- The paper demonstrates that multi-task LoRA fine-tuning markedly improves performance across nine radiology tasks, with gains up to 280% in impression generation.
- It applies a rigorously curated dataset of 161K samples and task-weighted sampling to balance structured generation and extraction tasks for clinical applications.
- The study shows that compact, quantized models run efficiently on consumer CPUs, offering safe clinical error profiles and practical deployment insights.
RadLite: Multi-Task LoRA Fine-Tuning of Small LLMs for Deployable Radiology AI
Overview and Motivation
RadLite addresses the central challenge of deploying capable radiology AI in clinical settings where computational resources are constrained and reliance on GPU-based or cloud-hosted LLMs is impractical. The study systematically evaluates whether open-weight small LLMs (SLMs), specifically Qwen2.5-3B-Instruct (3B parameters) and Qwen3-4B (4B parameters), can, via LoRA fine-tuning, match multi-task radiology performance that approaches much larger proprietary models, while remaining deployable entirely on consumer-grade CPUs. The core contributions span dataset curation, multi-task LoRA adaptation, a comprehensive benchmark across nine representative radiology tasks, architectural analysis, and practical deployment insights.
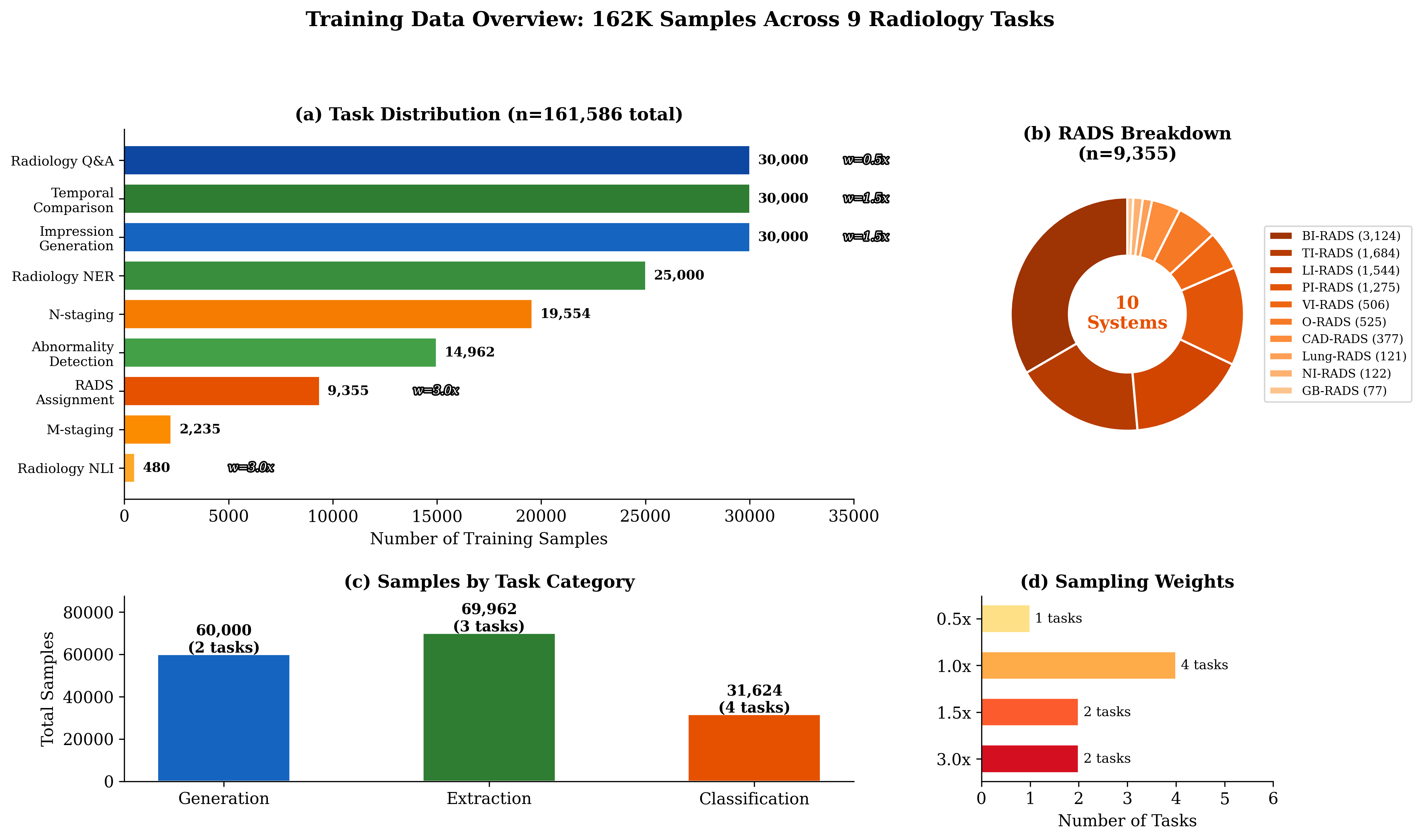
