- The paper introduces MCM-AVQA, a framework leveraging explicit auditory and visual confidence to dynamically fuse multimodal information.
- It employs a Swin Transformer and VGGish with specialized confidence modules, achieving high PLCC and SROCC across standard AVQA benchmarks.
- It demonstrates robustness to asymmetric distortions, offering scalable quality assessment for complex real-world streaming and teleconferencing scenarios.
Multimodal Confidence Modeling in Audio-Visual Quality Assessment
Introduction
Audio-visual quality assessment (AVQA) is crucial in streaming, teleconferencing, and immersive media applications. Real-world AV experiences frequently involve asymmetric distortions: one modality may undergo significant degradation while the other remains largely undisturbed. Human perceptual studies confirm that subjective judgments of AV quality are informed by relative modality reliability, rather than simple pooling strategies. Despite advances in deep learning for AVQA, most prior methods neglect explicit modeling of modality-specific confidence, leading to suboptimal fusion when modalities are asymmetrically degraded.
The paper "Multimodal Confidence Modeling in Audio-Visual Quality Assessment" (2605.01219) introduces MCM-AVQA, a framework that estimates per-modality confidence and injects these signals into the fusion process at the feature level to robustly aggregate audio and visual information in the presence of varied distortions.
Model Architecture and Confidence Estimation
MCM-AVQA is architected to propagate explicit audio and visual confidence estimates into the multimodal fusion pipeline. The system comprises several key components: unimodal encoders, dedicated confidence modules, and a confidence-aware Audio-Visual Mixer designed to modulate modality interaction at the feature level.
Each video frame is processed by a Swin Transformer backbone to extract hierarchical visual features, while VGGish transforms audio into a compact embedding. Visual confidence is inferred using the Multiple Visual Artifact Detector (MVAD), which computes per-frame probabilities of K=10 artifact types. Temporal convolution and multi-head MLPs convert these probabilities into temporally smoothed, clip-level confidence scores. Audio confidence is estimated from SCOREQ-based no-reference speech quality cues, providing a scalar per-clip representation normalized to [0,1]. Both confidence signals are injected downstream in the fusion process to dynamically modulate the reliability given to each modality.
Figure 1: Overall architecture of MCM-AVQA. Swin and VGGish encode the video and audio streams, while specific modules estimate visual and audio confidences. The confidence-aware Audio-Visual Mixer then modulates cross-modal attention before predicting the overall audio-visual quality.
