- The paper demonstrates that KV cache reuse preserves complete token-wise information to mitigate long-range decay in speculative decoding.
- It introduces the KVShot diagnostic framework to compare hidden-only, KV-only, and hybrid reuse paradigms through empirical evaluation on Qwen3-8B.
- The study identifies structural bottlenecks like query estimation challenges and sparse gradient flows that limit overall inference speedup.
Motivation and Context
Speculative decoding is a critical acceleration technique for LLM inference, enabling parallel candidate generation and verification to amortize the otherwise sequential autoregressive generation cost. Hidden-state reuse, exemplified by EAGLE and MTP architectures, has become the dominant drafter paradigm. However, these drafters are susceptible to long-range decay: acceptance rates for drafted tokens steeply decline as the speculative step increases, fundamentally limiting attainable speedups. While train-inference mismatch—wherein drafters conditioned on target hidden states must instead rely on recursively self-generated states at inference—has been posited as the primary cause, the persistence of long-range decay in autoregressive test-time training (TTT)-aligned models indicates the existence of deeper structural constraints.
The paper advances an information-theoretic view of long-range decay, formalizing the distinction between hidden-state and KV cache reuse. Target hidden states are query-dependent compressions: Transformer attention weights aggregate value vectors with respect to the decoding query, optimizing next-token prediction. The result is suppression of tokens deemed less relevant by the query's focus—even if those tokens become crucial for later speculative steps. This renders hidden-state-based drafters an ill-conditioned information recovery problem; reconstructing suppressed signals grows progressively harder with increasing draft depth.
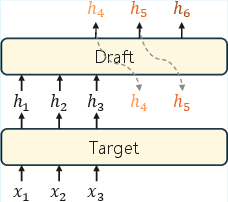
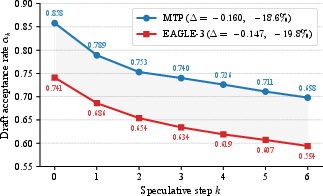
Figure 1: Hidden-state recursion highlights how recursive conditioning on self-generated hidden states leads to compounding distributional drift and information loss.
Contrastingly, the target model's KV cache retains all token-wise key-value pairs pre-aggregation, allowing draft models to re-attend to any prefix position using estimated queries. This recasts drafting as function approximation—accurately estimating future queries becomes the bottleneck, not information recovery—allowing every historical token to remain accessible regardless of initial attention suppression.
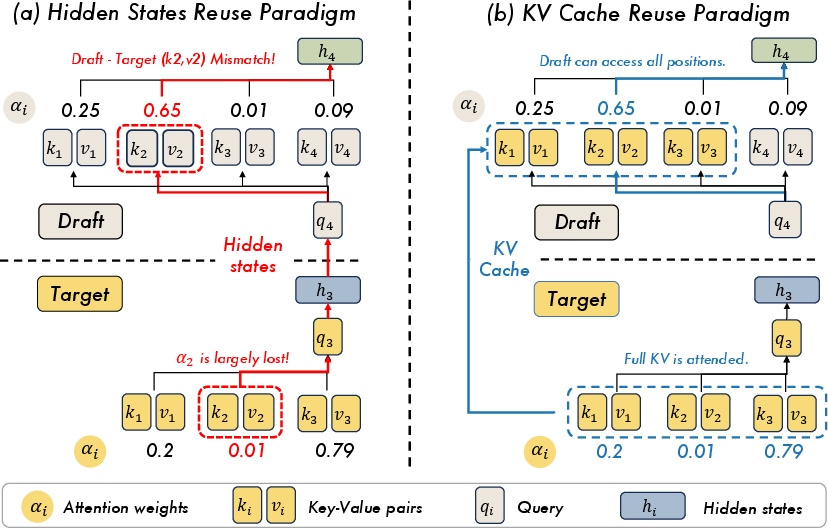
Figure 2: Comparison between hidden-state reuse (biased compression) and KV reuse (re-attention) illustrates superior prefix accessibility and potential information preservation with KV caches.
Three practical distinctions further complicate equivalence between hidden states and KV cache: there is a loss of top-layer KV information in standard hidden-state reuse, non-trivial projection gaps requiring shallow drafters to implicitly learn expensive transformations, and capacity competition when hidden-state-based drafters must simultaneously reconstruct projections and queries.
