- The paper introduces a novel budget-aware routing framework that formulates context selection as a knapsack-constrained task using a submodular RCD objective.
- It presents a modular pipeline integrating unitization, feature extraction, and adaptive selector routing based on token budgets and document structure.
- Extensive evaluations across clinical and biomedical datasets demonstrate scalability, cost-efficiency, and enhanced performance in both extractive and generative tasks.
Budget-Aware Routing for Long Clinical Text: An Expert Analysis
Introduction
"Budget-Aware Routing for Long Clinical Text" (2605.00336) addresses the high computational cost and operational challenges posed by deploying LLMs in clinical settings, where long, heterogeneous documents are prevalent. Clinical inputs frequently exceed the feasible context window of state-of-the-art LLMs, resulting in scalability concerns regarding inference latency, deployment cost, and model utility. The paper formalizes context selection as a knapsack-constrained subset selection task, decomposing it into distinct unitization and selection steps. Crucially, it introduces both a new submodular objective function—Relevance, Coverage, Diversity (RCD)—and a routing heuristic that adapts selection strategy to budget and document characteristics.
The work systematically explores the interplay of token budget, unitization, and selector design across extractive and generative downstream tasks, using clinical, biomedical, and mixed-domain long-document datasets. The study establishes key performance regimes and provides empirical guidelines on selector routing, with theoretical and practical implications for scalable, cost-sensitive LLM deployment.
Methodological Framework
The authors implement a modular pipeline for budget-constrained context construction, consisting of four principal stages: unitization, representation, routing, and selection. The framework accepts a long document and token budget, producing a context of maximal expected utility for downstream generation or inference.
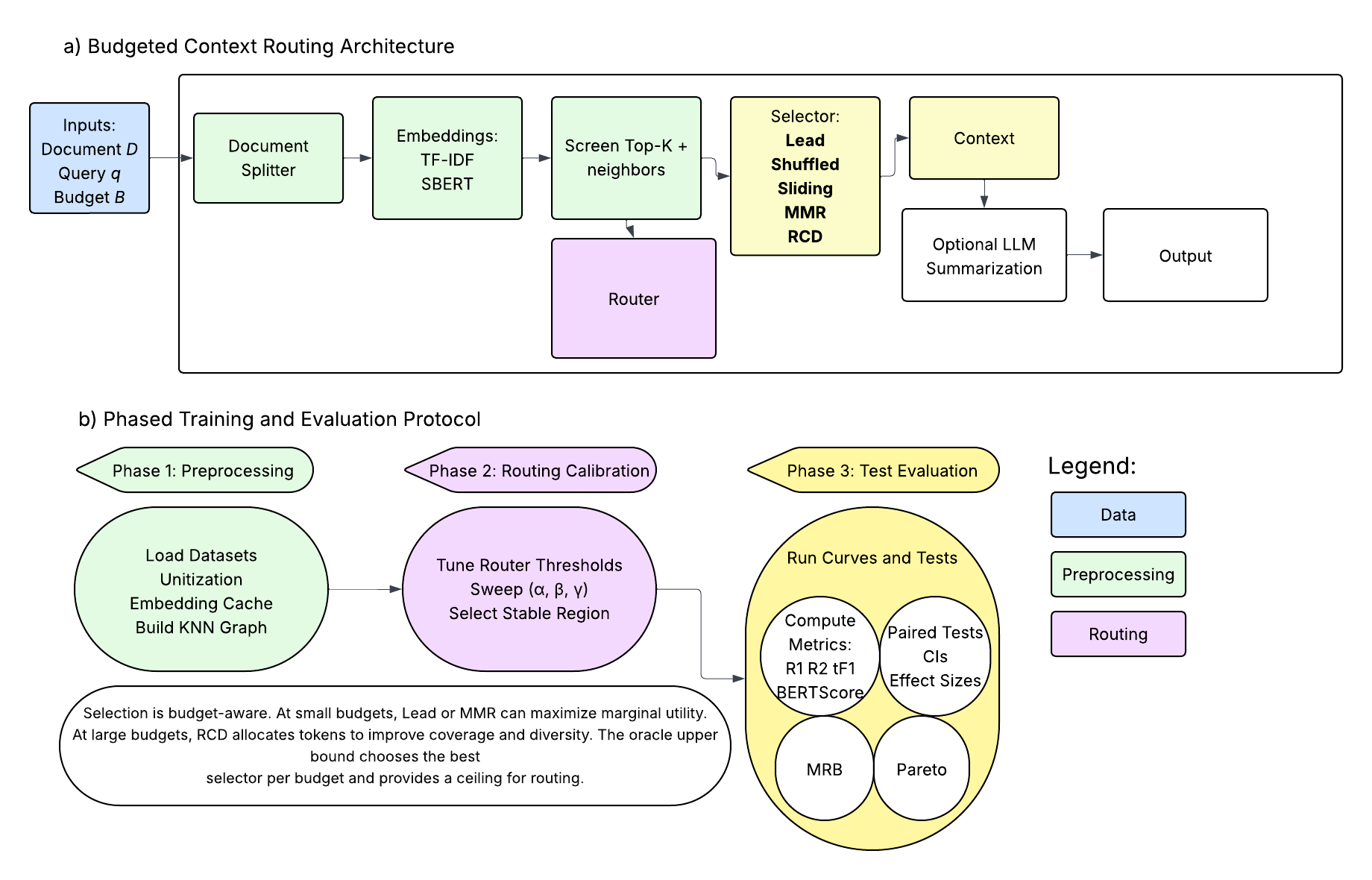
