- The paper introduces the DPI bound that quantifies information loss across iterative closed-system LLM reasoning steps.
- The methodology rigorously partitions multi-step debate protocols using Markov closure criteria and reveals significant Supported Faithfulness Score drops.
- The study demonstrates that external evidence injection, as in EGSR, recovers reasoning faithfulness and challenges accuracy-based evaluations.
The paper "The Reasoning Trap: An Information-Theoretic Bound on Closed-System Multi-Step LLM Reasoning" (2605.01704) develops a systematic theory addressing why multi-agent debate (MAD) protocols involving copies of the same LLM degrade reasoning faithfulness even as answer accuracy is preserved. The central theoretical claim is formalized as the DPI (Data Processing Inequality) Bound: In a closed-system Markov chain, where agent outputs are iteratively conditioned only on prior outputs and shared model parameters without re-injecting external evidence, the expected mutual information between evidence and agent outputs is non-increasing across steps.
The authors define reasoning faithfulness quantitatively as mutual information I(E;Ot) between the evidence E and the agent outputs Ot, and introduce the Supported Faithfulness Score (SFS) — a claim-level metric grounded in atomic decomposition and external verification against evidence. SFS is constructed to be decomposer-invariant (condition-level Spearman ρ=1.0 for GPT-4o/Claude decomposers) and operationalizes reasoning process-level measurement, not just correctness of the answer.
The analysis rigorously partitions closed-system multi-step reasoning protocols using four Markov closure criteria: shared parameters, single evidence injection at initialization, sequential dependency on prior agent outputs, and symmetric aggregation. Any protocol satisfying these is provably subject to the DPI bound:
E[I(E;Ot+1)]≤E[I(E;Ot)]
with strict inequality for vote-aggregation/summary protocols. This structural result holds for multi-agent debate, token-Markov CoT, Reflexion, and linear ToT; paradigms such as self-consistency and mixture-of-experts violate the closure and are outside scope (Figure 1).
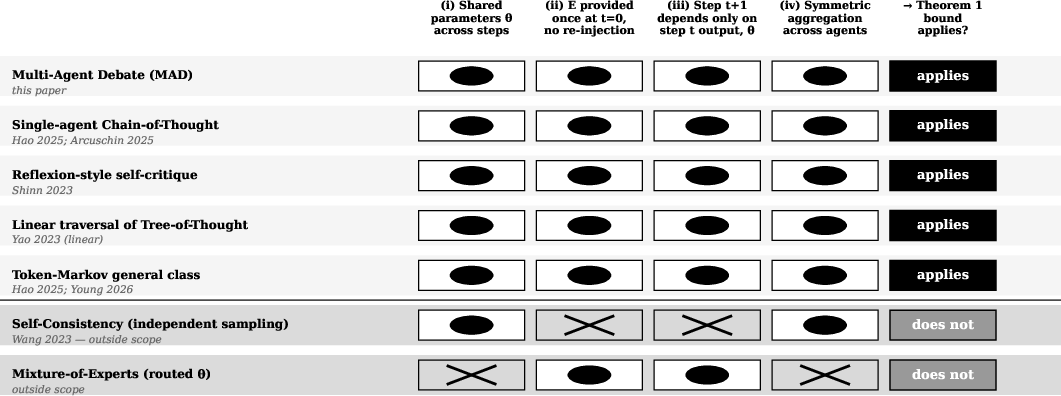
Figure 1: The scope of the DPI bound, showing which reasoning paradigms satisfy the four closure criteria and inherit the information-theoretic ceiling.
Empirical Evidence and Diagnostic Metrics
A comprehensive evaluation is conducted over 16 protocols (including SocraSynth debate, majority-vote MAD, EGSR variants, and ablations) across 18,430 trials on SciFact and FEVER datasets, using GPT-4o and Claude-3.5-Sonnet. The main result is a three-tier spectrum of evidence-grounded reasoning degradation:
- Reasoning degradation: e.g., SocraSynth debate (C4) yields a 39% SFS drop with only minor accuracy loss.
