- The paper introduces a multi-task LLM framework with LoRA fine-tuning that directly extracts tumor staging and biomarker status from pathology narratives.
- It employs a discriminative classification approach with parallel heads for staging, grade, and receptor status, achieving a Macro F1 of 0.976 and improved minority recall.
- The study leverages efficient parameter updates on a frozen LLM backbone, demonstrating superior training efficiency and robustness against class imbalance.
Multi-Task LLM with LoRA Fine-Tuning for Automated Cancer Staging and Biomarker Extraction
Introduction and Motivation
The extraction of structured clinical variables from unstructured pathology narratives remains a critical bottleneck for oncology informatics, impeding efforts in large-scale cohort discovery, registry curation, and data-driven analytics. Conventional rule-based and early deep learning models exhibit fundamental limitations in handling the linguistic variability, formatting heterogeneity, and subtle contextual dependencies inherent in clinical reports. This paper presents a parameter-efficient, multi-task framework leveraging a LoRA-fine-tuned Llama-3-8B-Instruct encoder to simultaneously extract tumor staging, histologic grade, and biomarker status from a large corpus of expert-verified pathology narratives (2604.13328).
System Architecture and Methodological Framework
The proposed approach reframes the pathology extraction task as multi-task discriminative classification, departing from generative text paradigms by directly projecting terminal LLM hidden states into parallel classification heads corresponding to the Tumor (T), Node (N), Metastasis (M) stages, Grade, Estrogen Receptor (ER), Progesterone Receptor (PR), and HER2 biomarker status.
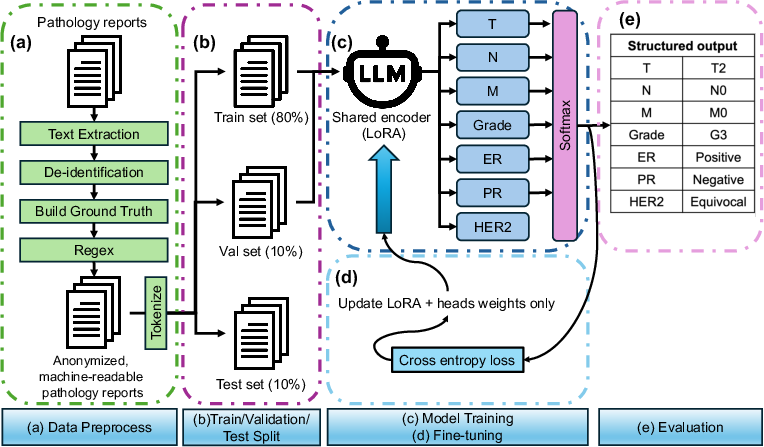
Figure 1: Schematic of the data preprocessing, model architecture, LoRA-based optimization, and structured inference pipeline for multi-task clinical extraction.
The pipeline consists of the following core stages:
- Data preprocessing: De-identification and expert-guided bootstrapping, including advanced segmentation and native text extraction.
- Architecture: Llama-3-8B-Instruct backbone is repurposed as a feature encoder with LoRA adapters, freezing backbone weights while updating low-rank parameters.
- Optimization: Joint cross-entropy loss is minimized for all extraction tasks; class imbalance is mitigated via inverse-frequency weighting, especially for minority classes such as HER2-positive.
- Evaluation: Structured clinical profiles are produced for each report, directly conforming to target registries.
This architectural design enforces strict schema adherence, eliminating the stochasticity and hallucination risks observed in conventional generative LLM pipelines. Crucially, the multi-head configuration supports inductive transfer across semantically entangled staging and biomarker variables.
LoRA Parameter-Efficient Fine-Tuning
To address the operational constraints of clinical environments, the system adopts Low-Rank Adaptation (LoRA) for parameter-efficient fine-tuning, targeting the query, key, value, and output projection matrices within each transformer block.
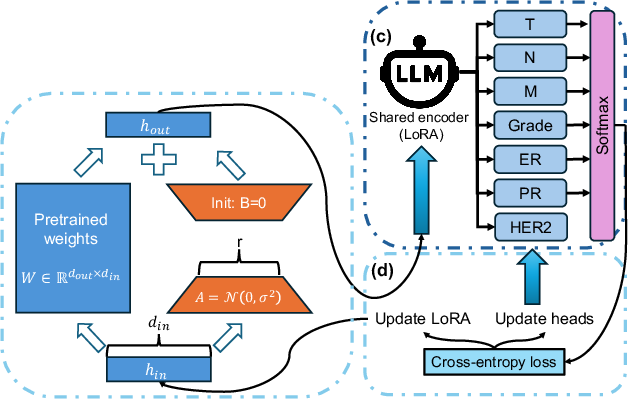
Figure 2: The LoRA adaptation mechanism, in which low-rank matrices are injected into selected transformer projections for efficient domain-specific adaptation.
