- The paper introduces a modular, staged pipeline that decodes EEG signals into 3D object meshes, achieving up to 85.4% top-1 EEG decoding accuracy.
- It integrates diffusion-guided EEG-to-image decoding with geometry-aware semantic reasoning and stable generative modeling for robust 3D reconstruction.
- Rigorous evaluation on the EEGCVPR40 dataset shows improved semantic alignment and perceptual metrics compared to traditional direct image-to-3D methods.
Multimodal EEG-to-3D Decoding: Architecture and Evaluation of Brain3D
Introduction
The reconstruction of visual content from neural signals is of central importance in neural decoding, BCI, and computational neuroscience. While prior work has focused largely on EEG-to-image pipelines, the extension to 3D object synthesis introduces additional challenges related to spatial structure and viewpoint consistency. "Brain3D: EEG-to-3D Decoding of Visual Representations via Multimodal Reasoning" (2604.08068) presents a staged, multimodal architecture advancing the state of EEG-driven visual decoding by bridging neural activity with structured 3D mesh generation. The approach leverages cross-modal alignment, geometry-aware semantics, and diffusion-based generative modeling to convert EEG trials into object-centric, semantically consistent 3D representations.
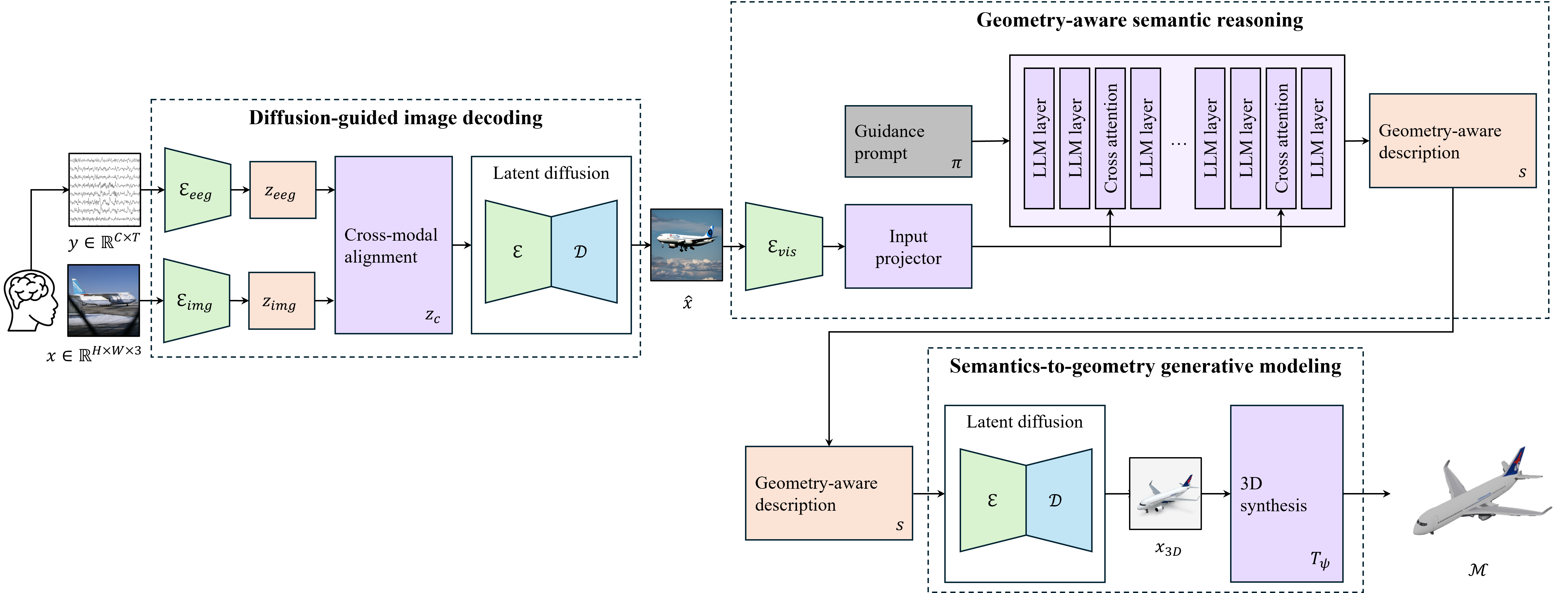
Figure 1: Brain3D’s staged pipeline for EEG-to-3D generation, consisting of EEG-to-image decoding, geometry-aware semantic reasoning via MLLM, and semantic-to-geometry generative modeling.
