DPN-LE: Dual Personality Neuron Localization and Editing for Large Language Models
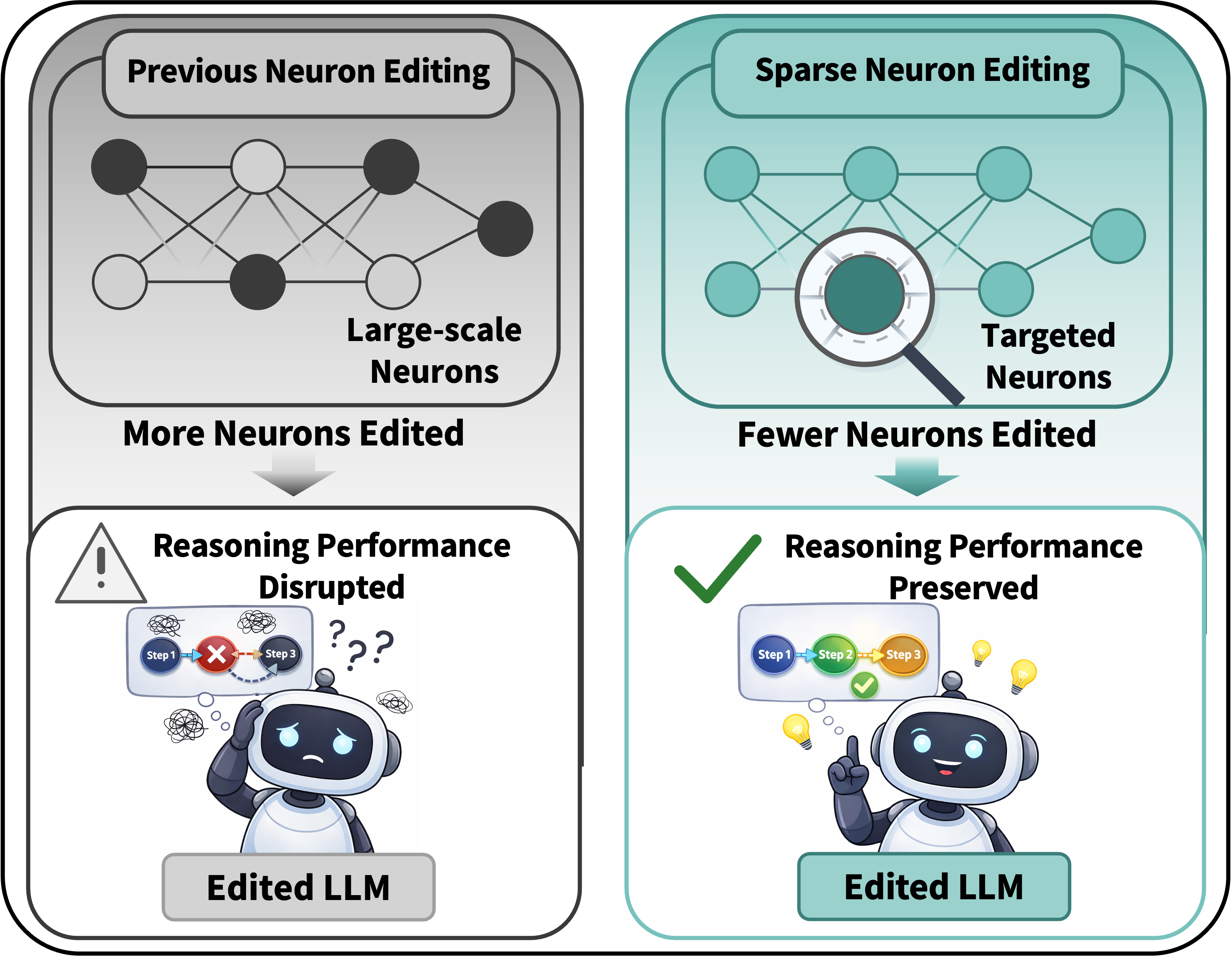
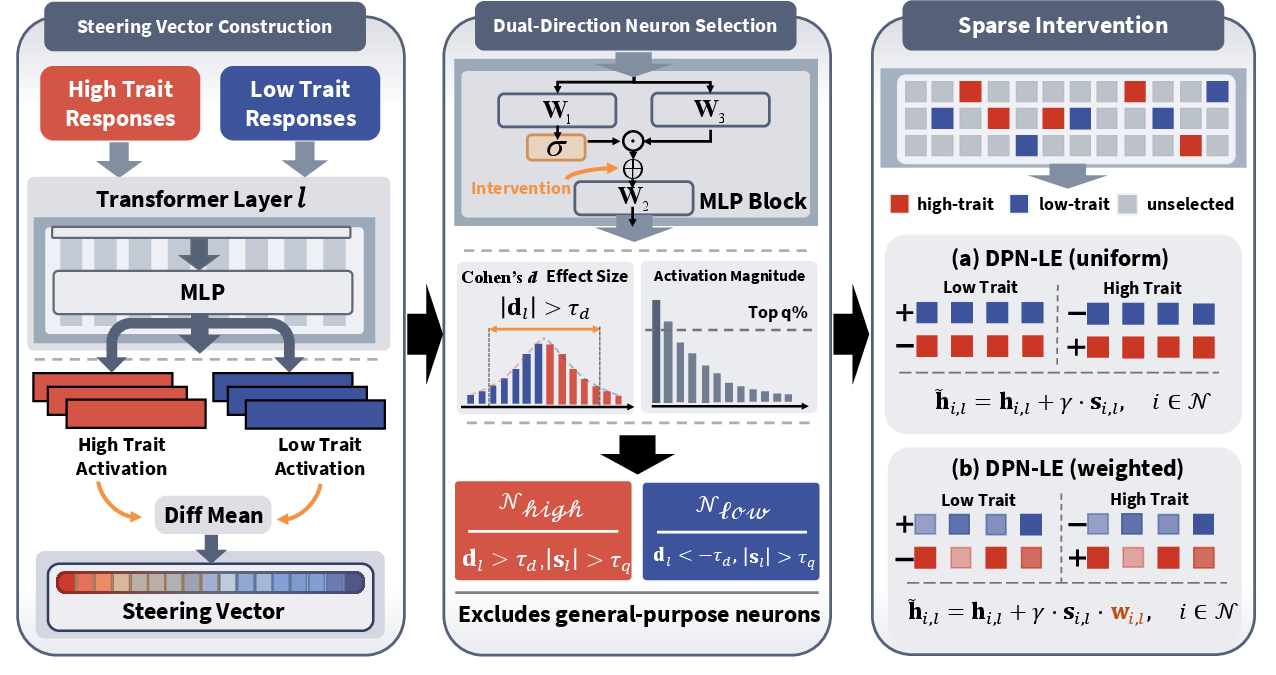
Abstract: With the widespread adoption of LLMs, understanding their personality representation mechanisms has become critical. As a novel paradigm in Personality Editing, most existing methods employ neuron-editing to locate and modify LLM neurons, requiring changes to numerous neurons and leading to significant performance degradation. This raises a fundamental question: Are all modified neurons directly related to personality representation? In this work, we investigate and quantify this specificity through assessments of general capability impact and representation-level patterns. We find that: 1) Current methods can change personalities but reduce overall performance. 2) Neurons are multifunctional, connecting personality traits and general knowledge. 3) Opposing personality traits demonstrate distinctly mutually exclusive representation patterns. Motivated by these findings, we propose DPN-LE (Dual Personality Neuron Localization and Editing), which identifies personality-specific neurons by contrasting MLP activations between high-trait and low-trait samples. DPN-LE constructs layer-wise steering vectors and applies dual-criterion filtering based on Cohen's $d$ effect size and activation magnitude to isolate mutually exclusive neuron subsets. Sparse linear intervention on these neurons enables precise personality control at inference time. Using only 1,000 contrastive sample pairs per trait, DPN-LE intervenes on $\sim$0.5\% of neurons while achieving competitive personality control and substantially better capability preservation across reasoning tasks. Experiments on LLaMA-3-8B-Instruct and Qwen2.5-7B-Instruct demonstrate the effectiveness and generalizability of our approach.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at how big LLMs (like chatbots) show “personality,” and how we can change that personality on purpose without breaking the model’s ability to think and answer questions well. The authors introduce a new method, called DPN-LE, that tweaks only a tiny fraction of the model’s internal parts to nudge it toward traits like being more friendly (agreeable) or more calm (low neuroticism), while keeping its reasoning skills mostly intact.
