- The paper introduces a novel multi-modal diffusion framework that fuses low-quality images, sketches, and text to significantly enhance suspect face synthesis accuracy.
- It employs an iterative human-in-the-loop editing process with retrieval-based identity verification to mitigate sampling variance and improve identity matching.
- The proposed approach achieves up to 85% identity match rates on forensic datasets, demonstrating state-of-the-art performance and practical applicability.
IdentiFace: Multi-Modal Iterative Diffusion for Suspect Face Synthesis in Crime Investigations
Problem Motivation and Background
Suspect face reconstruction plays a crucial role in crime investigations, facilitating identification when law enforcement must rely on witness memories or low-quality images. Classic workflows involving forensic sketches guided by witness descriptions are limited by their reliance on artistic expertise, low photorealism, and inefficiency. Recent advances in T2I diffusion models offer a path toward photo-realistic face generation using natural language descriptions, but such models face two fundamental issues in this forensic context: conditional ambiguity, due to insufficient structure in text-only prompts, and sampling variance, as one-shot generations may not reliably reproduce key identifying features.
Prior generative methods for forensic face synthesis have typically relied on single modalities (primarily text or sketches) or suffer from limited identity control, limiting practical applicability. IdentiFace directly addresses these dual limitations by integrating multi-modal conditioning and an interactive, iterative refinement paradigm.
Methodological Contributions
Multi-Modal Conditioning
IdentiFace leverages three evidence modalities commonly accessible in investigations:
- Extremely low-quality (LQ) images: These are often derived from surveillance footage—highly degraded, but still containing global facial structure and color priors.
- Simple sketches: Instead of requiring time-intensive, high-fidelity sketches, witnesses or artists produce rough structural outlines based on LQ evidence, guiding prominent feature positions.
- Fine-grained text descriptions: Structured textual inputs, formulated per forensic standards, encode subtle traits (gender, age, feature shapes, marks).
Crucially, IdentiFace fuses the LQ and sketch modalities (using image-domain superposition and CNN-based fusion) to form a spatially informative conditioning signal, suitable for unified processing by ControlNet-based diffusion architectures. This design enables stronger geometric and appearance constraints than text alone, yielding improved identity preservation.
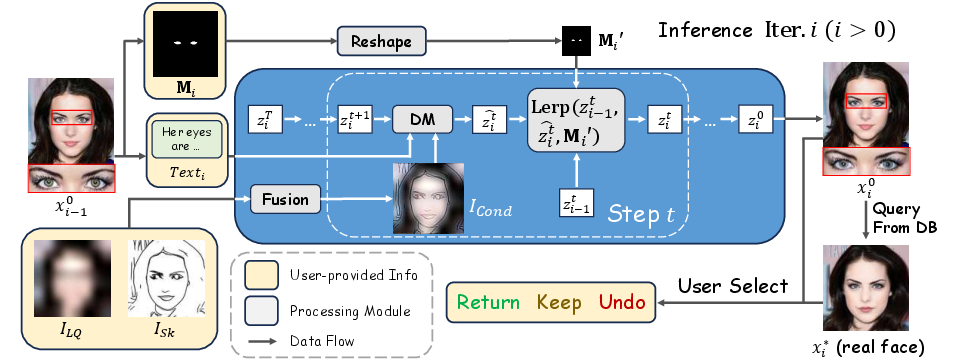
Figure 1: Overview of the IdentiFace framework, illustrating the fusion of LQ and sketch images and the iterative user-in-the-loop generation with retrieval-based identity reference.
Iterative Generation Pipeline and Human-in-the-Loop Refinement
Unlike prior one-shot diffusion generation, IdentiFace introduces a user-in-the-loop iterative editing process. In each iteration, users can:
- Provide new region masks and local texts for targeted editing via mask-guided latent diffusion.
- Inspect both the generated image and the best facial identity retrieval from a large facial database.
- Decide to accept the result, request further refinements, or undo/redo the prior action.
This closed-loop design is training-free during inference and significantly mitigates sampling variance. Importantly, the best-retrieval image, computed by facial recognition encoders (e.g., AdaFace), serves as an objective anchor for human judgment, focusing iteration on improving identity alignment.
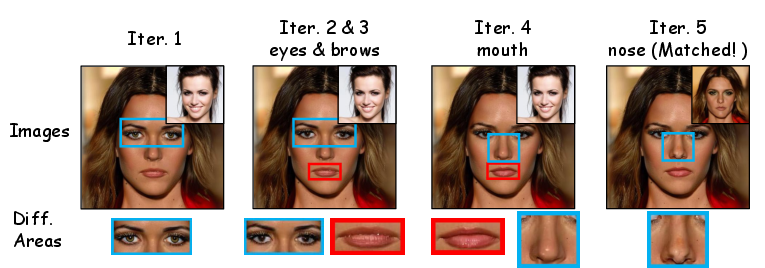
Figure 2: Demonstration of the iterative generation process, displaying both current synthesis and database retrieval for guided witness feedback.