- Debate Trap proper: DebateCV configuration (C13) preserves 88% of baseline accuracy but SFS drops by 43%.
- Reasoning elimination: Majority-vote MAD (C15) reduces SFS to 1.7% of baseline, despite ∼54% accuracy retention.
EGSR (Evidence-Grounded Socratic Reasoning), an open-system protocol that injects external evidence at each verification step, recovers SFS to within 98% of baseline, demonstrating a constructive mechanism for breaking the Markov chain and restoring faithfulness.
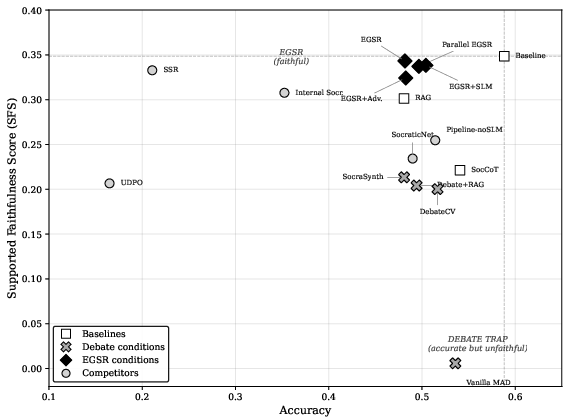
Figure 2: Scatterplot of accuracy vs. SFS. MAD variants (X markers) cluster with high accuracy yet low SFS; EGSR variants (diamond markers) retain SFS near baseline, illustrating the Debate Trap.
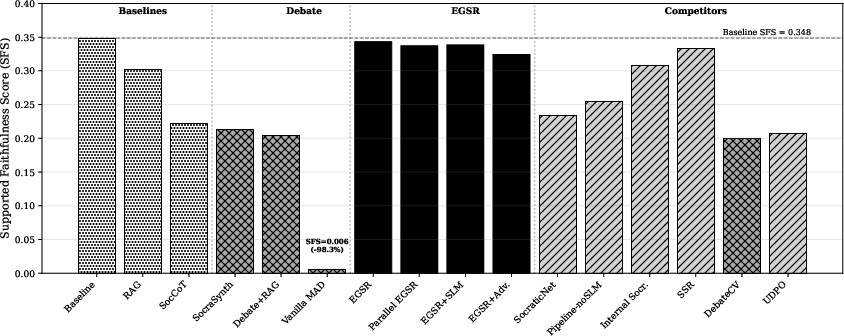
Figure 3: SFS across conditions, revealing three distinct levels of faithfulness degradation: reasoning degradation, Trap proper, and reasoning elimination. EGSR variants (C8, C9, C12, C14) recover near baseline SFS.
Human Reliability and Calibration Evidence
A cross-language cohort study (R6) involving 11 raters (Korean and English) uncovers triple failure of human reliability in faithfulness assessment. Fleiss κ≤+0.018 for Likert-5 scores; pairwise Cohen's κ for binary unsupported-claim flags peaks at +0.583. Intra-rater shifts (same rater, different language/domain) reach 0.8–1.4 Likert points and 28–47 percentage points, exceeding typical inter-rater variance. The calibration target, against which prior faithfulness metrics have been tuned, is empirically unstable and insufficient for reliable measurement.
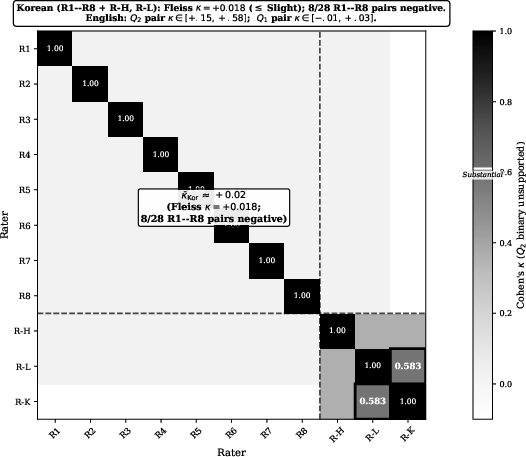
Figure 4: Pairwise Cohen's κ matrix for 11 raters; Korean cohort clusters near zero, no pair shows substantial agreement.
