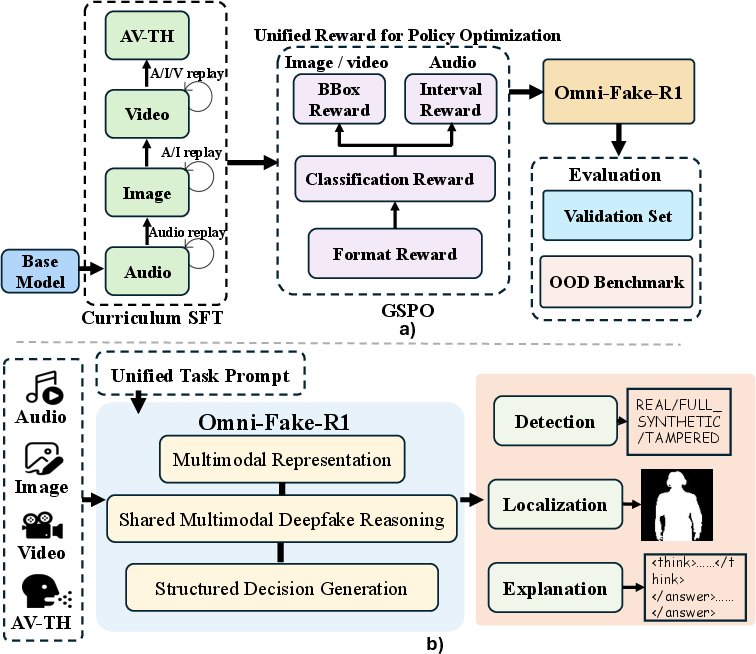
- The paper introduces Omni-Fake, a comprehensive multimodal benchmark and detection model for deepfake detection across images, audio, video, and talking-head content.
- The paper employs a four-stage curriculum SFT with modal replay and unified GSPO reinforcement learning, achieving state-of-the-art performance with a 95.54% detection F1 for talking-heads.
- The paper demonstrates robust performance under real-world corruptions and delivers interpretable, granular explanations, making it highly relevant for digital forensics and content moderation.
Introduction and Motivation
The proliferation of highly realistic, AI-generated multimodal content on social media platforms has escalated authenticity verification challenges, particularly as generative technologies become more sophisticated across images, audio, videos, and talking-head avatars. Existing detection benchmarks are constrained by their limited modality scope, overly simplistic manipulation schemes, and unrealistic distributional assumptions, resulting in suboptimal robustness and generalization when deployed in the wild. The "Omni-Fake" benchmark and the accompanying Omni-Fake-R1 detection model represent a systematic response to these limitations by advancing a unified, comprehensive testbed and a single, scalable model for multimodal deepfake detection, localization, and explanation.
Benchmark Design: Omni-Fake Dataset
Omni-Fake is constructed to address the critical need for a realistic, large-scale, and multimodal evaluation suite. The dataset provides coverage along four modalities—image, audio, video, and audio-visual (AV) talking-head videos—systematically annotated under unified detection, localization, and explanation protocols. It is composed of two primary splits:
- Omni-Fake-Set: Contains over 1M in-distribution samples curated from a diverse pool of more than 30 generative and manipulation methods.
- Omni-Fake-OOD: Contains over 200K fully disjoint samples, intentionally excluding any overlap in generators or manipulation techniques with Omni-Fake-Set, designed to rigorously evaluate out-of-distribution (OOD) generalization.
The label taxonomy is modality-comprehensive: real, partially manipulated (tampered), and fully synthetic for images, audio, and video; binary labels (real vs. fake) for talking-head AV content. Fine-grained spatial and temporal localization (e.g., bounding boxes, temporal intervals) is included whenever possible.
