- The paper introduces a retrieval model that indexes atomic facts with formal metadata, ensuring valid and conflict-aware fact retrieval for RAG systems.
- It employs LLM-based extraction, canonicalization, and temporal validation techniques to achieve a 42% increase in nugget recall and a 96% improvement in nDCG@10.
- The approach reduces generator input length by 64% and supports efficient deployment in dynamic, resource-constrained environments.
NuggetIndex: Governed Atomic Retrieval for Maintainable RAG
Motivation and Problem Framing
Retrieval-augmented generation (RAG) has become the dominant paradigm for grounding LLM outputs in external evidence to mitigate hallucination. Traditional RAG systems rely on passage-level or static proposition retrieval, which introduces a unit mismatch: while evaluation metrics increasingly operate at the atomic fact ("nugget") level, retrieval operations aggregate larger, unmanaged textual units lacking explicit governance. This mismatch complicates system maintenance as corpora evolve, fails to capture superseded facts or source disagreements, and propagates outdated/conflicting information in knowledge-intensive domains with rapid change (e.g., news, law, software). Nugget-based evaluation, now standard in TREC QA tracks and autograder benchmarks, demands the retrieval substrate to operate on precisely the atomic units it is scored against.
NuggetIndex Architecture and Data Model
NuggetIndex proposes a retrieval model wherein every indexed unit is an atomic fact (nugget) governed by formal metadata: a temporal validity interval, lifecycle state (active, deprecated, contested), and provenance links. The architecture decomposes documents into canonicalized triples, infers validity using temporal expressions and revision history, assigns epistemic status by evidence aggregation, and tags provenance for explainability and maintenance.
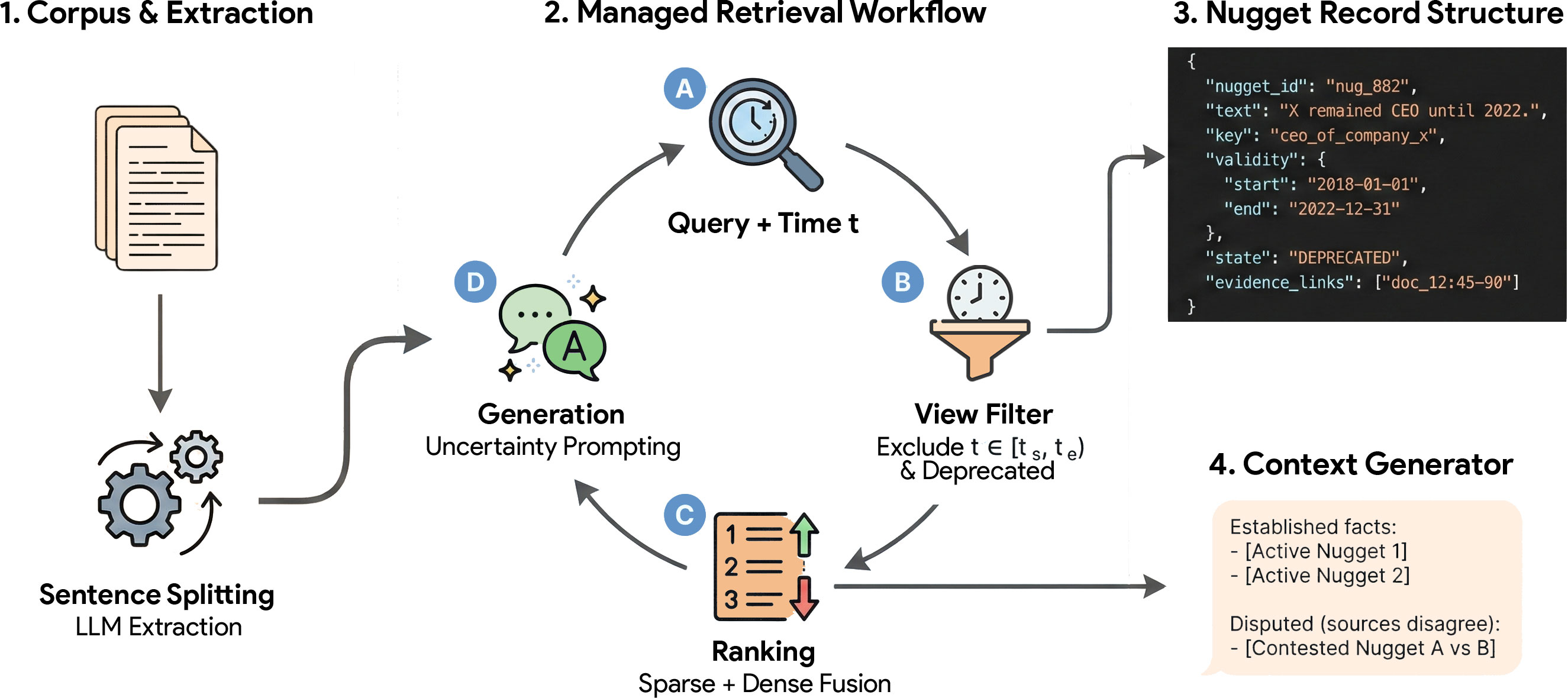
Figure 1: The NuggetIndex architecture transforms documents into atomic nuggets, filters by temporal validity and lifecycle state, and ranks for RAG generation.
