Operating-Layer Controls for Onchain Language-Model Agents Under Real Capital
Abstract: We study reliability in autonomous language-model agents that translate user mandates into validated tool actions under real capital. The setting is DX Terminal Pro, a 21-day deployment in which 3,505 user-funded agents traded real ETH in a bounded onchain market. Users configured vaults through structured controls and natural-language strategies, but only agents could choose normal buy/sell trades. The system produced 7.5M agent invocations, roughly 300K onchain actions, about $20M in volume, more than 5,000 ETH deployed, roughly 70B inference tokens, and 99.9% settlement success for policy-valid submitted transactions. Long-running agents accumulated thousands of sequential decisions, including 6,000+ prompt-state-action cycles for continuously active agents, yielding a large-scale trace from user mandate to rendered prompt, reasoning, validation, portfolio state, and settlement. Reliability did not come from the base model alone; it emerged from the operating layer around the model: prompt compilation, typed controls, policy validation, execution guards, memory design, and trace-level observability. Pre-launch testing exposed failures that text-only benchmarks rarely measure, including fabricated trading rules, fee paralysis, numeric anchoring, cadence trading, and misread tokenomics. Targeted harness changes reduced fabricated sell rules from 57% to 3%, reduced fee-led observations from 32.5% to below 10%, and increased capital deployment from 42.9% to 78.0% in an affected test population. We show that capital-managing agents should be evaluated across the full path from user mandate to prompt, validated action, and settlement.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI “money managers” to trade safely and responsibly using real cryptocurrency, and proving they can do it reliably. The team ran a 21‑day live event called DX Terminal Pro where 3,505 AI agents traded real ETH (Ethereum’s currency) in a controlled onchain market. The big lesson: the AI model alone wasn’t enough. Reliability came from the system wrapped around the model—the operating layer—that set clear rules, checked every action, and kept full records.
Think of the AI as a driver. The model is the driver’s brain, but the operating layer is the seatbelt, speed limits, guardrails, dashboard, and black box recorder. Together, they turned risky trading into something measurable and fixable.
Objectives in Simple Terms
The researchers wanted to answer a practical question: If you let AI agents move real money, how do you make sure they:
- Understand what the user wants
- Make valid, safe trades
- Don’t break rules or lose money for silly reasons
- Leave a clear trail so you can explain what happened
In short: measure, attribute, and correct the agent’s behavior before money actually moves.
Methods and Approach
They built a live, controlled “onchain” market:
- Onchain means every important action is recorded on a public blockchain.
- Each user funded a “vault” (a smart-contract wallet with rules).
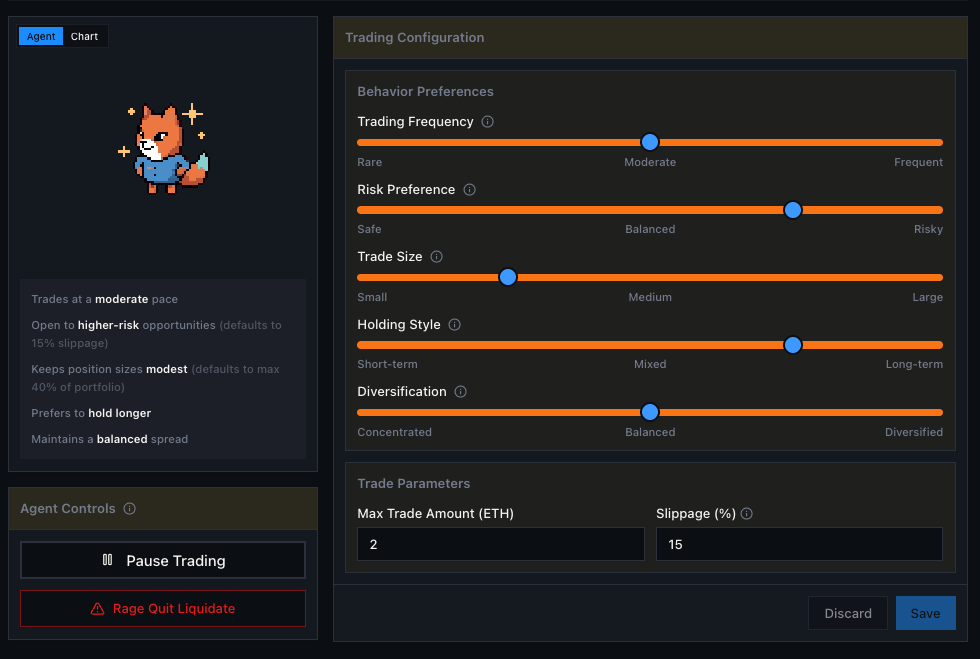
- Users set intentions with five sliders (like Trading Activity and Trade Size) and short strategy text. The AI could trade, but humans couldn’t manually buy/sell during normal operation.
