- The paper presents a novel Sparse-on-Dense architecture that combines dense systolic arrays with decompression logic to process sparse neural networks efficiently.
- The design inserts decompression units between the global buffer and PE array, enabling compressed data storage with only ~2% area overhead.
- Experimental results on AlexNet, VGG-16, and BERT demonstrate up to 11.9× throughput/area and 3.2× energy efficiency improvements over traditional sparse accelerators.
Sparse-on-Dense: Efficiently Mapping Unstructured Sparse Neural Networks onto Dense Matrix Multiplication Accelerators
Introduction
The increasing complexity and size of state-of-the-art DNNs, particularly in domains such as CV and NLP, amplify requirements for compute and memory resources. While unstructured pruning and other compression techniques yield significant reductions in both operations and memory by imposing sparsity, hardware utilization remains challenging: conventional sparse accelerators achieve high MAC utilization via complex index-matching logic and large FIFOs/buffers, resulting in prohibitive area and power overhead. Addressing the core architectural dilemma—whether to deploy a smaller number of highly-utilized, area-intensive sparse PEs or a greater number of lower-utilization, area-efficient dense PEs for sparse workloads—this work answers in favor of the latter. Sparse-on-Dense is introduced as a hybrid architecture, leveraging the memory and energy benefits of sparse data representations with the simplicity and spatial compute density of dense systolic PE arrays.
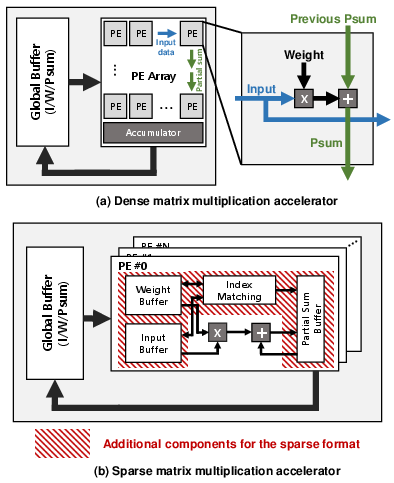
Figure 1: Architectures of the neural network accelerators: (a) Dense matrix multiplication accelerator (b) Sparse matrix multiplication accelerator.
Sparse-on-Dense Architecture
Sparse-on-Dense augments a conventional, TPU-style systolic PE array with decompression units strategically placed between the global buffer and PE array (rather than before the buffer) to maintain compact SRAM storage of sparse matrix data. The decompression units reconstruct the CSC-encoded weights and/or activations to a format directly consumable by the dense PEs, allowing all memory savings to be realized prior to matrix multiplication. During dense network execution, decompression is bypassed entirely. The top-level architecture thus seamlessly supports both unstructured sparse and dense workloads without modification, enabling effective multi-tenant and flexible DNN compute.
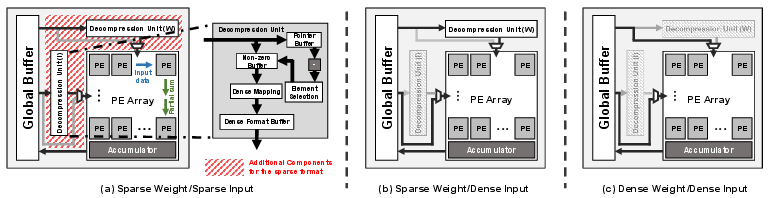
Figure 2: Overall architecture of Sparse-on-Dense and its operation mode for various input and weight densities.
Storage in compressed formats enhances SRAM reuse for tiled tensors, directly reducing external DRAM bandwidth and energy demands. The decompression pipeline is optimized for parallel bandwidth utilization and minimal area additions; its control logic rapidly maps values and indices to the appropriate dense slices in the systolic array’s input space.
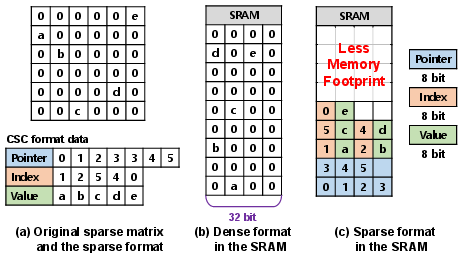
Figure 3: Memory usage for dense and sparse data representations in on-chip SRAM.