Confidence-Aware Cross-Modal Fusion
The core innovation is the Audio-Visual Mixer (AVM), which leverages modality-specific confidence to control cross-modal feature attention. Given visual feature maps and audio embeddings, the AVM gates visual keys using the learned visual confidence, and forms audio queries by concatenating confidence with audio features. A channel-wise attention mechanism, controlled by both audio and visual confidence, is then applied to each spatial channel of the visual feature map. This enables channel-specific emphasis or suppression of either modality depending on their estimated reliability.
This architecture allows the fusion process to dynamically prioritize the least-degraded modality. When audio is reliable (high ra), the fusion is dominated by audio guidance; under visually pristine conditions (high rv), visual features govern the output. The full sequence is aggregated through a lightweight fusion head, producing the final AVQA prediction.
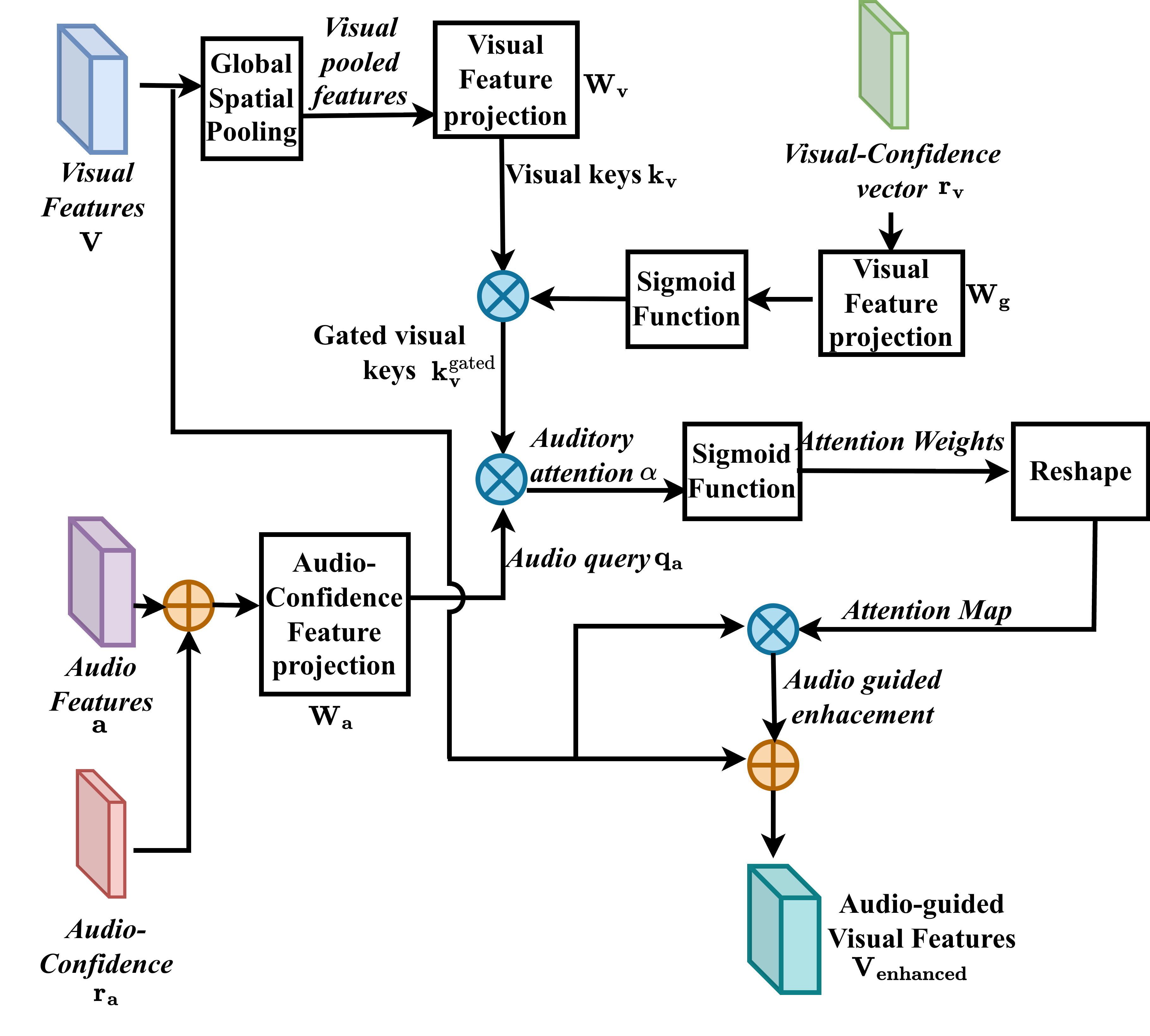
Figure 2: The Confidence-aware Audio–Visual Mixer uses visual and audio features, together with modality confidence scores, to compute channel-wise auditory attention weights that modulate visual feature maps and produce audio-guided visual representations.
Experimental Results and Numerical Analysis
MCM-AVQA is rigorously evaluated on UnB-AV, UnB-AVQ, and LIVE-SJTU—benchmarks containing complex, diverse, and highly asymmetric AV distortions scored by human mean opinion scores (MOS). Standard metrics, PLCC and SROCC, quantify the correlation between predictions and subjective MOS.
Across datasets, MCM-AVQA consistently achieves the highest or competitive PLCC and SROCC. On LIVE-SJTU and UnB-AVQ, MCM-AVQA attains the best PLCC values (0.965 and 0.967, respectively) and best SROCC (0.970 and 0.952), outperforming classical pooling, late fusion paradigms, and attention-based baselines. On UnB-AV, while Nave+w2v achieves the top SROCC, MCM-AVQA's mean absolute errors are significantly lower, as confirmed by paired t-tests (p-value 2.1×10−3) and Wilcoxon tests (p-value 2.2×10−3), demonstrating statistically meaningful performance improvement per sequence.
Ablation studies confirm that each component, especially the modality-specific confidence modules, incrementally contributes to overall gains. Removing confidence modeling degrades both correlation metrics; including the Audio-Visual Mixer alone yields modest improvement, but full reliance on confidence-aware, channel-specific attention yields predominant gains.