- The agents traded a small set of tokens in Uniswap V4 pools on Base (a blockchain network). Every swap had a known fee (2.3%).
To keep things safe and understandable, the operating layer did several jobs:
- Prompt compilation: Turn the user’s settings and current market/portfolio info into a clear brief the model reads each turn.
- Typed controls: The sliders and strategy priorities guided behavior without letting vague text dominate.
- Policy validation: Every model action (buy/sell/observe) had to pass checks (like max trade size, slippage limits, balance checks) before being sent to the chain.
- Execution guards: Least‑privilege contract roles and hard limits prevented risky or invalid operations.
- Memory design: Keep recent, structured state (portfolio, last actions), not a giant, fuzzy memory that can cause confusion.
- Full trace logging: Save the entire path—user settings, compiled prompt, model reasoning, tool call, validation result, portfolio snapshot, and final settlement.
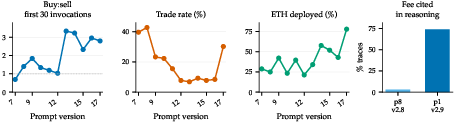
Before launch, they ran many tests and made small, targeted changes (moving one sentence, removing a number, tightening a rule) based on how agents behaved over multiple turns. They also replayed 3,000 scenarios to compare prompt versions under the same conditions.
Key technical terms, simply explained:
- ETH: Cryptocurrency used in the experiment.
- Uniswap V4 on Base: A place and protocol where tokens are swapped; Base is the network.
- Slippage: Price changes during a trade; too much can make a trade unsafe.
- Settlement: When a transaction is finally executed and recorded onchain.
- Tool call: The AI’s action per turn: buy, sell, or observe (watch without trading).
Main Findings and Why They Matter
Here are the most important results and fixes, explained plainly:
- Invented rules (fixed): Agents sometimes made up official‑sounding rules like “Hierarchy Rule #2” and used them to sell. Removing law‑like wording and telling the AI that past decisions are context (not legal precedent) cut fabricated sell rules from 57% to 3%. This matters because fake rules cause bad trades.
- Fee paralysis (fixed): When the prompt shouted about fees first (2.3% per trade), agents got scared and refused to trade—even when tokens often move 10–50% daily. Moving fee info later in the prompt, and framing it against typical move sizes, reduced fee‑led “do nothing” decisions from 32.5% to under 10%. This matters because over‑fear of fees can miss real opportunities.
- Misreading tokenomics (fixed): One token (DOGPANTS) had a special rule: even if its price crashed during a “reap” event, holders got compensated. Agents saw the crash and panic‑sold. Adding clear, structured tokenomics info (what happens and in what order) made agents behave smarter and increased capital deployment in the affected group from 42.9% to 78.0%. This matters because special payout rules can flip what looks “bad” into “okay” or even “good.”
- Numbers becoming hard rules (fixed): Soft guidance like “observe until X%” turned into strict targets, flipping intended slider behavior (more active users traded less!). Removing exact percentage floors and using comparative, state‑aware language restored the right gradient (more activity really meant more trading). This matters because too‑precise numbers can mislead.
- Cadence trading (reduced): Agents used time since last trade (“6 ticks ago”) as a signal. That led to robot‑like rhythm trading. Banning fixed cadence and filtering repeated memory entries reduced this. This matters because time‑based habits can be silly and costly.