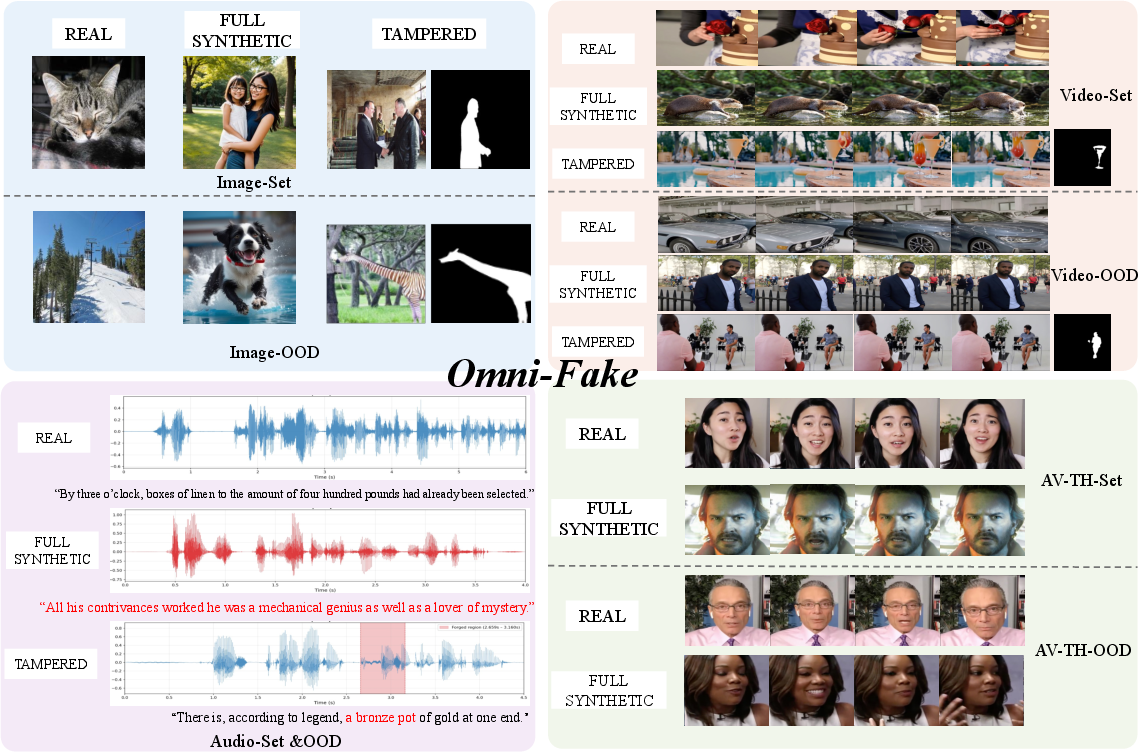
Figure 1: Diversity and quality of multimodal forgeries in social media scenarios from Omni-Fake.
Highly perceptual data quality across modalities is empirically validated by automatic metrics (FID, FVD, PESQ, etc.) and human evaluations. Rigorous balancing in class distributions and generator diversity between the Set and OOD splits is confirmed to avoid spurious shortcut exploitation.
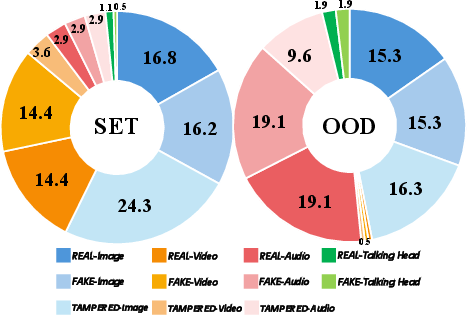
Figure 2: Label distribution of REAL, FULL SYNTHETIC, and TAMPERED samples across all modalities and splits in Omni-Fake, demonstrating broad coverage and balanced structure.
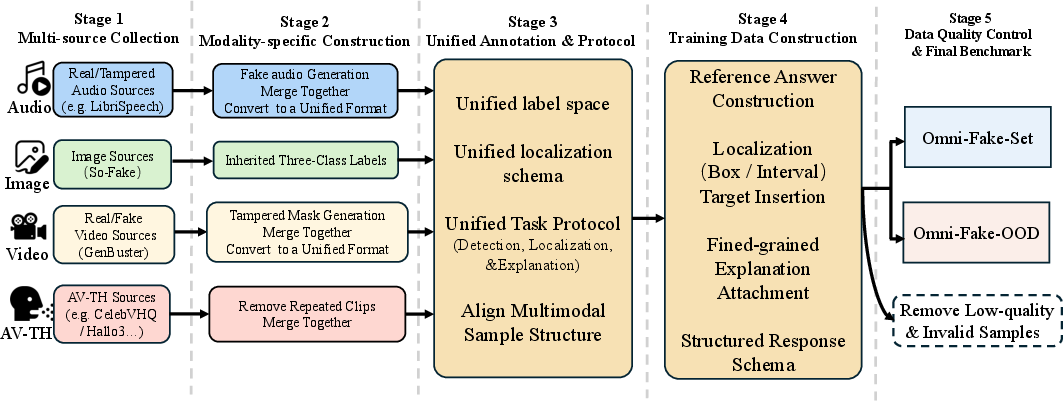
Figure 3: The Omni-Fake data pipeline unifies multimodal training protocols and supports high-quality OOD benchmark construction, facilitating trustworthy evaluation.
Unified Detection Framework: Omni-Fake-R1
The Omni-Fake-R1 model advances unified multimodal detection using a single Qwen2.5-Omni-7B foundation, outputting a structured triple per input: authenticity label, precise spatial/temporal localization, and a natural-language rationale. Key innovations in Omni-Fake-R1 include:
Experimental Results
Omni-Fake-R1 is comprehensively evaluated against strong single-modality and multimodal state-of-the-art (SOTA) baselines across all four modalities, both in- and out-of-distribution.
