- The paper introduces ACPO as a dual-axis contrastive framework that mitigates video-driven audio hallucinations in AVLMs.
- ACPO fine-tunes only the audio projection using audio-attribution and audio-sensitivity pairs, enhancing auditory grounding without affecting vision-language tasks.
- Empirical results show significant improvements, with F1 scores of 80.4 and enhanced audio captioning metrics, confirming reduced cross-modal bias.
Audio-Contrastive Preference Optimization for Mitigating Cross-Modal Hallucination in AVLMs
Problem Overview: Cross-Modal Hallucination and Visual Dominance
The proliferation of Audio-Visual LLMs (AVLMs) has enabled multimodal reasoning, but these systems are susceptible to cross-modal hallucination—especially video-driven audio hallucination. This error arises when strong visual priors override or fabricate auditory evidence, leading models to confidently generate sounds based solely on visual cues (e.g., inferring a siren from an image of a police car with no accompanying sound). As established in the paper, visual dominance is both pervasive and asymmetric: models default to visual tokens, with audio receiving low attention weights and audio-focused tasks exhibiting degraded performance as visual input increases. Conversely, visual reasoning remains robust to audio interference.
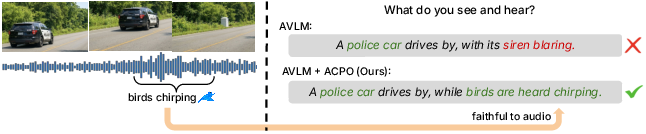
Figure 1: Correcting cross-modal hallucination in AVLMs, demonstrating how models hallucinate sound events (e.g., a siren) based on visual co-occurrences rather than actual auditory input.
ACPO: Methodology and Training Pipeline
To address visual dominance and break the reliance on superficial co-occurrence shortcuts, the paper introduces Audio-Contrastive Preference Optimization (ACPO), a dual-axis contrastive preference learning framework. ACPO leverages two orthogonal preference pair constructions:
- Output-Contrastive (Audio-Attribution) Pairs: These pairs penalize models for visually grounded responses to audio-focused prompts, employing swapped audio tracks (e.g., (vA,aB)) and modality-specific supervision targets. Preferred responses are audio captions grounded in the swapped audio, while dispreferred are visual captions.
- Input-Contrastive (Audio-Sensitivity) Pairs: These penalize the model for predictions invariant to changes in the audio track. The model should decrease its likelihood of generating the original audio-visual caption when auditory evidence is mismatched.
Key implementation detail: only the audio projection layer is fine-tuned, preserving vision-language performance while enforcing true auditory grounding.
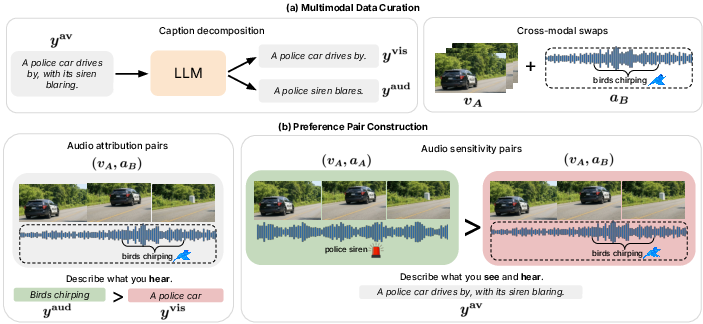
Figure 2: Overview of ACPO, showing decomposed modality-specific targets and contrastive pair construction for both audio-attribution and audio-sensitivity objectives.
ACPO is implemented atop a state-of-the-art AVLM (Video-LLaMA2-7B-AV), with preference pairs constructed using VALOR clips, modality decomposition via LLMs, and controlled audio swapping based on multimodal similarity scores.
Empirical Findings: Asymmetry and Robustness
The authors rigorously establish the model's asymmetrical modality bias, demonstrating that increasing visual input in audio-focused QA tasks degrades accuracy (76.8→74.0), whereas supplementing video tasks with audio input yields improvements (61.5→77.2). This evidences that visual cues actively override correct auditory reasoning, confirming that cross-modal hallucination is primarily video-driven.
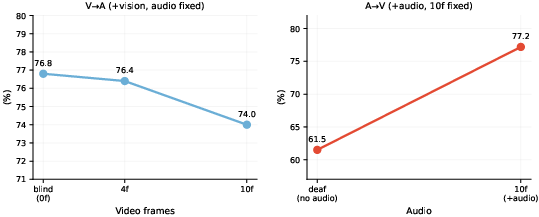
Figure 3: Empirical analysis of visual dominance in AVLMs, showing that additional video frames trigger more audio hallucinations.