Figure 1: End-to-end architecture for budgeted context construction, comprising unitization, feature extraction, budget-aware routing, context construction, and evaluation across multiple datasets.
Unitization Strategies
Four unitization schemes are evaluated: sentence-based, section-based, windowed, and graph-based clustering. Each creates distinct selectable units, affecting selector flexibility and granularity. Sentence-unitization is the canonical choice due to the fine-grained control it offers, while section, window, and cluster-based schemes introduce structural and semantic priors.
Selection Algorithms
Selector families include:
- Lead and Shuffled: Position-based baselines.
- Sliding Window and Hierarchical: Local relevance maximization and contextual expansion.
- GraphCluster: Semantic clustering with representative sampling.
- Maximal Marginal Relevance (MMR): Greedy selection balancing relevance and redundancy through a tunable λ.
- RCD Objective: Submodular maximization combining query relevance, facility location-based coverage, and log-determinant diversity.
The RCD objective permits principled maximization under knapsack constraints, offering formal approximation guarantees and explicit control over tradeoffs.
Budget-Aware Routing
The signature contribution is a lightweight, validated router that selects the selector regime based on budget (token count) and corpus statistics, operationalized via a front-loading index (relevance mass in leading units) and redundancy index (local similarity). The routing heuristic maps budget intervals to selector families (Lead, MMR, RCD) with thresholds tuned for empirical performance.
Experimental Results
Extensive experiments are conducted on MIMIC discharge notes, Cochrane abstracts, L-Eval, and PubMedQA-L, varying budgets across typical context lengths (e.g., 256–16,384 tokens). Evaluation spans both extractive metrics (ROUGE, token-level F1) and LLM-mediated generation (ROUGE, BERTScore).
Performance varies significantly by selector and budget regime. In highly front-loaded clinical documents, Lead dominates at strict budgets due to alignment between document structure and reference summaries.