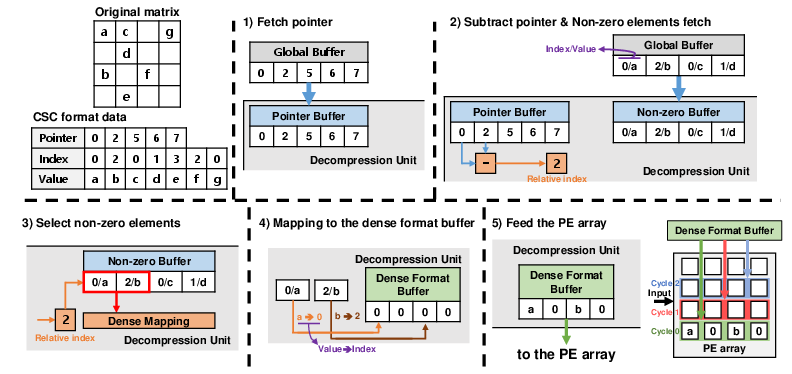
Figure 4: Stepwise decompression of sparse CSC-encoded weights; input decompression is analogous.
Experimental Results and Architectural Evaluation
Area and Power Breakdown
The decompression unit contributes an area overhead of only ~2% relative to a 4K PE array (Fig. 5), with negligible impact on overall chip area when accounting for SRAM.
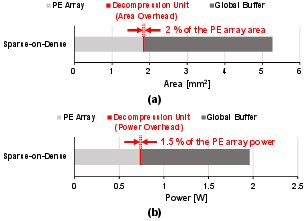
Figure 5: Area and power breakdown for Sparse-on-Dense. PE array: 4K PEs, 2 MB SRAM.
Throughput/Area and Energy Efficiency Trade-Off
Sparse-on-Dense maintains throughput/area (TOPS/mm²) within 1% of a classical dense-only accelerator when processing dense data. For pruned workloads, Sparse-on-Dense exhibits enhanced energy efficiency (up to 1.5–2.4× for moderate sparsity) versus dense baselines by reducing memory transfers and the associated DRAM/system power (Fig. 6).
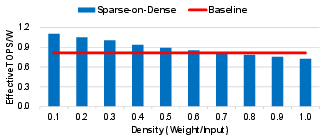
Figure 6: Energy efficiency of dense baseline vs. Sparse-on-Dense under varying data densities.
Compared to prior art for sparse computation (ESE, SCNN, SNAP, SIGMA), Sparse-on-Dense consistently delivers higher throughput/area in all but the extremely low-density regime, where specialized index-matching can yield utilization gains at high logic overhead. Notably, at typical DNN pruning densities (0.2–0.6), Sparse-on-Dense outperforms ESE, SCNN, and SNAP by 0.8–11.9× in throughput/area, and up to 3.2× in energy efficiency.
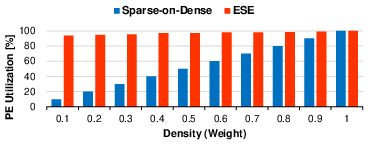
Figure 7: PE utilization comparison between Sparse-on-Dense and ESE for sparse weight-dense input.
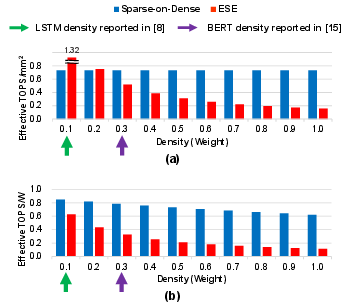
Figure 8: Throughput/area and energy-efficiency: Sparse-on-Dense vs. ESE (density = 0.1 for LSTM, 0.3+ for BERT).
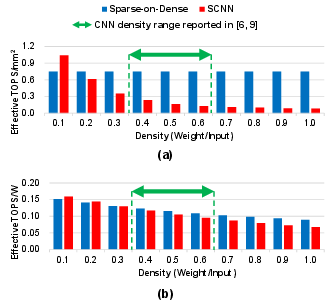
Figure 9: Throughput/area and energy-efficiency: Sparse-on-Dense vs. SCNN.
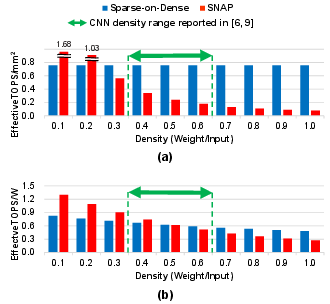
Figure 10: Throughput/area and energy-efficiency: Sparse-on-Dense vs. SNAP.
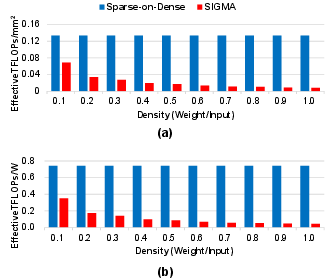
Figure 11: Throughput/area and energy-efficiency: Sparse-on-Dense vs. SIGMA.
