- The paper introduces an agentic pipeline that integrates KGs with LLMs, enhancing compliance reasoning with clear policy grounding.
- It employs a detailed methodology including document chunking, entity-relation extraction, and evidence synthesis for regulatory Q&A.
- Experimental results show increased accuracy and transparency in compliance tasks, highlighting trade-offs between closed and open schema approaches.
Knowledge Graph Representations for LLM-Based Policy Compliance Reasoning: A Technical Synthesis
Introduction and Motivation
The proliferation of AI systems has led to an urgent need for robust compliance mechanisms, particularly as regulatory frameworks such as the EU AI Act, the NIST AI RMF, and the OWASP Top 10 continue to diversify and overlap in their requirements. Manual navigation of these heterogeneous sources is impractical at scale, necessitating automated, reliable policy reasoning. Current LLMs, while potent, operate primarily with parametric, ungrounded knowledge, limiting their ability to cite or reason over specific policy requirements. Knowledge Graphs (KGs) offer structured grounding by encapsulating policy documents as discrete, interlinked entities and relations, which can augment LLM reasoning with provenance and explicit semantics.
Agentic Framework for Policy Compliance Reasoning
This work proposes an agentic pipeline that constructs and leverages KGs to enhance LLM-based policy compliance Q&A. The pipeline comprises four stages—document chunking, knowledge graph extraction, retrieval, and answer synthesis—each delegated to specialized LLM agents.
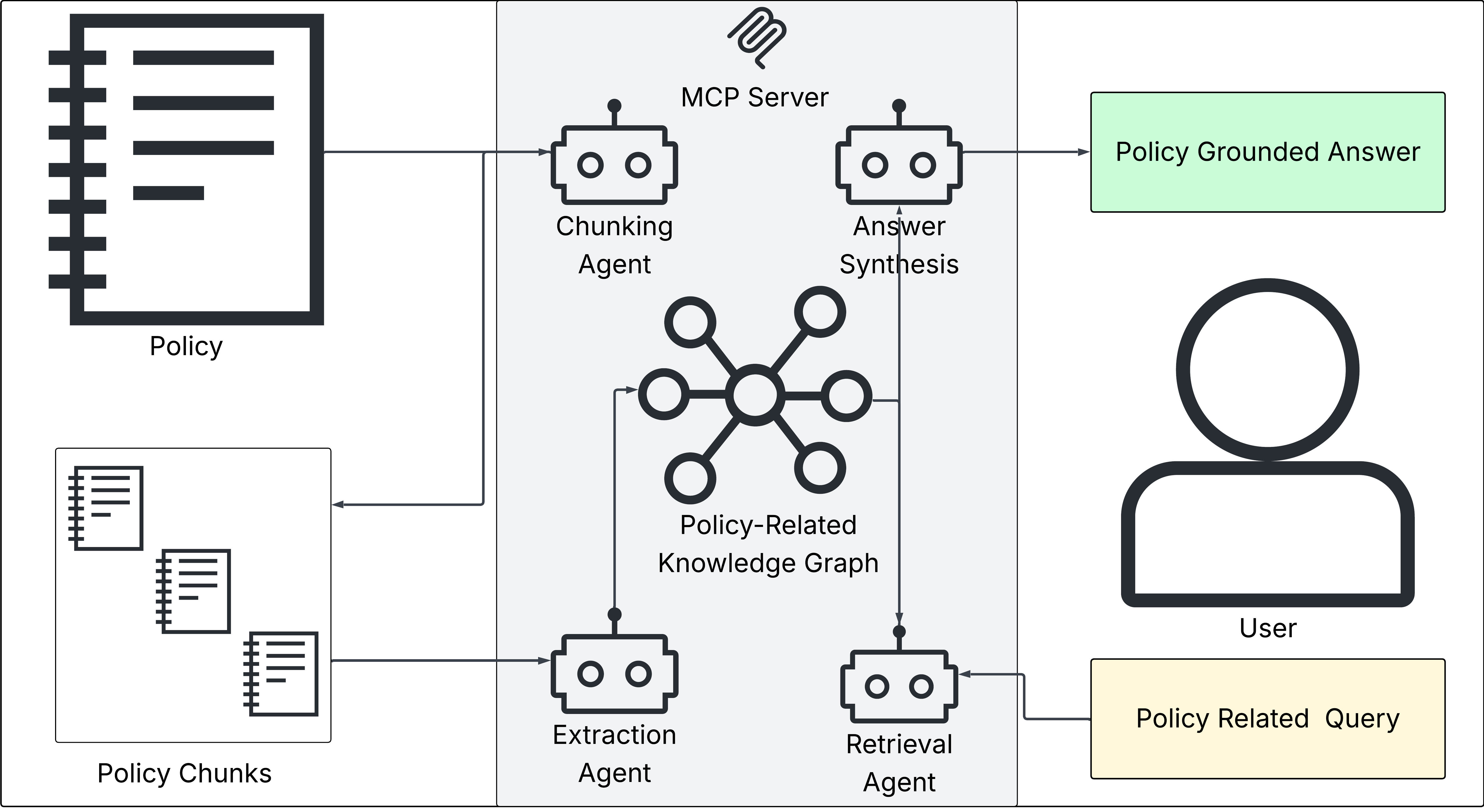
Figure 1: Overview of the agentic framework: policy documents are segmented, extracted into a KG, and traversed to synthesize policy-grounded answers.
Document Chunking
Accurate segmentation of regulatory documents is essential to ensure coherent context windows for LLM extraction agents. The chunking agent employs a two-phase scan and review routine, with dynamic boundaries aligned to semantic breaks (e.g., section or article ends), thus preserving logical structure and markedly improving downstream retrieval accuracy, in line with recent findings on legal document segmentation.
