- The paper introduces ATLAS, a modular annotation tool that integrates synchronized multi-modal robotic data to enhance action boundary detection.
- The paper demonstrates that the keyboard-centric design and extensible dataset interfaces reduce annotation time, achieving record low times and high expert label alignment.
- The paper validates ATLAS through quantitative comparisons, showing superior efficiency and a fivefold reduction in temporal segmentation error over existing tools.
Motivation and Problem Statement
Precise annotation of long-horizon robotic manipulation data is central to data-driven learning and evaluation of temporal action segmentation, a foundational problem for policy learning in complex robotic tasks. While annotation tools for computer vision and behavioral studies exist, they lack vital support for time-synchronized, multi-modal robot data (including gripper state, force/torque, and multiple sensor streams), and either require impractical modality adaptation or demand inefficient user workflows. Collecting new annotated datasets is expensive, and existing resources are often in heterogeneous formats with insufficient annotations. Thus, a need exists for a domain-specialized, extensible, and efficient annotation tool capable of integrating existing large-scale data resources and optimizing human-in-the-loop efficiency.
System Overview and Feature Set
ATLAS is introduced as a modular, extensible annotation tool specifically tailored for long-horizon robotic action segmentation. The design is guided by four core principles: (i) synchronized, multi-modal visualization, (ii) compatibility with multiple dataset formats, (iii) keyboard-centric, efficient workflows, and (iv) extensibility via an abstract dataset interface. The system is architected around a modular backend supporting abstract dataset integration, paired with a PyQt5-based interactive frontend.
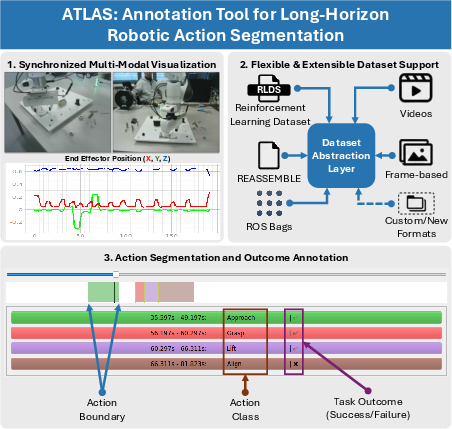
Figure 1: ATLAS provides synchronized multi-modal annotation of robotic actions, supporting diverse dataset formats and annotation of action boundaries, classes, and outcomes.
Native support encompasses standard video files, frame-based datasets, ROS bag files, RLDS (Reinforcement Learning Dataset) format, and domain-specific datasets such as REASSEMBLE. The dataset plugin system allows the integration of new formats through subclassing, decoupling annotation logic from data loading specifics. The tool is highly configurable, with customizable visualization and workflow options, and supports efficient, keyboard-centric annotation to minimize annotator latency.
Interface, Workflow, and Data Handling
The main interface is organized into five vertically stacked panes: synchronized multi-view camera feeds, selectable time-series signal plots, episode description field, navigation timelines, and annotation panels. This structure provides real-time context for accurate segmentation, and allows the annotator to navigate, segment, and label actions efficiently, including binary labeling of task outcomes (success/failure).
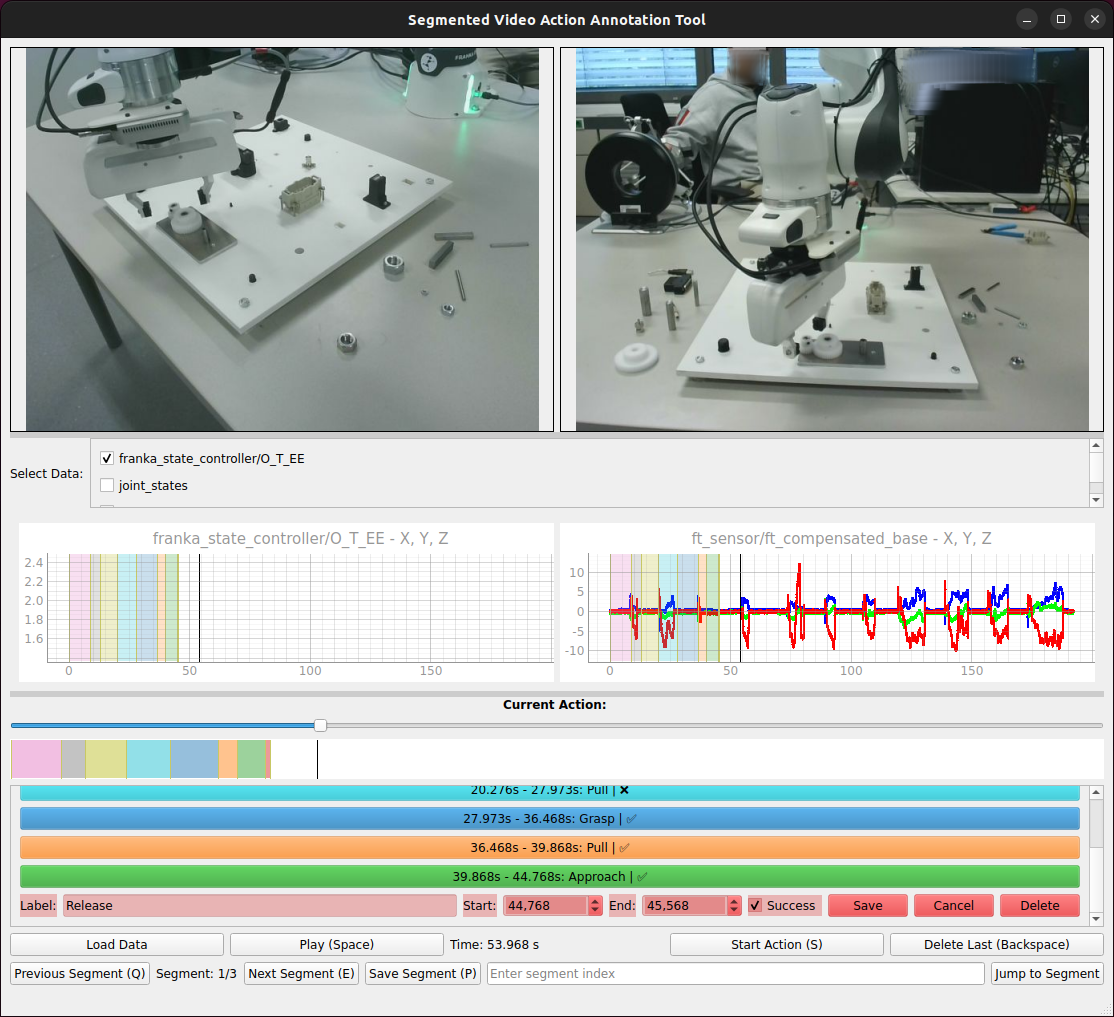
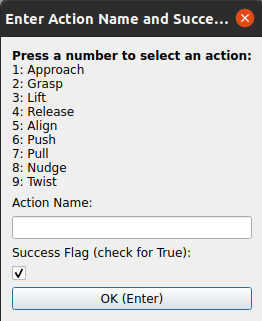
Figure 2: (a) The ATLAS GUI shows synchronized video and signal data for annotation. (b) The action dialog enables assignment of semantic class and outcome. (c) The modular code structure allows extension to arbitrary data formats.
Synchronization between mismatched sensory modalities is accomplished through optimized timestamp mapping, and the tool manages dataset-specific idiosyncrasies (e.g., explicit versus inferred timestamps, multi-view consistency). The backend preprocesses all streams to NumPy arrays, leveraging background threads and ring buffers for low-latency access, even in large-scale datasets.
