- The paper introduces a novel distributed, vision-only multi-view framework (MulViT-TF) that integrates independent ViT encoders with a Transformer-based fusion module to estimate RSSI.
- It achieves up to 26.3% RMSE reduction and 13.8 percentage points improvement in 3dB error coverage, demonstrating robust performance in NLoS and limited FoV conditions.
- The methodology leverages spatially distributed RGB cameras and a cross-camera attention mechanism to eliminate auxiliary sensors and reduce uplink overhead.
Introduction
RSSI (Received Signal Strength Indicator) is a core metric for adaptive wireless communication systems, underpinning applications such as handovers, beam management, and transmit power optimization. Traditional receiver-side feedback-based RSSI estimation introduces uplink overhead, is susceptible to erratic multipath and shadowing effects, and exhibits latency due to its retrospective reporting nature. Several vision-based approaches have been explored to enable out-of-band RSSI estimation; however, current strategies are constrained by reliance on auxiliary sensors (e.g., depth, LiDAR), hardware heterogeneity, or dependence on single-view images, making them vulnerable to Non-Line-of-Sight (NLoS) conditions and limited spatial coverage.
This work presents MulViT-TF, a distributed multi-view vision-only framework for RSSI estimation, uniquely exploiting spatially distributed RGB cameras in practical indoor environments. The architecture synergizes independent ViT (Vision Transformer) encoders for each viewpoint and a cross-view Transformer-based fusion network, enabling robust estimation under severe NLoS and restricted Field-of-View (FoV) constraints without auxiliary modalities or signal measurements.
Architecture of MulViT-TF
The framework leverages the proliferation of camera-equipped IoT devices typically present in indoor infrastructure (e.g., CCTV, service robots), orchestrating them as a distributed vision sensor fabric for wireless sensing. Each camera input is processed by an independent ViT encoder, initialized via transfer learning from the scene-centric Places365 dataset with the DeiT recipe, and fine-tuned for viewpoint-specific features.
A key design is the cross-camera Transformer-based fusion module which concatenates the patch and class tokens from each view and enables global attention across all spatial tokens. This enables the model to capture complex cross-camera correlations fundamental for multi-view spatial reasoning, surpassing simpler feature concatenation or token-wise DNN fusions in capturing spatial diversity and compensating for NLoS. The resulting fused feature vector undergoes multi-layer perceptron post-processing to yield the RSSI estimate.
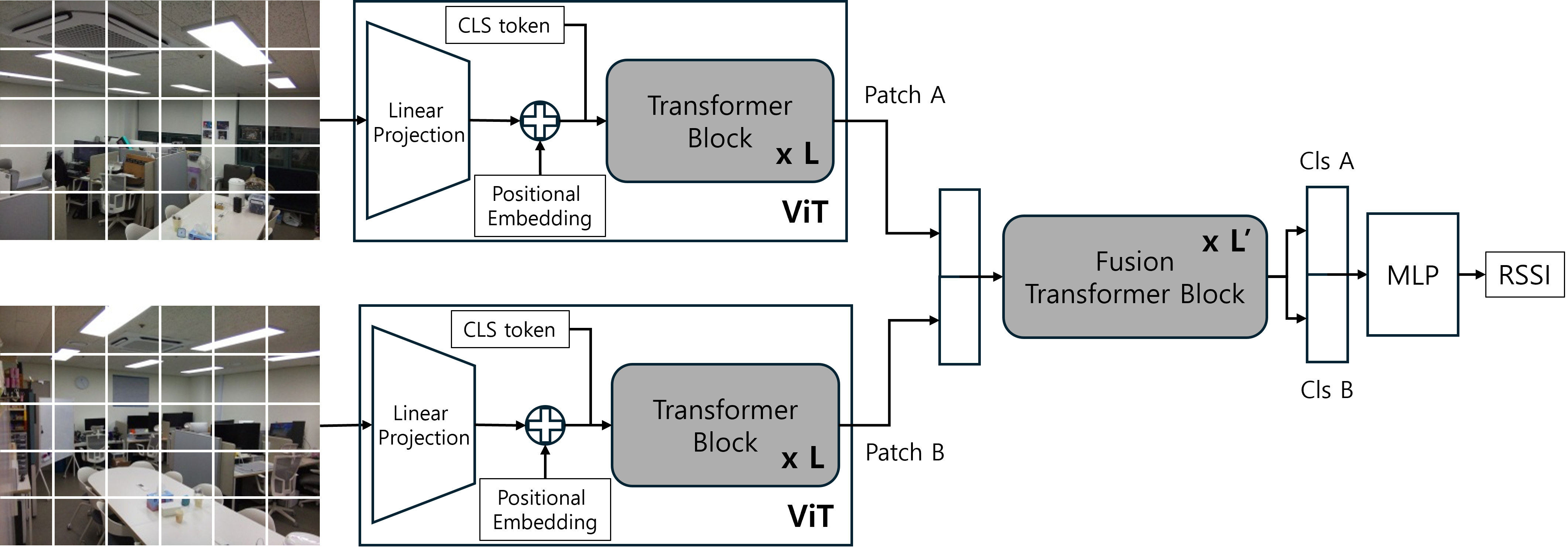
Figure 1: Overall architecture of MulViT-TF with distributed multi-view ViT and Transformer-based fusion.