Figure 1: The RadLite multi-task training corpus, illustrating task distribution, sampling weights, and category breakdowns (generation, extraction, classification) across 162K samples from 12 public datasets.
RadLite leverages a curated composite dataset of 161,586 samples covering nine critical radiology tasks: RADS classification across ten systems (e.g., BI-RADS, PI-RADS), impression generation, temporal comparison, radiology NLI, NER (RadGraph schema), abnormality detection (e.g., CheXbert-labeled CXR), N/M staging (Merlin dataset), and clinical question-answering. Data is sourced from 12 public datasets, spanning modalities, and stratified into gold (expert), silver (model), and bronze (LLM) annotation tiers. All data is unified into an instruction-tuning framework with task-specific prefixing. Task-weighted sampling is applied to mitigate imbalance stemming from diverse sample sizes and to boost representation of clinically vital but low-resource tasks (e.g., NLI, RADS assignment).
LoRA Fine-Tuning and Multi-Task Approach
Both Qwen2.5-3B and Qwen3-4B are fine-tuned with identical LoRA configurations: rank r=64, scaling factor α=128, targeting all key projection matrices in both the attention and feedforward submodules. Effective adaptation with 1.2–1.6% trainable parameters (~240 MB per adapter) is achieved without catastrophic forgetting, using single-epoch