Qualitative and Quantitative Results
ACPO achieves robust gains in both hallucination mitigation and audio captioning. On AVHBench, ACPO attains F1 = 80.4 and accuracy = 79.9 in audio hallucination, outperforming both baseline and contemporary training strategies (including DPO and OmniDPO). Notably, precision improves while maintaining competitive recall, indicating improved discrimination against visually-induced hallucinations.
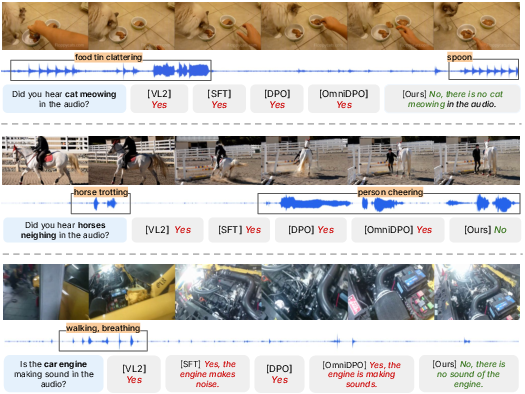
Figure 4: Qualitative examples where ACPOcorrectly grounds responses in the audio signal, while baselines hallucinate affirmative answers despite the absence of queried sound events.
Strong numerical results are also observed in open-ended audio captioning. ACPO produces substantial gains in audio CIDEr (27.9→43.6 on original clips; 13.1→30.6 on swapped clips), evidencing improved capability to describe auditory events in the presence of conflicting visual cues.
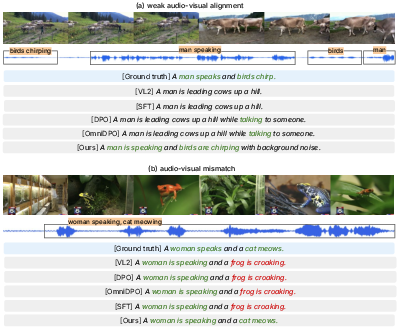
Figure 5: Qualitative audio-focused captioning; ACPO identifies actual auditory events (speech, birds, cat meowing) while baselines erroneously default to visual priors (e.g., "frogs croaking", "leading cows up a hill").
Further analysis reveals:
- Audio-attribution pairs boost precision, reducing affirmative hallucinations.
- Audio-sensitivity pairs increase recall, enforcing attention to genuine auditory input.
- The combination yields optimal F1 and accuracy.
ACPO preserves overall multimodal capabilities; vision-language and joint audio-visual tasks remain unaffected due to targeted fine-tuning.
Remaining Limitations and Error Modes
ACPO's improvements are bounded by remaining error modes. In joint captioning, ACPO prioritizes auditory grounding but may generalize or drop certain visual details. Detection of subtle or brief audio events (e.g., coin clinking) remains problematic across all methods, suggesting the need for further advances in temporal audio modeling and fine-grained auditory event detection.

Figure 6: Remaining limitations, including incomplete multimodal descriptions and failure to identify short, subtle audio cues.
Implications and Future Directions
ACPO demonstrates that targeted contrastive preference optimization, utilizing modality-specific supervision and carefully constructed adversarial examples, is an effective mechanism for mitigating cross-modal hallucination in AVLMs. The approach establishes a pathway toward balanced and trustworthy multimodal generation, particularly in real-world applications (e.g., embodied systems, assistive technologies) where reliable audio-visual attribution is critical.
Practically, the lightweight fine-tuning signal—operating solely on the audio projection—enables rapid adoption without risk of catastrophic forgetting of vision-language capabilities. Theoretically, the findings reinforce the necessity of contrastive, modality-grounded learning over simple noise injection or naive preference optimization. Future developments will likely focus on:
- Enhanced detection of transient auditory events
- Improved scalability to larger datasets and more diverse modalities
- Integration of multimodal attention architectures that offer finer control of modality attribution
Conclusion
This work identifies and systematically corrects the entrenched problem of video-driven audio hallucination in AVLMs. ACPO delivers state-of-the-art results in audio grounding, substantially improving both hallucination resistance and fidelity of audio description without compromising multimodal reasoning. The methodology provides a robust framework for precise modality attribution and paves the way for future research into balanced, explainable multimodal AI systems.