This formulation constrains updates to a low-dimensional subspace, maximizing sample efficiency and preserving general language knowledge within the frozen backbone. The initialization strategy sets the new matrices near zero, ensuring stable adaptation from pretrained checkpoints.
Ground Truth Curation and Data Quality
The study’s extensive dataset—10,677 pathology reports—was assembled using a hybrid deterministic regex engine iteratively refined by manual expert audit to serve as high-fidelity supervisory targets. The bootstrapped process included dual update loops for coverage and accuracy, driving the regex logic toward clinical parity.
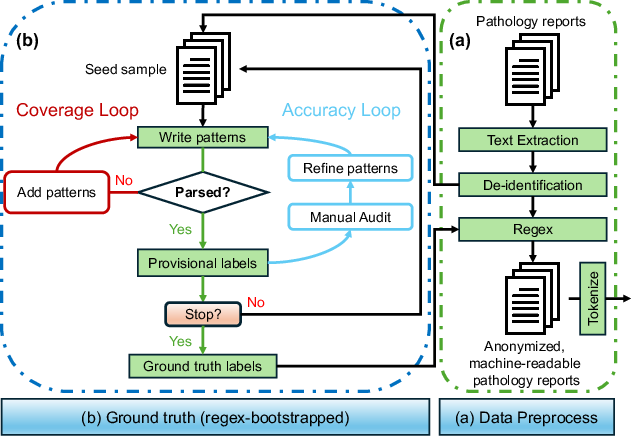
Figure 3: Human-in-the-loop ground truth construction workflow integrating iterative coverage and accuracy refinement for expert-aligned labeling.
Final class distributions highlight the “long-tail” nature of clinical oncology data, with pronounced imbalance between common and rare classes for both staging and biomarker endpoints.
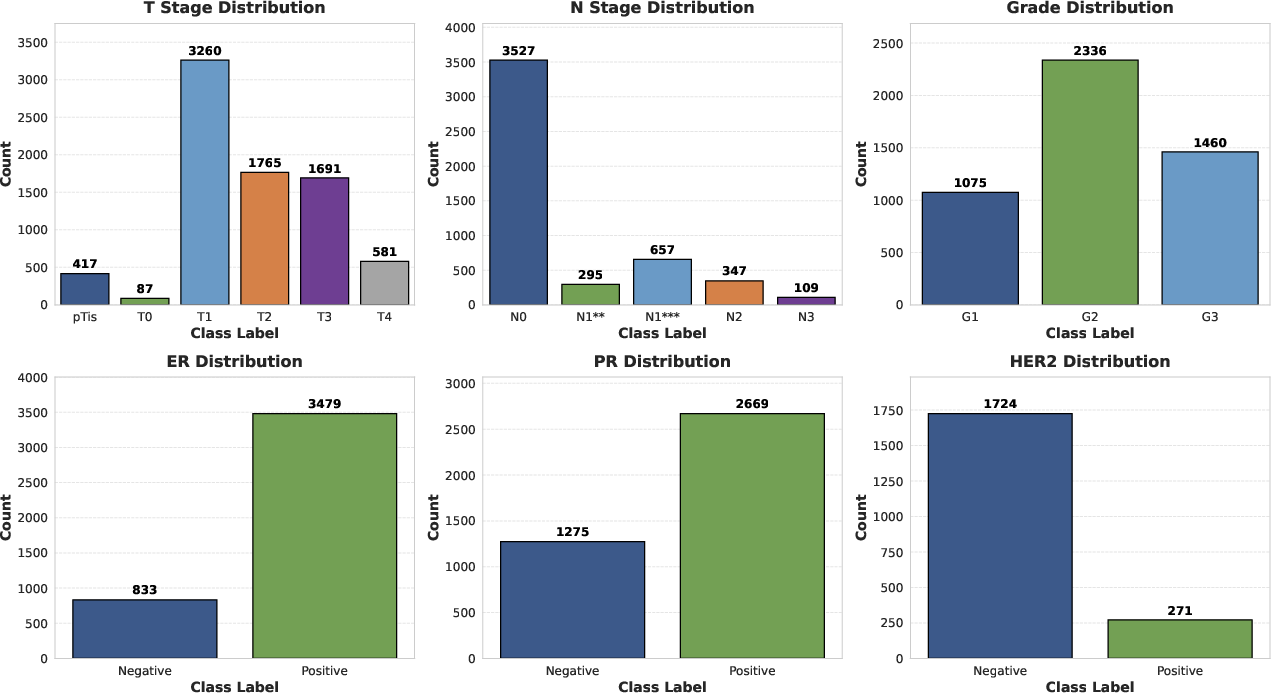
Figure 4: Distribution of ground truth classes for primary clinical variables, illustrating task-specific imbalance and sparsity in tail categories.