The main questions the paper asks
- Do current methods change far more of the model than necessary when trying to adjust personality?
- Can we find the specific “parts” inside the model that most directly relate to a personality trait?
- Is it possible to change personality during use (at inference time) while keeping math and fact skills strong?
How the researchers did it (in simple terms)
Think of a LLM as a huge soundboard with thousands of sliders (“neurons”) across many levels (“layers”). Personality shows up as certain patterns on this soundboard.
The researchers’ approach, DPN-LE, works like this:
- They collected pairs of examples for each trait, one showing a “high” version (e.g., very outgoing) and one showing a “low” version (e.g., very reserved).
- Inside the model, they watched which sliders moved differently for high vs. low examples. This difference is like a “direction” that tells you how to push the soundboard toward high or low personality.
- They picked only the sliders that were: 1) consistently different between high and low samples (measured with a simple statistic called Cohen’s d—think of it as “how much do these sliders really separate the two groups?”), and 2) strong enough to matter (high activation magnitude—“these sliders actually move a lot”).
- They then nudged just those selected sliders a small amount when the model was answering, without changing the model’s permanent settings.
There are two versions:
- DPN-LE: gently nudges all selected sliders equally.
- DPN-LE_w: nudges the most personality-specific sliders a bit more, and the less specific ones a bit less.
In everyday language: instead of turning lots of knobs all over the place, they find the few knobs that truly control “friendly vs. unfriendly” or “calm vs. anxious,” and tap those lightly.
What they found and why it matters
- Earlier methods changed personality but hurt general skills a lot. Some methods turned tens of thousands of knobs and made the model worse at math and fact questions.
