- The paper introduces NF-NPCDR, which integrates neural processes with normalizing flows to overcome unimodal limitations and model multi-interest user preferences.
- It employs a learnable preference pool and adaptive FiLM-based decoding to jointly capture individual and communal user interests.
- Empirical results demonstrate significant MAE and RMSE improvements over state-of-the-art methods, confirming its robustness in cold‐start scenarios.
Personalized Multi-Interest Modeling for Cross-Domain Recommendation to Cold-Start Users
Introduction and Motivation
The persistent cold-start problem in recommendation systems has motivated intensive research into cross-domain recommendation (CDR) techniques, which leverage user-item interactions from an auxiliary domain to mitigate data sparsity in a target domain. Common CDR approaches based on Embedding and Mapping (EMCDR) learn user-shared mappings, thereby overlooking user-specific interests. Meta-learning-based CDR approaches learn user-specific mappings but ignore latent common preferences shared by users and generally fail to model multi-interest phenomena, collapsing user preference into simplistic unimodal representations.
The paper "Personalized Multi-Interest Modeling for Cross-Domain Recommendation to Cold-Start Users" (2604.25732) introduces a comprehensive framework, NF-NPCDR, that leverages neural processes (NP) augmented by normalizing flows (NF) to capture personalized multi-modal user preferences as well as underlying communalities between users. A preference pool captures shared latent preferences, while a stochastic adaptive decoder jointly modulates personal and shared preferences, addressing cold-start recommendation at a new level of granularity.
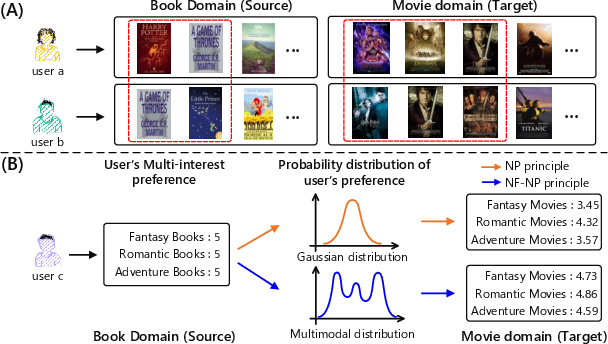
Figure 1: (A) User-user common preference structures and (B) illustrations contrasting standard NP with the richer expressivity enabled by normalizing flows for multi-modal preference modeling.
Methodological Framework
Neural Process–Normalizing Flow Integration
Neural processes model preference uncertainty by mapping observed support sets (source domain interactions) to stochastic latent variables encoding user preference, typically leading to unimodal Gaussian approximations. However, user interests in reality exhibit multi-modality. NF-NPCDR augments the representational capacity of NPs using normalizing flows, which transform unimodal latent distributions into expressive multimodal ones, thereby encoding heterogeneous user interests.
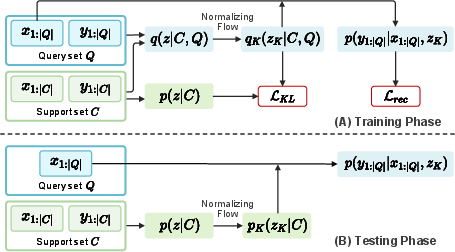
Figure 2: The NF-NP principle during training and test phases: normalizing flows transform the latent NP posterior to multimodal distributions, improving support-query transfer.
Modeling Common Preferences via Preference Pool
NF-NPCDR introduces a preference pool—comprising N soft cluster centroids—that serves as a learnable, unsupervised set of anchors for modeling common user preferences. Each user's elementary preference embedding, derived from their support set, is soft-assigned to this pool using a Student's t-distribution-based similarity metric. The resulting hybrid representation incorporates both individual (personalized) and community (common) signals.
