety; does not autonomously diagnose or treat
- Sector: Digital Health (Consumer Mental Wellness Apps)
- Application: Multi-session chat support that remembers user context, tracks goals, and adapts tone/strategy (supportive vs. challenging) across weeks
- Tools/Workflows: Reaction Classifier microservice (emotion, intensity, attitude) to tailor responses; weekly plan recap; adherence nudges (homework check-ins)
- Assumptions/Dependencies: Clear disclaimers (not a substitute for therapy); safety escalation pathways; culturally appropriate content (initial strengths in Chinese)
- Sector: Employee Assistance Programs (EAPs)
- Application: Intake-to-follow-up continuity assistant (reminds of earlier concerns, aligns tasks/goals, prepares human counselor handoff documents)
- Tools/Workflows: Handoff summary generator; longitudinal progress cards for counselors; adherence tracking for between-session exercises
- Assumptions/Dependencies: Employer data governance; explicit consent; seamless integration with incumbent case management systems
- Sector: Education (Counseling Training, Clinical Supervision)
- Application: Role-play simulation lab using the paper’s high-fidelity longitudinal patient simulator to train skillful phase transitions and strategy selection
- Tools/Workflows: “Synthetic Patient Generator,” multi-session scenario bank by issue category; scoring along Coherence/Flexibility/Empathy/Attunement
- Assumptions/Dependencies: Simulator face validity; supervision rubric alignment; avoids overfitting trainees to simulator quirks
- Sector: Healthcare Operations (Quality Assurance)
- Application: Multi-session quality dashboard for counseling programs, with the paper’s metrics (Coherence, Flexibility, Empathy, Therapeutic Attunement)
- Tools/Workflows: “Multi-Session QA Dashboard” powered by LLM judging; drift detection in alliance/attunement over time
- Assumptions/Dependencies: Transparent, auditable scoring; bias checks; model agreement with human raters for local population
- Sector: Primary Care Integration
- Application: Behavioral health case continuity assistant embedded in collaborative care (summarizes mental health trajectory for PCPs)
- Tools/Workflows: Cross-session memory recall + session-note summarizer that surfaces risk changes, goals, and modality used
- Assumptions/Dependencies: Interoperability (FHIR); clinical oversight; clear escalation criteria
- Sector: Insurance/Managed Care
- Application: Documentation support for value-based care (goal tracking across sessions; evidence of modalities tried and adapted)
- Tools/Workflows: Therapy-method timeline; “Therapy Switch Advisor” rationale draft (kept as suggestion for clinicians)
- Assumptions/Dependencies: Human review before claims submission; compliance with medical-necessity documentation standards
- Sector: Customer Support/Coaching (Non-clinical)
- Application: Longitudinal coaching agent (habit-building, stress management) that adapts style based on user attitude/emotional intensity
- Tools/Workflows: Attitude-aware strategy switch (supportive vs. challenge); weekly progress continuity summaries
- Assumptions/Dependencies: Non-clinical scope; safety filters; user consent for memory retention
- Sector: Public Health/Policy Pilots
- Application: Evaluation harness for multi-session conversational services (benchmarking vendors on longitudinal metrics)
- Tools/Workflows: The paper’s evaluation protocol and metrics operationalized for procurement and pilot studies
- Assumptions/Dependencies: Standardized test sets; independent oversight; transparency into prompts/scoring
- Sector: Software/AI Platforms
- Application: Agentic building blocks for any multi-session workflow (memory recall, phase tracking, strategy switching)
- Tools/Workflows: “Dual-Loop Orchestrator API” with modules: Reaction Classifier, Memory Recall, Phase Tracker, Post-Session Evaluator, Strategy/Therapy Selector
- Assumptions/Dependencies: API hardening; latency/cost control; content policy guardrails
- Sector: Academia/Research
- Application: Benchmarking and ablation-friendly testbed for longitudinal counseling research
- Tools/Workflows: Reuse of the paper’s simulator and metrics; side-by-side evaluation against baselines; component ablations (memory, phase, strategy, selection)
- Assumptions/Dependencies: Licensing/terms for CPsyCounR-derived assets; IRB for any human evaluation
Long-Term Applications
These use cases require additional clinical validation, scaling, technical development, or regulatory pathways before wide deployment.