- Neurons (the model’s tiny parts) are multitaskers. Many affect both personality and general knowledge, so changing too many at once causes trouble.
- Opposite traits (like high vs. low extraversion) show clear, opposite patterns inside the model—like two clusters that barely overlap. This helped them find the most trait-specific neurons.
- DPN-LE changes only about 0.5% of neurons per trait and still gets strong personality control.
- It keeps general abilities much better than older methods. For example, compared to a strong baseline method that often caused large drops on math problems, DPN-LE usually caused much smaller drops while still shifting personality effectively.
- It uses relatively little data: only 1,000 pairs of examples per trait to learn where to nudge.
- It works across different models (tested on LLaMA-3-8B-Instruct and Qwen2.5-7B-Instruct).
Why this is important: It shows we can adjust a model’s “style” (how it talks and behaves) without sacrificing “substance” (its ability to reason and recall facts).
What this could lead to
- Safer, more dependable role-playing and social interaction: A chatbot could be gently made more empathetic or more direct depending on the situation, without becoming worse at answering correctly.
- Better understanding of how personality is represented inside AI models: Knowing where and how traits live in the model can guide future tools and safety measures.
- Practical control at runtime: Because DPN-LE only nudges a few neurons when the model is running, it doesn’t need retraining.
A few caveats:
- It relies on good example pairs to tell “high” from “low” personality. Weak examples mean weaker control.
- Some trait directions still affect math skills more than others (e.g., making the model more reserved/extraverted in certain ways).
- The paper focuses on one trait at a time; combining multiple traits is future work.
- There’s a trade-off: DPN-LE preserves reasoning well, but some methods that change many more neurons may match very detailed, individual personality tests slightly better.
In short
DPN-LE is a smart, precise way to locate the few parts of a LLM that mainly control personality and tweak only those. This keeps the model’s core abilities much stronger than older methods while still letting you raise or lower a personality trait like turning a careful set of knobs on a soundboard.
Knowledge Gaps
Below is a single consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved in the paper. Each point is phrased to be actionable for future research.
- Causal specificity of selected neurons: Beyond correlational selection via effect sizes, do targeted causal ablations (silencing vs. enhancing) of the chosen neurons alone produce the observed trait changes without unintended side effects?
- Component and position coverage: The method focuses on MLP activations at the last token; does neuron localization in attention heads and residual streams, and at different token positions (early, mid, all tokens), yield better control–capability trade-offs?
- Layer selection procedure: Layers are chosen via PCA-based separation; can more principled or automated criteria (e.g., CKA, mutual information, probing accuracy, causal tracing) identify optimal layer ranges per trait?
- Hyperparameter sensitivity and calibration: How sensitive are outcomes to thresholds (Cohen’s d, quantiles) and intervention strength γ across models and datasets? Can data-driven or automated hyperparameter tuning (e.g., Bayesian optimization on a held-out set) improve stability?
- Trait exclusivity quantification: The paper posits mutual exclusivity of opposing traits; how strongly do high- and low-trait neuron sets overlap across layers, and can exclusivity be formally quantified and statistically tested?
- Content/style confounds in contrastive pairs: Do high- vs. low-trait samples differ in topical content or stylistic artifacts that confound neuron selection? Controlled, content-matched contrastive pairs or counterbalanced designs are needed.
- Sample complexity and data quality: What is the minimum number of contrastive pairs needed for stable neuron selection, and how do results vary with different data sources (human-authored vs. model-generated, domains, cultural contexts)?
- Cross-run reproducibility: Are the selected neuron sets stable across different random seeds, sampling procedures, and runs? Report overlap metrics (e.g., Jaccard) and variance in downstream effects.
- Cross-trait interference: How does editing one trait alter other Big Five traits (e.g., unintended increases or decreases)? Can orthogonalization of steering vectors or constrained optimization minimize cross-trait leakage?
- Multi-trait composition: What happens when simultaneously steering multiple traits (additive vs. interfering effects)? Are interventions commutative and stable under composition?
- Reasoning-protective selection (proposed but not implemented): Can neurons predictive of reasoning performance (e.g., via probing on GSM8K features) be explicitly excluded to mitigate capability drops, especially for Extraversion-low and Neuroticism-high?
- Generalization across model families: Do findings hold for larger models (e.g., 13B–70B), different activations (ReLU vs. SwiGLU), and architectures (MoE, state space models)? How does the fraction of neurons required scale with model size?
- Multilingual and cross-cultural robustness: Are neuron sets and steering vectors language- and culture-dependent? Evaluate and (if needed) adapt selection for non-English tasks and culturally diverse personality constructs.
- Long-horizon and multi-turn stability: Does control persist over long responses and extended dialogues (persona drift), and how does the effect decay across turns without reapplication?
- Robustness to prompting/decoding: How stable is personality control under varied prompts, conversation contexts, and decoding settings (temperature, top-p), including adversarial or jailbreak prompts?
- Broader capability impacts: Beyond GSM8K, HotpotQA, and TriviaQA, what are the effects on MMLU, ARC, BBH, code generation, calibration, perplexity, and long-context tasks?
