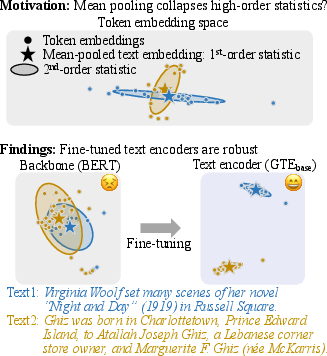
Why Mean Pooling Works: Quantifying Second-Order Collapse in Text Embeddings
Abstract: For constructing text embeddings, mean pooling, which averages token embeddings, is the standard approach. This paper examines whether mean pooling actually works well in real models. First, we note that mean pooling can collapse information beyond the first-order statistics of the token embeddings, such as second-order statistics that capture their spatial structure, potentially mapping distinct token embedding distributions to similar text embeddings. Motivated by this concern, we propose a simple metric to quantify such a collapse induced by mean pooling. Then, using this metric, we empirically measure how often this collapse occurs in actual models and texts, and find that modern text encoders are robust to this collapse. In particular, contrastive fine-tuned text encoders tend to be less prone to the collapse than their pretrained backbone models. We also find that the robustness of these text encoders lies in the concentration of token embeddings within each text. In addition, we find that robustness to the collapse, as quantified by our proposed metric, correlates with downstream task performance. Overall, our findings offer a new perspective on why modern text encoders remain effective despite relying on seemingly coarse mean pooling.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at a very common trick used in language AI: turning a whole sentence into a single vector (a list of numbers) by averaging the vectors of its words. This trick is called “mean pooling.” The authors ask a simple question: if averaging throws away details, why does it still work so well in modern systems? They introduce a way to measure when averaging loses important information and then test real models to see how often this happens.
What were the main questions?
- Does mean pooling (just averaging word vectors) accidentally make different sentences look the same?
- Can we measure how bad this problem is when it happens?
- Do today’s popular text encoders actually avoid this problem in practice?
- If they do, how do they avoid it?
- Is being robust to this problem linked to doing better on real tasks?
How did the researchers study it?
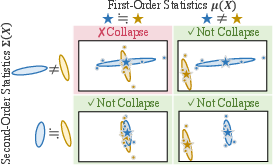
Think of each sentence as a “cloud” of points in space, where each point is a token (word or subword) vector. Mean pooling takes the center of that cloud and uses it as the sentence’s overall vector.
- First-order information = the center of the cloud (the average).
- Second-order information = the shape and spread of the cloud (how wide, narrow, or stretched it is).
Two very different clouds can have the same center. If you only keep the center (by averaging), you might miss that the clouds are different. That’s the potential problem.
What they did:
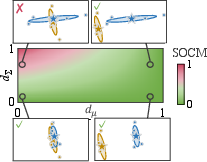
- They created a simple score called SOCM (Second-Order Collapse by Mean pooling). In plain terms, SOCM gets big when two sentences have very similar centers (means) but very different spreads/shapes. It ranges from 0 (no problem) to 1 (worst case).
- They computed SOCM for lots of sentence pairs using several well-known models (like BERT and newer, fine-tuned versions that are trained to pull matching texts together and push mismatched ones apart).