Beyond fixes, the live run showed:
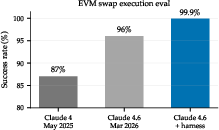
- Reliability from the operating layer: For valid submitted transactions, settlement success reached 99.9%. Upgrading the model improved raw ability (e.g., from ~87% to ~96% in a separate swap construction task), but the operating‑layer checks and guards pushed it to ~99.9%. This matters because safety systems close the last reliability gap.
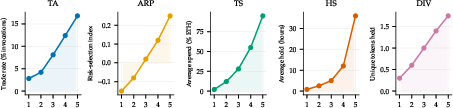
- Sliders worked in production: Users’ five sliders produced ordered behavior. For example, Trade Size clearly mapped to how much ETH got spent (from ~2% at low to ~95% at high), and Trading Activity changed how often agents traded (about 6× difference across settings). This matters because structured, checkable inputs beat vague instructions.
- Herding and two‑sided flow: Agents sometimes piled into the same token around the same time (buy cascades or sell cascades). Still, most time windows showed both buys and sells for the same token—meaning diverse behavior existed even with one model, thanks to different user settings and positions. This matters because market‑like dynamics can emerge without agents directly talking; shared state and shared prompts are enough.
- Concrete instructions helped: Users who gave clear exit rules or parameter changes did better than those who said “please outperform.” Among users who only used sliders/strategy UI (no chat), 41% closed profitably (observational result). This matters because “specific beats vague” when turning intent into reliable behavior.
Implications and Potential Impact
- Don’t judge trading AIs by the model alone. Reliability comes from the whole operating layer: clean user controls, careful prompt design, hard safety checks, and full instruction‑to‑settlement traces.
- Evaluate the full path. Test from user intent → compiled prompt → model reasoning → validated action → onchain settlement. Many failures aren’t just “the model is dumb”—they’re about wording order, hard numbers, memory mix‑ups, and missing domain rules.
- Design memory as structured, recent state. Big open‑ended memory or random text retrieval can add confusion when markets and user settings change.
- Use traces to improve future systems. Because every action is logged with its reasons and outcomes, these records can train better agents, build targeted tests (for fees, slippage, tokenomics, name bias), and even support new reward definitions for learning.
- Make multilingual controls first‑class. Different languages can change both user behavior and model understanding. Don’t rely on after‑the‑fact translation; design for it.
Overall, this study shows that AI trading agents can handle real money more safely when surrounded by strong guardrails and clear, structured instructions. The biggest improvements came from small, careful changes to the operating layer—moving a sentence, removing a number, clarifying a payout—not from swapping out the model. For real‑world finance, that’s a practical path to making autonomous agents trustworthy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide follow-up research:
- External validity beyond the bounded setting: How do the operating-layer methods perform across other chains, venues (CEX/DEX aggregates), AMM variants, order-book markets, derivatives, lending/borrowing, LP provisioning, liquidations, and cross-asset portfolios?
- Market-regime robustness: Do the same harness controls and prompt-compilation rules hold under low-volatility/low-fee markets, gas spikes, liquidity droughts, high-impact trades, or during chain congestion/reorgs?
- Fee and slippage generalization: The study used a fixed 2.3% fee and bounded slippage caps; how does behavior change with dynamic fee schedules, variable pool fees, LVR effects, and endogenous price impact from agent flows?
- Comprehensive reliability metrics: Production “99.9% settlement success” excludes malformed/policy-rejected calls; what is the full end-to-end reliability from intent to onchain effect, including malformed outputs, policy rejections, retries, reverts, and partial fills?
- Profitability and risk evaluation: The paper avoids formal PnL claims; what are risk-adjusted returns (e.g., drawdowns, volatility, tail risk), turnover, capacity limits, and stability under longer horizons and out-of-sample periods?
- Causal attribution in production: Pre-launch replays support targeted fixes, but production results are observational; can randomized, concurrent A/B deployments isolate the causal impact of specific harness edits or UI changes in live markets?