- Safety and alignment side effects: Does low-trait steering (e.g., low Agreeableness) increase toxicity, harassment, or jailbreak rates? How does personality control interact with guardrails and RLHF alignment?
- Latency and systems overhead: What is the runtime and memory cost of per-layer, per-neuron interventions in real-time generation, and can efficient implementations (e.g., fused kernels, caching) reduce overhead?
- Mechanistic interpretability: What are the functions of the selected neurons and their circuit-level interactions? Do similar circuits recur across models, and can we identify interpretable features they encode?
- Directionality and causation: Do “high-trait” vs. “low-trait” neuron sets exert symmetric causal influence, or is suppression inherently harder? Are different mechanisms needed for inhibition vs. enhancement?
- Adaptive and context-aware interventions: Instead of fixed γ and uniform application across steps/layers, can per-token or context-conditioned schedules reduce capability degradation while preserving control?
- Improved individual alignment: Given weaker IPIP-NEO-300 alignment than some baselines, can per-example adaptive strengths, user-conditioned steering, or small learned adapters (e.g., LoRA) enhance alignment without sacrificing capabilities?
- Trait-layer heterogeneity: Do different traits peak in separability at different layer ranges? A trait-specific layer selection study could reveal fine-grained maps of personality representation across depth.
- Residual vs. MLP intervention comparison: Does steering the residual stream (as in activation addition) or mixing residual and MLP edits yield superior control with lower side effects than MLP-only edits?
- Tool use and agentic settings: How does personality steering affect tool selection, planning, and function-calling behavior in agent frameworks?
- Cross-dataset leakage and OOD tests: Are steering vectors overfitted to the datasets used for selection/evaluation? Test on disjoint, out-of-domain corpora and unseen prompt templates to assess true generalization.
- Ethical deployment and user consent: What mechanisms ensure transparent and consentful personality manipulation in user-facing systems, and how can misuse (e.g., deceptive personas) be prevented?
Practical Applications
Overview
Based on the paper’s findings, DPN-LE offers a training-free, inference-time method to control an LLM’s expressed personality by sparsely intervening on approximately 0.5% of MLP neurons identified via contrastive activation analysis (using Cohen’s d and activation magnitude). This preserves general capabilities substantially better than prior neuron-editing methods while enabling precise, switchable trait expression. Below are concrete applications, organized by deployment horizon, with sectors, potential tools/workflows, and feasibility notes.
Immediate Applications
These can be implemented now with open-weight models (e.g., LLaMA-3-8B-Instruct, Qwen2.5-7B) or any model that exposes internal activations at inference.
- Customer support and marketing (Software, Customer Experience)
- Use case: Brand-aligned chatbots with tunable tone (e.g., high Agreeableness for empathy, high Conscientiousness for structure) that preserve reasoning in troubleshooting and knowledge-grounded tasks.
- How: Precompute per-trait steering vectors with ~1,000 contrastive sample pairs; apply DPN-LE at inference as a “personality dial.”
- Tools/products/workflows: Inference middleware that hooks MLP activations and applies sparse, layer-wise offsets; persona presets (“Brand Friendly,” “Formal Pro,” “Concise Advisor”).
- Assumptions/dependencies: Access to model internals (open weights or APIs with activation hooks); hyperparameter tuning (γ, quantile q) to balance tone and capability; brand/legal review.
- Entertainment and gaming (Interactive media)
- Use case: Consistent, distinct NPC personalities for dialogue and narrative, with minimal logic/performance loss.
- How: Assign character-specific neuron subsets and intervention strengths; toggle or blend during scenes.
- Tools/products/workflows: “Persona manager” per character; offline evaluation for stability across contexts.
- Assumptions/dependencies: Latency budget for activation edits; dataset quality for each persona.
- Education and tutoring (EdTech)
- Use case: Adaptive tutor tone—e.g., high Agreeableness for anxious learners, high Conscientiousness for structured learners—while retaining problem-solving performance.
- How: Runtime DPN-LE adjustments per student preference or lesson context.
- Tools/products/workflows: Student preference profiling; A/B tests measuring learning outcomes and satisfaction.
- Assumptions/dependencies: Human-in-the-loop oversight; guardrails; trait-direction combos (e.g., Extraversion-low) may impact reasoning more and need careful tuning.
- Healthcare-facing support chat (Healthcare, Wellness)
- Use case: Patient-facing assistants exhibiting calibrated empathy and patience without degrading factual guidance.
- How: Emphasize Agreeableness/Neuroticism-high or -low within safe bounds; freeze domain reasoning layers if available.
- Tools/products/workflows: Safety filters; escalation workflows to clinicians; audit logs of intervention settings.
- Assumptions/dependencies: Regulatory/safety review; this is not a medical device unless validated; clinical oversight required.
- Safety red teaming and behavior audits (AI Safety, Compliance)
- Use case: Stress-test LLM safety under extreme trait settings (high/low) to uncover risk profiles and failure modes; evaluate robustness trade-offs.
- How: Systematically sweep traits and γ; run standard safety suites; log performance deltas (e.g., GSM8K/QA) alongside safety events.