To add a new dataset, one simply implements the required data interface, as illustrated in the modular code structure, allowing seamless extensibility to novel data schemas and emerging robotics benchmarks.
Experimental Analysis and Quantitative Outcomes
The utility of ATLAS is evaluated through structured comparison with representative annotation tools: ROSAnnotator, ELAN, and its own variants (vision-only and vision-plus-proprioception). Tasks involved annotating contact-rich, long-horizon robotic gear assemblies, with precise ground truth established by expert annotators.
Key metrics included per-action annotation time, annotation-expert alignment score (continuous-time agreement), and average boundary distance (error in temporal segmentation).
Key numerical results:
- Annotation efficiency: ATLAS (vision-only) achieved the lowest average annotation time (11.0±1.2 s/action), outperforming ELAN (19.7±1.1 s) and ROSAnnotator (26.9±6.1 s).
- Annotation quality: ATLAS (vision + proprioception) produced the highest alignment with expert labels (99.4±0.1% agreement), and a fivefold reduction in boundary error (0.06±0.01 s) compared to vision-only tools.
- The keyboard-centric design in ATLAS accounts for the efficiency gain over ELAN, which, despite also supporting keyboard shortcuts, suffers from a less ergonomic, less context-specific interface.
The addition of proprioceptive and force-related signals increases annotation time (to 18.5±0.9 s/action) due to increased cognitive demands but yields substantial gains in segmentation accuracy and inter-annotator consistency.
Theoretical and Practical Implications
ATLAS provides an extensible annotation pipeline that directly addresses the limitations of earlier tools—namely, lack of robotic modality integration, inefficient human annotation paradigms, and dataset inflexibility. Time-synchronized, multi-modal contextual information is shown to be critical for reliable action boundary detection in contact-rich, highly dynamic settings, directly impacting the training and benchmarking of both supervised and unsupervised temporal segmentation methods.
By significantly reducing per-action annotation time and maximizing annotation quality, ATLAS lowers the barrier for dataset curation in robotics, particularly for large and heterogeneous archives such as Open X-Embodiment. These capabilities reduce overall annotation cost and facilitate the extension of existing benchmarks with richer, more granular supervision, supporting progress in policy learning, skill discovery, and evaluation. The tool's extensibility ensures future compatibility as data collection practices and format standards evolve.
Future Directions
Potential extensions of ATLAS include integration with collaborative annotation services, semi-automated active learning loops, and fine-grained user analytics to further optimize annotation strategy. As robot learning tasks become more complex, domain-adapted annotations (e.g., force events, failure type taxonomies) and direct coupling with downstream learning algorithms will become increasingly valuable. ATLAS establishes a foundation for such extensions due to its modular architecture.
Conclusion
ATLAS systematically addresses the unique challenges of annotating long-horizon multi-modal robotic action data by combining efficient keyboard-centric interfaces with synchronized visualization and extensible data handling. Quantitative experiments demonstrate superior efficiency and annotation quality relative to leading alternatives. ATLAS's open extensibility and integration with canonical robotics formats position it as a critical tool for accelerating dataset curation and advancing research in robotic skill acquisition and temporal segmentation.