- The paper introduces RERCL which dynamically estimates requirement difficulty to tailor curriculum learning.
- It optimizes unsolvable requirements by enriching details to generate measurable reward signals and enhance training efficiency.
- Adaptive curriculum sampling with smoothing mitigates catastrophic forgetting and boosts overall LLM code generation performance.
Requirement-Aware Curriculum Reinforcement Learning for LLM-Based Code Generation
Introduction
The paradigm of code generation using LLMs has achieved remarkable progress, accelerating intelligent software engineering. Despite their success, contemporary LLMs underperform on complex requirements due to suboptimal training strategies. Curriculum Reinforcement Learning (CRL), where training data is sequenced from easy to hard based on task difficulty, has emerged as an effective approach to boost LLM code generation. However, prior CRL methods suffer from three main deficiencies: static and model-agnostic requirement difficulty perception, lack of optimization for hard requirements, and curriculum sampling strategies that provoke catastrophic forgetting and training instability.
This work introduces Requirement-aware Curriculum Reinforcement Learning (RERCL), a modular CRL framework specifically addressing these weaknesses. RERCL provides (1) dynamic, model-specific requirement difficulty estimation, (2) requirement difficulty optimization via attribute-guided refinement and validation, and (3) adaptive curriculum sampling with difficulty smoothing. These are demonstrated to significantly improve generalization and stability for LLM code generation across diverse architectures and challenging benchmarks.
Background and Motivation
Existing CRL frameworks typically annotate requirement difficulty using human judgment or static code complexity metrics (e.g., cyclomatic complexity, Halstead difficulty). These proxies neither reflect the current model’s capacity nor adapt to training progression. Empirical analysis reveals critical misalignment: LLMs frequently fail on supposedly “introductory” tasks as per manual labeling, illustrating the discord between annotation and model-perceived difficulty.
Highly difficult requirements rarely yield positive reward signals (passing code samples), resulting in poor data utilization and stalling gradient flow during RL. Further, abrupt stage-wise curriculum shifts (e.g., hard transitions from “easy” to “medium”) often trigger catastrophic forgetting, where learned representations for simpler tasks deteriorate, and cold-start issues, destabilizing optimization.
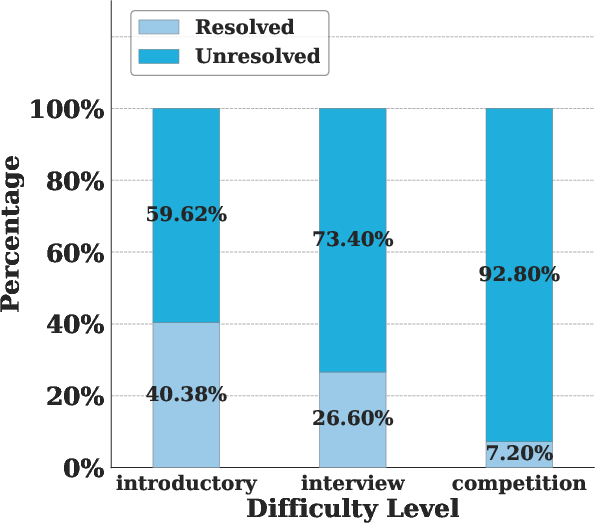
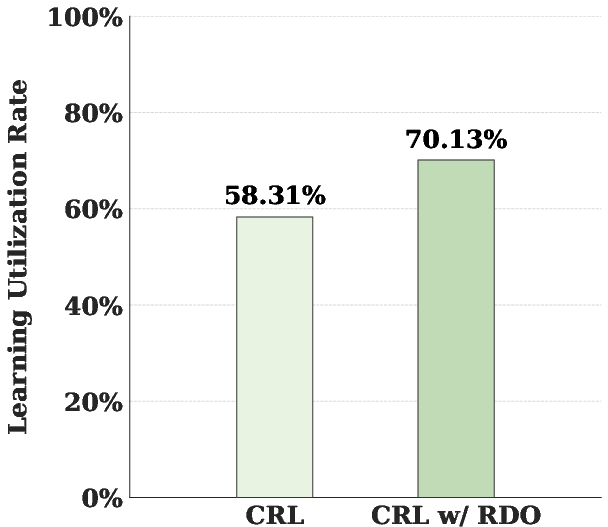
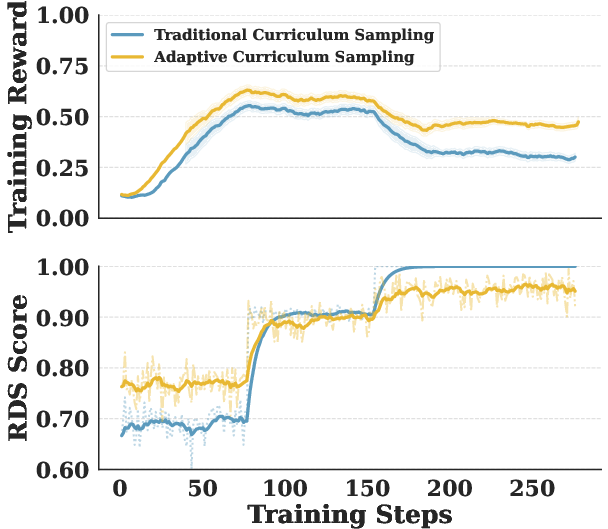
Figure 1: Discrepancy between manual annotations and model-perceived difficulty; improvement in data utilization from requirement optimization; superiority in reward profiles using adaptive curriculum sampling over rigid sampling.