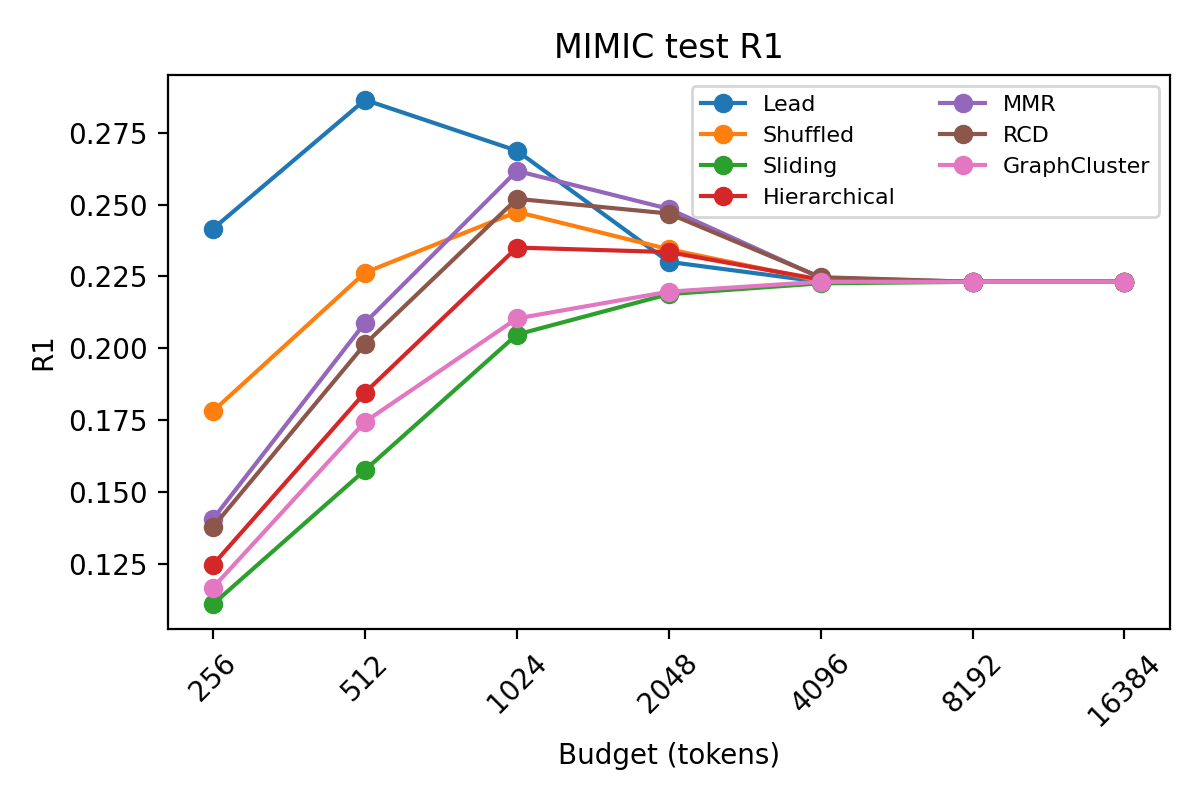
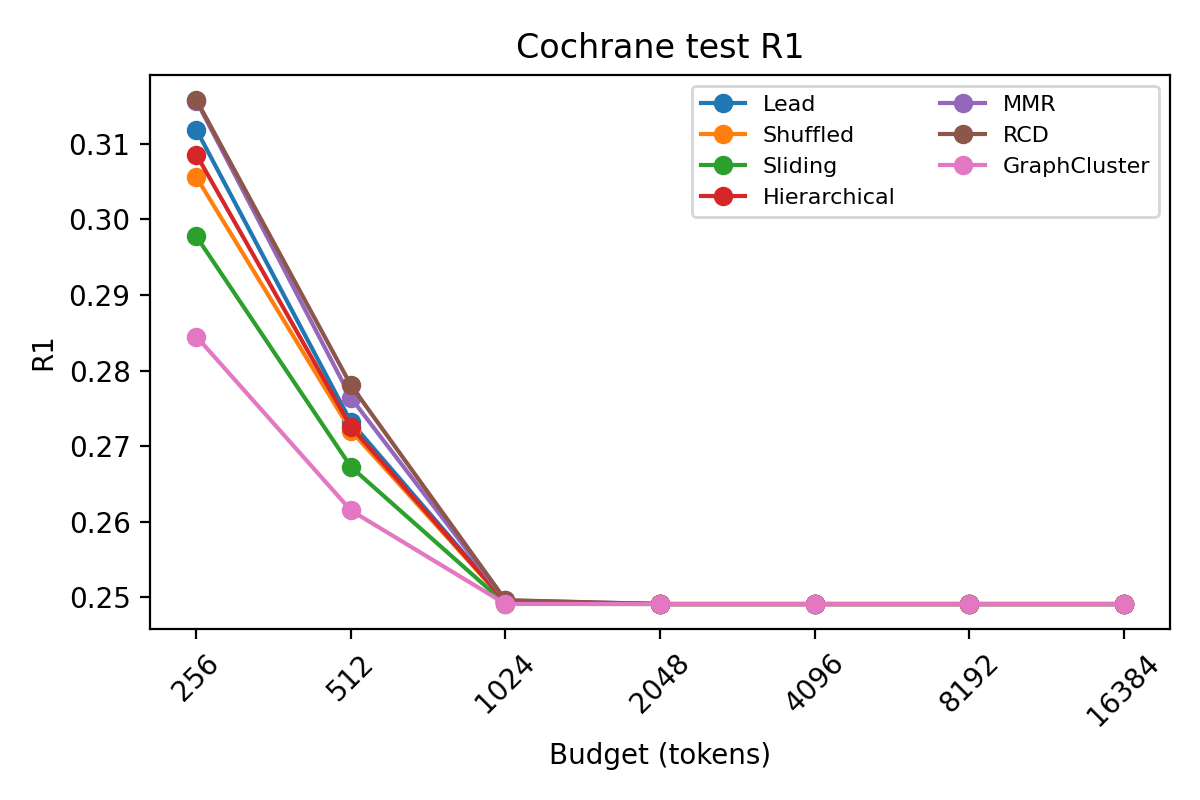
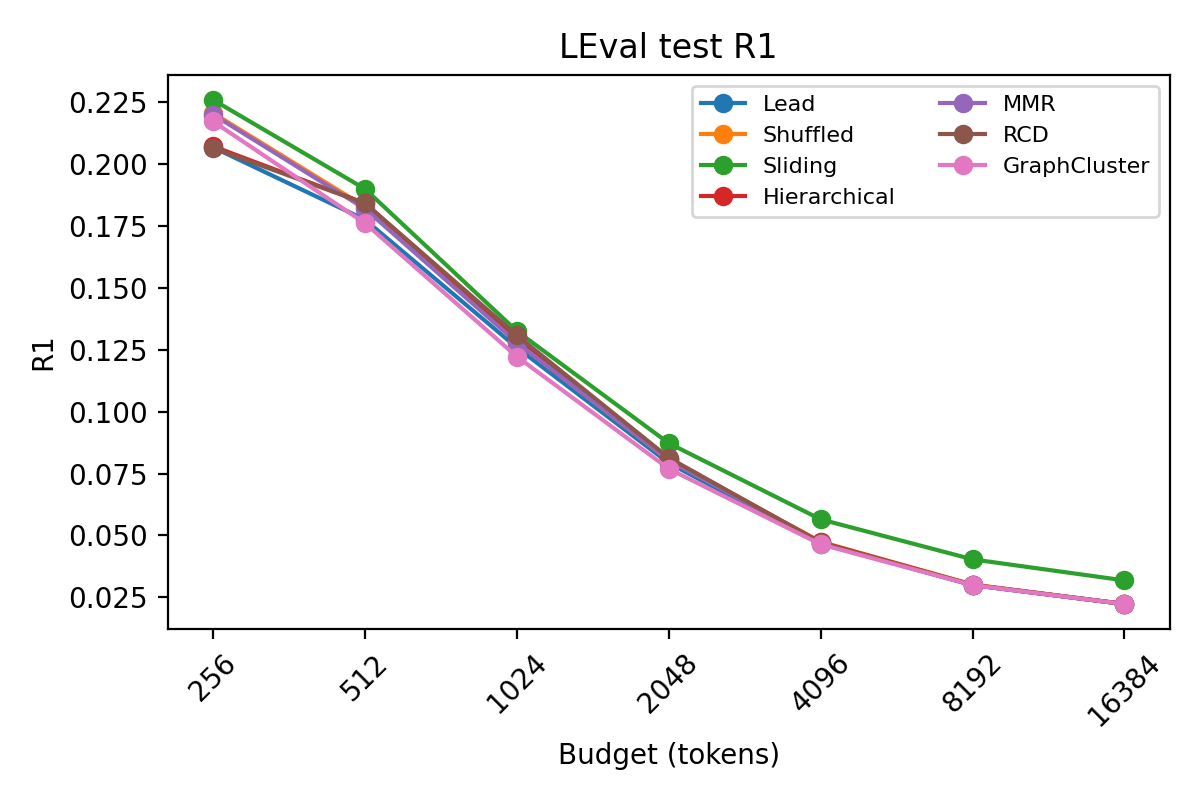
Figure 2: ROUGE-1 F1 score as a function of token budget on MIMIC, demonstrating Lead's superiority at