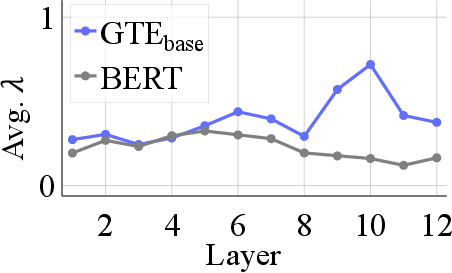
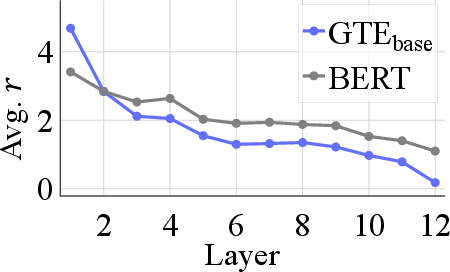
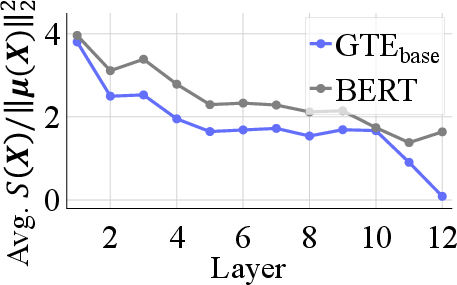
- They also peeked inside Transformer layers to understand why some models are less affected. They found that, in strong encoders, the token vectors inside each sentence tend to gather closely together (their “clouds” get tight). When the cloud is tight, averaging captures most of what matters.
- Finally, they checked whether models with lower SOCM scores also do better on standard benchmarks.
What did they find, and why is it important?
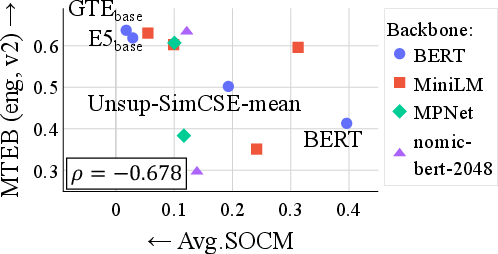
- Mean pooling works well in modern models: In practice, the feared “collapse” (different sentences averaging to similar vectors) doesn’t happen often with today’s fine-tuned text encoders.
- Fine-tuning helps: Models that are contrastively fine-tuned (trained to make similar sentences closer and different sentences farther apart) have much lower SOCM than their original backbone versions. In other words, they are more robust to the averaging problem.
- Token vectors concentrate: Inside these fine-tuned models, the token vectors for each sentence bunch up around a common center, especially in later layers. That makes the sentence’s average a good summary.
- Theory and experiments agree: A simple mathematical analysis shows that if tokens concentrate, SOCM becomes small. Measurements from real models match this: the layers behave in a way that leads to tight token clouds and low SOCM.
- Better robustness, better performance: Models with lower SOCM scores tend to score higher on real-world tasks (like the MTEB benchmark). So, avoiding this collapse seems to be linked to stronger practical performance.
Why this matters: It explains why a very simple method—mean pooling—still powers top text embeddings. It’s fast, memory-friendly, and, thanks to how models are trained, surprisingly reliable.
What’s the takeaway?
Even though averaging might sound like it throws away a lot, modern text encoders are trained in a way that makes averaging capture the essential meaning. The authors’ SOCM score helps quantify when averaging would fail, and they show that strong, contrastively fine-tuned encoders mostly avoid those failures. This gives developers confidence to keep using mean pooling and suggests new ways to improve models—like training them so their token vectors naturally concentrate, or even using SOCM as a training guide in the future.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper’s analysis and claims:
- Generalization across languages and domains is untested: results rely on English Wikipedia/MS MARCO and MTEB (eng v2). Evaluate SOCM and findings on multilingual, code, biomedical, and low-resource domains.
- Effect of text length and tokenization is not analyzed: assess how SOCM scales with sequence length, subword granularity, stopwords, and punctuation; control for or normalize by n_i to avoid length-induced covariance artifacts.
- Random-pair evaluation may understate collapse risk: measure SOCM specifically on hard negatives, semantically similar-but-distinct pairs, and near-duplicates where mean pooling is most likely to fail.
- No per-task breakdown of correlation: identify which MTEB task families (e.g., retrieval vs. STS vs. classification) are most sensitive to SOCM, and whether SOCM predicts failure modes at the task level.
- Causality between SOCM and downstream performance is unestablished: perform controlled interventions (e.g., SOCM-regularized training, synthetic manipulations of token spread) to test whether lowering SOCM improves performance.