Theoretical Implications and Practical Partition
The DPI Bound establishes a fundamental limit on internal regeneration of evidence-grounded reasoning in closed-system protocols. Vote aggregation further compresses the available information to E0 bits regardless of evidence entropy, and reasoning content disappears as outputs are reduced to verdicts. EGSR, by re-injecting evidence, forms a sub-martingale; faithfulness strictly increases or is preserved at each step.
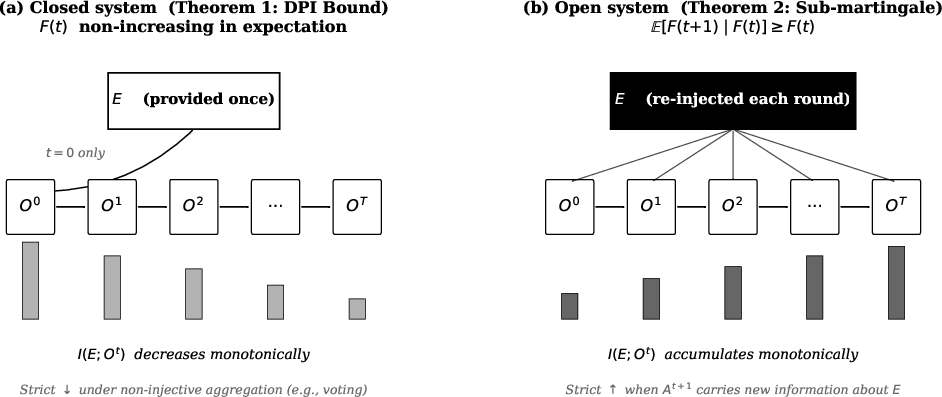
Figure 5: Information flow diagrams for closed-system (DPI bound, faithfulness decreases) versus open-system EGSR (faithfulness accumulates).
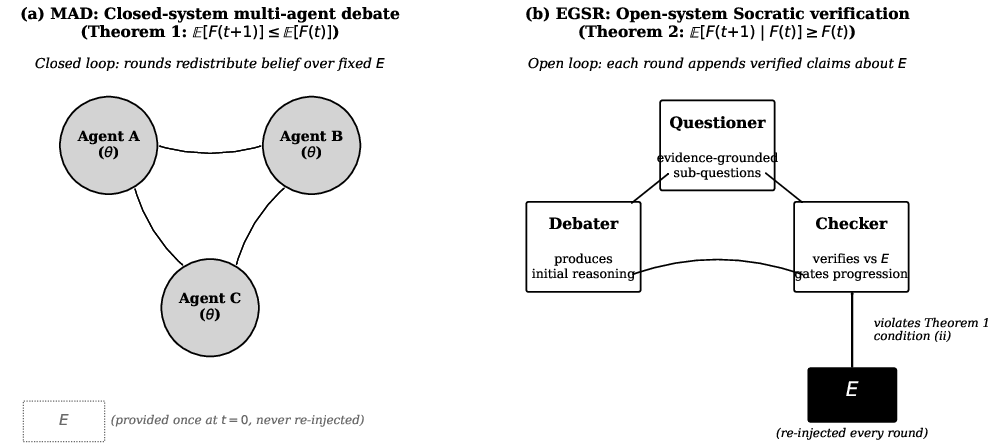
Figure 6: Architectural comparison—MAD (closed loop among agents) vs. EGSR (open loop, evidence re-injected at each verification step).
Implications for Evaluation and Future Directions
Accuracy-based evaluation in MAD protocols fails to detect substantial reasoning trap-induced degradation. The authors recommend explicit faithfulness reporting and condition-level declaration of Markov closure satisfaction in multi-agent systems. EGSR's external evidence injection provides a reliable pathway to process-level faithfulness recovery, but is not an answer-maximizing protocol. The findings simultaneously challenge the premises of debate-based scalable oversight proposals and call for a shift from answer correctness to defensible reasoning.
