Personality Traits in Large Language Models
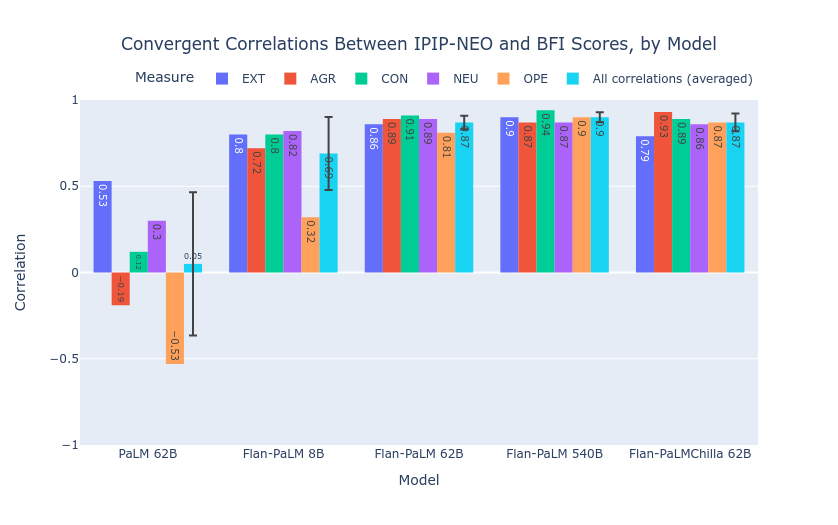
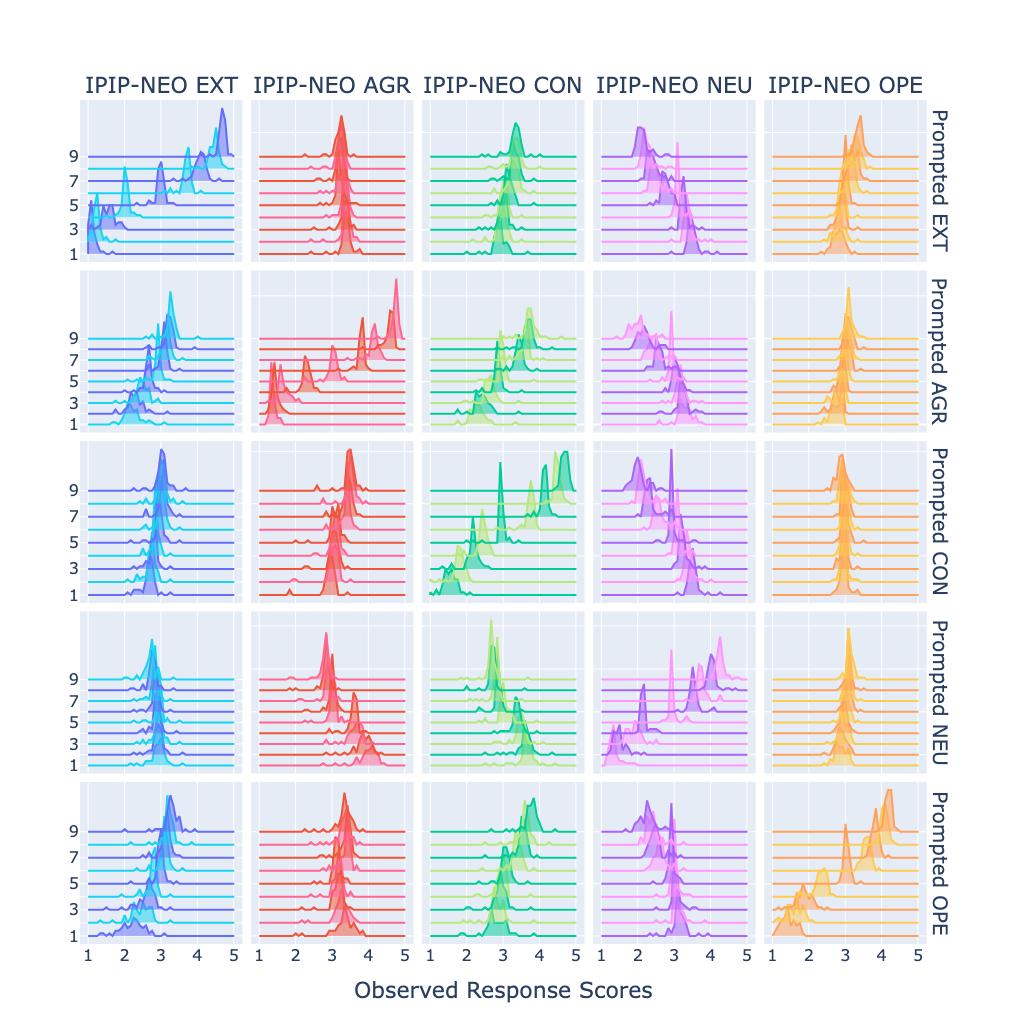
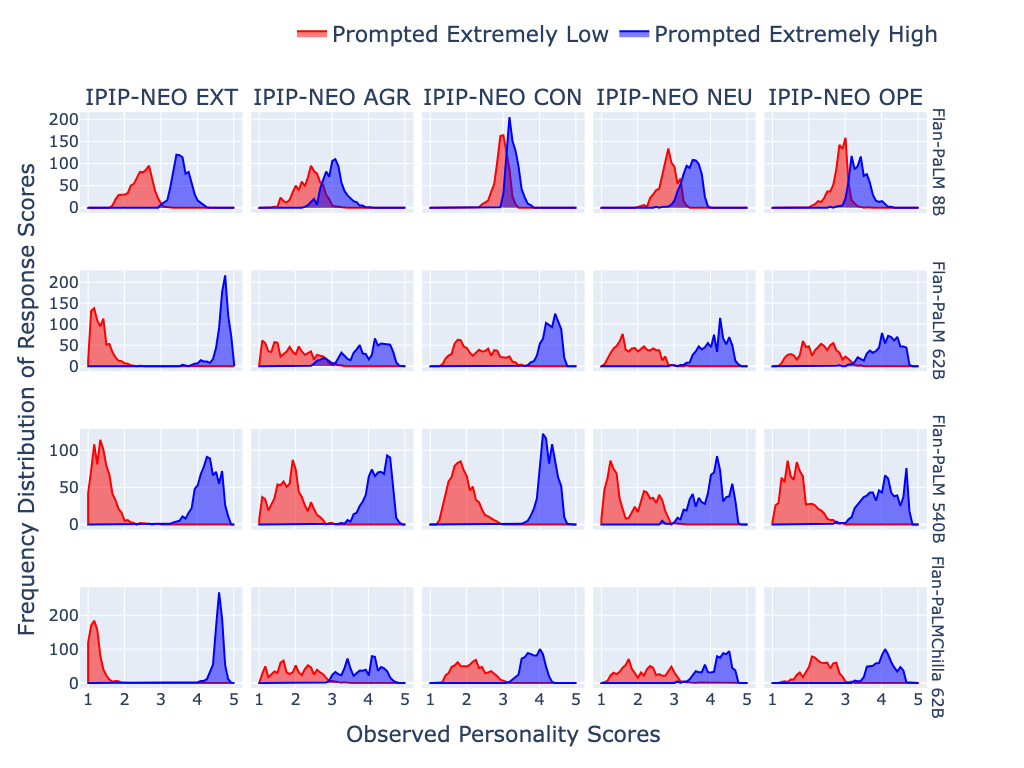
Abstract: The advent of LLMs has revolutionized natural language processing, enabling the generation of coherent and contextually relevant human-like text. As LLMs increasingly powerconversational agents used by the general public world-wide, the synthetic personality traits embedded in these models, by virtue of training on large amounts of human data, is becoming increasingly important. Since personality is a key factor determining the effectiveness of communication, we present a novel and comprehensive psychometrically valid and reliable methodology for administering and validating personality tests on widely-used LLMs, as well as for shaping personality in the generated text of such LLMs. Applying this method to 18 LLMs, we found: 1) personality measurements in the outputs of some LLMs under specific prompting configurations are reliable and valid; 2) evidence of reliability and validity of synthetic LLM personality is stronger for larger and instruction fine-tuned models; and 3) personality in LLM outputs can be shaped along desired dimensions to mimic specific human personality profiles. We discuss the application and ethical implications of the measurement and shaping method, in particular regarding responsible AI.