- Sector: Healthcare (Clinical-Grade Digital Therapeutics)
- Application: FDA/CE-cleared, reimbursable, multi-session digital therapeutic with adaptive modality selection (e.g., CBT ↔ MI ↔ client-centered)
- Tools/Workflows: Outcome-optimized therapy policy; RCT-validated pathways; clinician dashboard with justification of therapy switches
- Assumptions/Dependencies: Robust RCT evidence; post-market surveillance; explainability; safety/risk triage embedded
- Sector: Crisis Care and Triage
- Application: Longitudinal risk sensing (escalation for suicidality or deterioration; continuity-aware triage)
- Tools/Workflows: Multi-session risk trajectory modeling; handoff protocols to hotlines/urgent services
- Assumptions/Dependencies: Extremely high precision/recall; legal and clinical oversight; integration with crisis infrastructure
- Sector: Integrated Care with Multimodal Sensing
- Application: Therapy phase and strategy adaptation using passive data (wearables, sleep, voice prosody) fused with dialogue memory
- Tools/Workflows: Multimodal perception pipeline; privacy-preserving federated learning; clinician-in-the-loop tuning
- Assumptions/Dependencies: Consent and data rights; robust multimodal models; strong privacy/security guarantees
- Sector: Personalized Treatment Policy Learning
- Application: Learning individualized long-horizon therapy policies from outcomes (preference optimization/RL with clinical constraints)
- Tools/Workflows: Off-policy evaluation; safety-constrained RL; causal inference for therapy switch effects
- Assumptions/Dependencies: Sufficient longitudinal outcome data; bias mitigation; ethical review
- Sector: Global and Multilingual Mental Health
- Application: Culturally adapted, multilingual agents with localized therapy norms and risk protocols
- Tools/Workflows: Regional knowledge bases; culturally tuned Reaction Classifier; locale-specific safety pathways
- Assumptions/Dependencies: Local clinical partnerships; translation quality; regulatory harmonization
- Sector: Education (Accredited Virtual Clinics and OSCE-style Exams)
- Application: Standardized longitudinal OSCEs and virtual practicums that assess phase alignment, attunement, and strategic flexibility
- Tools/Workflows: Longitudinal scenario authoring tools; calibrated grading models; assessor dashboards
- Assumptions/Dependencies: Accreditation body acceptance; psychometric validation; fairness audits across student groups
- Sector: Health System Workforce Optimization
- Application: Blended-care orchestration (agent handles low-risk sessions/homework; clinicians focus on complex cases)
- Tools/Workflows: Session routing policy; outcome-based triage; utilization dashboards
- Assumptions/Dependencies: Scope-of-practice boundaries; reimbursement alignment; strong escalation rules
- Sector: Public Health at Scale
- Application: Government-run virtual mental health clinics providing longitudinal support in low-resource settings
- Tools/Workflows: Cloud/on-prem hybrids; offline-capable memory; community health worker supervision
- Assumptions/Dependencies: Infrastructure reliability; local language/culture competence; governance and accountability frameworks
- Sector: Insurance/Value-Based Care
- Application: Closed-loop outcome contracts where adaptive therapy switches are tied to measurable improvements
- Tools/Workflows: Outcome registries; contract analytics; audit trails for therapy selection rationale
- Assumptions/Dependencies: Trusted outcome measures; transparent algorithms; appeal/exception processes
- Sector: Human Factors and Trust Science
- Application: Explainable attunement and strategy rationales surfaced to patients (shared decision-making)
- Tools/Workflows: Patient-facing “why this approach” summaries; consent and preference memory
- Assumptions/Dependencies: Usability studies; interpretability that doesn’t mislead; user control over memory
- Sector: Cross-Domain Agent Transfer
- Application: Longitudinal agent pattern applied to education tutors, chronic-disease self-management, customer success, and coaching
- Tools/Workflows: Domain-specific phase models (e.g., assess → teach → practice → mastery); memory of learner/client history; strategy switching
- Assumptions/Dependencies: Domain expertise for phase definitions; outcome metrics; guardrails for harmful advice
- Sector: Standards and Regulation
- Application: Policy frameworks for multi-session conversational agents (documentation, auditing, metric reporting, data retention limits)
- Tools/Workflows: Standardized longitudinal benchmarks; conformance tests for safety and equity; model cards addenda for multi-session behavior
- Assumptions/Dependencies: Multi-stakeholder consensus; periodic third-party audits; legal clarity on liability
Notes on Feasibility and Dependencies (cross-cutting)
- Model and data quality: The paper’s results are based on simulated patients and Chinese counseling cases; real-world effectiveness requires clinical trials and multilingual adaptation.