Experimental Setup and Data Processing
Extensive real-world experiments were conducted in two contrasting indoor environments:
- Scene 1: An office room dominated by NLoS conditions due to furniture-induced occlusions.
- Scene 2: A conference room with predominant LoS propagation.
Both scenarios were instrumented with spatially distributed Raspberry Pi cameras (CAM1, CAM2) and ESP32-based WiFi transmitters/receivers, with geometry and camera deployment visualized below.
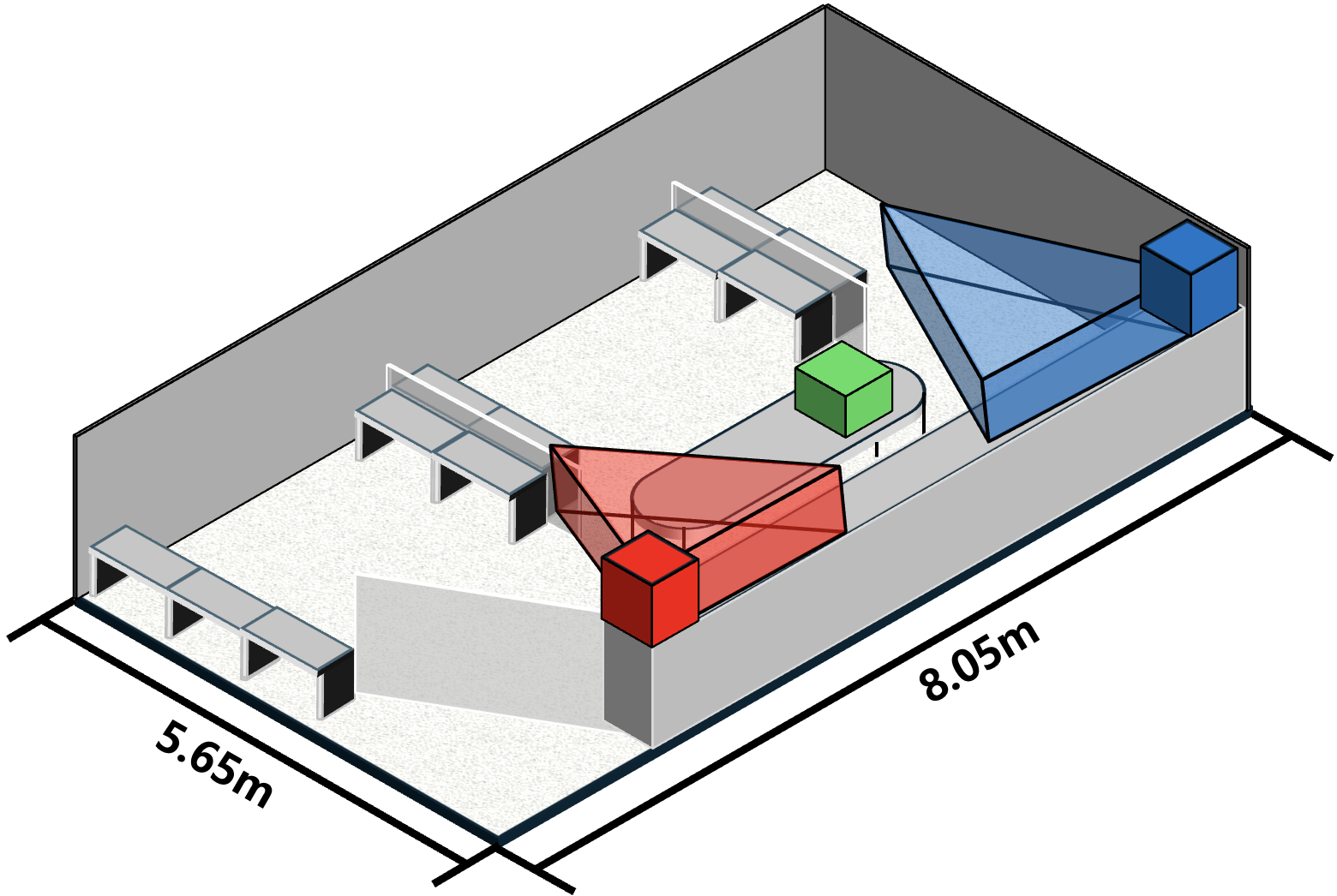
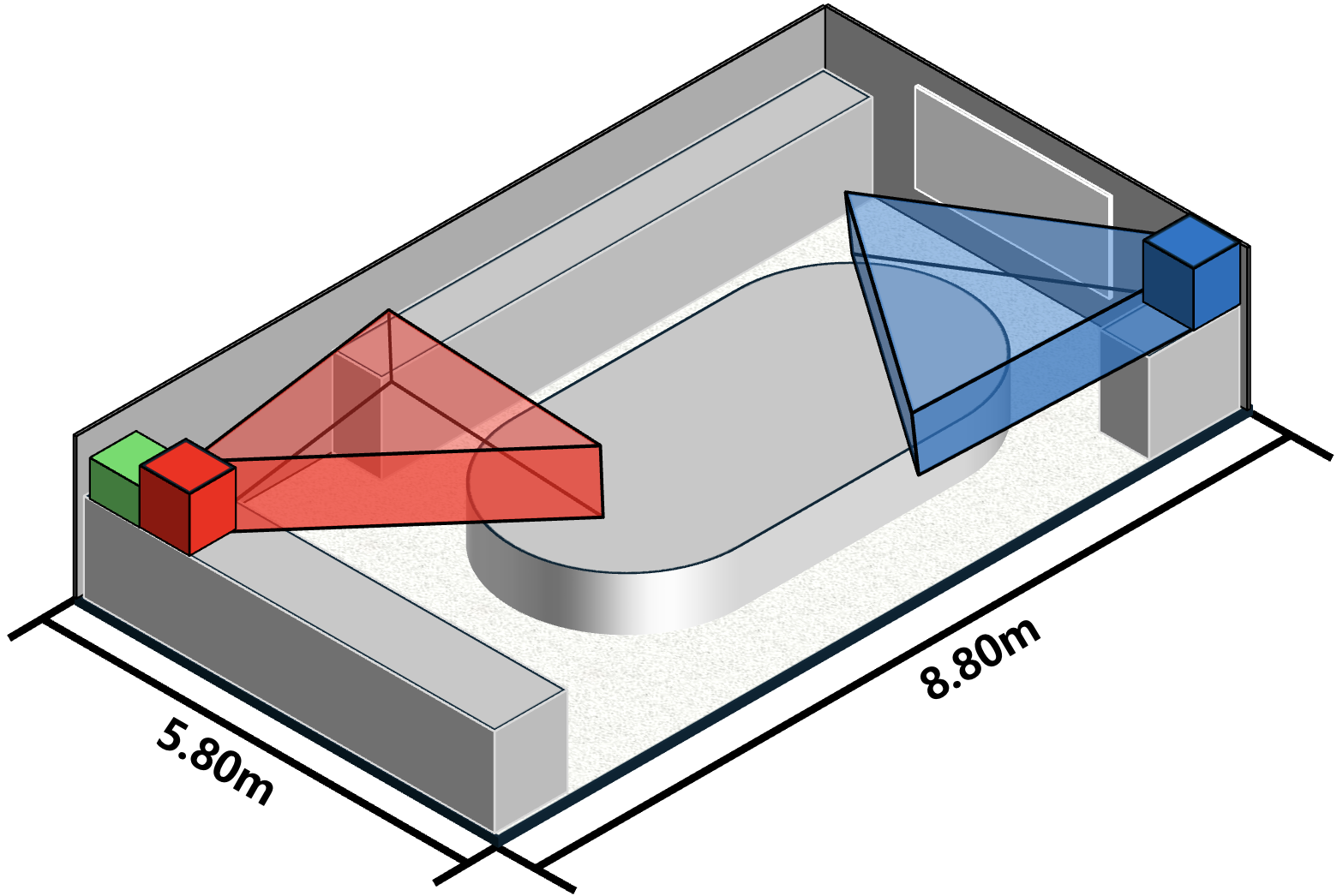




Figure 2: Scene 1 layout depicting distributed camera viewpoints and FoVs relevant for complementary spatial coverage.
