- The paper introduces an open-source platform that generates, verifies, and analyzes comprehensive agent reasoning traces linked to document retrieval.
- It employs Corpus-Aware Seeding to optimize topic diversity and an Active Validation Loop to ensure trace verifiability.
- Empirical results show enhanced retrieval breadth and reduced redundancy, setting a new benchmark for agent simulation.
Introduction
The evolution of LLMs into agentic architectures, capable of multi-step reasoning and tool usage, creates demand for auditable, process-level supervision—especially in retrieval-augmented generation (RAG). Traditional datasets typically focus on question-answer endpoints, fail to tie reasoning traces to verifiable document evidence, or only capture interface-level interactions, thereby ignoring the cognitive workflow of retrieval, synthesis, and strategy adaptation. "AgentSim: A Platform for Verifiable Agent-Trace Simulation" (2604.26653) presents an integrated solution to this problem by introducing an open-source platform for systematically generating, validating, and analyzing comprehensive agent reasoning traces, meticulously linked to concrete retrieval actions over arbitrary document corpora.
AgentSim’s architecture integrates a visual web-based workflow designer and a scalable command-line toolkit. Researchers can specify agent pipelines, incorporate various LLMs and retrieval backends, and instantiate reproducible experiments. Two central methodological contributions anchor the platform:
1. Corpus-Aware Seeding:
AgentSim addresses the inefficiency and bias of naive random or stratified seeding by embedding all candidate queries, clustering them (typically K=50), and using maximal marginal relevance (MMR) to ensure that the chosen seed set jointly optimizes topic diversity and retrieval novelty. This pipeline systematically explores the breadth of the document corpus and minimizes redundant retrievals.
2. Active Validation Loop:
Data quality and diversity are bolstered via a multi-model active validation pipeline. For each simulated step, an Analyst (generation model) proposes the next action, two Critics offer independent evaluations, and a Judge computes a Divergence Score indicating cross-model disagreement. Only steps exceeding a threshold are escalated for focused human annotation, while low-confidence grounding automatically triggers document re-retrieval. This approach targets human review where it is most consequential, enables large-scale curation, and achieves high rates of grounded answers.
Construction and Structure of the Agent-Trace Corpus (ATC)
Using AgentSim, the authors release the Agent-Trace Corpus (ATC): over 103,000 verifiable reasoning steps, 20,548 supervised training pairs, and nearly 200,000 unique retrieval actions, spanning MS MARCO, Quasar-T, and CausalQA. Each reasoning step is traceable to cited passages in the underlying corpus—a critical property for transparent audit and process-level supervision.
The corpus is released in three granularities:
- Traces: Full thought→action→observation sequences, for detailed behavioral analysis.
- Trajectories: Abstract action sequences mapping invoked tools and their results.
- Supervised pairs: Direct question, evidence, and synthesis triples suitable for fine-tuning.
For trace verifiability, the authors conducted explicit audits: 100% of substantive synthesized answers (after excluding correct abstentions due to insufficient evidence) are grounded in their cited documents, with 87.2% token coverage. An NLI-based analysis found that 83.3% of atomic claims are fully supported—a level of verification unmatched by prior reasoning-trace corpora.
Empirical Evaluation
The central empirical evaluation targets both the efficacy of the seeding mechanism and the comparative behavioral analysis of multiple SOTA LLM agents in simulated search environments.
Seeding Policy Assessment
Corpus-Aware Seeding delivers statistically significant improvements over Random, Stratified, and Determinantal Point Process (DPP)-based baselines. It achieves perfect cluster coverage, substantially lower retrieval redundancy, and higher corpus coverage. It also yields the greatest proportion of initiated traces that proceeded to non-degenerate explorations (68–98%).
Comparative Agent Behavior
Using 3,000 seeds per dataset and rotating analysts between GPT-4o, Mistral-Large, and DeepSeek-v3, the platform enables direct measurement of exploration diversity and redundancy.