The DPI framework is argued to be a general ceiling for any closed-system reasoning protocol; open questions remain on how to achieve transformational creative reasoning, and whether AI systems trained via autoregressive next-token prediction can escape the information bottleneck without external anchoring.
Conclusion
The paper provides a unified metric–algorithm–theorem framework for diagnosing and remedying reasoning faithfulness degradation in multi-agent LLM debate. The DPI Bound serves as a falsifiable structural limitation: accuracy can be preserved while reasoning faithfulness collapses, unless external evidence is injected. EGSR demonstrates that protocol-level design—not contingent training tricks—determines faithfulness recovery. Human calibration is insufficient; decomposer-invariant operational measures are preferable. Future multi-step LLM designs should explicitly address information-theoretic relationships with evidence and report faithfulness alongside accuracy.
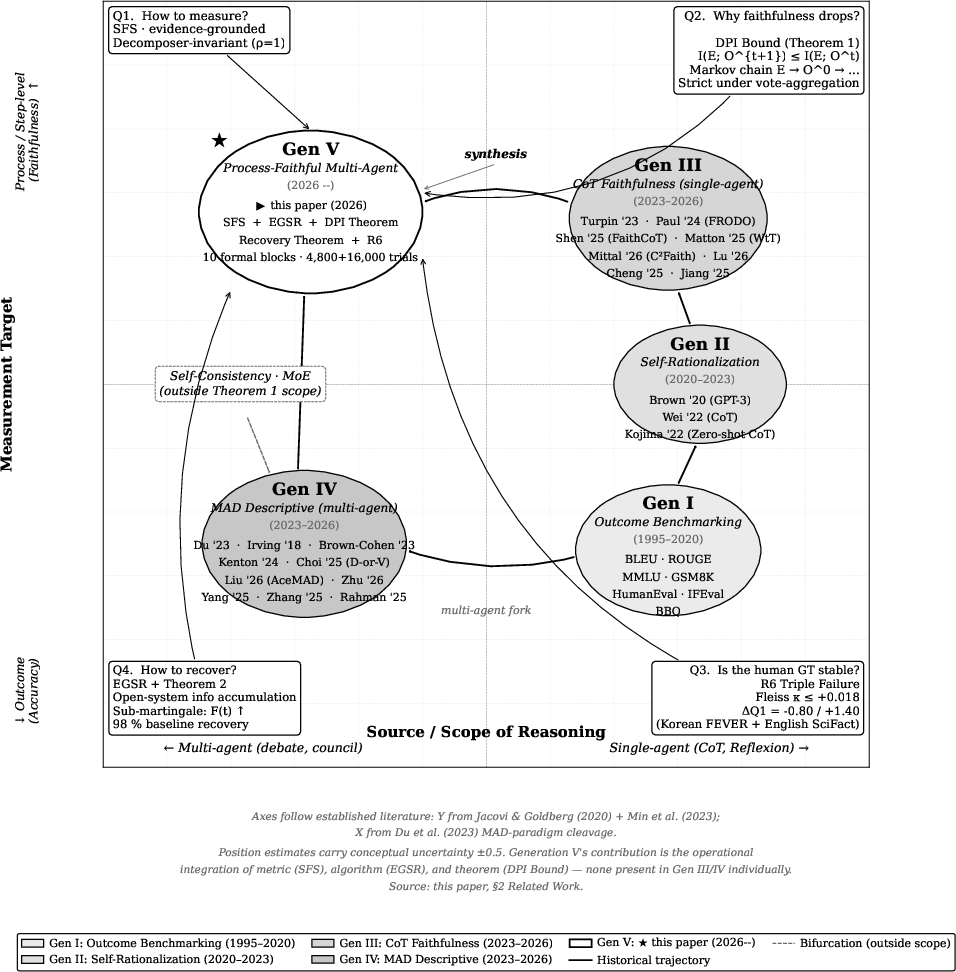
Figure 7: Generational map of reasoning faithfulness research; Generation V integrates metric (SFS), algorithm (EGSR), and theorem (DPI Bound), partitioning reasoning protocols by their information-theoretic relationship to evidence.