- Moral foundations of large language models. In AAAI 2023 Workshop on Representation Learning for Responsible Human-Centric AI, 2022.
- G. Allport. Personality: A Psychological Interpretation. H. Holt, 1937.
- Standards for educational and psychological testing. American Educational Research Association, Lanham, MD, Mar. 2014.
- Standards for Educational and Psychological Testing. American Educational Research Association, 2014.
- Neural machine translation by jointly learning to align and translate. In Y. Bengio and Y. LeCun, editors, 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7–9, 2015, Conference Track Proceedings, 2015.
- Psychometric properties of the Beck Depression Inventory: Twenty-five years of evaluation. Clinical Psychology Review, 8(1):77–100, 1988.
- On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’21, page 610–623, New York, NY, USA, 2021. Association for Computing Machinery.
- B. A. Bettencourt and C. Kernahan. A meta-analysis of aggression in the presence of violent cues: Effects of gender differences and aversive provocation. Aggressive Behavior, 23(6):447–456, 1997.
- The policy relevance of personality traits. American Psychologist, 74(9):1056, 2019.
- Language-based personality: A new approach to personality in a digital world. Current Opinion in Behavioral Sciences, 18:63–68, 2017. Big data in the behavioural sciences.
- Language models are few-shot learners. In H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 1,877–1,901. Curran Associates, Inc., 2020.
- Convergent and discriminant validation by the multitrait-multimethod matrix. Psychological Bulletin, 56(2):81, 1959.
- G. Caron and S. Srivastava. Identifying and manipulating the personality traits of language models. CoRR, abs/2212.10276, 2022.
- Evaluating large language models trained on code. CoRR, abs/2107.03374, 2021.
- PaLM: Scaling language modeling with pathways. CoRR, abs/2204.02311, 2022.
- Scaling instruction-finetuned language models. CoRR, abs/2210.11416, 2022.
- L. A. Clark and D. Watson. Constructing validity: Basic issues in objective scale development. Psychological Assessment, 7(3):309, 1995.
- L. A. Clark and D. Watson. Constructing validity: New developments in creating objective measuring instruments. Psychological Assessment, 31(12):1412, 2019.
- P. T. Costa, Jr. and R. R. McCrae. Revised NEO Personality Inventory (NEO PI-R) and NEO Five-Factor Inventory (NEO-FFI): Professional Manual. Psychological Assessment Resources, Odessa, FL, 1992.
- L. J. Cronbach. Coefficient alpha and the internal structure of tests. Psychometrika, 16(3):297–334, 1951.
- Common Crawl Foundation., 2008.
- C. G. DeYoung. Toward a theory of the Big Five. Psychological Inquiry, 21(1):26–33, 2010.
- Personality neuroscience: An emerging field with bright prospects. Personality Science, 3:1–21, 2022.
- Testing predictions from personality neuroscience: Brain structure and the Big Five. Psychological Science, 21(6):820–828, 2010.
- J. D. Evans. Straightforward Statistics for the Behavioral Sciences. Brooks/Cole Publishing Co, 1996.
- R. Fischer and D. Boer. Motivational basis of personality traits: A meta-analysis of value-personality correlations. Journal of Personality, 83(5):491–510, 2015.
- I. Gabriel. Artificial intelligence, values, and alignment. Minds and machines, 30(3):411–437, 2020.
- I. Gabriel and V. Ghazavi. The Challenge of Value Alignment: From Fairer Algorithms to AI Safety. In The Oxford Handbook of Digital Ethics. Oxford University Press.
- F. Galton. Measurement of character. Fortnightly Review, 36:179–85, 1884.
- The pile: An 800gb dataset of diverse text for language modeling. CoRR, abs/2101.00027, 2020.
- L. R. Goldberg. Language and individual differences: The search for universals in personality lexicons. Review of Personality and Social Psychology, 2(1):141–165, 1981.
- L. R. Goldberg. The development of markers for the Big-Five factor structure. Psychological Assessment, 4(1):26–42, 1992.
- L. R. Goldberg. A broad-bandwidth, public domain, personality inventory measuring the lower-level facets of several Five-Factor models. Personality Psychology in Europe, 7(1):7–28, 1999.