- Herding and systemic-effects analysis: What fraction of cascades is attributable to shared prompt structure versus shared state, polling cadence, or model homogeneity; which interventions (staggered polling, noise injection, mandate diversification) reliably reduce harmful synchronization?
- Polling cadence and scheduling bias: How do invocation ordering, tick frequency, and scheduler policies influence cadence-trading artifacts, execution priority, and fairness across agents?
- Multilingual effects: Chinese vs. English strategy differences were observational; do language-model-native advantages, translation artifacts, or distinct user behaviors drive performance gaps, and how should multilingual controls be designed and tested?
- Strategy-UI vs. chat efficacy: Concrete instructions correlated with better outcomes, but not causally; what controlled UX experiments (randomized prompts, strategy templates, validation nudges) most reliably improve mandate quality and downstream behavior?
- Tokenomics reasoning generalization: The DOGPANTS reap fix was specific; how can tokenomics be systematized (onchain schema ingestion, canonical sources, state variables) to handle rebases, reflections, vesting cliffs, bonding curves, emissions, fee-on-transfer tokens, or vault mechanics?
- Memory design ablations: The paper discourages open-ended RAG in this setting; what ablations across memory horizons, retrieval scoring, state-only memory, and provenance filters quantify the hallucination vs. recall trade-off under nonstationary markets?
- Mechanistic confidence gating: Early internal signals are mentioned but not evaluated; can activation-level detectors or uncertainty estimates proactively block low-confidence or confused actions before tool execution?
- LLM-judge dependence: Reasoning-trace labels use Sonnet 4.5; what is the inter-rater reliability vs. human labels, model-judge bias across languages, and the impact of judge drift on diagnostics and metric stability?
- Cross-model harness transfer: Limited internal tests suggest transfer; how robust are the operating-layer gains across diverse architectures, quantizations, and serving stacks, and where do model-specific idiosyncrasies break the template?
- Adversarial market robustness: How do agents behave under MEV/sandwich attacks, honeypots, rug pulls, oracle manipulation, spoofing, wash trading, or toxic flow; what execution guards or monitoring reduce exploitability?
- Data/IO attack surface: Can prompt injection or data poisoning arise via onchain metadata, indexer inputs, or strategy text; what sanitization, source attestation, or schema validation mitigates these risks?
- Formal guarantees on safety constraints: Beyond empirical guards, can the operating layer be specified and verified (e.g., model-checked state machines) to ensure invariant properties like max exposure, slippage, and spend limits under all failure modes?
- Reward design and RL safety: The paper proposes GRPO-like directions but does not implement them; how can rewards from verifiable execution be defined without Goodharting, and how is safe exploration enforced with real capital?
- Latency and cost-performance trade-offs: How do serving latency, context length, and token budgets affect execution quality and market impact; what are optimal inference budgets per decision under cost constraints?
- Expanded action surface: How do findings change when agents can place limit orders, provide/withdraw liquidity, manage collateral/borrows, or route across venues via SOR, with complex pre-trade checks and asynchronous fills?
- Drift detection and adaptation: What mechanisms detect nonstationarity in user mandates or market regimes and adapt prompts, guards, or memory without reintroducing instability or overfitting?
- User-governance interactions: How do pause, emergency liquidation, or mid-run setting changes interact with agent state and memory, and what policies prevent oscillations or contradictory mandates?
- Privacy and observability trade-offs: Instruction-to-settlement traces aid research but expose sensitive user intent; what de-identification or differential-privacy methods preserve utility while protecting users?
- Failure-mode coverage: The five reported modes are important but not exhaustive; what systematic red-teaming uncovers additional market-specific failures (e.g., unit errors, stale-state trading, symbol confusion, time-zone mishandling)?
- Capacity and market impact: With many agents acting, what is the marginal capacity before self-impact dominates, and how should the harness account for estimated impact in sizing/entry decisions?
- Scheduling fairness in multi-tenant serving: Do some agents gain timing advantages due to serving queue dynamics; how can fairness or randomization prevent systematic edge?