Brain3D Pipeline: Modular Multimodal Stages
The Brain3D pipeline decomposes the neural-to-geometry mapping into three independent but sequential stages:
- Diffusion-Guided EEG-to-Image Decoding: EEG trial data are processed via neural and visual encoders into a shared latent space. Cross-modal alignment projects neural features into the conditioning space of a diffusion image generator. The output is a visually grounded image reflecting stimulus semantics.
- Geometry-Aware Semantic Reasoning with MLLM: The decoded image is fed to a Vision-LLM (LLaMA 3.2 Vision 90B), which extracts object-centric prompts, emphasizing shape, material, and 3D structure. Prompting is engineered to suppress background and focus purely on the main object, yielding descriptions optimized for downstream 3D generative modeling.
- Semantics-to-Geometry Generative Modeling: A Stable Diffusion 3.5 Medium model generates refined images from the semantic prompt. These are subsequently converted into 3D meshes using the Microsoft TRELLIS single-image-to-3D network, reconstructing volumetric geometry consistent with the semantic and visual input.
This modular design avoids direct EEG-to-3D mapping, enhancing stability and broadening compatibility with diverse EEG-to-image methods.
Quantitative and Qualitative Evaluation
The EEGCVPR40 dataset is used for evaluation, encompassing 2,000 EEG/image pairs across 40 object categories. Successful decoding is rigorously quantified using Top-k n-way accuracies, CLIPScore, LPIPS, FID, and IS, with both semantic and perceptual alignment against original stimulus images and against intermediate EEG-to-image reconstructions.
Key outcomes:
- The pipeline achieves up to 85.4% 10-way Top-1 EEG decoding accuracy and 0.648 CLIPScore using the GWIT backbone—a substantial margin over earlier EEG-to-3D approaches.
- Semantic retrieval and generative fidelity correlate strongly with the quality of the intermediate EEG-to-image stage, evident in GWIT's performance on 3D mesh reconstruction.
- The semantic reasoning and generative modeling modules provide substantial improvement: ablation studies show increases of up to +0.018 in 10-way Top-1 accuracy and significant decreases in FID (e.g., GWIT: −30.27 compared to direct image-to-3D baseline).
- Cross-model compatibility demonstrates model-agnostic integration, where Brain3D can deploy with GWIT, BrainVis, EEG-CLIP, and DreamDiffusion backbones while preserving semantic consistency.
Figure 2: Qualitative reconstructions from Brain3D across object categories, showing ground-truth stimulus, EEG-to-image outputs, and resulting 3D meshes.
Qualitative results reinforce quantitative metrics: well-decoded categories (e.g., camera, parachute, elephant) display high-fidelity mesh structure and semantic alignment. Failure cases arise primarily from weak EEG-to-image stages, underscoring the importance of upstream decoding accuracy.
Implications and Future Directions
The staged, multimodal reasoning architecture enables robust EEG-driven 3D object reconstruction, offering implications for BCI interfaces, cognitive neuroscience, and embodied AI:
- Practical Implications: The approach is readily extensible to XR, robotics, and simulation domains requiring spatially coherent object representations from neural signals. The model-agnostic pipeline permits rapid adaptation to new EEG decoding advances.
- Theoretical Implications: Decoupling neural decoding from geometry modeling facilitates detailed analysis of intermediate representations, revealing bottlenecks (primarily EEG-to-image stage) and guiding future improvements in cognitive modeling.
- Future Development: Prospects include scaling to scene-level 3D reconstruction, incorporating temporal dynamics for animated 3D decoding, and integrating more advanced foundation models (e.g., multimodal LLMs) for richer semantic extraction. Advances in high-resolution, single-shot 3D generation and more precise EEG decoding will further increase geometric fidelity and semantic alignment.
Conclusion
Brain3D establishes a robust, modular architecture for EEG-to-3D decoding through multimodal reasoning, enabling the translation of neural signals into semantically consistent 3D object meshes. Strong quantitative gains and qualitative fidelity are achieved across multiple EEG-to-image backbones. The modular pipeline accentuates the importance of high-quality visual decoding for downstream geometric synthesis and provides a scalable foundation for future research in brain-driven visual generation. The separation and refinement stages inherent to Brain3D yield improved object-level semantics and generative quality, with demonstrated resilience to noise and ambiguity in neural signal reconstruction.