- Safety and ethics: Always maintain human oversight, crisis escalation, and explicit scope limitations; manage memory with strict consent and retention controls.
- Integration: EHR/FHIR interoperability, identity continuity across sessions, and secure key management for memory stores are non-trivial.
- Bias and generalization: Evaluate for population-specific bias and cultural fit; continuously calibrate Reaction Classifier and therapy selection behaviors.
- Cost and latency: Dual-loop orchestration and long-term memory stores can raise inference costs; caching and distillation may be needed for scale.
Glossary
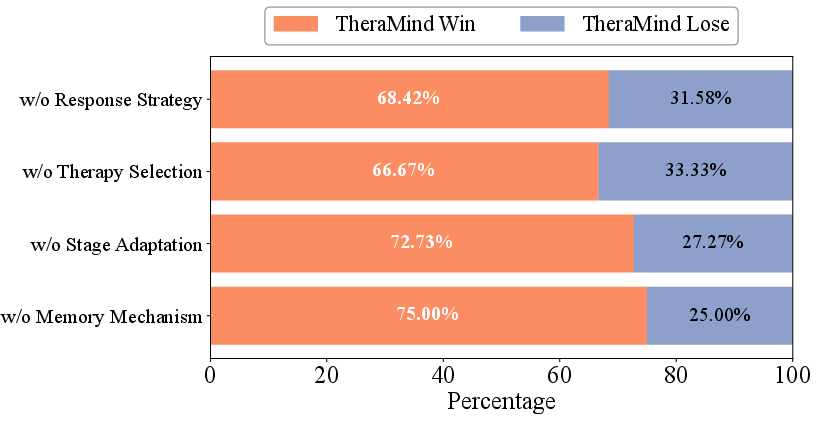
- Ablation study: An experimental method where components of a system are removed or altered to assess their impact on performance. "To validate the contribution of each core component within TheraMind's dual-loop architecture, we conducted an ablation study via pairwise comparison."
- Adaptive Therapy Selection: A mechanism that adjusts the therapeutic method across sessions based on observed efficacy and dialogue history. "Adaptive Therapy Selection"
- Catastrophic forgetting: The tendency of models to lose previously learned information when new information is added, especially with limited context windows. "Standard LLMs with fixed context windows suffer from catastrophic forgetting, undermining trust and therapeutic progress."
- Clinical amnesia: A loss of continuity in therapeutic memory, where past interactions are not retained or leveraged in future sessions. "operate under a paradigm that fundamentally misaligns with the principles of genuine psychotherapy. These systems are predominantly architected for single-session contexts, exhibiting a form of 'clinical amnesia' that prevents them from building upon past interactions."
- Cognitive Behavioral Therapy (CBT): A structured, evidence-based psychotherapy focusing on modifying negative thoughts and behaviors. "single therapeutic modality (e.g., Cognitive Behavioral Therapy)"
- Cohen's kappa: A statistical measure of inter-rater agreement that accounts for chance agreement. "we achieved a Cohen's~ of 0.676"
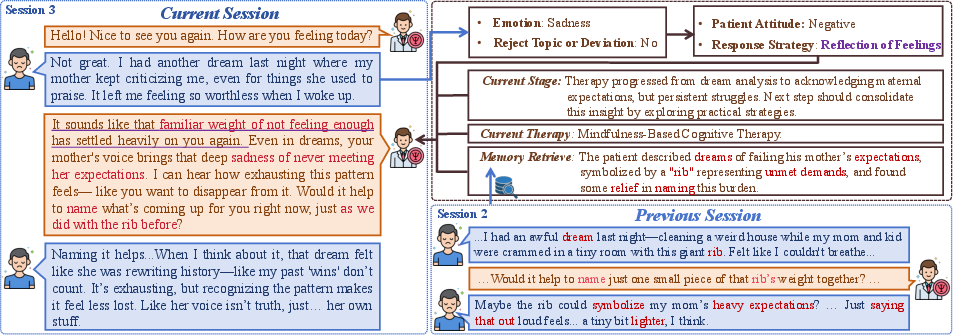
- Cross-Session Loop: The strategic component that evaluates therapy effectiveness after each session and adjusts future methods. "The Cross-Session Loop empowers the agent with long-term adaptability by evaluating the efficacy of the applied therapy after each session and adjusting the method for subsequent interactions."