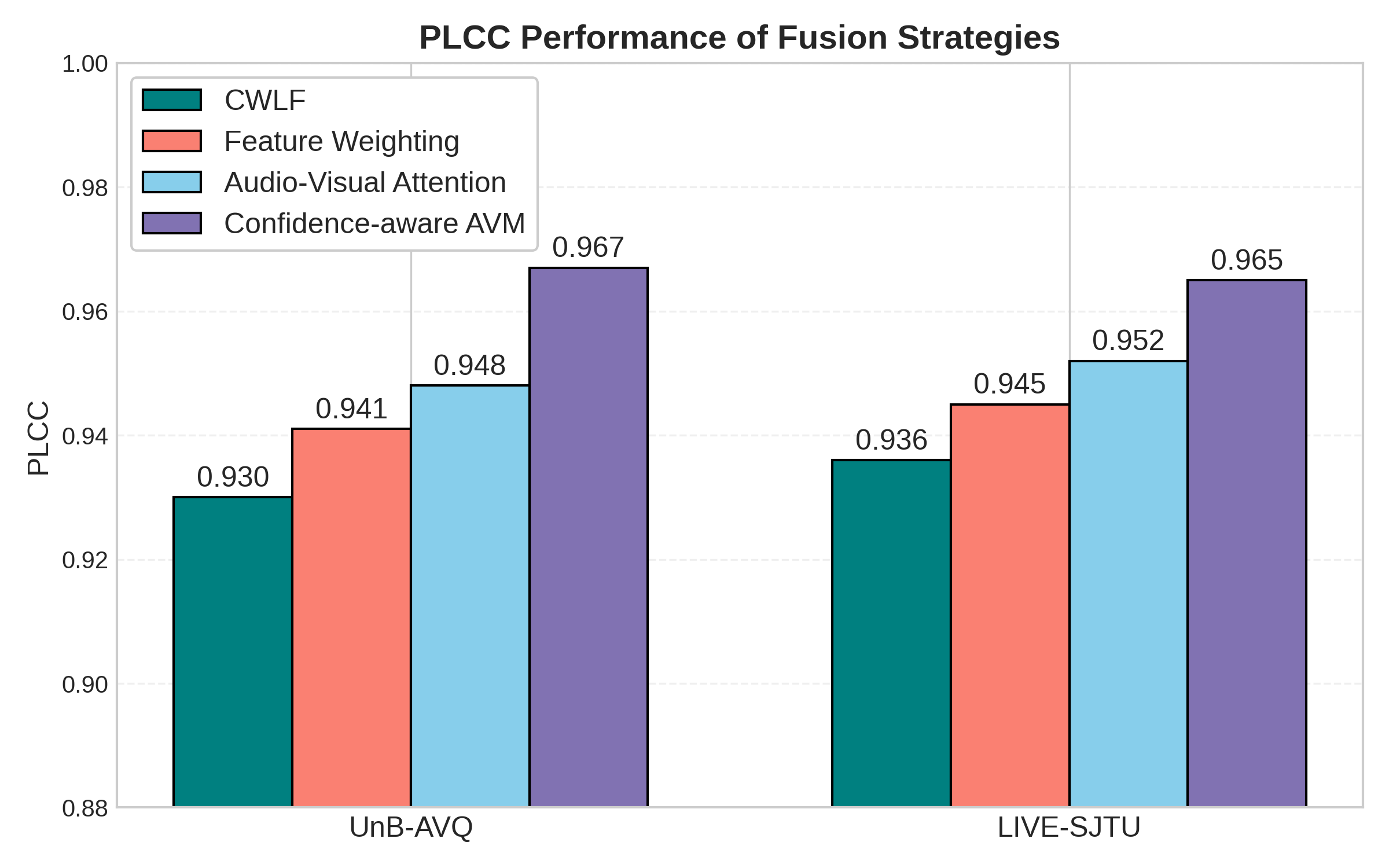
Figure 3: PLCC performance comparison of fusion strategies on UnB-AVQ and LIVE-SJTU, for feature weighting, confidence-weighted late fusion, Audio-Visual Attention Network, and Audio-Visual Mixer (AVM).
Robustness to Asymmetric Distortion
A critical empirical contribution is the analysis of robustness to asymmetric audio-visual distortion. MCM-AVQA demonstrates far greater temporal stability and accuracy under mismatched distortion conditions compared to naive late fusion and attention-only baselines. When tested on scenarios where one modality is degraded and the other remains clean, the AVM's adaptation to modality confidence dramatically reduces performance variance and increases median SROCC, especially for videos with clean audio but degraded video, or vice versa. The drop-off in SROCC under cross-condition evaluation is also minimal for MCM-AVQA, evidencing adaptation to distortion asymmetry.