- Robustness statistics are coarse: report distributions, confidence intervals, and significance tests for SOCM across pairs and models; examine tail cases (worst 1%) to surface rare but critical collapses.
- Gaussian approximation of token lists is unvalidated: quantify the error introduced by modeling token embedding sets as Gaussians; compare SOCM built on Gaussian decomposition to metrics using empirical optimal transport, MMD, or energy distance.
- Covariance estimation reliability is unaddressed: with small n_i, covariance estimates are noisy. Study shrinkage/regularization strategies and sensitivity to sample size for stability.
- Assumption checks for normalization and trace bound are incomplete: systematically test when and hold in practice (early layers, different LayerNorm variants, non-shared parameters), and provide SOCM variants without these constraints.
- Metric sensitivity to alternative scalings is unknown: evaluate whether SOCM’s conclusions hold under different normalizations (centering, whitening, unit-variance), similarity measures (cosine vs Euclidean), and different scalings.
- Alternatives to mean pooling are not empirically compared: benchmark CLS pooling, max/attention pooling, SIF/IDF weighting, or lightweight second-order aggregations (e.g., mean+diagonal variance) to test if lower SOCM translates to gains.
- Efficient second-order-aware embeddings are unexplored: propose and evaluate compact representations (e.g., low-rank covariances, projected second-order features) that approximate at ANN-friendly cost.
- Theoretical analysis relies on strong simplifications: relax assumptions of i.i.d. Gaussian token inputs, fixed attention weights, single-head attention, and abstract per-token transforms; derive results for multi-head attention, data-dependent A, and realistic LayerNorm/FFN.
- Mechanism of concentration under contrastive learning is unclear: provide a formal link from contrastive objectives (temperature, negatives, batch size, in-batch mining) to token concentration and reduced SOCM.
- Role of architectural and training hyperparameters is unstudied: ablate embedding dimension, number of heads, residual scaling, normalization placement, and fine-tuning regimes to see how they affect , , , token spread, and SOCM.
- Layer-wise SOCM dynamics are not analyzed: compute SOCM across layers to identify where collapse is mitigated and how this evolves during fine-tuning.
- Potential downsides of token concentration are unexamined: test whether concentration induces oversmoothing or harms token-level tasks (NER, QA alignment) and interpretability; map the trade-off frontier between concentration and precision.
- Domain shift and robustness are untested: measure SOCM and performance under distribution shifts (noisy inputs, adversarial perturbations, OOD domains) to see if collapse risk increases.
- Pair selection and sampling bias may confound conclusions: compare SOCM computed on curated positives/negatives (labeled STS, supervised retrieval) versus random pairs; control for text length and topic.
- Correlation analysis uses a small model set: increase the number/diversity of encoders to validate Spearman correlations and test for confounders (pretraining data volume, objective, dimension).
- Practical computability of SOCM at scale is unclear: analyze computational cost of per-pair Bures distance, propose batching/approximation schemes, and study trade-offs for online monitoring during training.
- Alternative second-order distances were not compared: benchmark Bures vs Log-Euclidean, KL between Gaussians, or spectral metrics to test metric choice sensitivity.
- Impact of anisotropy correction/whitening is unknown: evaluate whether common post-processing (e.g., centering, whitening, PCA debiasing) changes SOCM and its link to performance.
- Error analysis linking SOCM to retrieval failures is missing: inspect high-SOCM false positives/negatives to validate collapse as a concrete failure mode and design targeted mitigations.
- Training-time use of SOCM is only suggested: implement SOCM-based regularizers or curriculum (e.g., penalize high on hard negatives) and measure gains vs. computational overhead.
- Cross-modal and generative settings are unaddressed: extend SOCM to image–text embeddings and to context compression in LLM generation; quantify whether similar second-order collapse arises and matters.
Practical Applications
Immediate Applications
Below is a concise set of deployable use cases that leverage the paper’s findings (robustness of mean pooling in contrastively fine-tuned encoders, the SOCM metric, and layer-wise token concentration diagnostics).