- Deliberative clinical intervention: A purposeful, strategy-guided therapeutic action rather than a reactive response. "transform response generation from a reactive task into a deliberative clinical intervention."
- Digital twin paradigm: A modeling approach that creates a virtual replica of a patient or process to simulate and adapt therapeutic interactions. "PsyDT \cite{PsyDT} introduces a digital twin paradigm with dynamic one-shot learning and GPT-4âguided synthesis."
- Dual-loop architecture: A design that separates in-session dialogue management from cross-session strategic planning. "The cornerstone of TheraMind is a novel dual-loop architecture that decouples the complex counseling process into an Intra-Session Loop for tactical dialogue management and a Cross-Session Loop for strategic therapeutic planning."
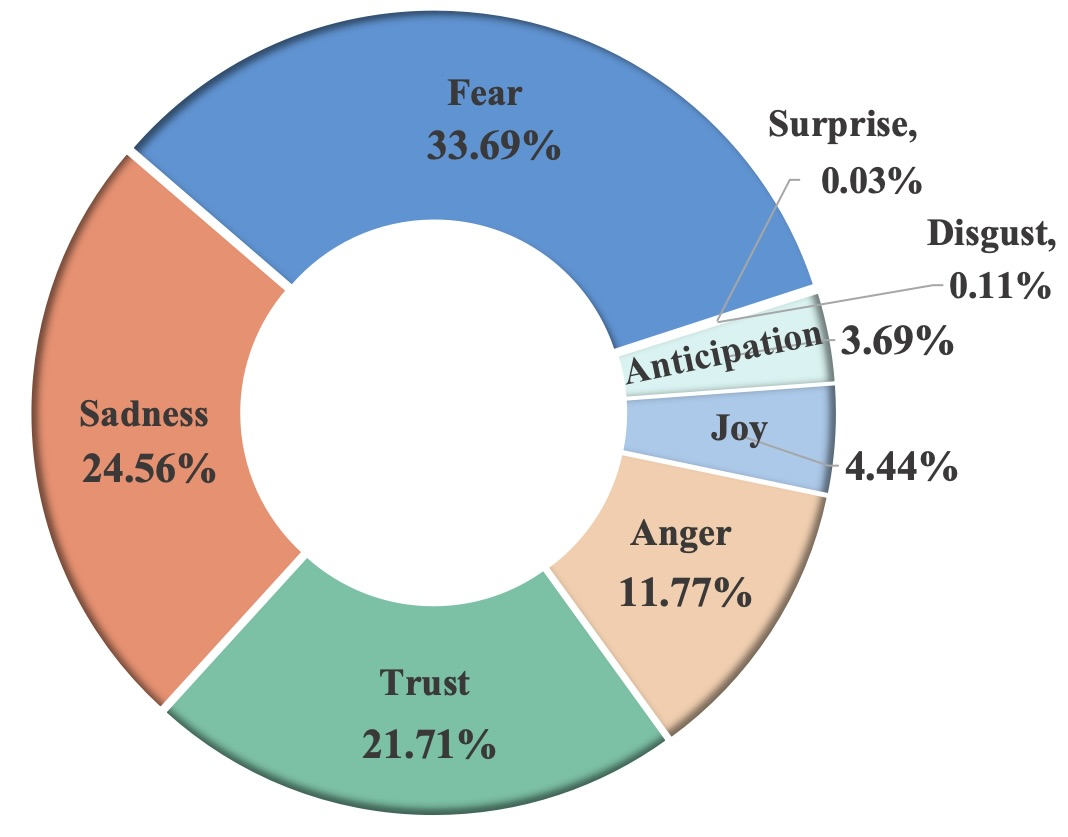
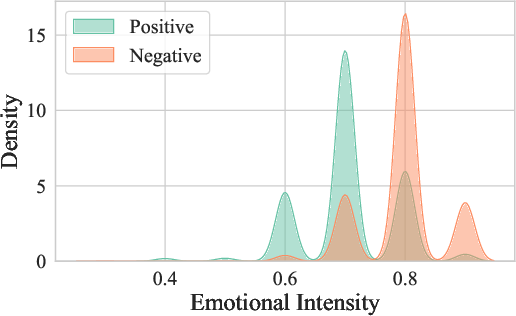
- Kernel Density Estimation (KDE): A non-parametric method to estimate the probability density function of a variable. "Kernel Density Estimation (KDE) plot illustrating the distribution of emotional intensity for conversations categorized by patient attitudes with positive versus negative sentiments."