This design pivots from passage- or proposition-based retrieval by tightly coupling fact-level governance with retrieval operations, ensuring that only temporally valid, consensus-supported atomic facts are surfaced at query time. Deprecated knowledge and contested claims are filtered or explicitly flagged, supporting strict factual correctness and nuanced uncertainty propagation.
Nugget Construction and Governance Pipeline
The pipeline comprises candidate extraction (LLM-based atomic fact mining with sliding windows), canonicalization (alias and controlled-vocabulary normalization), validity inference (temporal taggers and revision history for interval assignment), and conflict detection/state assignment (algorithmic cross-document evidence aggregation). Conflict resolution applies functional/multi-valued schema discipline, enabling support for succession, concurrency, and explicit contestation reflective of corpus reality. Nugget keys are derived from normalized subject-predicate-scope tuples, allowing robust deduplication and cross-version tracking.
Downstream, the retrieval stack is modular: sparse (BM25), dense (HNSW embeddings), and metadata indices allow hybrid/fallback deployment. Sparse retrieval is empirically shown to outperform dense on atomic nuggets, and the system is engineered for low-latency, low-footprint operation, including browser-based and edge environments.
Experimental Evaluation: Coverage, Temporal Correctness, and Efficiency
Nugget Recall and Ranking Quality
On the nuggetized MS MARCO RAVine benchmark, NuggetIndex achieves a 42% increase in nugget recall and 47% increase in recall for vital nuggets vs passage retrieval baselines, with a 96% improvement in nDCG@10. The direct indexing and ranking of atomic facts consolidates duplicates and filters deprecated/conflicted content prior to generation, yielding a highly competitive retrieval substrate for nugget-based evaluation.
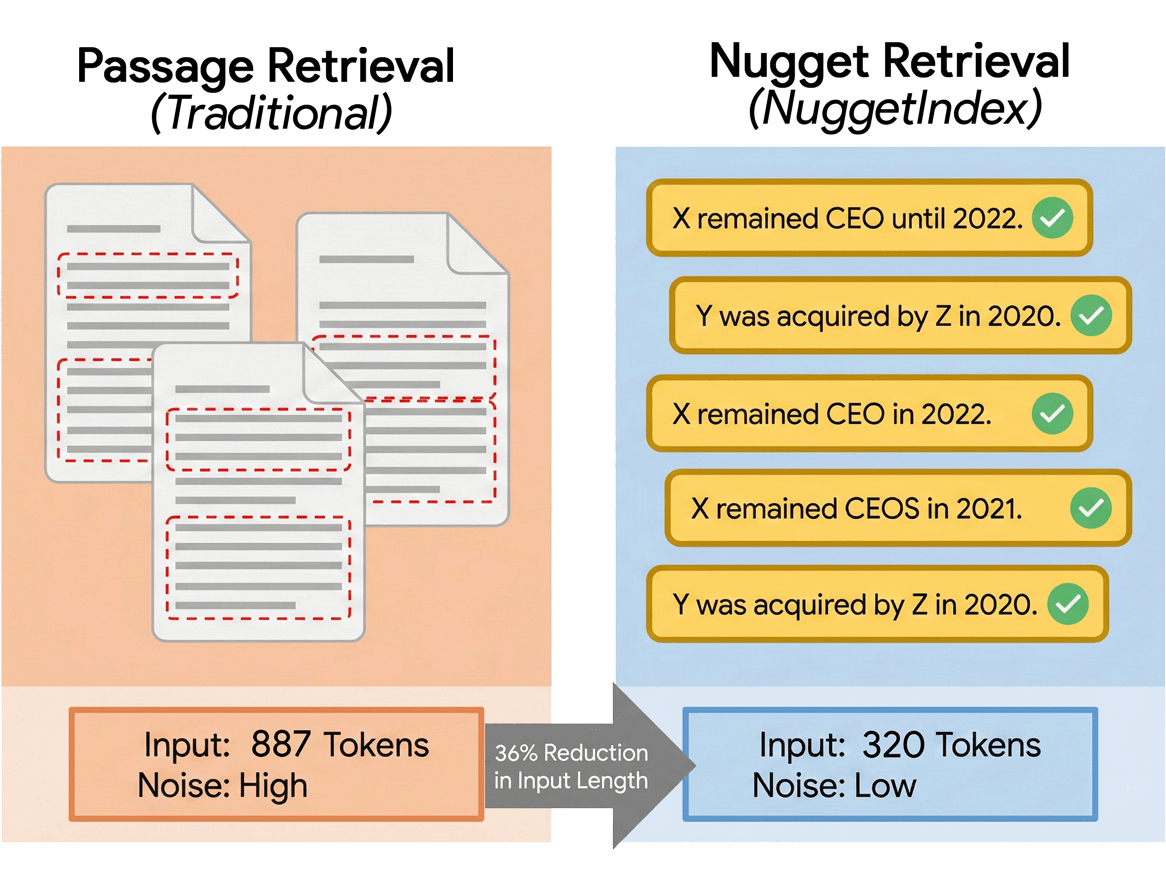
Figure 2: NuggetIndex delivers substantially higher nugget recall and ranking quality compared to passage and proposition-based baselines on RAVine.