low budget and MMR's gains at higher budgets.
Diversity and coverage become increasingly salient at higher budgets as redundancy limits positional heuristics. MMR and RCD outperform Lead in less-structured benchmarks and in non-front-loaded domains.
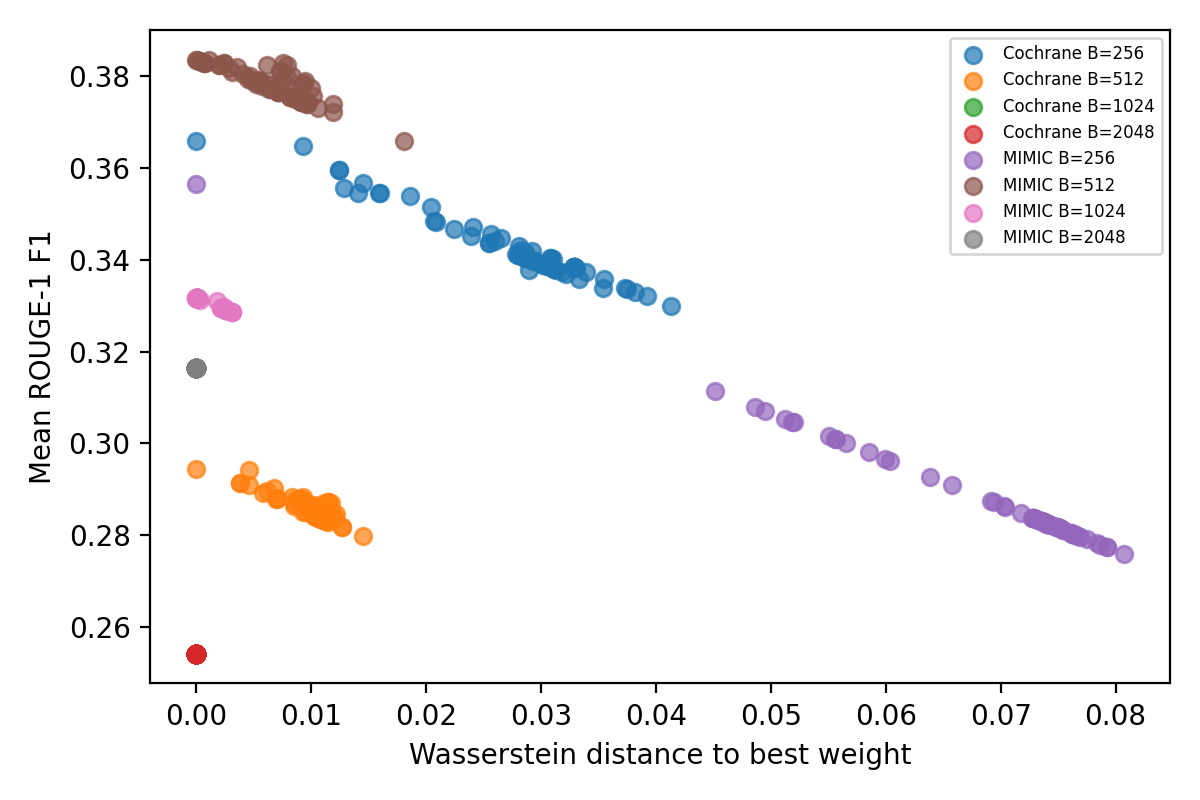
Figure 4: Robustness of ROUGE-1 F1 score to weight perturbation in RCD; performance degrades smoothly with increased distance from optimal weight configuration.