- Tools/products/workflows: Red-teaming harness with persona toggles; dashboards showing Cohen’s d-selected neurons and measured impacts.
- Assumptions/dependencies: Access to internal activations; safety governance processes to act on findings.
- Mechanistic interpretability and personality research (Academia, R&D)
- Use case: Study mutually exclusive neuron sets for opposing traits; quantify multifunctionality vs. trait exclusivity; replicate across architectures.
- How: Use the paper’s PCA and dual-criterion neuron selection; analyze layer-wise separations (e.g., LLaMA layer 12+).
- Tools/products/workflows: Neuron browsers; effect-size reports; cross-benchmark evaluation.
- Assumptions/dependencies: Open models; consistent evaluation data; reproducibility practices.
- Enterprise MLOps and customization without fine-tuning (Software, Platform)
- Use case: Ship one base model with switchable personas instead of multiple fine-tuned variants.
- How: Store neuron subsets and steering vectors as small persona artifacts; enable runtime selection per tenant or user.
- Tools/products/workflows: Persona registry; inference-time policy engine; tracing/observability for interventions.
- Assumptions/dependencies: Model architecture stability across versions; inference stack that supports activation interception.
- Rapid A/B testing of tone and conversion (E-commerce, Sales)
- Use case: Test how persona settings affect click-through, satisfaction, or escalation rates without retraining.
- How: Assign cohorts to high/low Agreeableness/Extraversion; monitor KPIs and reasoning metrics.
- Tools/products/workflows: Experiment orchestration with intervention logging; conversion analytics.
- Assumptions/dependencies: Ethical review; avoid manipulative designs; ensure performance parity.
- Formality and tone control beyond “personality” (Cross-sector communications)
- Use case: Swap between formal vs. casual, direct vs. tentative styles by creating relevant contrastive pairs and neuron sets.
- How: Treat style dimensions as traits; compute steering vectors with domain-specific pairs.
- Tools/products/workflows: Style libraries; editorial QA loops.
- Assumptions/dependencies: Quality of contrastive data; cultural/regional adaptation.
- Finance and legal assistants (Finance, LegalTech)
- Use case: Maintain a compliant, professional tone while preserving analytical rigor in advice and summarization.
- How: Boost Conscientiousness-like traits; cap γ to avoid math/QA degradation; add compliance guardrails.
- Tools/products/workflows: Persona presets reviewed by compliance; automated regression tests on reasoning benchmarks.
- Assumptions/dependencies: Domain risk assessments; strong evaluation of edge cases.
Long-Term Applications
These require further research, scaling, or integration work (e.g., better “reasoning-protective” selection, multi-trait control, clinical validation, standardization).
- Multi-trait composition and blending (Software, HRI, EdTech)
- Use case: Simultaneous control of multiple traits (e.g., high Agreeableness + medium Extraversion) with guaranteed capability preservation.
- R&D needs: Algorithms to resolve trait interactions; explicit exclusion of reasoning-critical neurons; stability under long dialogues.
- Personalized, adaptive personas (Cross-sector)
- Use case: Agents that learn user-preferred tone and adapt over sessions while preserving safety and performance.
- R&D needs: Online/adaptive neuron-weighting; privacy-preserving preference learning; drift detection.
- Clinical-grade AI companions and coaching (Healthcare, Wellness)
- Use case: Empathic, consistent assistants for mental health support or chronic condition coaching.
- R&D needs: Controlled trials; regulatory approval; culturally sensitive trait calibration; robust guardrails.
- Standards and audits for “personality governance” (Policy, Compliance)
- Use case: Regulated disclosure and auditing of persona controls in deployed AI systems.
- R&D needs: Standard metrics for capability preservation vs. personality strength; audit artifacts (neuron lists, effect sizes, logs); certification frameworks.
- Training and assessment simulators (HR, Education, Public Safety)
- Use case: Interview or negotiation simulators with controlled counterparts (e.g., low Agreeableness for stress training).
- R&D needs: Task-outcome validation; bias and fairness audits across demographics; scenario libraries.
- Robust safety hardening via neuron-level constraints (AI Safety)
- Use case: Lock-in safe stylistic defaults and prevent jailbreaks that exploit tone shifts.
- R&D needs: Automatic detection of reasoning neurons and safety-critical neurons; “reasoning-protective” filters as proposed in the paper’s limitations.
- Cross-cultural and domain-specific personality frameworks (Global products)
- Use case: Trait sets that reflect local norms beyond the Big Five; domain-specific “bedside manner,” “investor-relations tone,” etc.
- R&D needs: New contrastive datasets; validation across languages and cultures; fairness evaluation.
- Model distillation/pruning with preserved persona (ML Systems)
- Use case: Distill or prune models while maintaining controllable persona and core capabilities.
- R&D needs: Use neuron importance maps for compression; evaluate trade-offs on reasoning and personality control.
- Low-latency production integration (Infra)
- Use case: Deploy neuron-level control in high-throughput serving stacks (vLLM/TensorRT-LLM) with minimal overhead.