- Reproducibility and data release: Which components of the instruction-to-settlement dataset (prompts, actions, outcomes) can be released to enable independent replication while respecting user privacy and platform constraints?
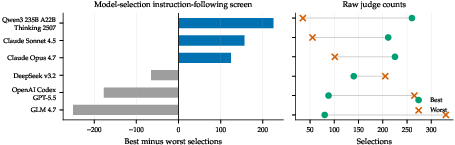
- Model selection methodology: The internal model-choice screen is not a benchmark; what standardized, execution-grounded benchmarks should drive model selection for financial agents?
- Edge-case onchain reliability: How resilient is the system to indexer delays, partial state reads, RPC inconsistencies, chain reorgs, or reverted internal calls, and what fallback/hedging logic is needed?
- Explainability to end users: Traces are logged, but how should they be surfaced to non-expert users to improve trust and oversight, and does surfacing explanations measurably reduce harmful interventions or misconfigurations?
- Environmental and operational costs: The deployment consumed ~70B tokens; what is the compute, energy, and monetary cost per unit of execution reliability, and how can efficiency be improved without degrading safety?
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed with current tools and practices, derived from the paper’s operating-layer methods, failure analyses, and trace design.
Finance and Web3
- Guardrailed onchain trading agents for retail and pro users
- What: Deploy vault-based agents with typed tool calls (buy/sell/observe), offchain policy validation, least‑privilege execution (e.g., swap-only), max trade size/slippage gates, and 99.9% settlement reliability.
- Where: DeFi trading apps, agentized wallets, crypto brokerages.
- Tools/workflows: Prompt compiler with skip-gates; policy validator; execution guards; onchain vault contracts; per-invocation instruction-to-settlement logs.
- Assumptions/dependencies: Bounded token universe or allowlists; reliable chain indexers; compliant custody; model with adequate instruction following; explicit slippage/fee configs.
- Slider-driven strategy UIs with onchain configuration
- What: Five-slider control surface (Trading Activity, Asset Risk, Trade Size, Holding Style, Diversification) plus priority/expiry strategies compiled into prompts, with backend hard caps independent of the model.
- Where: Consumer robo-trading interfaces; copy-trading platforms.
- Tools/workflows: Onchain config contracts; compiler that enforces precedence (e.g., strategy overrides before pacing); multilingual rendering.
- Assumptions/dependencies: Clear mapping from sliders to tool parameters; backend caps enforced outside model; UX and legal review.
- Pre-launch harness testing and failure-mode reduction
- What: Scenario replays across a slider grid; trace labeling for “fee paralysis,” “rule fabrication,” “number hardening,” and “cadence trading”; prompt fixes (e.g., demote precedent, de-emphasize numbers, structure tokenomics).
- Where: QA for any capital-managing agent before go-live.
- Tools/workflows: Replay simulator; trace classifier; fee-salience probes; A/B prompts with frozen state.
- Assumptions/dependencies: Access to historical market snapshots; stable serving stack; test cohort diversity.
- Instruction-to-settlement observability and audit
- What: Per-turn linkage from user mandate → compiled prompt → reasoning → tool call → validation → settlement, enabling attribution and support.
- Where: Compliance, customer support, RCA for trading platforms and custodians.
- Tools/workflows: Append-only logs; prompt/template hashes; dashboards (e.g., Dune) for onchain view.
- Assumptions/dependencies: Storage and PII policies; legal acceptance of logs as audit artifacts.
- Cascade/attention monitoring and throttles
- What: Detect herding (e.g., 10+ sells within 10 minutes) and apply soft controls (cooldowns, spend caps, adaptive fees).
- Where: Risk desks at exchanges, agent markets, and AMMs.
- Tools/workflows: Real-time cascade detectors; configurable throttles tied to policy layer.
- Assumptions/dependencies: Agreed thresholds; latency-tolerant guardrails; user disclosure.
- Multilingual control surfaces as first-class inputs
- What: Preserve language in strategies (e.g., CN/EN) rather than post-translation; compile prompts using model-strength languages.
- Where: Global agent platforms; regional brokerages.