In-Distribution Results
On images, videos, audio, and AV talking-head tasks, Omni-Fake-R1 demonstrates the highest or on-par detection accuracy and F1 scores, while consistently outperforming all baselines in localization performance—IoU and localization F1—where ground truth exists. For AV talking-heads, detection F1 reaches 95.54%, establishing robustness with high inter-modality output consistency.
Out-of-Distribution Robustness
Performance drop from Set to OOD splits is substantial for legacy baselines, particularly those trained on isolated or paired modalities; however, Omni-Fake-R1's unified protocol yields the strongest OOD generalization, especially evident in high-maintenance of localization and detection metrics, underscoring resilience to generator and content distributional shift.
Robustness to Channel Corruptions
The model preserves high overall localization and detection accuracy under real-world post-processing (JPEG compression, blur, random rescale, and additive noise), with marginal degradation, indicating robust invariance vital for deployment on noisy or platform-recompressed social media content.
Ablation Studies
Systematic ablation demonstrates:
- Curriculum SFT with replay substantially outperforms naïve mixing or single-modality SFT, both by reducing forgetting and facilitating inter-modal knowledge transfer.
- Unified GSPO RL for detection-localization-explanation consistently improves across all evaluation axes compared to SFT-only or RL-only baselines.
Explanation Quality
Omni-Fake-R1 reaches highest semantic similarity (CSS) and ROUGE-L scores between generated and reference explanations across modalities. Human expert evaluations confirm that rationales are both factually correct and informative for forensics, with little variance, underscoring interpretability and transparency—qualities critically needed for downstream moderation and forensic workflows.

Figure 5: Case studies for image forgeries: detection, bounding box localization, and textual explanations illustrate model grounding and fine-grained reasoning.

Figure 6: Video tampering detection and region localization, with detailed explanations, exemplify temporal localization capabilities.
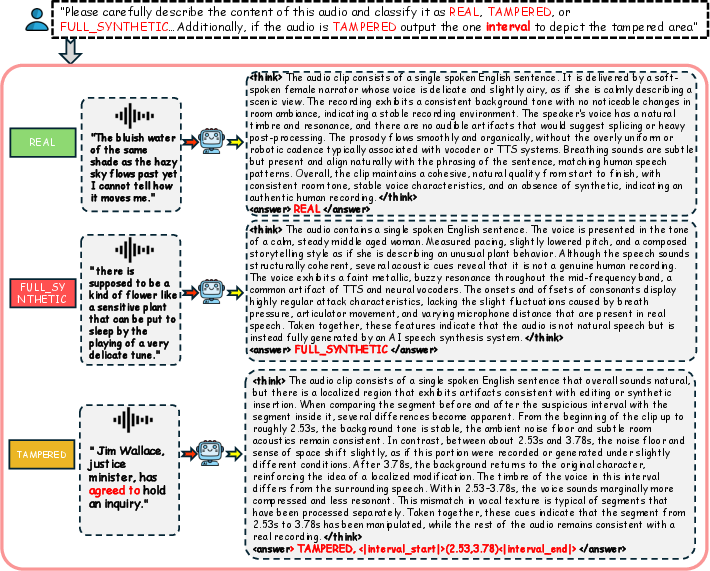
Figure 7: Audio deepfake case analysis, highlighting forged temporal intervals and corresponding textual rationales.

Figure 8: AV talking-head deepfake detection: model outputs leverage audio-visual consistency for comprehensive explanation.
Implications and Prospects
The Omni-Fake benchmark constitutes a comprehensive testbed for multimodal deepfake detection research. The combination of in-distribution and OOD data with unified localization and explanation annotations enables rigorous, realistic benchmarking and exposes vulnerabilities in current modeling paradigms. Omni-Fake-R1's reinforcement-learning alignment across detection, localization, and explanation demonstrates that end-to-end unified optimization is feasible and delivers consistent cross-modality improvements in both robustness and interpretability.
From a practical perspective, this research lays a robust foundation for multimodal forensics on social media at scale. The structured, explainable outputs open doors for integration within content moderation, digital forensics, and even legal workflows where evidence transparency is essential.
Theoretically, the work pushes the frontier of unified multimodal representation learning, demonstrating that curriculum strategies with explicit replay and structured RL objectives can alleviate cross-modal interference and catastrophic forgetting, paving the way for extension to additional modalities (e.g., 3D avatars, code-switched audio, or richer multimodal narratives) and broader generalization.
Conclusion
Omni-Fake sets a new bar for benchmarking and developing unified deepfake detection systems at web scale. The Omni-Fake-R1 model, trained with curriculum SFT and GSPO RL, achieves SOTA performance across detection, localization, and explanation, with exceptional OOD generalization and robustness. These results strongly support the adoption of unified, explainable multimodal approaches for trustworthy and practical AI-driven media forensics, and point to promising directions for further expanding modality coverage and maintaining benchmark relevance as generative media technology evolves.