Stochastic Adaptive Decoding
A FiLM-inspired stochastic adaptive decoder ingests the user’s personalized multimodal latent (zi,K) along with their common latent (hi) and target item encoding. It adaptively modulates decoding parameters on a per-user basis, predicts ratings on candidate items in the target domain, and aggregates the contribution of personal and shared interests efficiently.
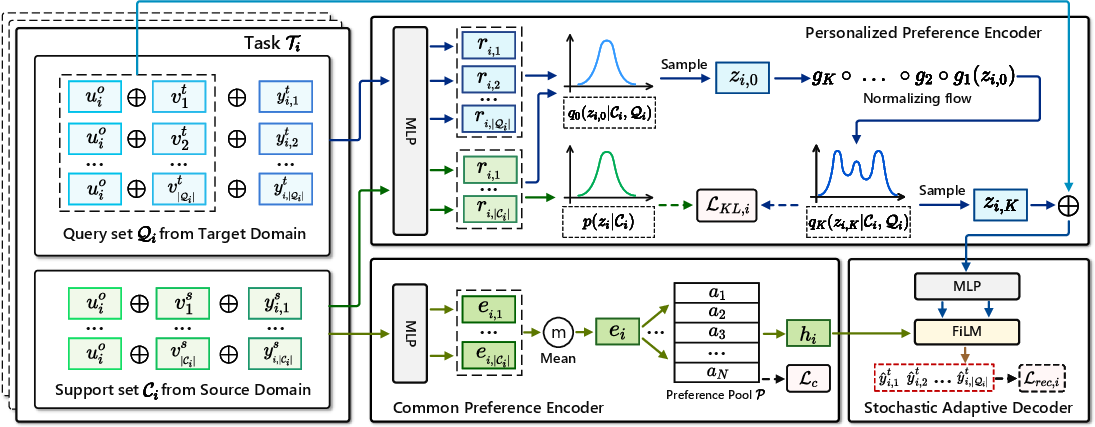
Figure 3: NF-NPCDR architecture—personalized preference encoder (NP+NF), preference pool, and stochastic adaptive decoder.
Empirical Results and Analysis
Comprehensive evaluation on large-scale Amazon and Douban datasets benchmarks NF-NPCDR against 11 representative CDR models. NF-NPCDR achieves substantial and consistent improvements:
- In Amazon CDR scenarios, MAE improvement over prior state-of-the-art (CDRNP) ranges from 44%–50%, and RMSE improvement is typically >20%.
- Douban scenarios yield MAE improvements of 38%–50%.
These gains persist across varying proportions of cold-start users, demonstrating the model’s robustness and generalizability.
Ablation Studies
Component-wise ablation highlights the indispensability of each element in the architecture:
- Removing the normalizing flow (NF) degrades MAE by up to 7.6%, confirming the criticality of multi-modal preference modeling.
- Omission of the preference pool notably increases error, demonstrating the benefit of leveraging common preference anchors.
- Removal of the FiLM-based modulation reduces the system’s adaptability and accuracy.
Multimodal Representation and User Studies
NF-NPCDR displays higher latent entropy than baseline NPs—direct evidence of richer, multi-modal modeling—across various support set lengths.
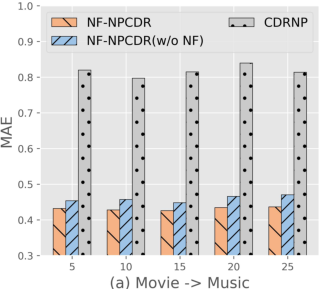
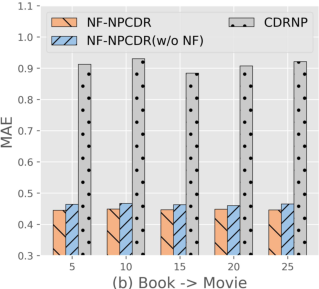
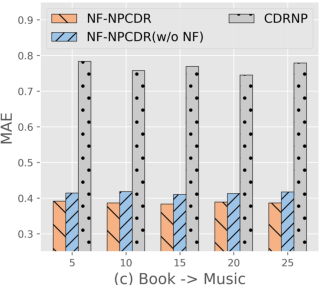
Figure 4: NF-NPCDR maintains lower MAE, regardless of support set size, compared to unimodal and prior multi-task variants.