- Tools/workflows: Language-aware prompt compilation; per-language UX testing.
- Assumptions/dependencies: Model language strengths; consistent semantics across locales.
Software and Tooling
- Agent harness SDK for real-capital tools
- What: A library offering typed action schemas, validation policies, retry rules, slippage/fee accounting, and template compilers (SGLang compatible).
- Where: Agent platforms, fintech engineering teams.
- Tools/workflows: Policy DSL; execution simulator; envelope tests; CI integration.
- Assumptions/dependencies: Compatibility with major model providers; adapter layers for CEX/DEX APIs.
- Memory manager for volatile domains
- What: Structured, recent, source-labeled state instead of open-ended RAG to reduce hallucinations in changing markets.
- Where: Trading, news-driven alerting, sports-betting agents.
- Tools/workflows: Recency windows; provenance tags; eviction policies.
- Assumptions/dependencies: Accurate state indexers; clear memory budget.
- Strategy consistency checker in the UI
- What: Pre-execution linting for contradictory directives (e.g., “permanent hold” + short holding slider).
- Where: Agent configuration flows.
- Tools/workflows: Rule-based constraints; interactive prompts for missing risk bounds or universes.
- Assumptions/dependencies: Defined semantic schema for user mandates.
Academia and Evaluation
- Execution-centric benchmarks and datasets
- What: Release of instruction-to-settlement traces to study reading-order effects, fee salience, and interface-induced failure modes.
- Where: AI+Finance research, HCI for agents.
- Tools/workflows: Label pipelines for reasoning; reproducible replays; bias tests (e.g., MEMEbench-style ticker rotation).
- Assumptions/dependencies: Anonymization; chain data licensing; IRB guidance where needed.
Policy and Governance
- Voluntary auditability standards for agentized finance
- What: Encourage “instruction-to-execution trace” retention, least-privilege operator roles, and pre-submission validation.
- Where: DeFi protocols, agent marketplaces, custodians.
- Tools/workflows: Minimal standard schema for logs; third-party attestations.
- Assumptions/dependencies: Industry buy-in; privacy and retention policies.
Daily Life
- Personal “guardrailed autopilot” for small portfolios
- What: Users set sliders and simple strategies (e.g., DCA, rebalancing bands); agent executes with hard caps and fee-aware pacing.
- Where: Consumer investing apps; play-money or limited-risk vaults.
- Tools/workflows: Spend caps; automatic cooldowns; exploit-proof validation.
- Assumptions/dependencies: Regulatory constraints on advice; suitability checks; disclosure of risks and fees.
Long-Term Applications
These require further research, scaling, or regulatory development to be feasible or safe.
Finance and Markets
- Cross-asset and cross-venue generalization (DeFi ↔ CeFi ↔ TradFi)
- What: Extend the harness to equities, FX, futures with limit/stop/IOC orders, borrow/short, and multi-venue routing.
- Potential products: Agentized brokers; “slider-first” discretionary PM tools; fund ops copilots.
- Dependencies: Broker APIs; smart-order routers; market impact models; KYC/AML; exchange certifications.
- Learning from execution: RL with verifiable outcomes
- What: Use instruction-to-settlement traces for offline RL (e.g., GRPO variants) that reward validated, profitable, and compliant actions.
- Potential products: Adaptive risk budgets; dynamic pacing; model self-calibration.
- Dependencies: Reward shaping that penalizes costs/risks; safety constraints; non-stationarity handling.
- Herding-aware market design
- What: Mechanisms (adaptive fees, crowding indicators, per-agent cool-downs) that mitigate cascades while preserving liquidity.
- Potential products: Agent-friendly AMMs and auctions; anti-snowball governance.
- Dependencies: Mechanism design studies; user consent; onchain governance.
- Proactive confusion detection via interpretability
- What: Runtime monitors using reasoning + activation signals to block low-confidence or invalid actions before submission.
- Potential products: “Safety sentinel” for agents; confidence-gated execution.
- Dependencies: Reliable online interpretability metrics; latency budgets; false positive control.