- R&D needs: Kernel-level hooks for MLP activation editing; caching and batching for steering vectors.
- Agent teams with complementary personas (Multi-agent systems)
- Use case: Ensembles of agents with diverse personalities for brainstorming, debate, and consensus, improving outcomes.
- R&D needs: Coordination protocols; measurement of diversity benefits; stability and safety controls.
- Social robots and embodied systems (Robotics)
- Use case: Personality-consistent verbal interaction in service robots (hospitality, eldercare) that preserves task reliability.
- R&D needs: Multimodal extension to VLMs; HRI trials; safety and acceptance studies.
Key Dependencies and Assumptions (cross-cutting)
- Model access: DPN-LE requires access to internal MLP activations; most feasible with open-weight models or APIs that expose activation hooks.
- Data quality: Contrastive sample pairs (≈1,000 per trait) must represent desired trait expressions; cultural and domain adaptation may be necessary.
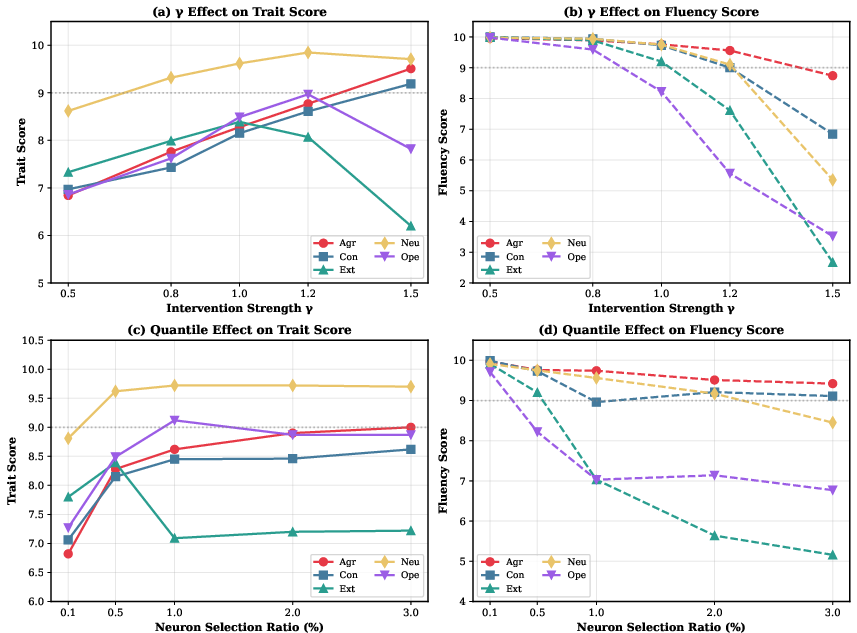
- Capability trade-offs: Certain trait-direction combinations (e.g., Extraversion-low, Neuroticism-high) can more strongly impact reasoning; careful γ and neuron selection tuning is required.
- Evaluation and guardrails: Always test on reasoning (e.g., GSM8K/QA) and safety metrics after persona changes; include human review in high-stakes domains.
- Governance and ethics: Avoid manipulative or discriminatory use of personality control; document interventions, disclose persona settings where appropriate, and comply with domain regulations.
Glossary
- Activation steering: A technique that controls a model’s behavior by adding carefully constructed vectors to its internal activations during inference. "Activation steering controls model behavior by adding steering vectors to internal representations during inference"
- Attention heads: Components in Transformer architectures that attend to different parts of the input; here, specific heads are targeted for personality alignment. "identifies effective attention heads and optimizes activation offsets for personality alignment"
- Big Five model: A psychological framework describing five broad personality traits used to assess or induce personality in LLMs. "such as the Big Five model"
- CAA: A method that constructs and adds contrastive activation differences to steer model behavior. "CAA constructs steering vectors by averaging activation differences between contrastive examples, then adds them to the residual stream at all token positions"
- Causal tracing: Techniques that trace and manipulate internal components causally responsible for specific knowledge or behaviors. "ROME and MEMIT further develop causal tracing techniques to locate and edit factual associations in MLP layers"
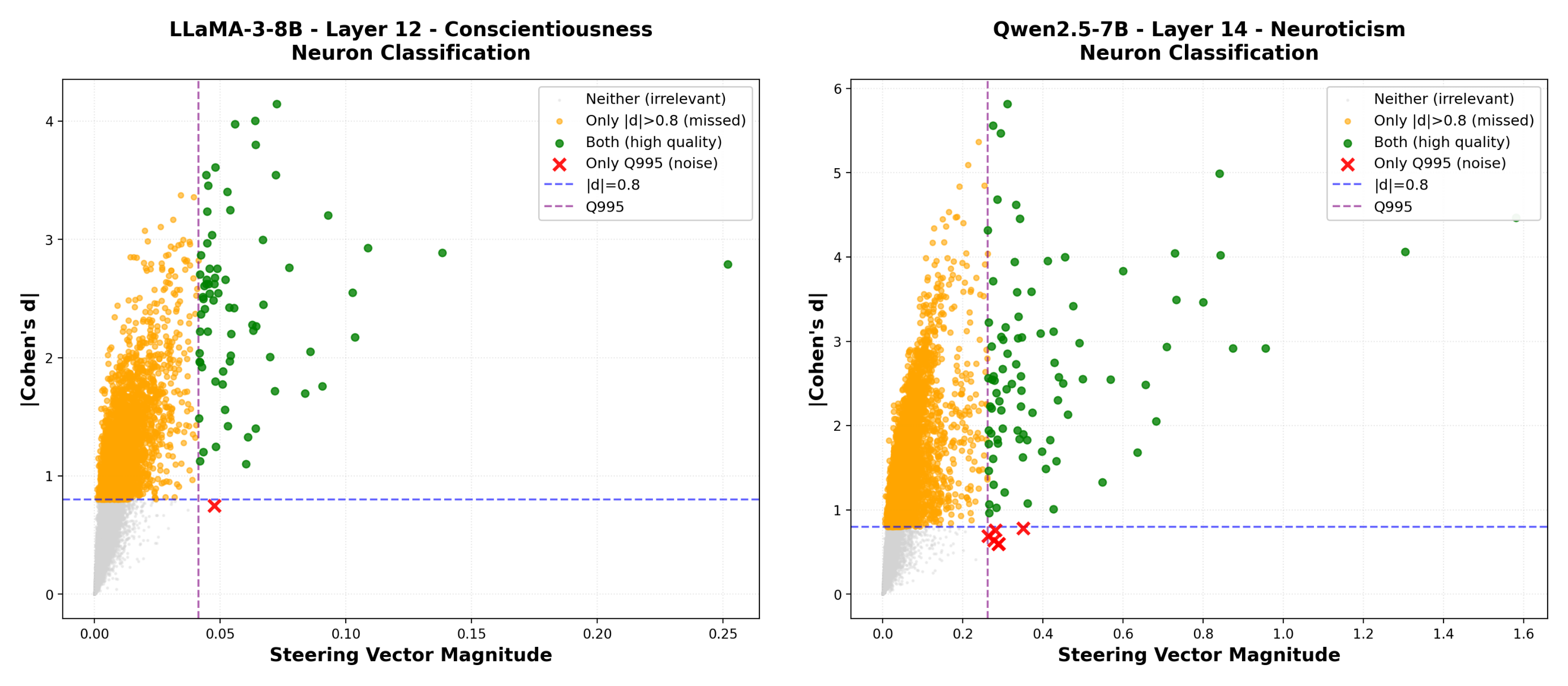
- Cohen’s d effect size: A standardized measure of the difference between two groups’ means, expressed in standard deviation units, used to select trait-specific neurons. "based on Cohen's effect size and activation magnitude"