RSSI and synchronized RGB images were acquired at 40Hz and 20Hz, respectively, producing 10,000 timestamp-aligned image-RSSI pairs per scene after careful preprocessing: outlier removal, Gaussian smoothing, and NTP-based time alignment.
Strong, consistent improvements are observed with distributed multi-view fusion. MulViT-TF achieves up to 26.3% RMSE reduction and 13.8 percentage points improvement in 3dB error coverage compared to the best single-view baseline, while operating with lower model complexity (FLOPs and parameters) than the strongest single-view ViT (SinViT-W).
Empirical CDF evaluation highlights a significant increase in the proportion of predictions within a strict 3dB error margin—an operationally critical threshold corresponding to a -50% to +100% linear power deviation. The performance and error distribution are robustly improved in MulViT-TF versus both single-view and multi-view token-wise DNN fusion controls. This effect is further visualized by RSSI statistics across experimental environments.
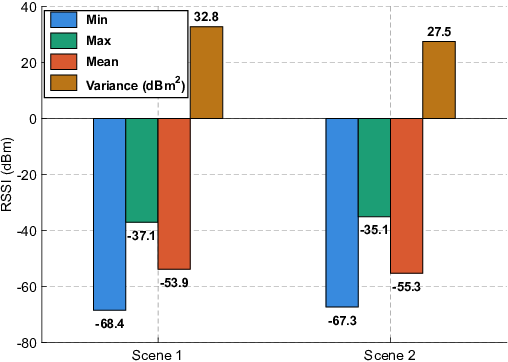
Figure 3: RSSI statistics across Scene 1 (NLoS-rich) and Scene 2 (LoS-rich) showing signal variability targeted by vision-based estimation.
The multi-view Transformer fusion module demonstrably outperforms token-wise DNN approaches (MulViT-TWDNN) in capturing spatial correlations across cameras, especially under harsh multipath or NLoS disruptions typical in practical deployments.
Theoretical and Practical Implications
This work substantiates the viability of multi-view vision-only wireless sensing: eliminating auxiliary sensors and distributed feedback channels while maintaining low-latency, sufficiently accurate, and robust RSSI estimation. The Transformer fusion paradigm enables dynamic selection and integration of spatial cues crucial for generalizing to uncalibrated environments.
From a theoretical perspective, the results validate that inter-view spatial attention layers can effectively model environment-induced wireless signal propagation, particularly in the presence of complex occlusion patterns and variable antenna configurations. Practically, MulViT-TF provides a deployable path to uplink-less RSSI estimation, anticipatory link adaptation, and real-time resource optimization in dense IoT and 6G scenarios where privacy and cost prohibit further sensor instrumentation.
Future Directions
Further avenues include scaling to higher numbers of viewpoints, extending to dynamic multi-user environments, investigating transferability across buildings and layouts, and hardware-efficient adaptations for edge deployment. Generalization of this distributed spatial reasoning approach can benefit other wireless context sensing tasks (e.g., channel estimation, environment-aware beamforming, proactive handover), and may inform broader multimodal AI research in the unification of spatial and signal domain learning.
Conclusion
MulViT-TF demonstrates substantial improvements in indoor RSSI estimation by unifying distributed multi-view ViT encoding with Transformer-based spatial fusion. The architecture removes the need for auxiliary sensing—a usual limitation in prior methods—while providing robust, low-overhead performance in NLoS and FoV-challenged conditions. These results advance practical vision-based wireless sensing and establish a precedent for distributed, multi-view Transformer architectures in environmental understanding and link adaptation tasks.