- Omega over alpha for reliability estimation of unidimensional communication measures. Annals of the International Communication Association, 44(4):422–439, 2020.
- L. Guttman. A basis for analyzing test-retest reliability. Psychometrika, 10(4):255–282, 1945.
- T. Hagendorff. Machine psychology: Investigating emergent capabilities and behavior in large language models using psychological methods. CoRR, abs/2303.13988, 2023.
- C. Hare and K. T. Poole. Psychometric Methods in Political Science, chapter 28, pages 901–931. John Wiley & Sons, Ltd, 2018.
- Personality: The universal and the culturally specific. Annual Review of Psychology, 60(1):369–394, 2009.
- Measuring massive multitask language understanding. In International Conference on Learning Representations, 2021.
- An empirical analysis of compute-optimal large language model training. In A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho, editors, Advances in Neural Information Processing Systems, 2022.
- A. Z. Jacobs. Measurement as governance in and for responsible AI. CoRR, abs/2109.05658, 2021.
- Can large language models truly understand prompts? a case study with negated prompts. In A. Albalak, C. Zhou, C. Raffel, D. Ramachandran, S. Ruder, and X. Ma, editors, Proceedings of The 1st Transfer Learning for Natural Language Processing Workshop, volume 203 of Proceedings of Machine Learning Research, pages 52–62. PMLR, 03 Dec 2023.
- Compiling measurement invariant short scales in cross-cultural personality assessment using ant colony optimization. European Journal of Personality, 34(3):470–485, 2020.
- Evaluating and inducing personality in pre-trained language models. CoRR, abs/2206.07550, 2023.
- Personallm: Investigating the ability of gpt-3.5 to express personality traits and gender differences. CoRR, abs/2305.02547, 2023.
- How can we know when language models know? on the calibration of language models for question answering. Transactions of the Association for Computational Linguistics, 9:962–977, 09 2021.
- Paradigm shift to the integrative Big Five trait taxonomy: History, measurement, and conceptual issues. In O. P. John, R. W. Robbins, and L. A. Pervin, editors, Handbook of Personality: Theory and Research, pages 114–158. The Guilford Press, 2008.
- O. P. John and S. Srivastava. The Big Five trait taxonomy: History, measurement, and theoretical perspectives. In L. A. Pervin and O. P. John, editors, Handbook of Personality: Theory and Research, volume 2, pages 102–138. Guilford Press, New York, 1999.
- Scaling laws for neural language models. CoRR, abs/2001.08361, 2020.
- Estimating the personality of white-box language models. CoRR, abs/2204.12000, 2023.
- Big Five personality traits as the predictors of creative self-efficacy and creative personal identity: Does gender matter? The Journal of Creative Behavior, 47(3):215–232, 2013.
- The personalization of conversational agents in health care: Systematic review. J Med Internet Res, 21(11):e15360, Nov 2019.
- Large language models are zero-shot reasoners. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 22199–22213. Curran Associates, Inc., 2022.
- Facebook as a research tool for the social sciences: Opportunities, challenges, ethical considerations, and practical guidelines. American Psychologist, 70(6):543, 2015.
- Private traits and attributes are predictable from digital records of human behavior. Proceedings of the National Academy of Sciences, 110(15):5802–5805, 2013.
- Linking “big” personality traits to anxiety, depressive, and substance use disorders: A meta-analysis. Psychological Bulletin, 136(5):768, 2010.
- An evaluation of a cognitive theory of response-order effects in survey measurement. Public Opinion Quarterly, 51(2):201–219, 1987.
- K. Lee and M. C. Ashton. Psychometric properties of the HEXACO Personality Inventory. Multivariate Behavioral Research, 39(2):329–358, 2004.
- Does GPT-3 demonstrate psychopathy? evaluating large language models from a psychological perspective. CoRR, abs/2212.10529, 2023.
- Towards understanding and mitigating social biases in language models. CoRR, abs/2106.13219, 2021.
- R. Likert. A Technique for the Measurement of Attitudes. Number 136–165. Archives of Psychology, 1932.
- TruthfulQA: Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3,214–3,252, Dublin, Ireland, May 2022. Association for Computational Linguistics.
- Lost in the middle: How language models use long contexts. CoRR, abs/2307.03172, 2023.