coverage over the balanced corpus and moderate regularization (dropout 0.05, cosine schedule, batch size 32). The multi-task objective is pivotal: a single LoRA adapter adapts the base SLMs to simultaneously handle free-text generation and structured token-level classification/extraction, tested over large, diverse held-out sets with task-specific gold metrics.
Fine-tuned SLMs show dramatic improvements versus zero-shot across all major clinical NLP tasks:
- RADS assignment: +53 pp (24.2% → 77.0% Qwen2.5, 76.4% Qwen3)
- N-staging: +89 pp (0% → 89%, both models)
- NLI: +60 pp (22–26% → 82–83%)
- Impression generation: +280% (0.132 → 0.502 ROUGE-L for Qwen2.5)
- NER: +1,840% for Qwen3 (0.049 → 0.950 ROUGE-L)
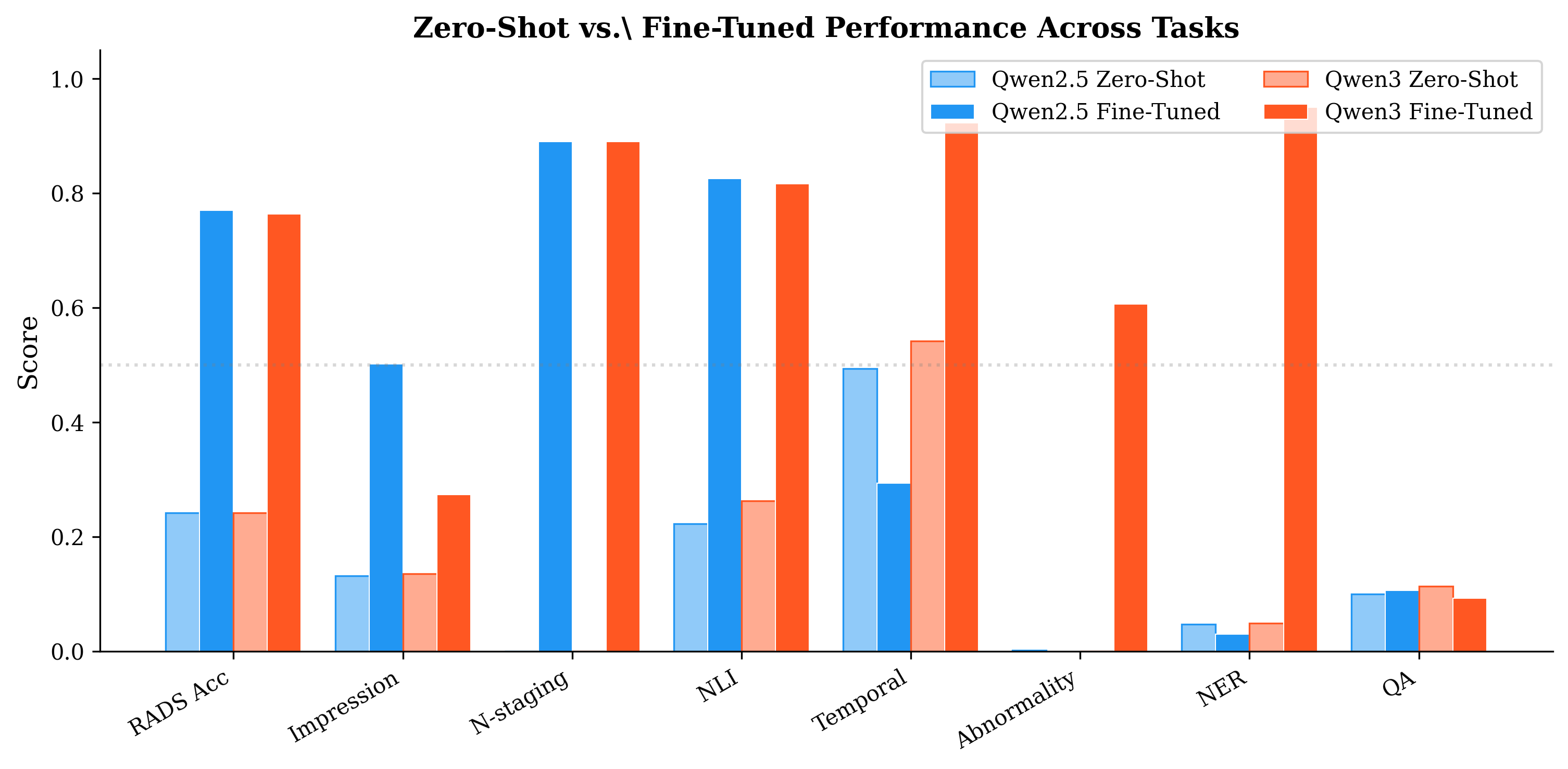
Figure 2: Absolute and relative performance gains moving from baseline zero-shot to LoRA fine-tuned small models, highlighting a pronounced and complementary improvement pattern between Qwen2.5 and Qwen3.
Model Architectural Complementarity
A major empirical insight is the complementary task strengths of the two SLMs:
- Qwen2.5-3B outperforms at structured generation (impression, NLI, QA) and displays more consistent cross-system RADS accuracy.
- Qwen3-4B excels at extraction/detection (NER +3,067% over Qwen2.5, temporal comparison +215%) and demonstrates a marked advantage on high-prevalence RADS categories.