- Contrastive sample pairs: Pairs of inputs that differ along a target trait (e.g., high vs. low) used to isolate relevant activations. "Using only 1,000 contrastive sample pairs per trait"
- Dual-criterion filtering: A neuron selection approach combining an effect-size threshold with an activation-magnitude quantile to isolate trait-specific neurons. "applies dual-criterion filtering (Cohen's threshold and quantile threshold) to select trait-exclusive neurons"
- Exact Match (EM): A QA metric requiring exact string equality between the prediction and the ground truth. "we report Exact Match (EM), which requires exact string matching between prediction and ground truth"
- F1 score: A QA metric measuring token-level overlap between prediction and ground truth, balancing precision and recall. "and F1 score, which measures token-level overlap"
- Gated activation: The post-nonlinearity activation in an MLP that includes a gating mechanism (e.g., GELU/SwiGLU), from which hidden states are extracted. "computed after the gated activation"
- GSM8K: A benchmark dataset for evaluating mathematical reasoning in LLMs. "GSM8K for mathematical reasoning (Accuracy)"
- HotpotQA: A dataset for multi-hop question answering used to evaluate reasoning abilities. "HotpotQA for multi-hop question answering"
- Inference-time intervention: Modifying a model’s internal activations during inference rather than retraining, to change behavior. "The inference-time intervention is straightforward to implement"
- IPIP-NEO-300: A 300-item multiple-choice personality questionnaire used to assess alignment with human personality profiles. "IPIP-NEO-300: a multiple-choice personality questionnaire"
- Layer-wise steering vectors: Steering vectors computed separately for each Transformer layer to guide trait expression. "constructs layer-wise steering vectors from MLP activations"
- LLaMA-3-8B-Instruct: An instruction-tuned 8B-parameter LLaMA model variant used as a testbed. "Experiments on LLaMA-3-8B-Instruct and Qwen2.5-7B-Instruct demonstrate the effectiveness and generalizability of our approach"
- MEMIT: A method for mass-editing model memories by locating and modifying factual associations. "ROME and MEMIT further develop causal tracing techniques to locate and edit factual associations in MLP layers"
- MLP activations: The neuron activations within the model’s feed-forward (MLP) sublayers that are analyzed or modified for steering. "identifies personality-specific neurons by contrasting MLP activations between high-trait and low-trait samples"
- NPTI: Neuron-based Personality Trait Induction; a method that identifies neurons differing between high- and low-trait expressions and modulates them. "NPTI identifies neurons that activate differently for high versus low trait expressions by computing activation probability differences."