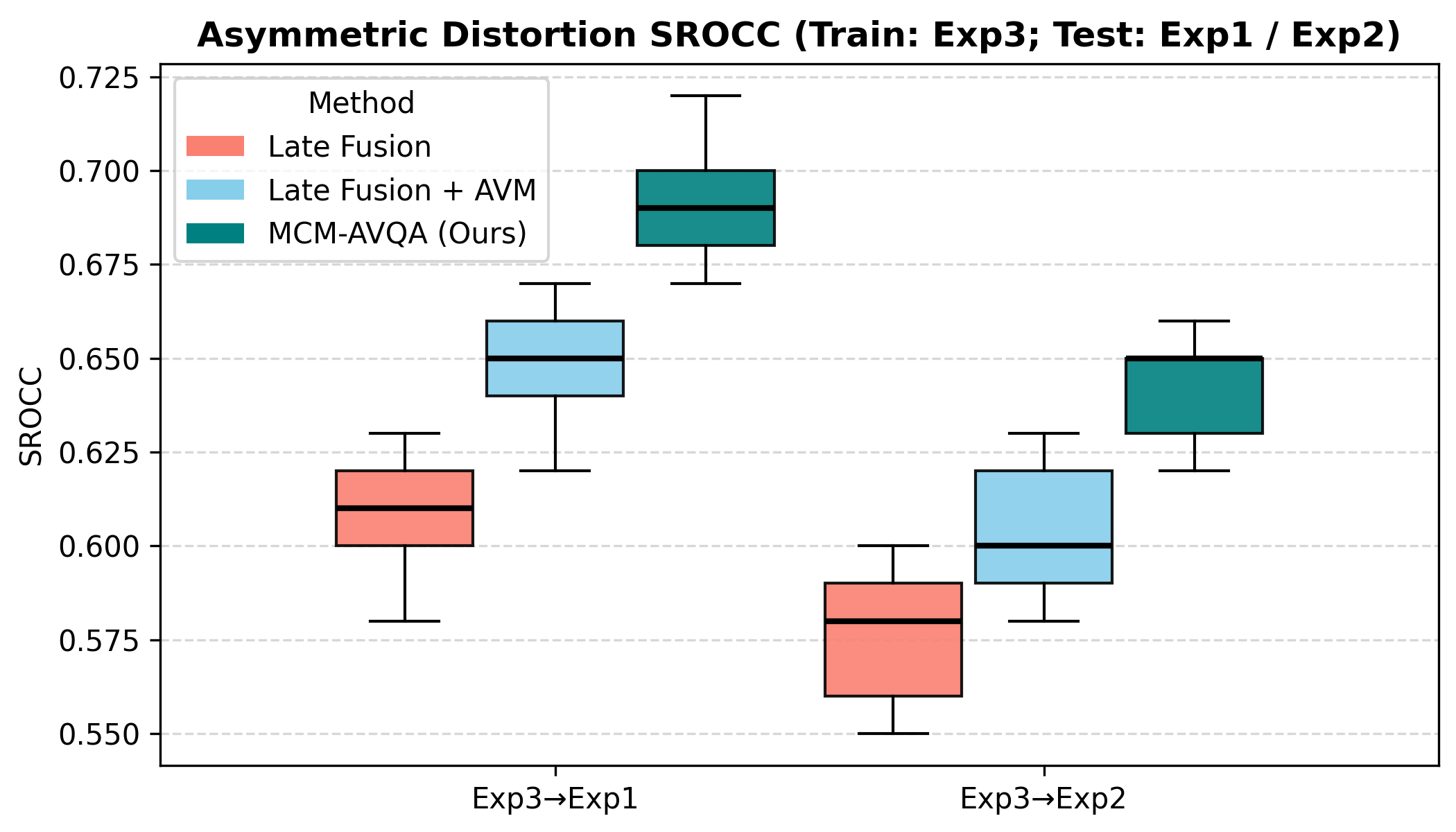
Figure 4: Asymmetric distortion analysis on UnB-AV. Models are trained on Exp3 and evaluated on Exp1 (video-degraded only) and Exp2 (audio-degraded only). Each box plot summarizes the SROCC distribution across five runs, where the central black line denotes the median.
Practical and Theoretical Implications
MCM-AVQA's explicit confidence modeling enables interpretable, robust quality predictions in heterogeneous and unpredictable streaming environments. This design paradigm, in which unimodal reliability directly modulates feature attention, can be readily extended to other multimodal quality assessment domains—such as image-text, audio-language, or point cloud-video tasks—where modality trust varies dynamically.
Theoretically, the work underscores the necessity of integrating explicit reliability estimation for robust multimodal learning, rather than relying on implicit or symmetric attention. Routes for further development include refining confidence estimation via uncertainty quantification, generalizing this architecture for end-to-end multimodal transformer frameworks, and investigating transfer learning between quality assessment and other reliability-sensitive multimodal tasks.
Conclusion
MCM-AVQA advances the state of the art in AVQA by introducing a confidence-aware cross-modal fusion framework that robustly models and explicitly uses audio and visual confidence to gate multimodal integration. Superior results across multiple AVQA datasets and robust performance under asymmetric distortion highlight that fusion at the feature level, gated by modality reliability, is essential for practical deployment. Future research can extend the confidence modeling approach to other domains and further enhance confidence estimation within end-to-end multimodal architectures.