This complementarity is visualized in the radar diagram, and confirmed by Wilcoxon/McNemar significance testing (p < 0.001 on five of nine tasks). The divergence reflects deep architectural differences: Qwen2.5's canonical decoder is generation-optimized, while Qwen3's GQA and reasoning-oriented features favor extractive structuring. As a result, a task-routed ensemble that dispatches each input to the superior model achieves maximal performance across the entire task suite.
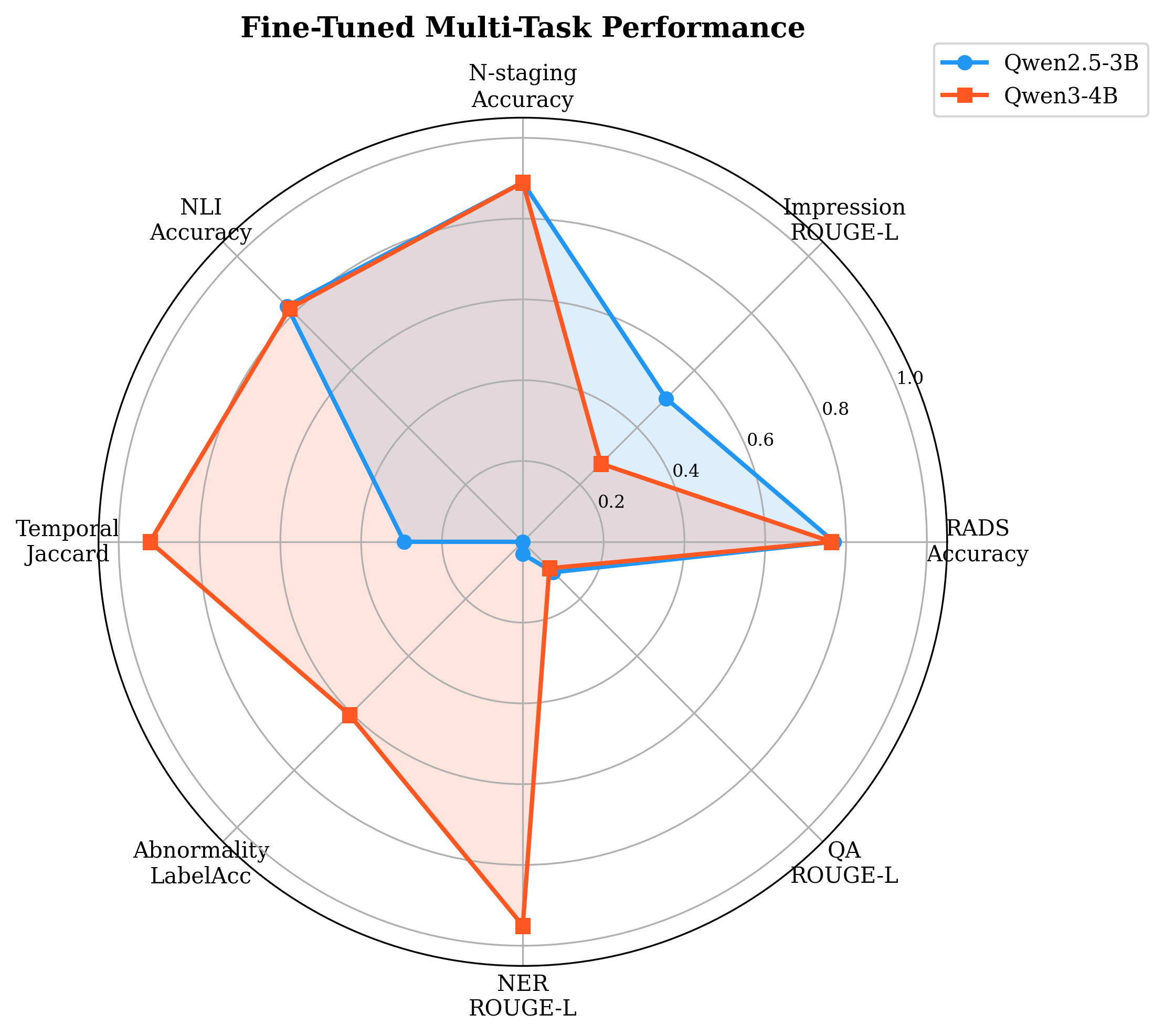
Figure 3: Radar plot demonstrates orthogonal patterns in task-specificity, with Qwen2.5 dominating generation quadrants and Qwen3 dominating extraction-related axes.