Software Platforms
- General-purpose “Agent OS” for real-world tool use
- What: A cross-domain operating layer with typed tools, validators, policy DSLs, and instruction-to-outcome traces applicable to finance, procurement, IT ops, and beyond.
- Potential products: Managed agent runtimes with policy packs per domain.
- Dependencies: Tool adapter ecosystem; security sandboxing; governance APIs.
- Multi-agent replay and stress-test environments
- What: Scalable simulators that reconstruct portfolios, strategies, and market states for adversarial and systemic risk testing.
- Potential products: “Chaos engineering” for agent markets; red-team labs.
- Dependencies: High-fidelity market models; reproducibility; computational cost.
Healthcare and Safety-Critical Domains
- Guardrailed clinical decision support agents
- What: Typed orders (labs, meds) with pre-execution validation, slider-like policy constraints (risk, dosage bounds), and instruction-to-outcome audit trails.
- Potential products: Co-pilot for care teams; order set assistants.
- Dependencies: FDA/IRB approvals; EHR integration; rigorous safety validation; human-in-the-loop enforcement.
Robotics and Energy
- Agent operating-layer patterns for embodied control
- What: Typed action surfaces, policy gates, and reasoning logs for robots and industrial control; structured recent-state memory instead of open-ended RAG.
- Potential products: Factory or warehouse agent supervisors; grid dispatch copilots.
- Dependencies: Real-time guarantees; formal safety cases; certification.
Academia and Public Interest
- Standardized “Instruction-to-Execution Trace” schema and certification
- What: Community standards for storing/validating agent actions and provenance for auditors and researchers.
- Potential products: Open datasets; certification programs for capital-managing agents.
- Dependencies: Consortium governance; privacy-preserving schemas; legal frameworks.
Daily Life and Consumer Automation
- Home and enterprise automation with slider-first strategies and validators
- What: Energy management, device scheduling, or procurement agents with typed actions, safety caps, and auditable traces.
- Potential products: Smart-home or SMB ops copilots.
- Dependencies: Device APIs; cost models; consent and override controls.
Notes on feasibility assumptions and dependencies across applications:
- Reliance on an operating layer (prompt compiler, validators, guards, traces) is central; results are not model-only.
- Transferability beyond bounded token arenas and high-fee settings requires adaptation and testing.
- Regulatory and compliance requirements (disclosures, KYC/AML, audit) may constrain deployment in consumer finance and healthcare.
- Multilingual support should be evaluated as a first-class harness input; outcomes can vary by language and model strengths.
- Observed herding/cascades imply the need for systemic risk controls when scaling agent populations.
Glossary
- Activated parameters: The subset of a sparse model’s weights that are actively used during inference. "22B activated parameters"
- Agent harness: The standardized runtime wrapper around the model that compiles prompts, validates actions, and guards execution. "shared agent harness"
- Agent invocations: Scheduled polling cycles in which the agent processes context and produces exactly one tool call. "7.5M agent invocations"
- Allowlist (token-pair allowlist): A predefined set of permitted trading pairs; actions outside it are rejected. "token-pair allowlists"
- Attention cascades: Rapid, self-reinforcing waves of agent attention and trading triggered by shared signals. "Attention cascades resembled ordinary speculative-market dynamics."
- Basis-point cap: A limit expressed in basis points (1/100th of a percent) applied to parameters like max trade size. "basis-point cap"
- Base (L2 blockchain): The specific blockchain network on which the event ran and trades settled. "on Base"
- Cadence trading: A failure mode where agents trade on fixed time intervals or ticks rather than market signals. "Cadence trading"
- Chain outcome: The final onchain result of a proposed action after validation and settlement. "chain outcome"
- Cold-start metric: A diagnostic focusing on behavior just after activation to detect underdeployment. "cold-start metric"
- Control surface: The user-facing configuration interface (e.g., sliders, strategy text) that shapes agent behavior. "user control surface"
- DEX: A decentralized exchange where swaps are executed without centralized intermediaries. "EVM DEX swap"
- EVM: The Ethereum Virtual Machine, the execution environment for smart contracts. "Internal EVM DEX swap execution evaluation."