- LLM-based patient simulator: A system that uses a LLM to simulate patient behaviors and responses for evaluation. "These guides provide the LLM-based patient simulator with coherent goals for each session without rigidly scripting responses."
- Longitudinal psychological counseling: Therapy conducted across multiple sessions, emphasizing continuity and long-term adaptation. "TheraMind, a strategic and adaptive agent for longitudinal psychological counseling."
- Memory-Augmented Contextualization: A mechanism that retrieves and summarizes relevant past information to maintain continuity in dialogue. "Memory-Augmented Contextualization"
- Motivational interviewing: A counseling technique that enhances motivation to change by exploring and resolving ambivalence. "motivational interviewing \cite{Anno-mi}"
- Perception–action loops: Iterative cycles where an agent perceives the environment and acts upon it, enabling complex task execution. "Memory-augmented, context-augmented, and hierarchical architectures allow perceptionâaction loops for complex tasks"
- Preference optimization: Training techniques that optimize model outputs based on human or task-specific preferences. "Beyond SFT, reinforcement learning and preference optimization enhance adaptability."
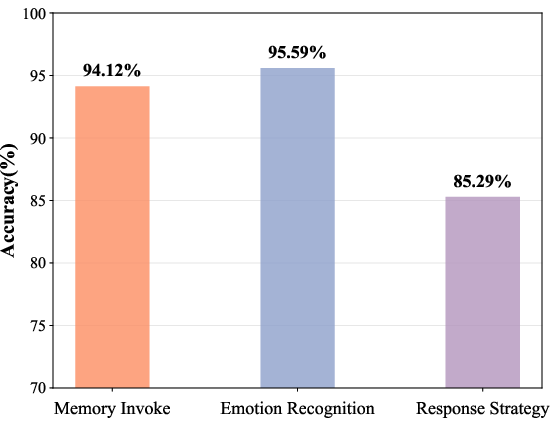
- Reaction Classifier: A model component that infers a structured representation of the patient's emotion, intensity, and attitude from an utterance. "TheraMind employs a Reaction Classifier to infer a structured representation of the patient's immediate psychological state."
- Reinforcement learning (RL): A learning paradigm where agents learn policies by maximizing rewards through trial and error. "COMPEER \cite{COMPEER} applies RL for controllable empathetic reasoning,"
- Stratified sampling: A sampling method that ensures representation across predefined categories or strata. "This stratified sampling approach ensures our agent is evaluated across a wide spectrum of psychological issues."
- Supervised fine-tuning (SFT): Training an LLM on labeled data to adapt it to specific tasks or domains. "Recent efforts adapt LLMs through supervised fine-tuning (SFT) on counseling data."
- Therapeutic alliance: The collaborative relationship between therapist and patient, including agreement on goals, tasks, and bond. "Counseling dialogue systems are conversational agents for mental health that emphasize empathy, therapeutic alliance, and safety beyond task-oriented systems"
- Therapeutic Attunement: The alignment of interventions with the patient’s current treatment phase and subtle progress signals over time. "The performance gains are particularly pronounced in multi-session metrics such as Coherence, Flexibility, and Therapeutic Attunement"
- Therapeutic modality: A specific, structured approach or framework used in therapy. "single therapeutic modality (e.g., Cognitive Behavioral Therapy)"
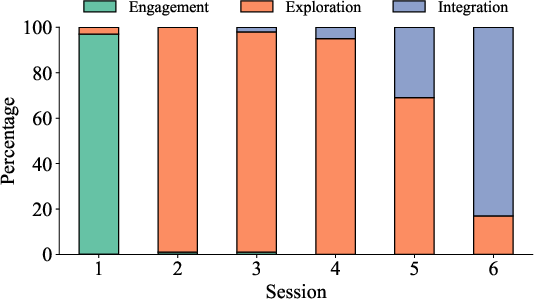
- Therapeutic phase: A stage within a treatment method that guides appropriate interventions during a session. "the current therapeutic phase is identified based on the session's overarching therapy method and the dialogue history in the current session :"
- Working Alliance Inventory (WAI): A standardized instrument for assessing the strength of the therapeutic alliance. "Based on the Working Alliance Inventory (WAI) framework"
Collections
Sign up for free to add this paper to one or more collections.