Benchmark Layer-wise Analysis
Sparse-on-Dense was evaluated on real pruned DNNs: AlexNet and VGG-16 (CV, unstructured pruning following [han2015learning]), and BERT (NLP, SQuAD/MNLI tasks using movement pruning [sanh2020movement]). With moderate to high sparsity (BERT SQuAD: ~0.33, MNLI: ~0.13; VGG-16: ~0.33), Sparse-on-Dense achieves significant gains compared to ESE and SCNN even in layer-wise breakdown. For instance, on AlexNet, the average throughput/area improvement over SCNN is 11.9×, and energy efficiency is up to 3.2× over ESE on BERT SQuAD.
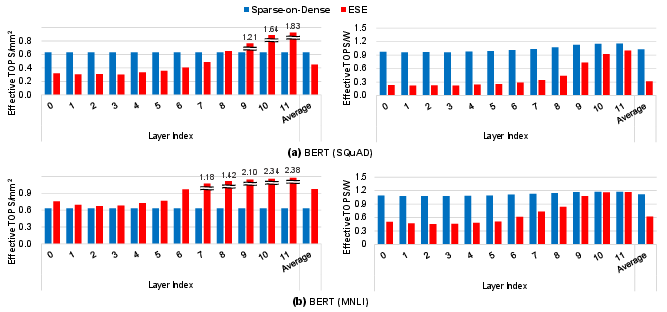
Figure 12: Layer-wise throughput/area and energy efficiency: Sparse-on-Dense vs. ESE for BERT SQuAD/MNLI.
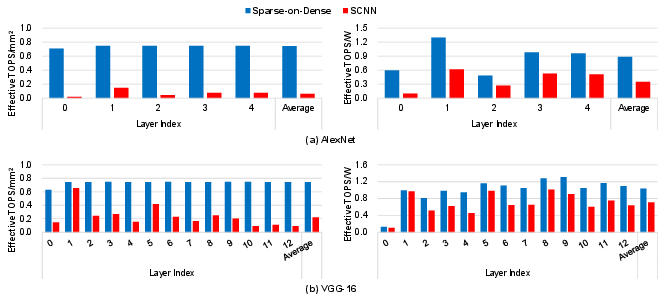
Figure 13: Layer-wise throughput/area and energy efficiency: Sparse-on-Dense vs. SCNN for AlexNet and VGG-16.
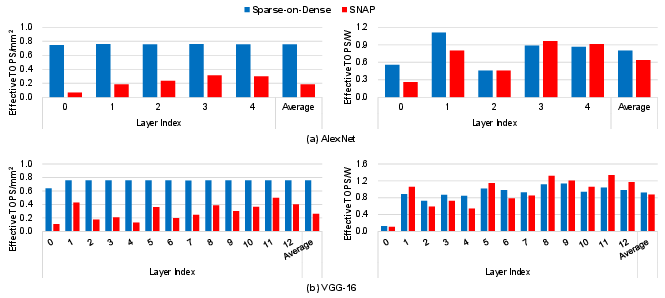
Figure 14: Layer-wise throughput/area and energy efficiency: Sparse-on-Dense vs. SNAP for AlexNet and VGG-16.
Notably, Sparse-on-Dense also supports workloads with dense or structured-sparse layers without performance drop (by bypassing decompression), providing full workload generality. In contrast, prior sparse designs are typically restricted in supporting only certain compute patterns or kernel sizes.
Design Implications and Future Prospects
The results definitively indicate that for plausible area budgets and in-practice DNN sparsity levels, maximizing PE count—via simple, dense PEs operated on decompressed data—outperforms complex sparse PE-centric designs, except in rare extreme-sparsity regimes. The regular address paths of systolic arrays enable simpler routing, less congestion, and higher scalable energy efficiency as model size grows.
Sparse-on-Dense’s flexibility to execute both unstructured and dense matrix multiplications with a single PE array is crucial for contemporary multi-tenant and transformer-centric DNN workloads, where both compute patterns co-exist. The architecture could trivially benefit from advanced power-gating and voltage-domain partitioning, further boosting energy efficiency under partial utilization scenarios. The approach also scales well with broader research in dynamic sparsification and mixed-sparsity models.
Conclusion
Sparse-on-Dense demonstrates that, contrary to trends in index-matching-intensive sparse accelerators, large-scale systolic arrays with decompression-adapted input logic outperform explicit sparse PEs in throughput/area and energy efficiency for typical pruned DNNs. The architecture supports unstructured/structured/dense workloads with negligible area overhead and achieves up to 11.9× throughput/area and 3.2× energy efficiency improvement versus strong sparse baselines on real benchmarks. The results strongly support architectural simplification and flexible, software-transparent sparse acceleration as foundational for upcoming hardware DNN accelerators.
Reference: "Sparse-on-Dense: Area and Energy-Efficient Computing of Sparse Neural Networks on Dense Matrix Multiplication Accelerators" (2604.26587).