Custom Training Loss and New Datasets
To further promote identity preservation, a novel Facial Identity Loss is introduced, computed as a sigmoid-transformed margin between generated and ground-truth embeddings in the face-recognition encoder space. The loss is only applied during late-stage denoising steps, where predictions stabilize, weighting gradient flow relative to the similarity threshold for identity matches.
Two new multimodal forensic face datasets are constructed: ID-CelebA and ID-FFHQ, encompassing paired LQ, sketch, and detailed text for tens of thousands of labeled identities. Data augmentation pipelines simulate realistic LQ degradations and GAN-based sketch synthesis; structured text is generated via LLMs guided by forensic templates.
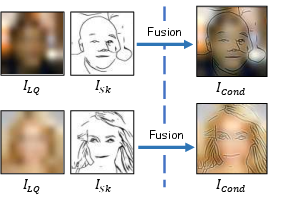
Figure 3: Examples illustrating the generation of LQ, sketch, and fused conditional images for multimodal conditioning.
Empirical Evaluation
Synthetic Data Experiments
Comparisons across a range of baselines—text-to-image diffusion, sketch-to-image, face restoration, multimodal T2I adapters—demonstrate that IdentiFace achieves state-of-the-art performance on identity-centric metrics (AdaFace/SFace match rates, cosine similarity) and image quality (FID, LPIPS, MS-SSIM).
Under one-shot generation, the inclusion of all three modalities outperforms text-only or single-modality baselines by large margins in identity matching rate; the fusion strategy further improves over dual-branch models. For example, on ID-CelebA and ID-FFHQ, IdentiFace achieves identity match rates of 84% and 85%, respectively, far exceeding previous architectures.

Figure 4: Qualitative comparison per modality and baseline, showing superior AdaFace similarity and retrieval identity for IdentiFace.
Ablation studies substantiate that both the facial identity loss and incorporation of local textual details (controlled via the Local Text Ratio hyperparameter) further increase identity fidelity.
Iteration analysis reveals a major gain: For both generic ControlNet (w/ sketch) and IdentiFace, iterative generation increases identity match rates by >15% (absolute), validating the efficacy of user-guided, anchor-based editing.
Real-World User Study
Simulated forensic scenarios are conducted using real volunteers and a database with thousands of confounders. Users iteratively generate candidate faces based on LQ inputs, hand-drawn sketches, and their own memories, with feedback from AdaFace/SFace retrieval anchors. Across six target identities and multiple trials, the success rate (retrieving the correct identity) is high, with trial durations (4–12 minutes) and number of iterations (1.2–6.3) reflecting both sample difficulty and user strategy. Failure cases highlight the persistence of identity confusion in some ambiguous instances, but overall results demonstrate strong potential for practical deployment.
Theoretical and Practical Implications
IdentiFace makes several bold claims, supported by strong empirical evidence:
- Multi-modal fusion (LQ + sketch + text) provides significantly stronger geometric and identity control than any individual modality or their naïve combination.
- Iterative, anchor-driven editing fundamentally mitigates diffusion model sampling variance in high-stakes forensic contexts.
- Face-similarity-based loss directly optimizes identity reconstruction, a crucial objective overlooked in generic image generative modeling.
The practical implications are substantial: forensic workflows can be radically accelerated and democratized, with less reliance on artistic skill. The embedded use of facial recognition as a feedback signal further ties generative results to operational investigatory tools.
Limitations and Future Directions
While IdentiFace demonstrates high accuracy and practical viability, certain challenges remain:
- Fine grained attribute manipulation is not always robust, sometimes requiring multiple editing rounds or yielding visual artifacts.
- Biases inherent to training data (in ethnicity, age, demographics) may propagate into generation quality or matching rates.
- Ethical concerns arise regarding privacy, facial image misuse, and cross-domain generalization.
Future research should focus on increasing localized controllability, mitigating data biases via balanced dataset curation and training, and further integrating privacy-preserving mechanisms.
Conclusion
IdentiFace delivers a comprehensive multi-modal, iterative diffusion framework for suspect face generation in crime investigations. Through rigorous architectural design, tailored loss functions, and purpose-built datasets, IdentiFace achieves superior identity preservation and application readiness relative to existing baselines. The closed-loop, human-in-the-loop editing paradigm establishes a new functional standard for forensic generative models, with clear paths for enhancement in controllability, fairness, and real-world deployment.