Detailed RADS Analysis and Clinical Error Profile
Both models achieve strong (>85%) accuracy on common RADS systems (VI-RADS, TI-RADS, PI-RADS); performance degrades on rare or data-limited systems. Qwen3's prevalence-biased advantage on BI-RADS (largest group) is contrasted with Qwen2.5's consistency. Most misclassifications are "off-by-one," respecting clinical severity orderings.
Crucially, error directionality analysis reveals Qwen2.5's conservative bias (50.5% overcall errors, only 32.4% undercalls) compared to Qwen3 (44.1% undercalls), which is safer for clinical deployment since overcalls prompt unnecessary follow-up rather than missed pathology.
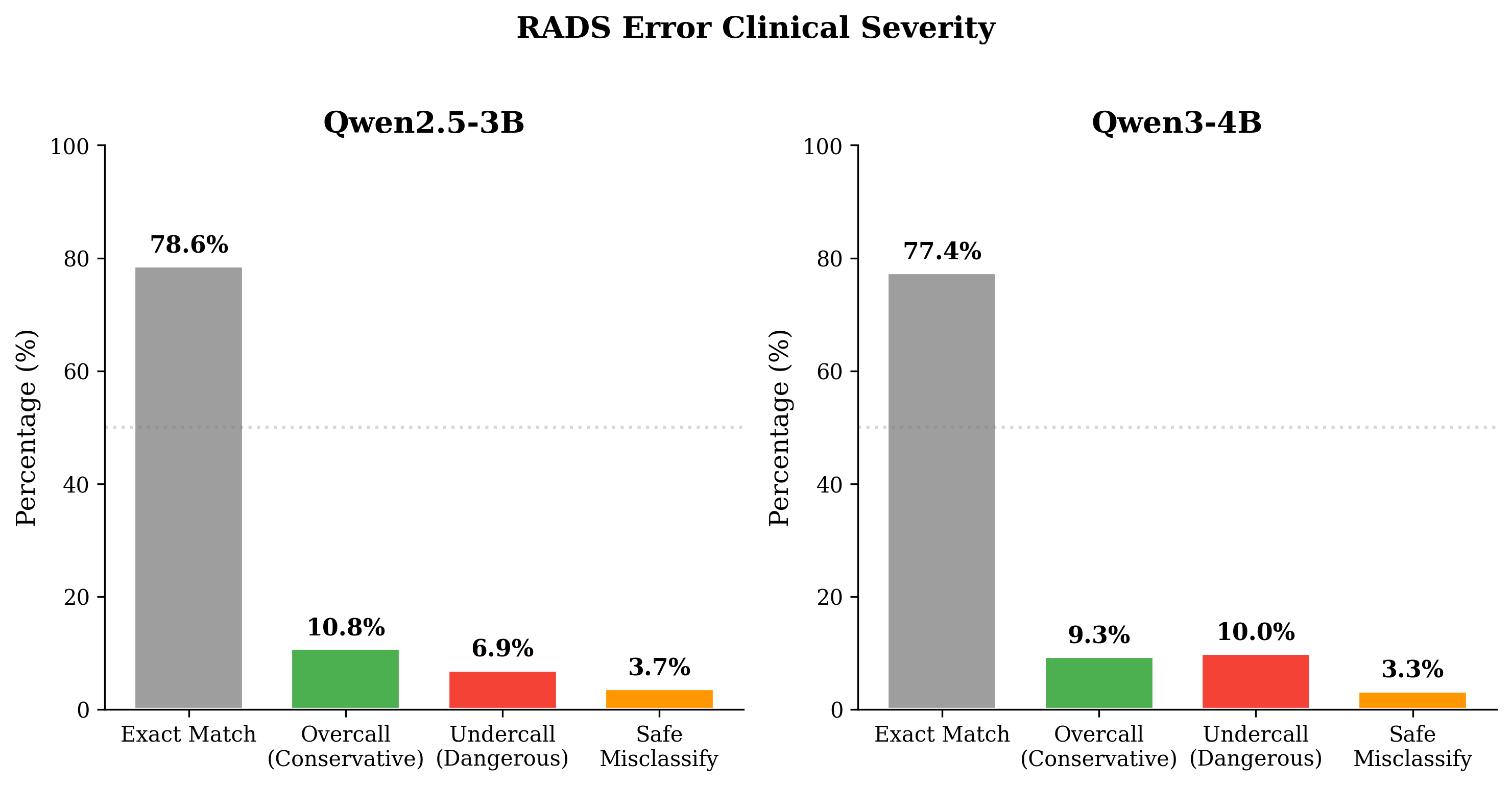
Figure 4: Distribution and severity of RADS classification errors: Qwen2.5's overcall bias results in fewer dangerous undercalls than Qwen3.