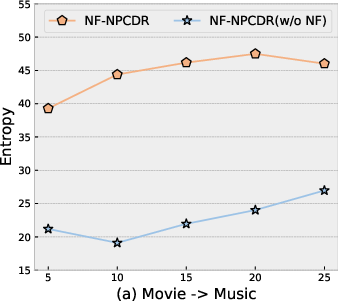
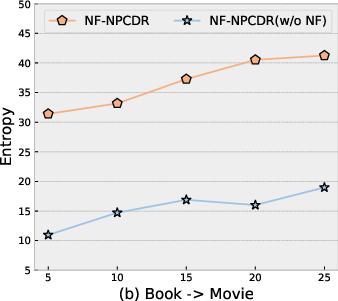
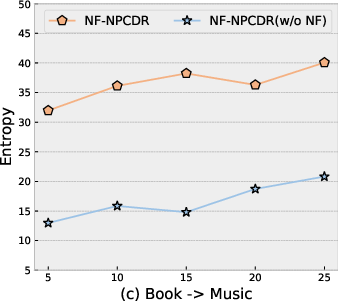
Figure 5: Entropy of latent variable z is highest in the full NF-NPCDR, confirming enhanced multi-interest capacity.
Case studies demonstrate improved recommendation coverage across a user’s distinct interest clusters, where previous state-of-the-art models return unimodal, “majority-interest-only” suggestions.
Common Preference Visualization
Soft cluster assignment heatmaps validate the preference pool’s ability to discover and model latent user communities: users interacting with similar items share high cluster assignment probability, while distinct users diverge across the preference pool anchors.
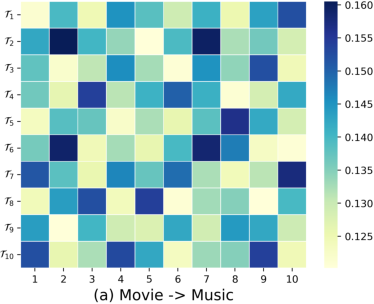
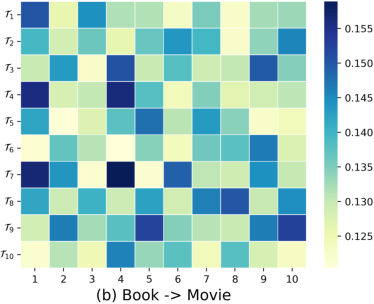
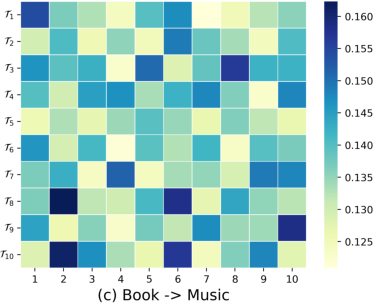
Figure 6: Users sharing community clusters, as revealed by the preference pool, encode common interests not apparent from individual support sets alone.
Computational Cost and Flow Sensitivity
NF-NPCDR retains competitive training time and parameter efficiency. While normalizing flows increase training time compared to pure NP-based models, improved performance–cost tradeoff is obtained with shallow flows (Planar, K=4–$6$). Deeper flows or more complex flow variants bring diminishing returns and increased overfitting risk.