- PCA (Principal Component Analysis): A dimensionality-reduction technique used to analyze and visualize activation patterns in representation space. "we employ Principal Component Analysis (PCA) to characterize the activation patterns at the internal representation level"
- PersonalityBench: A dataset used to evaluate and induce personality traits in LLMs. "NPTI identifies approximately 20,000 neurons per trait through the PersonalityBench dataset"
- Pooled standard deviation: A combined standard deviation estimate across two groups used in calculating effect sizes like Cohen’s d. "where $\sigma_{\mathrm{pooled}$ is the pooled standard deviation."
- Quantile threshold: A cutoff selecting the top proportion (e.g., 0.5%) of neurons by activation magnitude for intervention. "applies dual-criterion filtering (Cohen's threshold and quantile threshold) to select trait-exclusive neurons"
- Residual stream: The main pathway in a Transformer that accumulates layer outputs; steering vectors can be added here to affect behavior. "adds them to the residual stream at all token positions"
- ROME: A method for locating and editing factual associations within Transformer MLP layers. "ROME and MEMIT further develop causal tracing techniques to locate and edit factual associations in MLP layers"
- Sigmoid-weighted modulation: A modulation scheme applying a sigmoid-based weighting to activation edits. "we use enhancement coefficient with sigmoid-weighted modulation"
- Sparse linear intervention: Adding a sparse linear offset to selected neurons’ activations to control behavior with minimal side effects. "Sparse linear intervention on these neurons enables precise personality control at inference time."
- Steering vector: A vector computed from activation differences (e.g., between high- and low-trait inputs) used to push activations toward a desired direction. "The steering vector is computed as the mean activation difference:"
- Trait-exclusive neurons: Neurons that respond strongly to only one direction of a personality trait (high or low), enabling precise control. "there exist trait-exclusive neurons that respond strongly to only one direction."
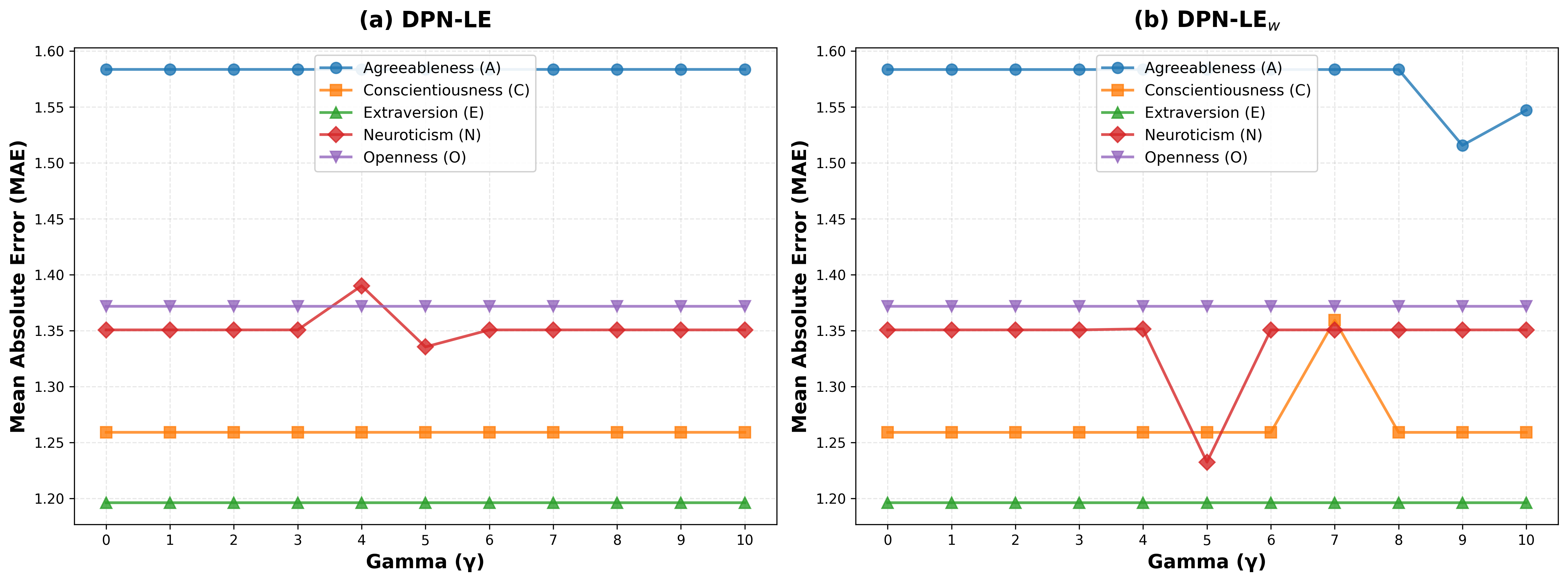
- Weighted intervention: An intervention strategy that scales steering by weights (e.g., based on effect size) across selected neurons. "DPN-LE (weighted intervention): When selecting more neurons"
Collections
Sign up for free to add this paper to one or more collections.