Effects of Few-Shot Prompting on Fine-Tuned SLMs
An unexpected and robust negative result is that introducing few-shot (3-shot) prompting to fine-tuned SLMs reduces overall accuracy in RADS assignment, mainly harming well-learned systems while offering modest gains only for very low-resource categories. The net drop is 5.0 pp in accuracy. This is attributed to prompt distribution shift: LoRA fine-tuned models specialize on the training format, and in-context examples perturb the learned mapping. This insight underscores the superiority of parameter-efficient adaptation over continual prompting for domain-specific SLM deployment.
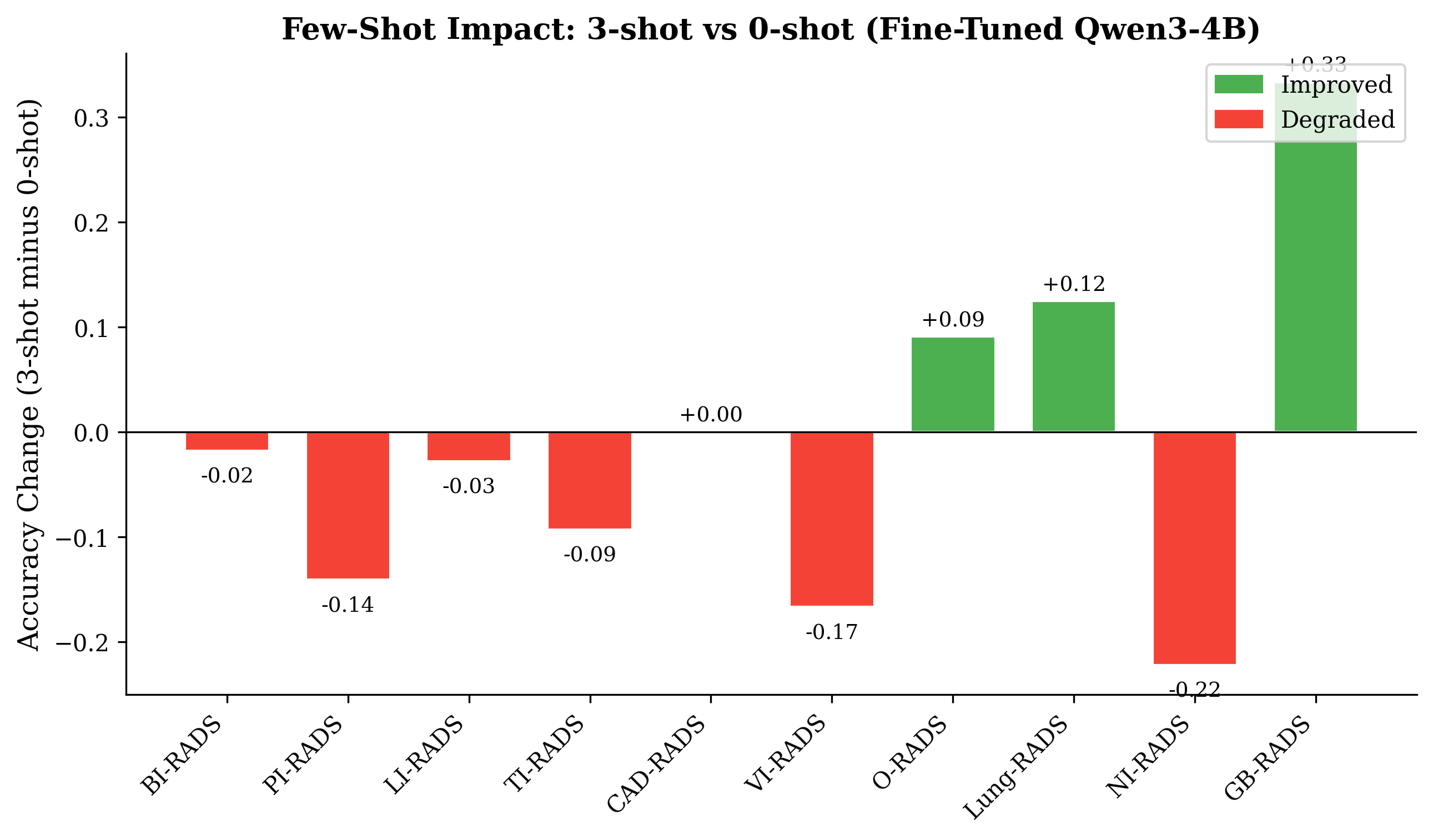
Figure 5: Few-shot prompting yields mixed effects, with aggregate performance reduction due to negative shifts in high-volume system accuracy.
Model Quantization and Practical CPU Deployment
Both models are quantized (GGUF Q4_K_M) to 1.8–2.4 GB files—well within ordinary consumer RAM budgets. Throughput on an i7-class CPU is strong: Qwen2.5-3B achieves 7.7 tokens/second and Qwen3-4B 4.4 tokens/second, supporting completion of typical clinical queries in 2–4 seconds—suitable for radiologist-in-the-loop applications.