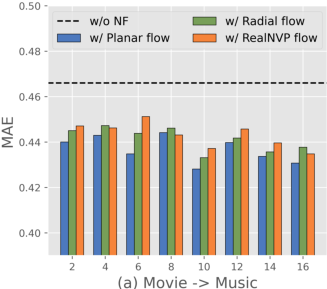
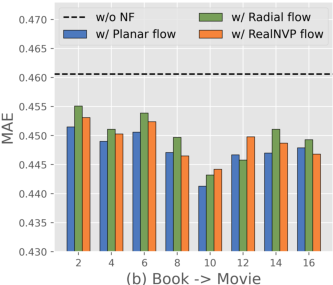
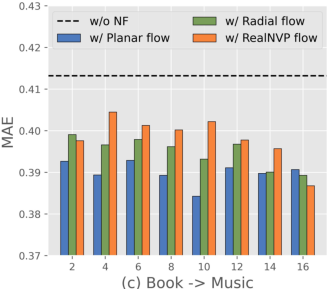
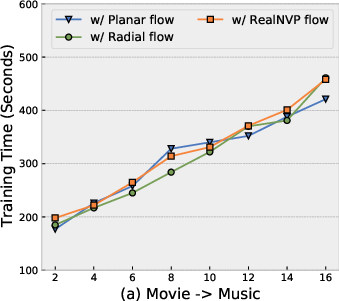
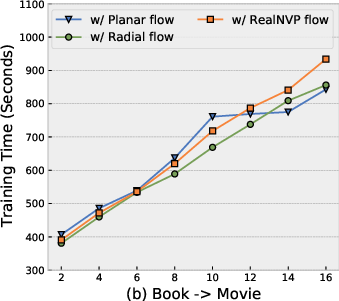
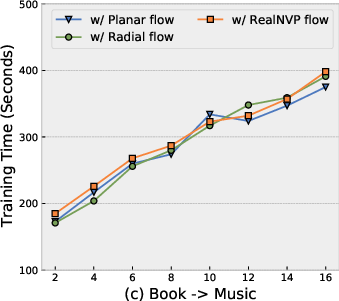
Figure 7: Training time remains practical for Planar flows at moderate depth, with optimal MAE at K=4–$6$.
Hyperparameter Robustness
NF-NPCDR exhibits mild sensitivity to the preference pool size (N) and the loss balance factor (zi,K0), maintaining performance over a broad parameter range in both dense and sparse interaction regimes.
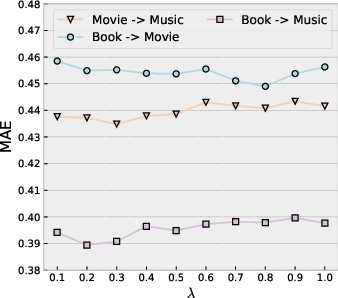
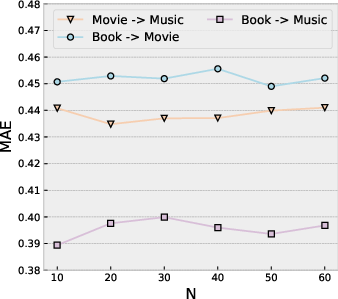
Figure 8: MAE varies minimally across wide spans of zi,K1 (preference pool loss weight) and zi,K2 (pool cardinality) on dense Amazon scenarios.
Implications and Forward-Looking Perspectives
This work demonstrates the benefit of augmenting stochastic process-based preference modeling with normalizing flows to capture multi-interest user profiles for CDR tasks. The introduction of a trainable preference pool reveals generalizable community structure and commonality, relevant for regularized adaptation in user-sparse cold-start regimes. The established superiority in both dense and sparse settings, together with practical computational demands, supports adoption in industrial-scale, rapid-onboarding recommendation deployments.
Further directions include dynamically learning the preference pool cardinality, integrating side information as auxiliary signals, leveraging context-aware flows for sequential recommendation, and extending the framework to multidomain and heterogeneous interaction graphs.
Conclusion
NF-NPCDR advances cross-domain recommendation for cold-start users by unifying neural processes with normalizing flows for personalized, multimodal, and community-aware preference modeling. Extensive experimental evidence demonstrates the approach’s superior accuracy, robustness to data sparsity, and computational practicality, establishing a new benchmark for CDR architectures targeting realistic cold-start deployment scenarios.