- Model selection and qualification for retrieval and RAG
- Description: Evaluate candidate embedding models on in-domain corpora using SOCM to select those least prone to mean-pooling collapse; prioritize contrastively fine-tuned encoders (e.g., GTE, E5) over backbones.
- Sectors: Software, healthcare (clinical guideline and EHR retrieval), legal (case/contract search), finance (policy/compliance search), education (course material search), customer support (KB search).
- Tools/workflows: Add SOCM to internal model eval suites alongside MTEB-style tasks; threshold SOCM for procurement decisions.
- Assumptions/dependencies: Access to token-level embeddings from the encoder; corpus-specific sampling; normalization consistent with the paper’s setup.
- Cost-effective index design for vector search
- Description: Prefer single-vector-per-document indexing with mean pooling (ANN-compatible) when SOCM is low, avoiding heavier multi-vector methods (e.g., ColBERT) unless necessary.
- Sectors: E-commerce, media/recommendation, enterprise search, SaaS knowledge bases.
- Tools/workflows: Faiss/ScaNN/HNSW indexes using mean-pooled embeddings; capacity planning and cost modeling based on single-vector storage.
- Assumptions/dependencies: SOCM (and/or token spread) remains low on the organization’s corpus; performance targets met on retrieval evals.
- RAG pipeline hardening and QA
- Description: Instrument retrieval components with periodic SOCM sampling to flag regressions in embedding robustness as models, prompts, or data change.
- Sectors: LLM applications across all industries.
- Tools/workflows: CI/CD checks compute SOCM on a fixed validation corpus; dashboards track SOCM vs. retrieval metrics (nDCG, MRR).
- Assumptions/dependencies: Stable validation sets; efficient SOCM computation (eigendecomposition of covariance).
- Domain adaptation triage
- Description: Before deploying a general-purpose encoder in a specialized domain (e.g., cardiology, tax law), run SOCM on domain texts; if high, perform domain-specific contrastive fine-tuning and re-check SOCM.
- Sectors: Healthcare, legal, finance, scientific publishing.
- Tools/workflows: Light-weight contrastive fine-tuning with in-domain positives/negatives; early stopping if SOCM plateaus.
- Assumptions/dependencies: Curated domain pairs or weak supervision for contrastive training; token-level access.
- Training diagnostics and early stopping
- Description: Track SOCM and token concentration (S(X)/||X||²) during fine-tuning to detect when models become robust to collapse; use as early stopping or hyperparameter tuning signals.
- Sectors: Software/ML platform teams.
- Tools/workflows: Training callbacks that log SOCM over validation batches; sweep learning rates and batch compositions guided by SOCM trends.
- Assumptions/dependencies: Compute budget to evaluate SOCM during training; stability of normalization as in the paper.
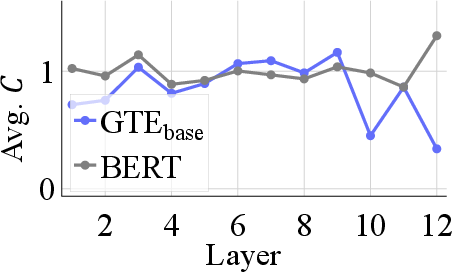
- Layer-wise encoder debugging
- Description: Use the paper’s λ (attention+projection), r (residual), and C (per-token transformation) diagnostics to identify where concentration emerges or degrades, guiding architecture or finetuning choices.
- Sectors: Model development teams (foundation model providers, in-house ML).
- Tools/workflows: Layer-wise analytics notebooks; adjustments to attention heads, residual scaling, LayerNorm/FFN settings.
- Assumptions/dependencies: Access to internal layer activations/weights; simplified assumptions still informative for real models.
- Procurement and governance checklists
- Description: Add SOCM thresholds to enterprise procurement criteria for embedding services/APIs, especially where retrieval robustness is critical (e.g., regulated industries).
- Sectors: Finance, healthcare, public sector.