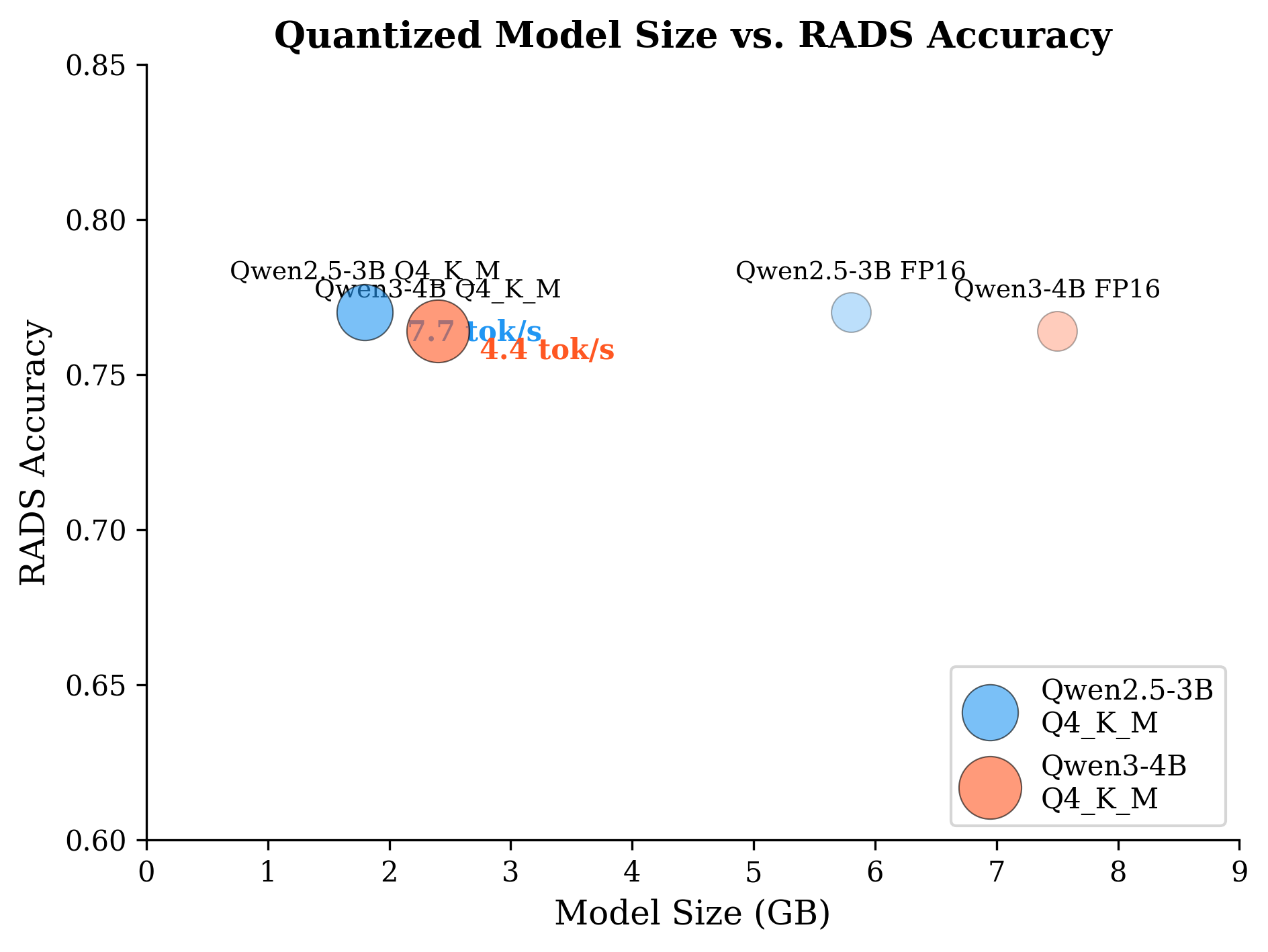
Figure 6: Throughput and memory footprint for RadLite models, both supporting multi-task inference on consumer CPUs under typical RAM constraints.
Implications and Future Directions
Practically, RadLite SLMs enable private, rapid multi-task radiology assistance—RADS decision support, report summarization, abnormality detection, and clinical reasoning—on standard desktops, overcoming obstacles of cost, privacy, and cloud connectivity. The complementary nature of small model architectures suggests future work in dynamic task routing, LoRA composition, or mixture-of-experts approaches for specialized medical LLMs without scale-induced inefficiency. The demonstrated drop in performance under few-shot prompting for domain-adapted SLMs argues for a reevaluation of in-context learning's role in clinical NLP: parameter tuning takes precedence.
Theoretically, this work reinforces that model scale is not the only axis of importance; architecture, pretraining schema, and adaptation method jointly determine cross-task transfer potential. Further investigation into negative interference in multi-task LoRA and strategies for orthogonal adapter training are warranted, especially as models are operationalized in real-world clinical environments. Prospective validation and expansion to multilingual, multimodal, and larger-context scenarios represent logical next steps.
Conclusion
RadLite provides compelling evidence that compact, open-weight transformers—when appropriately fine-tuned with LoRA on broad, clinically representative datasets—can deliver multi-task radiology performance that rivals much larger models, all within tight hardware constraints. The models generalize across extraction and generation tasks, offer safe clinical error profiles, and are deployable on commodity CPUs with minimal latency and storage requirements. These findings establish a strong foundation for scalable, privacy-preserving, and accessible AI assistants in radiology, especially for under-resourced or offline settings. The public release of code, data, and quantized models further accelerates open clinical NLP research and practical adoption.