KVShot Diagnostic Framework and Reuse Paradigms
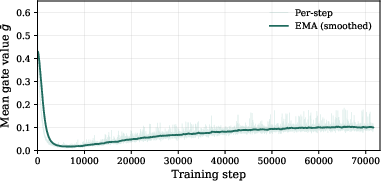
To isolate these effects, the paper introduces KVShot—a unified diagnostic framework facilitating controlled evaluation of three paradigms: hidden-only reuse (EAGLE/MTP), KV-only reuse (direct target KV cache injection via cross-attention), and hybrid reuse (gated fusion of hidden and KV signals).
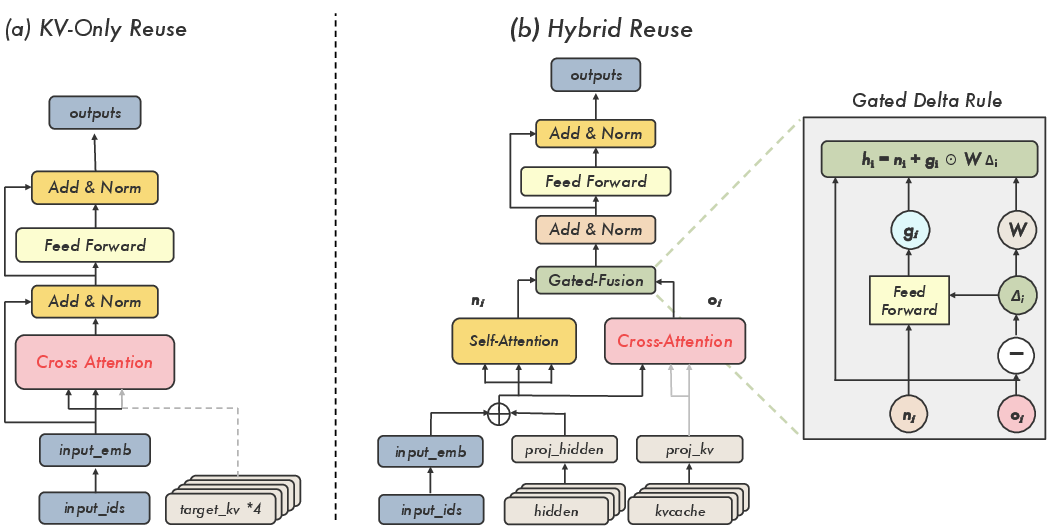
Figure 3: KVShot architecture variants: KV-only reuse enables direct cross-attention to target cache; hybrid reuse applies a gated delta correction to hidden-state anchor.
Empirical investigation is performed on Qwen3-8B using autoregressive TTT, with acceptance rates and mean accepted tokens (MAT) as primary metrics. The evaluations discriminate effects of representation choice from confounding factors.
Numerical Results and Structural Bottlenecks
KV-only reuse is empirically shown to degrade more gracefully than hidden-state reuse as draft steps increase. However, gains are insufficient to yield significant end-to-end speedup due to structural bottlenecks:
Despite hybrid drafters exceeding EAGLE-3 baseline in step-wise MAT (2.54 vs. 2.37), end-to-end improvements are marginal (MAT increase of only 0.03 on large-scale data with additional drafting latency of 5–10%), primarily due to stronger baselines with larger datasets and compressed differences under tree verification.
Practical Implications and Future Directions
The theoretical advantage of KV cache reuse is validated at the step-wise level: it provides more robust long-range context preservation and enables hybrid designs that outperform hidden-only drafters. However, the sequential constraints and sparse optimization dynamics in autoregressive TTT pipelines currently prevent full exploitation of these benefits in wall-clock inference.
This motivates the exploration of block-wise and non-autoregressive training paradigms, such as DFlash, that allow parallel prediction of token blocks, denser gradients for KV projection, and deeper drafters. These settings are theoretically better aligned with the structural needs of KV-aware drafting, offering pathways for unlocking practical acceleration.
Theoretical and Practical Implications
From a theoretical perspective, this work reframes speculative decoding bottlenecks as information-preservation and capacity allocation problems, highlighting that usable information in KV caches is only as valuable as the query estimation power and training signal diversity. Practically, the findings suggest hybrid drafters, though promising, require pipeline-level innovation beyond autoregressive TTT—particularly block-wise training—to realize speedups commensurate with step-wise improvements.
Conclusion
This work delivers a rigorous analysis of long-range decay in speculative decoding, arguing for the KV-reuse hypothesis and substantiating it via the KVShot diagnostic framework. While KV reuse demonstrably alleviates step-wise decay, structural bottlenecks impede end-to-end gains under current pipelines. The central implication is clear: KV caches carry valuable long-range signals, but future drafter architectures and training strategies must explicitly address query estimation, gradient density, and fusion dynamics to translate theoretical advantages into practical inference speedups.