- Tools/workflows: Vendor evaluation templates including SOCM and standard retrieval KPIs.
- Assumptions/dependencies: Vendors expose token-level or equivalent statistics to compute SOCM on representative data; or provide SOCM reports.
- Drift detection in production
- Description: Monitor SOCM periodically on sampled content to detect embedding degradation from data drift or model updates (e.g., API version changes).
- Sectors: Any production search/RAG system.
- Tools/workflows: Scheduled SOCM jobs on rolling windows; alerting when SOCM exceeds thresholds in specific domains/topics.
- Assumptions/dependencies: Anonymization/privacy controls for sampled text; compute for periodic covariance computations.
- Lightweight developer workflows
- Description: For startups and hobbyists building search/QA, choose contrastively fine-tuned mean-pooling encoders and validate with a small SOCM harness to justify single-vector indexes and reduce costs.
- Sectors: Daily life/developer tooling.
- Tools/workflows: Open-source SOCM scripts; Hugging Face/LLMOps plug-ins that compute token spreads and SOCM on a small benchmark set.
- Assumptions/dependencies: Python stack, access to token embeddings, manageable corpus size.
- Academic reproducibility and pedagogy
- Description: Use SOCM to teach and study why mean pooling works; replicate the paper’s experiments on new encoders and domains.
- Sectors: Academia.
- Tools/workflows: Course labs, research benchmarks augmented with SOCM plots and layer-wise measures.
- Assumptions/dependencies: Instructor access to models exposing token representations.
Long-Term Applications
These applications require additional research, scaling, or ecosystem changes but are natural extensions of the paper’s methods and insights.
- SOCM-regularized training objectives
- Description: Incorporate SOCM (or differentiable approximations) into loss functions alongside contrastive losses to explicitly discourage second-order collapse.
- Sectors: Foundation model training, enterprise model customization.
- Tools/products: Training libraries with SOCM regularizers; auto-tuning of regularization strength.
- Dependencies: Efficient/approximate gradients through Bures distance; robust normalization in diverse architectures.
- Adaptive retrieval routing
- Description: Use token-spread proxies (e.g., S(X)/||X||²) and/or query–doc SOCM estimates to route queries dynamically: mean-pooled single-vector retrieval by default; escalate to multi-vector methods when collapse risk is high.
- Sectors: Search engines, enterprise RAG, e-commerce.
- Tools/products: Hybrid retrievers with routing policies; latency-aware controllers.
- Dependencies: Reliable per-text or per-pair collapse predictors; latency budget for multi-vector fallback.
- Architecture and attention regularizers for concentration
- Description: Design attention patterns or residual/LayerNorm modifications that encourage within-text token concentration in later layers, aligning with low SOCM.
- Sectors: Model R&D.
- Tools/products: New encoder variants (“concentrative encoders”); ablations aligning λ, r, C to performance.
- Dependencies: Theoretical guarantees beyond simplified assumptions; stability across languages/domains.
- Benchmark standards and certification
- Description: Extend MTEB-style benchmarks and industry standards to include SOCM and token concentration metrics; create “robust mean pooling” certifications for embedding providers.
- Sectors: Academia, standards bodies, procurement in regulated industries.
- Tools/products: Public leaderboards reporting SOCM; third-party audit kits.
- Dependencies: Community consensus; standardized protocols for token access and normalization.
- Multimodal and cross-lingual extensions
- Description: Adapt SOCM to image, audio, and cross-lingual embeddings where pooling is common (e.g., patch or frame pooling), evaluating collapse risk across modalities and languages.
- Sectors: Media search, speech analytics, multilingual search.
- Tools/products: SOCM variants for multimodal encoders; cross-lingual robustness dashboards.
- Dependencies: Token/patch-level outputs from multimodal encoders; modality-specific normalization.
- LLM context compression and retrieval planning
- Description: Use SOCM (or its extensions) to study and control information loss when compressing context or long documents to vectors for retrieval planning in LLM systems.