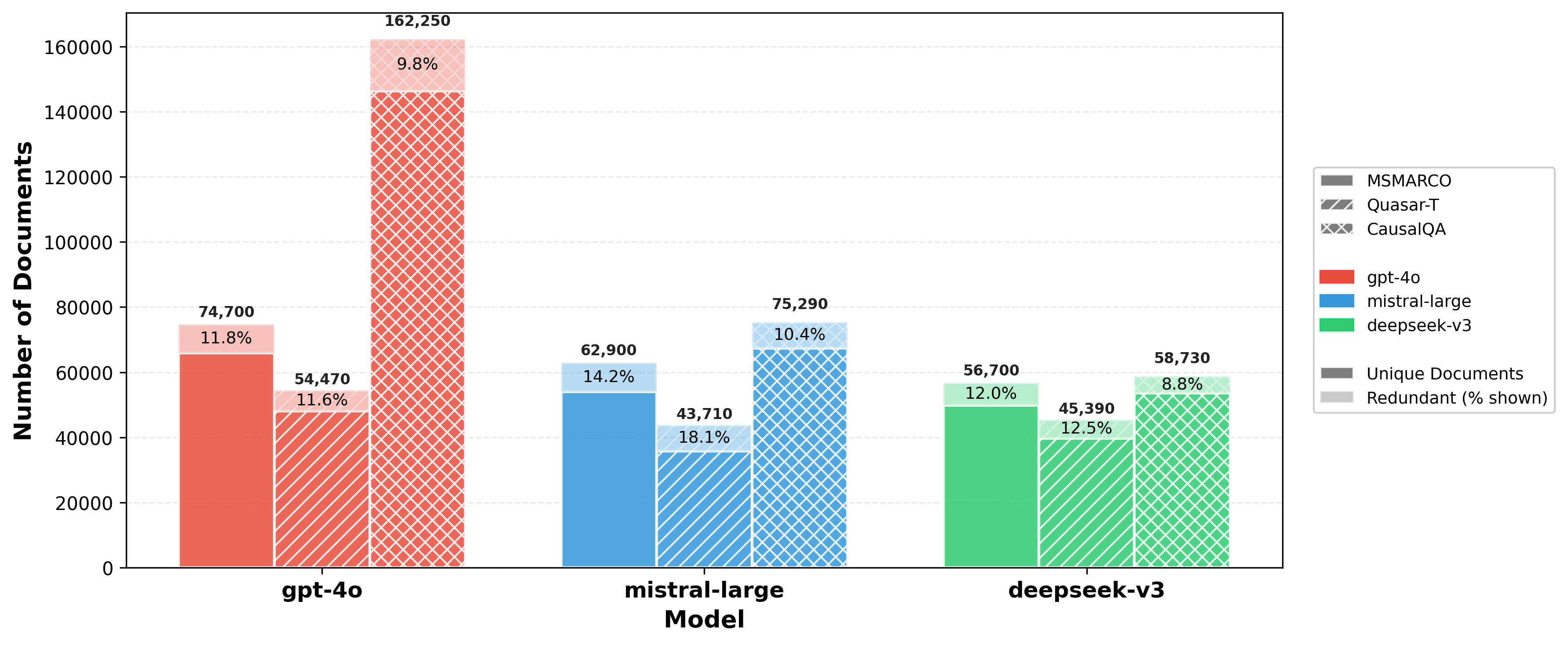
Figure 1: Exploration breadth and retrieval redundancy across MS MARCO, Quasar-T, and CausalQA for three SOTA LLM analyst models.
GPT-4o achieves the highest exploration breadth, retrieving up to 176% more unique documents than DeepSeek-v3 on the CausalQA corpus. In contrast, Mistral-Large exhibits the highest document redundancy, indicating a tendency towards verification rather than breadth-first exploration. DeepSeek-v3’s policies skew towards syntactic query simplification and conservative document expansion. These differences are statistically robust and tied directly to each model’s engagement with the active validation pipeline.
(Query reformulation analysis reveals that DeepSeek-v3 disproportionately favors syntactic keyword reduction, while GPT-4o and Mistral-Large prefer conceptual expansion. This is reflected in average query length dynamics and in the breadth of exploration.)
In synthesis under uncertainty, GPT-4o and Mistral-Large favor majoritarian decisive answers, whereas DeepSeek-v3 is more likely to explicitly acknowledge contradictions, highlighting divergent policies on confidence calibration versus caution—strategic axes critically relevant for deploying trustworthy agentic systems.
Implications and Directions
AgentSim demonstrates that the grounded collection of agent-level cognitive traces enables new lines of empirical analysis in agent reasoning policies, exploration strategies, and synthesis under uncertainty. The corpus supports fine-tuning across paradigms (CoT, imitation, query reformulation, abstention detection, student-teacher distillation) and demonstrates direct sample-efficiency improvements: fine-tuning Qwen-0.5B using ATC raises abstention-detection F1 from 0.362 to 0.815.
Practical implications are substantial. The capacity for explicit error auditing, root-cause analysis, and targeted process reward modeling in RAG agents directly supports real-world deployment in high-stakes domains (e.g., scientific or legal IR). The platform's modularity and open codebase facilitate rapid domain transfer and extensibility.
From a theoretical perspective, the finding that grounding and trace diversity drastically affect downstream reasoning generalization calls for further exploration of how fine-grained process supervision can replace or complement endpoint benchmarks. As LLMs continue to scale and diversify, explicit, verifiable trace datasets like ATC are poised to become foundational assets for trustworthy agentic AI.
Conclusion
AgentSim systematically closes the cognitive RAG gap by enabling large-scale, reproducible, and verifiable simulation of agent reasoning over document collections. The dual innovations of Corpus-Aware Seeding and Active Validation facilitate the construction of a high-quality, auditable corpus that surpasses prior work in both scale and fidelity of reasoning supervision. The comparative behavioral analysis made possible by AgentSim sets a new standard for examining, diagnosing, and training agentic LLMs. Future research will naturally extend to domain-adapted trace generation, richer human-in-the-loop validation protocols, and deeper exploration of process-level reward modeling for agent alignment.
The software, corpus, and evaluation toolchain are provided openly, and the framework is modeled to catalyze ongoing community contributions and benchmarking of agentic systems.