RERCL: Framework Overview
RERCL introduces three orthogonal modules to construct a curriculum learning signal that truly reflects a model’s limitation and promotes staged, balanced learning.
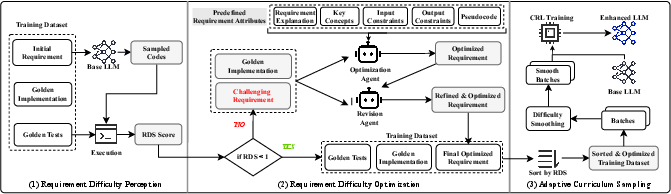
Figure 2: Schematic of RERCL's pipeline comprising requirement difficulty perception, requirement optimization agents, and adaptive curriculum sampling with smoothing.
Dynamic Difficulty Perception
Instead of relying on static, model-agnostic difficulty attributes, RERCL computes a Requirement Difficulty Score (RDS) for each requirement via multi-sample code generation and test-based verification: for each requirement, N codes are sampled, evaluated using golden tests, and RDS is set as one minus average code correctness. Thus, RDS is sensitive to current model performance and training stage, enabling personalized curriculum schedules that adapt if the model's abilities improve.
Requirement Difficulty Optimization
A significant subset of requirements are “unsolvable” under the current model: none of the sampled codes pass all tests. RERCL deploys an optimization agent, leveraging principles from software requirements engineering. Given gold code and the original requirement, the agent enriches requirements with five structured attributes: explanation, key concepts, input/output constraints, and pseudocode. This not only clarifies intent but exposes essential implementation hints. A revision agent post-processes for logical consistency and redundancy elimination.
Post-optimization, requirements that were previously unreachable provide a nontrivial positive reward signal, improving sample efficiency and effective RL horizon.
Adaptive Curriculum Sampling and Smoothing
Instead of rigid clusters (easy/medium/hard) with abrupt transitions, RERCL partitions by RDS but reshuffles at each stage with a smoothing factor λ. At each update, λ fraction of samples is drawn from the current cluster; the remainder is sampled uniformly from across clusters. This soft blending ensures rehearsal of previously solved requirements and gradual exposure to harder problems, mitigating catastrophic forgetting and sudden cold-starts. Experiments control λ between 0 and 1 to probe the stability/performance frontier.
Experimental Evaluation
RERCL was validated using five open LLMs (Qwen2.5-Coder-1.5B/3B/7B, Llama-3.2-3B, SmolLM3-3B) and five standard benchmarks (HumanEval, HumanEval+, MBPP, MBPP+, LiveCodeBench), always training on APPS+. Metrics included Pass@1 (strict accuracy) and AvgPassRatio (partial test completion).
RERCL demonstrated consistent and robust performance gains across all settings. For instance, average Pass@1 improvements over state-of-the-art CRL and distillation baselines were in the 1.2%--5.6% range; smaller models especially benefited, with RERCL-nurtured Qwen2.5-Coder-3B (66.5% Pass@1) surpassing the larger Qwen2.5-Coder-7B (66.05%).
Ablation studies isolating the effect of each module (manual/static RDS, dropping optimization, or smoothing) repeatedly indicated that each contributes substantial additive improvement—optimization of hard requirements was necessary for efficient credit assignment to “unsolvable” tasks, and smoothing was essential for transfer and retention of knowledge.
Parameter sweeps for the smoothing factor λ reveal an optimum around 0.6, balancing focused stage-wise training with adequate cross-stage rehearsal.
Discussion and Implications
The explicit model-centric perception of requirement difficulty, coupled with requirement optimization for reward shaping, substantially increases the effective data utilization during RL, directly addressing one of the most salient pitfalls of prior curriculum strategies. Smoothing in curriculum sampling strengthens continual learning and mitigates the classic RL problem of catastrophic forgetting, long recognized as a core instability in lifelong model adaptation.
Given the modular nature of RERCL components, gradual extension to repository-level code generation, code evolution, or bug-fix synthesis is straightforward. More generally, the framework offers a delineation of role separation: grounding curriculum in observed model weaknesses (difficulty perception), amplifying positive reward signals for hard cases (optimization), and blending staged reinforcement to retain past skills (adaptive sampling).
Potential future directions include efficient test case prioritization to reduce RL overhead, automatic expansion of targeted requirement attributes (e.g., dynamic resource constraints), and truly online/dynamic scheduling of sampling parameters via reward variance or other performance indicators.
Conclusion
RERCL establishes a rigorous and effective protocol for curriculum reinforcement learning in LLM-based code generation by integrating model-driven difficulty estimation, intelligent requirement optimization, and stabilized curriculum transitions. The empirical evidence demonstrates not only aggregate improvements in pass rates, especially for compact models, but also a reduction of intra-benchmark and cross-model performance disparities. The requirement-aware approach embodied in RERCL sets the stage for further conceptual convergence between software requirements engineering and curriculum design for autonomous software agents.
These results will motivate future research on generic requirement- and performance-aware training protocols in code generation and broader AI-for-SE domains.

