- The paper introduces learnable bottleneck tokens to explicitly pool modality-agnostic embeddings for efficient unified retrieval.
- It employs a novel generative information condensation technique that enforces token-level supervision to ensure accurate semantic compression.
- Experimental results on the MMEB-V2 benchmark demonstrate significant performance gains across images, videos, and documents.
Bottleneck Tokens for Unified Multimodal Retrieval: A Technical Analysis
Introduction
Unified multimodal retrieval remains central to scalable semantic search and retrieval-augmented generation (RAG) paradigms, especially as large multimodal LLMs (MLLMs) grow increasingly dominant. Decoder-only MLLMs, adapted via contrastive fine-tuning to act as universal embedders, typically extract input representations using the hidden state of the last token (e.g., the <EOS> token), a method referred to as implicit pooling. This convention, however, manifestly misaligns with the design of transformer causal attention and fails to provide robust, token-level supervision on how semantically relevant information is to be compressed for retrieval tasks, especially in complex or diverse modalities.
"Bottleneck Tokens for Unified Multimodal Retrieval" (2604.11095) directly addresses these limitations by introducing two orthogonal innovations: (1) a set of learnable Bottleneck Tokens (BToks) as an explicit pooling mechanism tailored for retrieval embedding, and (2) Generative Information Condensation—a training method that synergistically merges next-token prediction (NTP) with a condensation mask, structurally enforcing that predictive signals traverse the BTok bottleneck.
Architectural Innovations: Bottleneck Tokens
The core architectural component is the introduction of K learnable Bottleneck Tokens, appended after each input sequence, agnostic to modality. Instead of overloading the <EOS> token—a repurposed vocabulary token not designed for sequence-level aggregation—the BToks serve as a fixed-capacity explicit pooling mechanism. Their representations after the final transformer layer are mean-pooled to obtain a semantically rich, task-agnostic embedding.
This design decouples the embedding dimensionality from input length and sequence structure, ensuring that the same mechanism can be robustly employed for textual, image, video, or document modalities. Mean pooling across K tokens prevents representation collapse and encourages the network to learn diversified channels for semantic compression.
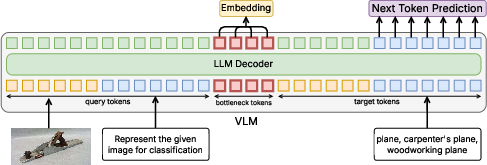
Figure 1: Bottleneck tokens (red) are inserted between the query and target tokens in the LLM decoder, explicitly mediating the flow of semantic information for improved multimodal retrieval.
The standard supervised contrastive framework (InfoNCE) specifies target proximity for embeddings but lacks structural constraints on the information compression path. The paper introduces Generative Information Condensation, whereby the training sequence comprises a query, BToks, and target segment. Crucially, a block-structured condensation mask forbids target tokens from directly attending to the query tokens; only the BToks act as mediators.
Under this regime, the generative NTP loss is computed over the target segment, but all semantic information needed for prediction must be channeled through the BToks. This mechanism enforces dense, token-level supervision, compelling the model to condense and reconstruct crucial intent and content exclusively into the BToks, thus aligning generative and retrieval performance objectives.
This approach realizes a fundamental architectural guarantee: at inference, the representation extracted by mean-pooling over BToks is inherently optimized to serve both retrieval and generative reconstruction, eliminating reliance on accidental or shortcut pathways afforded by standard transformer causal attention.
Experimental evaluation on MMEB-V2—a benchmark encompassing 78 datasets across images, videos, and visual documents—demonstrates robust improvements over state-of-the-art 2B-scale embedders. Notably:
- BToks achieves 59.0 Overall on MMEB-V2, outperforming VLM2Vec-V2 by +3.6, with consistent substantive improvements across all modalities.
- For Video-QA, a particularly challenging task due to long-range temporal dependencies, the gain is +12.6. Visual document (VisDoc) and image task improvements are also significant (+4.2 and +1.8, respectively).
- Compared to larger backbones (≥7B), BToks-equipped 2.2B models approach or match their performance under similar data and training conditions.
Ablations show that removing BToks in favor of EOS pooling leads to broad performance collapses, especially for tasks and modalities with high token-to-embedding compression ratios. Disabling either the condensation mask or the generative objective yields additively degraded performance, confirming the necessity and complementarity of both innovations.
Cross-Modal and Data Efficiency
BToks demonstrate strong cross-modal transfer when trained on only a single modality, with representations generalizing effectively to unobserved modalities—a +15.88 improvement for visual documents using only image data is observed. This finding implies that explicit bottleneck pooling engenders modality-agnostic embedding formation, potentially advantageous for transfer learning and real-world deployments with skewed data availability.
Efficiency benchmarks indicate merely a 1.2% overhead in inference latency and throughput compared to standard approaches. The design ensures that bottlenecking introduces fixed, negligible computational cost, as at inference, only the BToks and input tokens are processed.
Practical and Theoretical Implications
This work reorients the design of pooling mechanisms for MLLM-based embedding. By introducing explicit, learnable BToks with structural and generative supervision, the authors demonstrate that the architectural bottleneck—rather than mere model or data scale—can critically influence the fidelity and generalizability of the learned embedding space. The fixed-capacity and mean-pooling strategies mitigate information overload and prevent shortcut learning, while the condensation mask unifies generative and retrieval objectives at the representation level.
The analysis and ablation results strongly support the general principle that explicit, bottlenecked pooling with joint generative constraints yields superior, more robust multimodal embeddings, especially relevant for compositional and reasoning-heavy downstream retrieval tasks.
Future Directions
The paper identifies several directions for further research: scaling to larger backbones, learning or dynamically adjusting the number of BToks per input, integrating alternative dense supervision signals (e.g., masked reconstruction, retrieval-augmented generation), and generalizing to non-visual modalities such as audio or 3D data. Combining BToks with advanced contrastive or instruction-based objectives could close the residual gap to models trained with proprietary data or external chains of thought.
Conclusion
"Bottleneck Tokens for Unified Multimodal Retrieval" (2604.11095) establishes that purpose-built, explicit pooling through learnable bottlenecks, guided by structural generative supervision, substantially enhances the quality of multimodal embeddings. These findings have direct implications for the design of next-generation RAG architectures, universal embedding models, and cross-modal retrieval systems, situating explicit bottlenecked pooling as a foundational architectural advance for scalable, efficient, and generalizable multimodal semantic representation.