- The paper introduces Verbal-R3, a novel method that integrates analytic Verbal Annotations to explicitly connect retrieval and reasoning processes.
- It employs a two-agent framework with a Generator and a Verbal Reranker using GRPO and relevance-guided scaling for efficient multi-hop QA.
- Empirical evaluations across seven QA benchmarks reveal significant gains, including a +17.1% EM improvement and over 45% reduction in inference FLOPs.
Verbal-R3: Agentic RAG via Verbal Reranking and Analytic Narratives
Introduction and Motivation
Retrieval-Augmented Generation (RAG) offers a methodology for addressing limitations in parametric LLM knowledge—namely training data cutoffs and hallucinations—by incorporating retrieved external content. However, the canonical pipeline of directly injecting raw retrieved passages into the LLM context is inherently suboptimal. This arises from exposure bias, distributional shift compared to pretraining, and distractive noise, all of which degrade downstream reasoning and answer generation.
The Verbal-R3 framework (2605.01399) is introduced as an agentic RAG system that actively bridges the gap between retrieval and reasoning by integrating a novel class of analytic narratives termed Verbal Annotations. These are concise, logical explanations that articulate the explicit relationship between a query and retrieved contexts. The study demonstrates that such analytical, human-interpretable annotations significantly improve information integration and the factual reliability of LLM-generated answers, a finding empirically supported by comparative evaluation.

Figure 1: Comparison of conventional RAG and Verbal-R3 pipelines; Verbal Annotations filter irrelevant information, reducing hallucination and increasing answer correctness.
System Architecture and Methodology
Verbal-R3 employs a two-agent configuration: a Generator and a Verbal Reranker. The Generator is responsible for iterative search-query formulation and multi-turn reasoning, while the Verbal Reranker provides both pointwise relevance scores and natural language Verbal Annotations for each candidate document.
Training Workflow
- Verbal Reranker Distillation: Query-document-annotation triplets are synthesized using a large teacher LLM (GPT-OSS-120B), then distilled into compact student models (1.5B/3B parameters) via supervised fine-tuning for inference tractability.
- Generator Alignment: The Generator is aligned to optimally leverage Verbal Annotations using Group Relative Policy Optimization (GRPO), yielding strong integration between retrieval evaluation and multi-hop reasoning dynamics.
Relevance-Guided Test-Time Scaling
Inference is further optimized via a test-time scaling policy that uses Verbal Reranker's relevance scores to focus compute allocation on the most promising reasoning paths. This mechanism enables aggressive pruning of unproductive trajectories without sacrificing accuracy, achieving high computational efficiency in multi-trajectory RAG.

Figure 2: Relevance-guided test-time scaling of reasoning branches; relevance scores steer resource allocation to high-utility search directions.
Prompting Protocols
Prompt templates are carefully engineered for naive document injection, paraphrased context, and Verbal Annotations in the distillation pipeline; this ensures that the quality of annotations is both logically discriminative and efficiently scalable.

Figure 3: Prompt template for naive context injection.

Figure 4: Prompt template for paraphrased context creation.

Figure 5: Prompt template for structured Verbal Annotations and scoring with the Verbal Reranker.

Figure 6: Generator prompt template for structured reasoning and search query emission.
Empirical Results and Analysis
Extensive experiments on seven QA benchmarks (2Wiki, Bamboogle, HotpotQA, MuSiQue, NQ, PopQA, TriviaQA) show the following key outcomes:
- Performance Gains: Verbal-R3 achieves the highest EM and F1 on all evaluated datasets, outperforming competitive iterative RAG baselines such as Search-R1, IRCoT, and ITER-RETGEN by a wide margin (e.g., +17.1% EM over Search-R1 3B at equivalent model scale).
- Ablation Findings: While naive paraphrasing of context is detrimental, Verbal Annotations yield marked improvements in both final answer correctness and context utilization efficacy metrics (CUE). This directly validates the hypothesis that analytic, logically-structured narratives are a superior modality for mediating the retrieval-reasoning handshake.
- Multi-hop QA: Performance improvements from Verbal Annotations are most pronounced in multi-hop regimes, suggesting that filtering irrelevance/noise in complex, multi-turn retrieval chains is essential for deep reasoning.
- Computational Efficiency: Relevance-guided test-time scaling achieves comparable or better accuracy than majority-voting approaches while reducing reranker calls and inference FLOPs by >45%. This scaling protocol ensures Verbal-R3 maintains a favorable cost-performance operating point compared to both naive and brute-force alternatives.
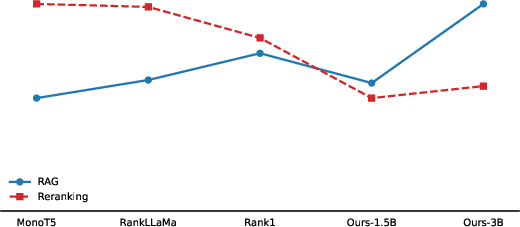
Figure 7: Disparate trends between reranking benchmarks and RAG integration underscore the necessity of evaluating rerankers in true end-to-end contexts.

Figure 8: Template for LLM-as-a-judge prompts used in retrieval accuracy evaluation.
Theoretical Implications and Future Directions
Verbal-R3 demonstrates that the main limiting factor in RAG architectures is not solely the quality of the retriever or the generative model, but the absence of a logico-linguistic layer that makes explicit the mapping from query to evidence. By formalizing this bridge via Verbal Annotations, the system both increases interpretability and minimizes context dilution and exposure bias.
This framework opens several avenues for further work:
- Scaling Up: As LLMs and retrievers scale, compact rerankers continue to deliver favorable marginal improvements with diminishing computational overhead.
- Generalization Beyond QA: The method has direct implications for agentic frameworks in science QA, legal reasoning, and task-specific open-domain assistants where strong interpretability and high-fidelity sourcing are mandatory.
- Integration with Real-Time Retrieval: Although the current study uses offline datasets, integrating the Verbal Reranker with live search (web-scale retrievers) and integrating confidence estimation could address error propagation and dynamic information coverage.
- Interpretability and Model Critique: By making the logical chain between question, evidence, and answer explicit, Verbal-R3 enhances traceability and auditability, thus contributing to trustworthiness in high-stakes applications.
Conclusion
Verbal-R3 (2605.01399) empirically and architecturally establishes that Verbal Annotations, synthesized via a compact Verbal Reranker, are critical for bridging retrieval and reasoning in agentic RAG. By refining the interface between retrieved data and LLM reasoning with structured, analytic narratives, and by optimizing inference through relevance-guided scaling, Verbal-R3 achieves state-of-the-art robustness and efficiency on complex multi-hop QA. The work provides both theoretical insight and a practical recipe for constructing highly controllable, interpretable RAG agents for knowledge-intensive NLP tasks.