Entity and relation extraction occurs via schema-constrained (AI Risk Ontology, AIRO) or open ontologies discovered by the LLM. The process encompasses two passes: entity identification and subsequent relation extraction, with explicit prompts to re-use established nodes and to connect entities across policy sources based on embedding similarity and string proximity. Notably, schema design directly influences KG navigability and retrieval accuracy.
Closed (AIRO) schemas offer controlled vocabularies, facilitating interoperability and minimizing type fragmentation. Open schemas allow richer, emergent entity and relation names, often enhancing alignment with user queries but potentially increasing retrieval noise via type proliferation.
Retrieval and Answer Synthesis
For each question, a routing agent selects between direct retrieval (semantic search + 1-hop expansion) for simple questions, and full agentic traversal for complex reasoning or cross-policy inference. Retrieved entities and supporting chunk texts are then synthesized into an answer by a dedicated LLM agent, which receives both structured graph serializations and policy citations for evidence-grounded completions.
Experimental Design and Evaluation
Task Suite and Datasets
The evaluation spans 42 QA tasks distributed across six reasoning types, ranging from single-hop entity lookup (T1) to multi-hop, cross-policy reasoning (T6). Questions are constructed semi-automatically from three distinct policy sources, with human-curated gold answers to decouple metric evaluation from KG construction artifacts.
Baselines and Comparison
Three experimental conditions are compared:
- No-context baseline (NC): Synthesis agent answers from parametric model knowledge only.
- Closed KG (AIRO): Pipeline executed with closed ontology schema.
- Open KG: Pipeline with LLM-emergent schema.
Five LLMs are tested, from frontier (gpt-5-mini) to small, local models (granite4:micro), each constructing and retrieving from their own KGs.
Metrics
Evaluation employs both heuristic techniques (semantic similarity, set-match F1, binary match, mapping accuracy) and an LLM-as-judge (gpt-4.1-mini), scoring factual accuracy, completeness, and relevance (1–5 scale). Every answer is assessed over five independent runs.
Results and Analysis
Across all five models, KG augmentation yields improvements in both heuristic and judge metrics, with mean LLM-judge gains ranging from +0.17 to +0.55. The most significant improvements are found on T1 and T3 tasks, which require precise, verbatim policy citations—categories where LLMs demonstrably fail without explicit graph grounding. For instance, perfect or near-perfect scores on compliance questions (T5) are achieved only when the answer synthesis agent has access to authoritative policy excerpts retrieved via the KG, enabling direct citation of relevant articles and obligations.
Interestingly, some models (notably nemotron:30b) exhibit a discrepancy between heuristic and judge metrics. This often arises from lexical differences (e.g., paraphrasing instead of verbatim text), illustrating that judge models better capture the factual adequacy of KG-grounded completions even when surface overlap is low.
Ontology Schema Choice and Model Capability Interactions
Open LLM-discovered schemas frequently match or exceed closed, formal schemas in LLM-judge scores, particularly for models capable of leveraging richer, descriptive entity and relation labels. However, schema proliferation in open KGs can degrade retrieval precision—a phenomenon observed when open schemas yield many singleton types, fragmenting the search space and diluting context assembly.
Conversely, closed schemas produce compact, high-connectivity graphs with concentrated node types and relation patterns (e.g., RISK_CONTROL, MITIGATES), maintaining navigability and steady performance, especially for smaller models. Notably, agentic traversal degrades performance on less capable models (e.g., granite4:micro), which fail to coordinate tool calls or select informative paths, reinforcing that retrieval strategy must be modulated to LLM capability.
Cross-Policy Retrieval Bottleneck
On cross-policy reasoning tasks (T6), KG augmentation affords only modest improvements. Effective cross-policy mapping is sensitive to vocabulary alignment between frameworks (e.g., "poisoning" versus "bias"), and the simple embedding-based entity linking deployed here can miss such correspondences. Models with open schemas and more cross-policy edges perform better, but the challenge of semantic drift and schema heterogeneity remains an open area for enhancement (e.g., via advanced schema alignment techniques).
Practical and Theoretical Implications
This study substantiates that integrating KGs into LLM-based compliance frameworks provides tangible performance benefits across regulatory Q&A and compliance-checking tasks. Augmented LLMs can furnish traceable, evidence-backed answers beyond the reach of parametric-only models, directly addressing regulatory demands for explainability and citation in high-stakes settings. The findings highlight the importance of adaptive pipeline orchestration—selecting schemas and retrieval strategies commensurate with model capability.
The open-vs-closed schema tradeoff suggests avenues for future research in hybrid ontology learning, automated schema alignment, and improved KG construction methods (including model distillation and policy optimization training) to support both breadth and reliability of compliance reasoning. Cross-policy inference remains constrained by vocabulary and schema mismatch, indicating that further advances in LLM-mediated entity linking, subgraph alignment, and graph summarization are needed to achieve robust multi-framework compliance reasoning.
Conclusion
The agentic framework presented in this work demonstrates that knowledge graph augmentation provides substantial gains for LLM-based policy compliance reasoning. Both open and formal ontologies can support high-quality retrieval and synthesis, provided model and schema selections are aligned to task and capability levels. While significant progress is achieved for intra-policy reasoning and evidence citation, cross-policy mapping and scalability will require further methodological advances. The evidence underscores that policy-aware KGs constitute an indispensable intermediate for reliable, transparent, and actionable automated compliance systems.