- Perfect: Prompt-free and efficient few-shot learning with language models. CoRR, abs/2204.01172, 2022.
- Dissociating language and thought in large language models: A cognitive perspective. CoRR, abs/2301.06627, 2023.
- Building a large annotated corpus of English: The Penn Treebank. Computational Linguistics, 19(2):313–330, 1993.
- Psychological framing as an effective approach to real-life persuasive communication. ACR North American Advances, 2017.
- R. R. McCrae and A. Terracciano. Universal features of personality traits from the observer’s perspective: Data from 50 cultures. Journal of Personality and Social Psychology, 88(3):547, 2005.
- R. P. McDonald. Test theory: A unified treatment. Lawrence Erlbaum Associates Publishers, 1999.
- Pointer sentinel mixture models. In International Conference on Learning Representations, 2017.
- S. Messick. Standards of validity and the validity of standards in performance asessment. Educational Measurement: Issues and Practice, 14(4):5–8, 1995.
- S. Messick. Test validity: A matter of consequence. Social Indicators Research, 45:35–44, 1998.
- Rethinking the role of demonstrations: What makes in-context learning work? CoRR, abs/2202.12837, 2022.
- Who is GPT-3? an exploration of personality, values and demographics. In Proceedings of the Fifth Workshop on Natural Language Processing and Computational Social Science (NLP+CSS), pages 218–227, Abu Dhabi, UAE, Nov. 2022. Association for Computational Linguistics.
- M. Mitchell and D. C. Krakauer. The debate over understanding in ai’s large language models. Proceedings of the National Academy of Sciences, 120(13):e2215907120, 2023.
- Auditing large language models: A three-layered approach. AI and Ethics, pages 1–31, 2023.
- D. Nettle. The evolution of personality variation in humans and other animals. American Psychologist, 61(6):622, 2006.
- U. of Cambridge Psychometrics Centre. Apply Magic Sauce API.
- OpenAI. ChatGPT, 2022.
- OpenAI. GPT-4 technical report. CoRR, abs/2303.08774, 2023.
- Training language models to follow instructions with human feedback. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 27,730–27,744. Curran Associates, Inc., 2022.
- The LAMBADA dataset: Word prediction requiring a broad discourse context. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1,525–1,534, Berlin, Germany, Aug. 2016. Association for Computational Linguistics.
- Automatic personality assessment through social media language. Journal of Personality and Social Psychology, 108(6):934, 2015.
- Meta-analytic five-factor model personality intercorrelations: Eeny, meeny, miney, moe, how, which, why, and where to go. Journal of Applied Psychology, 105:1490–1529, 2020.
- Personality traits and personal values: A meta-analysis. Personality and Social Psychology Review, 19(1):3–29, 2015.
- Large language models open up new opportunities and challenges for psychometric assessment of artificial intelligence. Oct. 2022.
- Linguistic styles: Language use as an individual difference. Journal of Personality and Social Psychology, 77(6):1296, 1999.
- Common method biases in behavioral research: A critical review of the literature and recommended remedies. Journal of Applied Psychology, 88(5):879–903, 2003.
- The NLP task effectiveness of long-range transformers. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 3774–3790, Dubrovnik, Croatia, May 2023. Association for Computational Linguistics.
- Lingua franca of personality: Taxonomies and structures based on the psycholexical approach. Journal of Cross-Cultural Psychology, 29(1):212–232, 1998.
- B. W. Roberts. A revised sociogenomic model of personality traits. Journal of Personality, 86(1):23–35, 2018.
- The power of personality: The comparative validity of personality traits, socioeconomic status, and cognitive ability for predicting important life outcomes. Perspectives on Psychological science, 2(4):313–345, 2007.
- Personality psychology. Annual Review of Psychology, 73(1):489–516, 2022.
- J.-P. Rolland. The cross-cultural generalizability of the Five-Factor model of personality. In R. R. McCrae and J. Allik, editors, The Five-Factor Model of Personality Across Cultures, pages 7–28. Springer US, Boston, MA, 2002.
- Modern Psychometrics: The Science of Psychological Assessment. Routledge, 4 edition, 2020.