Generative (LLM-based) Evaluation
In generation tasks, diversity-aware selectors (MMR, RCD) consistently outperform positional baselines, despite only modest improvements under extractive metrics. BERTScore, capturing semantic similarity, reveals larger performance differentials than ROUGE, underscoring the limitations of n-gram overlap for abstractive summaries.
Budgeted selection at 512–1024 tokens recovers or surpasses full-context performance in MIMIC, indicating substantial redundancy in clinical narratives.
The proposed routing heuristic achieves near-oracle performance, closely tracking the empirical Pareto frontier across all datasets.
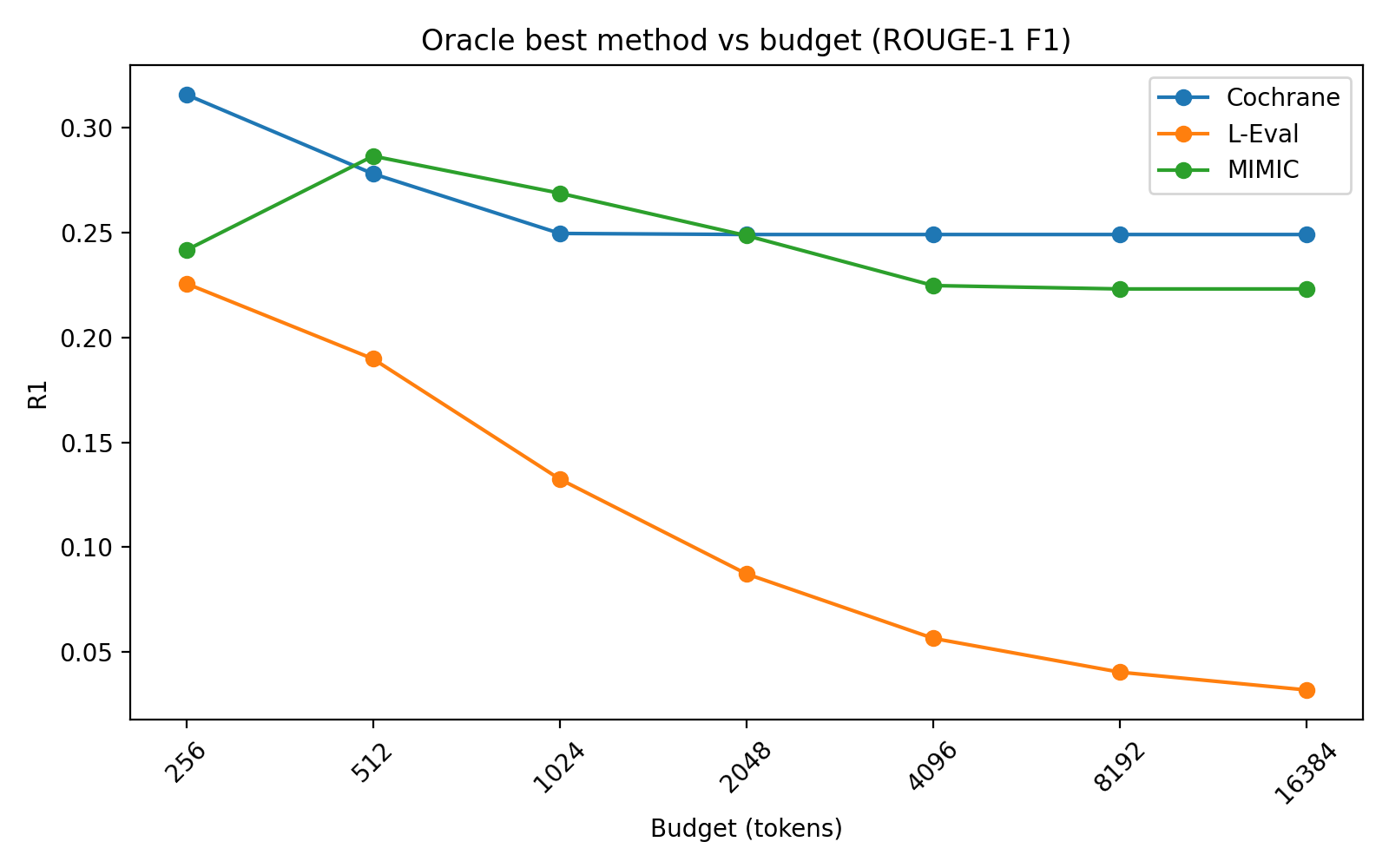
Figure 5: Pareto frontier for ROUGE-1 over budgets, showing the optimal policy performance at each budget for different datasets.
The router reliably selects between Lead (tight budgets), MMR (moderate budgets), and RCD (generous budgets), as confirmed by ablation and sensitivity analyses. Selector choice has a greater impact at low budgets; as budgets increase, method performance converges.
Generalization and Robustness
PubMedQA-L results highlight that positional heuristics can be actively harmful when sources lack front-loading; shuffled and diversity/coverage-based selectors significantly outperform Lead, affirming the utility of adaptive routing.
Sensitivity studies demonstrate that the RCD objective is robust to weight perturbation, and selector/budget routing yields stable, transferable performance across datasets and domains.
Theoretical and Practical Implications
The explicit factorization into unitization and selection—along with formal submodular guarantees—enables transparent, auditable, and efficient context curation for LLMs. This supports cost/latency-constrained scenario planning, auditable provenance, and scalable deployment in real clinical workflows. The budget-aware router provides an empirical recipe for method selection, facilitating operationalization in diverse environments.
From a theoretical perspective, the findings underscore the interaction between domain/structure (e.g., front-loaded vs. dispersed content), evaluation paradigm (extractive vs. generative), and budget regime. Notably, the redundancy inherent in clinical notes means aggressive abstraction and selection do not impair, and may even improve, downstream generation.
Practically, the work suggests that context selection modules should be decoupled and auditable in clinical NLP pipelines. Routine recalibration of routing policies and stratified performance monitoring are recommended to mitigate biases and maintain quality under evolving operational conditions.
Future Directions
Open research avenues include section-aware relevance modeling, hybridization with learned neural compression, and application to domains with less consistent editorial structure or higher evidentiary variability. Integration with task-conditioning (e.g., question-aware selection), targeted evaluation by clinical outcome, and model-in-the-loop adaptation will advance the fidelity and safety of plug-and-play LLM deployments in health and science.
Conclusion
This paper establishes budgeted context construction as a central design problem for real-world LLM applications and provides both the formal framework and empirical validation for selector routing across clinical and scientific domains. The modular system, submodular RCD objective, and practical routing heuristic enable substantial reductions in computational cost without sacrificing summary or inference quality, and generalize robustly to unseen domains and tasks. Future work should extend these principles to multi-task, multi-modal, and safety-critical settings.