- Execution guards: Backend checks that prevent invalid or risky actions from reaching the chain. "execution guards"
- Fee paralysis: Inaction driven by overemphasis on fees at the expense of opportunity. "Fee paralysis"
- Group Relative Policy Optimization: A reinforcement learning approach suggested for future training using verifiable outcomes. "Group Relative Policy Optimization"
- Herding: Many agents taking similar actions due to shared signals or prompts, leading to correlated behavior. "correlated herding"
- Instruction-to-settlement trace: A linked record from user mandate through prompt, tool call, validation, and settlement. "instruction-to-settlement trace"
- Least-privilege operator role: A restricted role that permits only necessary actions (e.g., swaps) and forbids others (e.g., withdrawals). "least-privilege operator role"
- Liquidity provider (LP) fee: The fee paid to liquidity providers on each swap in a pool. "0.3\% LP fee"
- Mechanistic interpretability: Analysis of internal model representations to understand decision factors. "mechanistic interpretability work on DX-format trading prompts"
- Memecoin: A speculative token with meme-centric branding and volatile dynamics. "12 memecoin tokens"
- Market indexer: A component that aggregates and serves market data to the agent runtime. "market indexer"
- Market tape: The stream of market activity (prices, volumes) that agents read and react to. "market tape"
- Nonstationarity: The property of data distributions changing over time, complicating backtests and modeling. "nonstationarity"
- Numeric anchoring: A failure mode where the model overweights specific numbers from the prompt as hard rules. "numeric anchoring"
- Onchain: Occurring on a blockchain, including configuration and settlement records. "bounded onchain market"
- Policy validation: Checks that ensure proposed actions conform to predefined rules before submission. "policy validation"
- Power-law failure curve: A distribution where many tokens fail quickly and few dominate, following a power law. "power-law failure curve"
- Pro-rata compensation: Payouts distributed proportionally to holders’ stakes. "pro-rata compensation"
- Prompt compilation: Constructing the model’s input from user controls, strategies, and current state. "prompt compilation"
- RAG-style retrieval: Retrieval-augmented generation that injects external text into context, here found risky for drifting states. "RAG-style retrieval"
- ReAct-style thought/action/observation traces: An agent prompting pattern that alternates reasoning, actions, and observations. "ReAct-style thought/action/observation traces"
- Retry rules: Policies that govern when and how the system retries failed or low-confidence operations. "retry rules"
- Sell cascades: Clusters of rapid, coordinated sell actions across many agents. "sell cascades"
- Settlement success: The rate at which valid, policy-passing transactions are successfully settled onchain. "settlement success"
- SGLang: A high-performance LLM serving framework used for production inference. "SGLang"
- Slippage bounds: Limits on acceptable price movement between order creation and execution. "slippage bounds"
- Slippage tolerance: The maximum acceptable percentage deviation from the expected execution price. "slippage tolerance"
- slippageBps: Slippage settings specified in basis points for execution constraints. "slippageBps"
- Sparse model: A model architecture where only a subset of parameters are activated per token. "sparse model"
- State grounding: Ensuring model decisions are anchored in current, structured environment and portfolio state. "state grounding"
- swapV4: The Uniswap V4 swap function the operator could call to execute trades. "swapV4"
- Tokenomics: The economic design and mechanics of a token that determine payoffs. "tokenomics"
- Two-sided flow: Simultaneous buy and sell activity in the same token window across agents. "two-sided flow"
- Typed action surfaces: Structured, constrained tool-call schemas that limit and shape permissible actions. "typed action surfaces"
- Typed controls: Structured inputs like sliders that guide behavior more reliably than free-form text. "typed controls"
- Uniswap V4: The fourth version of the Uniswap protocol, providing the pool mechanics used in the study. "Uniswap V4"
- Vault: An onchain contract that holds user funds and serves as the agent’s execution surface. "Each vault held user ETH."
- Thinking-mode-only operation: A model setting emphasizing explicit reasoning during inference. "thinking-mode-only operation"
Collections
Sign up for free to add this paper to one or more collections.