Temporal Governance and Conflict Resolution
On TimeQA, NuggetIndex maintains a temporal correctness rate of 93.1%—a 9.1pp improvement over passage baselines—while avoiding the recall collapse observed in document-level time-filtered systems. The conflict rate is reduced by 55% through explicit lifecycle state management and contested nugget handling, enabling generators to qualify outputs and propagate uncertainty when evidence is genuinely conflicted.
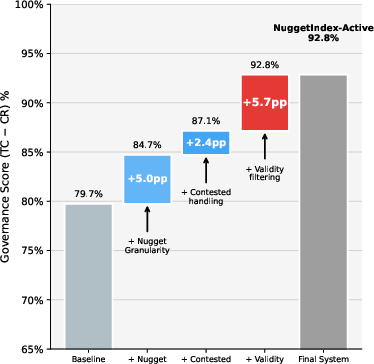
Figure 3: Temporal correctness and conflict rate on TimeQA demonstrate the efficacy of governed temporal filtering and state assignment.
Token Efficiency and Deployment Implications
NuggetIndex reduces generator input length by 64%, supporting prompt efficiency in production settings. The index size remains lightweight (9.3MB for 56k nuggets), and retrieval latency is sub-millisecond in lexical-only mode. This enables maintainable, scalable deployment in resource-constrained environments, including browser-based applications and edge inferencing, with minimal generator prompt cost and robust fact governance.
Ablation and Intrinsic Quality Analysis
Ablation studies confirm that validity filtering is the primary driver of governance score (temporal correctness minus conflict rate). Sparse lexical-only retrieval remains nearly as effective as hybrid, making embedding inference optional for atomic fact matching. The automated construction pipeline achieves .860 extraction precision, .943 atomicity, and perfect conflict detection/deprecation precision; oracle experiments with human-verified nuggets deliver only marginal gains (3.7–4.5pp).
Multi-Hop Reasoning
On multi-hop QA (HotpotQA, MuSiQue), NuggetIndex remains competitive with passage baselines, robustly chaining atomic facts across documents. While the governance signals are neutral on static closed-corpus settings, they provide resilience and maintainability in dynamic environments with frequent fact supersession or source disagreement.
Practical and Theoretical Implications
NuggetIndex bridges the gap between evaluation and retrieval unit granularity, providing a governed substrate for maintainable RAG as corpora evolve. Its architecture allows for transparent, explainable maintenance of knowledge bases, scalable fact-level updating, and streamlined conflict handling. This enables precise, temporally-grounded retrieval and robust propagation of uncertainty in LLM outputs.
The separation of fact validity from document timestamp is a fundamental paradigm shift, providing controlled maintenance and updating of factual knowledge. The integration with external freshness-aware retrieval, schema discovery, and optional human-in-the-loop annotation ensures adaptability and sustainability in real-world environments.
Future Directions
Improvements in end-time detection, schema/ontology linking, cross-document entity normalization, streaming and real-time update support, and deeper integration with autograder-based evaluation are proposed to address limitations (notably recall on expiration, normalization errors, and handling of adversarial or incomplete corpora). The paradigm provides a scalable blueprint for nugget-governed IR systems in dynamic domains.
Conclusion
NuggetIndex establishes governed atomic fact retrieval, structurally aligning retrieval units with nugget-based evaluation and ensuring high recall, temporal correctness, and conflict mitigation. The methodology delivers practical gains in maintainability, efficiency, and correctness for RAG systems—supporting scalable, robust deployment in evolving knowledge domains and providing a foundation for future work in governed, explainable AI retrieval architectures (2604.27306).