- Sectors: Software, education, legal summarization, healthcare triage.
- Tools/products: Compression controllers that safeguard against collapse; policies deciding granularity of chunking/aggregation.
- Dependencies: Extensions of SOCM to long-context and generative settings; reliable proxies without pairwise labels.
- AutoML for domain-specific embedding optimization
- Description: Automated pipelines that search fine-tuning data, architectures, and hyperparameters to minimize SOCM while maximizing downstream KPIs in target domains.
- Sectors: Enterprise ML, SaaS platforms.
- Tools/products: AutoML suites with multi-objective optimization (MTEB score + SOCM).
- Dependencies: Compute budget; robust SOCM estimators on limited samples.
- Distillation with SOCM preservation
- Description: Distill large encoders into smaller ones while matching both task performance and SOCM profiles to retain robustness of mean pooling.
- Sectors: Edge and mobile deployments.
- Tools/products: Distillation recipes including second-order behavior constraints.
- Dependencies: Teacher–student frameworks that preserve token-level geometry.
- Hybrid uncertainty-aware systems
- Description: For inputs with elevated collapse risk, complement mean embeddings with second-order descriptors (e.g., predicted covariances) and propagate this through retrieval/ranking as uncertainty.
- Sectors: Healthcare decision support, legal discovery.
- Tools/products: Retrieval pipelines that fuse mean and covariance signals; risk-aware rankers.
- Dependencies: Efficient estimation of second-order stats at scale; calibration studies.
- Privacy-preserving and federated deployments
- Description: Lean on single-vector mean pooling (validated by low SOCM) to reduce data transmission in federated or privacy-sensitive settings; communicate only mean embeddings.
- Sectors: Mobile, healthcare, finance.
- Tools/products: Federated search protocols exchanging compact embeddings; on-device retrieval.
- Dependencies: On-device encoders with acceptable SOCM; legal approval for embedding sharing.
- Higher-order metric research
- Description: Extend beyond Gaussian/second-order approximations to metrics that capture third- and higher-order token statistics where necessary, and study trade-offs vs. compute.
- Sectors: Advanced research.
- Tools/products: Libraries for efficient higher-order moment comparisons; approximations for production.
- Dependencies: New theory and efficient algorithms; empirical validation of benefit over SOCM.
- Policy and governance frameworks
- Description: Encourage inclusion of robustness-to-pooling metrics (e.g., SOCM) in AI governance and risk-management frameworks for systems relying on semantic search or RAG in high-stakes domains.
- Sectors: Public sector, regulated industries.
- Tools/products: Guidance documents, audit checklists, compliance attestations.
- Dependencies: Stakeholder consensus; mappings from SOCM thresholds to risk categories.
Notes on feasibility and dependencies common to many applications:
- SOCM relies on access to token-level embeddings and assumes normalized representations; some commercial APIs may not expose these, requiring vendor cooperation or use of open models.
- The SOCM definition uses Gaussian characterization and trace/normalization assumptions; extreme variance or non-Gaussian behavior may limit interpretability.
- Computing Bures distance for high-dimensional covariances can be costly; production use may need approximations, batching, or sampling strategies.
- Correlation with downstream performance is moderate (reported Spearman’s ρ ≈ −0.68), so SOCM should complement—not replace—task-specific evaluations.
Glossary
- Anisotropic: Direction-dependent; in embedding spaces, anisotropy means variance is concentrated in a few directions rather than being uniform. Example: "anisotropic token embeddings within each text"
- Approximate nearest neighbor search: Algorithms and indexes that find near neighbors efficiently with sublinear time by trading exactness for speed. Example: "compatibility with approximate nearest neighbor search~\cite{Douze2025-wj}"
- Attention weight matrix: The matrix of attention weights (typically softmax-normalized) that determines how tokens attend to each other. Example: "the attention weight matrix after softmax"
- Bures Wasserstein distance: A distance on positive semidefinite matrices equivalent to the 2-Wasserstein distance between Gaussians’ covariances. Example: "the scaled Bures Wasserstein distance~\cite{Dowson1982-sq}:"
- Contrastive fine-tuning: Training that brings semantically similar texts closer and pushes dissimilar ones apart in embedding space via a contrastive loss. Example: "This popularity likely reflects its compatibility with contrastive fine-tuning~\cite{Gao2021-ds}"
- Contextualized embeddings: Token or text representations that depend on surrounding context, typically produced by Transformer encoders. Example: "contextualized embeddings from Transformer~\cite{Vaswani2017-kx} encoders"
- Covariance matrix: A second-order statistic capturing the spread and correlation structure of a distribution. Example: "such as the covariance matrix."