- G. Saucier and L. R. Goldberg. Lexical studies of indigenous personality factors: Premises, products, and prospects. Journal of Personality, 69(6):847–879, 2001.
- Large pre-trained language models contain human-like biases of what is right and wrong to do. Nature Machine Intelligence, 4(3):258–268, 2022.
- Personality, gender, and age in the language of social media: The open-vocabulary approach. PLOS ONE, 8(9):1–16, 09 2013.
- PsyBORGS: Psychometric Benchmark of Racism, Generalization, and Stereotyping.
- Measuring creative self-efficacy: An item response theory analysis of the Creative Self-Efficacy Scale. Frontiers in Psychology, 12:678033, 2021.
- Language models that seek for knowledge: Modular search & generation for dialogue and prompt completion. CoRR, abs/2203.13224, 2022.
- Assessment of the Five Factor Model. In T. A. Widiger, editor, The Oxford Handbook of the Five Factor Model, pages 353–380. Oxford University Press, 05 2017.
- U. Singh and P. Aarabhi. Can AI have a personality? In 2023 IEEE Conference on Artificial Intelligence (CAI), pages 205–206, 2023.
- Have large language models developed a personality?: Applicability of self-assessment tests in measuring personality in LLMs. CoRR, abs/2305.14693, 2023.
- Do long-range language models actually use long-range context? In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 807–822, Online and Punta Cana, Dominican Republic, Nov. 2021. Association for Computational Linguistics.
- The science of detecting LLM-generated texts. CoRR, abs/2303.07205, 2023.
- User–robot personality matching and assistive robot behavior adaptation for post-stroke rehabilitation therapy. Intell. Serv. Robot., 1(2):169–183, Apr. 2008.
- Language models can generate human-like self-reports of emotion. In 27th International Conference on Intelligent User Interfaces, IUI ’22 Companion, pages 69–72, New York, NY, USA, 2022. Association for Computing Machinery.
- Llama: Open and efficient foundation language models. CoRR, abs/2302.13971, 2023.
- T. Ullman. Large language models fail on trivial alterations to theory-of-mind tasks. CoRR, abs/2302.08399, 2023.
- Trojan horse or useful helper? a relationship perspective on artificial intelligence assistants with humanlike features. Journal of the Academy of Marketing Science, pages 1–23, 2022.
- Attention is all you need. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017.
- D. Watson and L. A. Clark. On traits and temperament: General and specific factors of emotional experience and their relation to the Five-Factor model. Journal of Personality, 60(2):441–476, 1992.
- D. Wechsler. The measurement of adult intelligence (3rd ed.). Williams & Wilkins Co, Baltimore, 1946.
- Finetuned language models are zero-shot learners. In International Conference on Learning Representations, 2022.
- Emergent abilities of large language models. Transactions on Machine Learning Research, 2022.
- Larger language models do in-context learning differently. CoRR, abs/2303.03846, 2023.
- Taxonomy of risks posed by language models. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’22, page 214–229, New York, NY, USA, 2022. Association for Computing Machinery.
- A comprehensive study on post-training quantization for large language models. CoRR, abs/2303.08302, 2023.
- Measuring personality in wave I of the national longitudinal study of adolescent health. Front. Psychol., 2:158, July 2011.
- Computer-based personality judgments are more accurate than those made by humans. Proceedings of the National Academy of Sciences, 112(4):1036–1040, 2015.
- Why Johnny can’t prompt: How non-AI experts try (and fail) to design LLM prompts. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, CHI ’23, New York, NY, USA, 2023. Association for Computing Machinery.
- Personalizing dialogue agents: I have a dog, do you have pets too? In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2204–2213, Melbourne, Australia, July 2018. Association for Computational Linguistics.
- A survey of large language models. CoRR, abs/2303.18223, 2023.
- Fine-tuning language models from human preferences. CoRR, abs/1909.08593, 2020.
- M. Zimmerman. Diagnosing personality disorders: A review of issues and research methods. Archives of general psychiatry, 51(3):225–245, 1994.
- Cronbach’s α𝛼\alphaitalic_α, revelle’s β𝛽\betaitalic_β, and mcdonald’s ω𝜔\omegaitalic_ω h: Their relations with each other and two alternative conceptualizations of reliability. Psychometrika, 70:123–133, 2005.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