Experimental Design and Comparative Analysis
A rigorous ablation framework is employed, incorporating comparisons to legacy rule-based extraction, alternative parameter-efficient fine-tuning strategies (IA3, Prefix Tuning), single-task LLMs, and variants of semantic slicing for input text preprocessing.
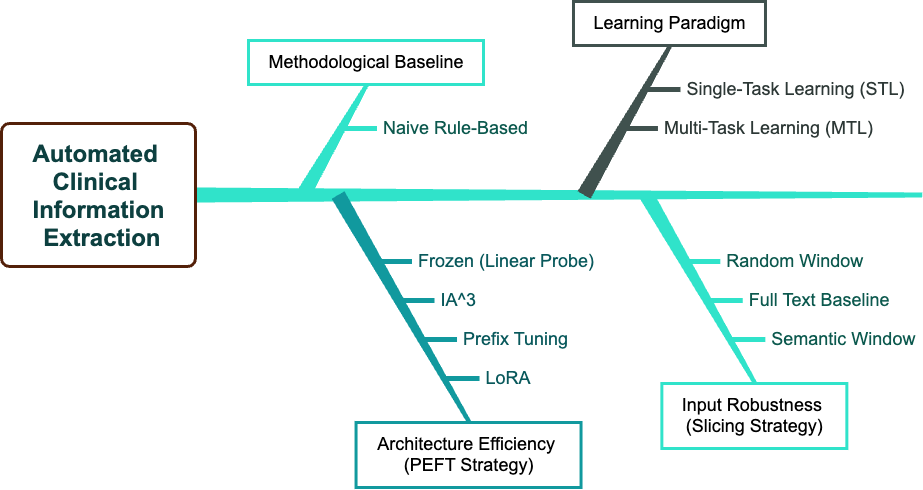
Figure 5: Overview of the multi-factorial experimental and ablation schema, capturing comparisons across methodology, adaptation technique, task-sharing strategy, and input slicing.
Results demonstrate that the LoRA-adapted multi-task LLM surpasses all baselines on both macro F1 and AUROC across tasks, reaching an overall Macro F1 of 0.976. For minority classes (HER2-positive, rare node/tumor stages), the joint MTL approach yields a marked boost in recall relative to single-task adapters, which exhibit catastrophic collapse under class imbalance.
The LoRA strategy also achieves superior training efficiency and wall-clock convergence compared to Prefix Tuning and IA3, with a modest increase in memory overhead that remains well within modern enterprise GPU budgets.
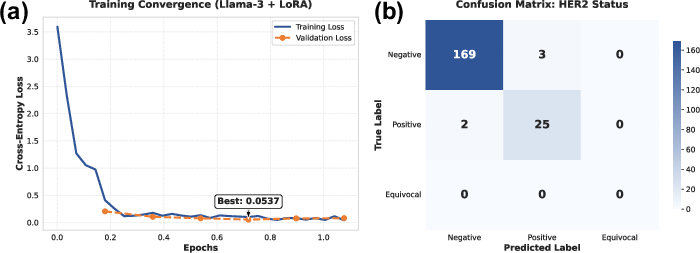
Figure 6: (a) Comparative training convergence and (b) HER2-specific classification performance, highlighting MTL effectiveness in minority recognition.
Implications and Future Perspective
This work provides an evidence-driven pathway for operationalizing LLM-based extraction systems in clinical registries, significantly mitigating the limitations of both fully generative LLM paradigms and rule-based approaches. By leveraging multi-task sharing, LoRA-based fine-tuning can accommodate severe data skew and cross-variable dependencies, resulting in robust extraction fidelity for both prevalent and rare oncologic endpoints. The entire framework is highly resource-efficient, favoring practical deployment in hospital or health system settings where full fine-tuning is infeasible.
Theoretically, this architecture substantiates the viability of freezing large-scale LLM backbones while achieving domain alignment via parameter-efficient modules even in biomedical domains with long-tailed and heterogeneous data. Practically, its use of structured classification heads obviates complex post-processing and hallucination filtering, facilitating scalable and interpretable integration with downstream clinical systems.
Future directions may address unsupervised domain adaptation across institutions, integration with image-level diagnostic modalities, continual learning for evolving clinical definitions, and expansion to other medical extraction tasks reliant on robust schema adherence and minority class discrimination.
Conclusion
The proposed parameter-efficient, multi-task LLM framework with LoRA fine-tuning provides a validated and scalable approach for automated extraction of cancer staging and biomarker profiles from heterogeneous pathology reports. The architecture’s explicit classification paradigm, combined with effective inductive transfer, achieves high-fidelity extraction even for minority classes and outperforms both traditional rule-based pipelines and leading PEFT alternatives. The work offers a transferable methodology for robust clinical data extraction and underscores the broader utility of adapter-based LLMs in healthcare-focused NLP.