- Empirical distribution: A distribution formed by treating observed samples as atoms with equal mass. Example: "when viewed as an empirical distribution in the embedding space."
- First-order statistic: The mean of a distribution; for token lists, the average embedding. Example: "the first-order statistic (mean) of the token embedding distribution."
- Frobenius norm: Matrix norm defined as the square root of the sum of squares of all entries. Example: "the Frobenius norm."
- Higher-order statistics: Moments or characteristics of a distribution beyond the mean (e.g., covariance, skewness). Example: "collapsing higher-order statistics."
- LayerNorm: A normalization technique that normalizes activations across features for each token. Example: "LayerNorm and FFN"
- MC dropout: Monte Carlo dropout; applying dropout at inference to sample from a model and approximate Bayesian uncertainty. Example: "via MC dropout"
- Mean pooling: Aggregation by averaging token embeddings to form a single text vector. Example: "mean pooling, which averages token embeddings,"
- MTEB (eng, v2): A benchmark suite for evaluating text embedding models across many English tasks. Example: "MTEB (eng, v2)"
- Optimal transport: A framework that measures the minimal “cost” to morph one distribution into another; used to compare token embedding lists. Example: "optimal transport between token embedding lists"
- Operator norm: The largest singular value of a matrix (spectral norm), measuring its maximum amplification of a vector. Example: "the operator norm"
- PCA projection without centering: Applying principal component analysis without subtracting the mean before projection. Example: "via PCA projection without centering."
- Per-token transformation: Post-attention operations applied independently to each token (e.g., LayerNorm, FFN). Example: "a per-token transformation "
- Residual connection: A skip connection that adds a module’s input to its output to ease optimization and preserve information. Example: "The residual connection adds to the input ,"
- Retrieval-augmented generation: Generation methods that condition on retrieved external documents to improve accuracy and grounding. Example: "retrieval-augmented generation~\cite{Lewis2020-gr}"
- Second-Order Collapse by Mean pooling (SOCM): A metric proposed to quantify how much second-order information is lost by mean pooling. Example: "Second-Order Collapse by Mean pooling (hereafter referred to as SOCM)"
- Second-order statistic: For token embeddings, the covariance capturing their spatial spread around the mean. Example: "a second-order statistic"
- Self-attention: Mechanism where tokens attend to each other to compute contextualized representations. Example: "a single-head self-attention block."
- Softmax: A function that transforms scores into a probability distribution. Example: "after softmax"
- Spearman's ρ: A rank-based correlation coefficient measuring monotonic association between two variables. Example: "Spearman's , "
- Spread (of token embeddings): A dispersion measure defined as the average squared distance of tokens from their mean. Example: "the spread of any matrix "
- Transformer encoder: A stack of self-attention and feed-forward layers producing contextualized token representations. Example: "Transformer text encoders"
- Unit-norm means: The assumption or normalization that mean vectors have Euclidean norm equal to 1. Example: "We assume unit-norm means, ,"
- Value and output projection matrices: Linear transformations in attention mapping value vectors and projecting attention outputs. Example: "the value and output projection matrices"
- Wasserstein distance: An optimal transport-based metric on probability distributions; here, the (2-Wasserstein) variant. Example: "the -Wasserstein distance "
Collections
Sign up for free to add this paper to one or more collections.