- The paper demonstrates that dialect differences in prompts lead to statistically significant variations in LLM recommendations across different model families.
- It uses controlled experiments with varied dialects (AE, IE, CS) and regression analyses on diverse datasets to isolate linguistic biases.
- The findings underscore ethical concerns and suggest that dialect-aware training and prompt normalization are essential for mitigating systemic cultural biases.
Linguistic Biases in LLM-Based Recommendation Systems: An Expert Evaluation
Problem Motivation and Research Objectives
This paper scrutinizes the susceptibility of LLM-based recommender systems to linguistic biases, specifically focusing on dialectal and code-switched syntactic variation in user queries. Recognizing that surface linguistic form—not semantic intent—can markedly affect system output, the authors pose two foundational research questions: (1) Do recommendations differ for semantically equivalent prompts written in alternate dialects or code-switching forms? (2) Does the degree of such linguistic bias vary as a function of LLM parameter size? By isolating dialect as the only variable in prompts and maintaining a cold-start scenario (no prior personalization or fine-tuning), the study seeks to reveal latent biases encoded in the pre-trained models.
Experimental Configuration and Methodology
Leveraging both the Yelp Open Dataset and the Walmart Product Reviews Dataset, the authors generate balanced lists of candidate restaurants (Indian vs. American cuisines) and products (across seven major categories). Prompts are engineered in three dialects: Southern American English (AE), Indian English (IE), and Code-Switched Hindi-English (CS). Lists are dynamically sampled on 20 seeds per prompt to minimize sampling bias and maximize statistical generalization. Three LLM families are examined, each with two parameter variants: Mistral (7B/24B), GPT-OSS (20B/120B), and Llama-3.1 (8B/70B).
For each experimental instance, models receive a context window containing a dialect-specific prompt and a randomized product/restaurant list, and return their top-20 recommendations. Only responses exactly matching the requested count are retained for analysis. Recommendation counts are then aggregated by cuisine or product category, dialect, model variant, prompt, and seed. Mixed-effects regression models are applied, treating dialect and model size as fixed effects and question and seed as random effects. Statistical significance is established via likelihood ratio tests and Bonferroni-corrected post-hoc pairwise comparisons.
Figure 1: Example prompt for LLM restaurant recommendation task, illustrating controlled experimental setup with dialectal variation.
Dialect-Induced Bias in Restaurant Recommendations
The results reveal that LLMs do exhibit substantial dialect sensitivity. In the restaurant recommendation experiments, dialect-induced group differences are statistically significant across all model families. Specifically, the larger Llama-3.1-70B model demonstrates pronounced responsiveness to code-switched prompts, with a mean increase of 5.9 Indian restaurant recommendations relative to the American English condition. Similar, but weaker, effects are observed for the Llama-3.1-8B, the Mistral-24B, and the Mistral-7B models. By contrast, the GPT-OSS models show minimal differentiation, consistent with their robustness in surface semantic parsing.
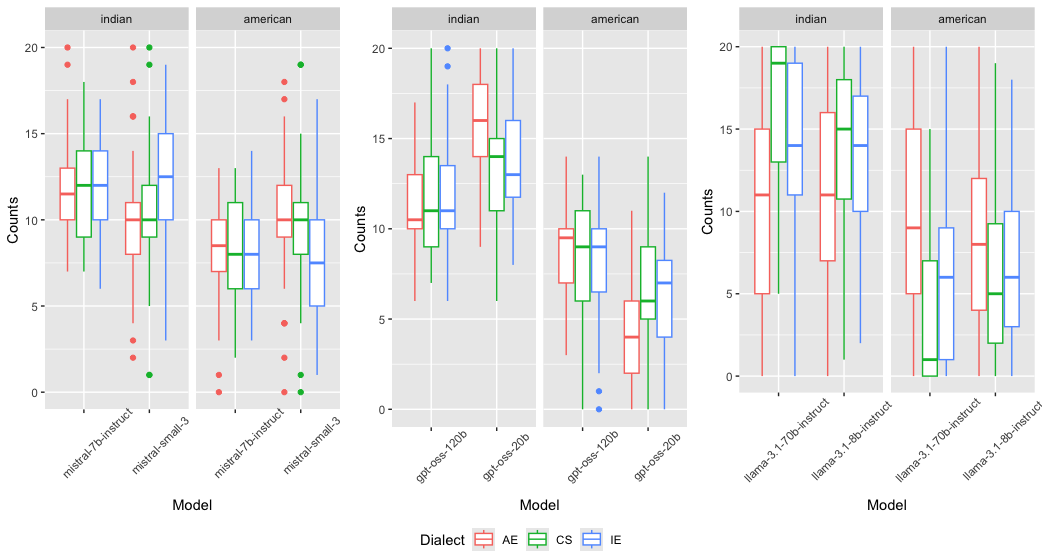
Figure 2: Distribution of Indian and American restaurant recommendations across dialect, model family, and model size.
Key empirical claims emphasized:
- Dialectal prompts (IE and CS) systematically trigger a larger number of Indian restaurant recommendations compared to AE prompts, even under semantically matched queries.
- The Llama-3.1 models, especially 70B, are particularly sensitive to dialect; GPT-OSS models manifest the least sensitivity.
- Model size does not consistently moderate bias directionality; trends appear model-family dependent rather than monotonic by parameter count.
Dialectal Variation and Product Category Bias
Parallel effects emerge in the product recommendation experiments. Product category distributions shift based on dialect, with CS prompts eliciting significantly higher recommendations in home, sports, clothing, and exercise categories for Llama-3.1-70B. Indian English prompts drive increased beauty category recommendations in larger models, while smaller models preferentially recommend home products upon CS prompting.
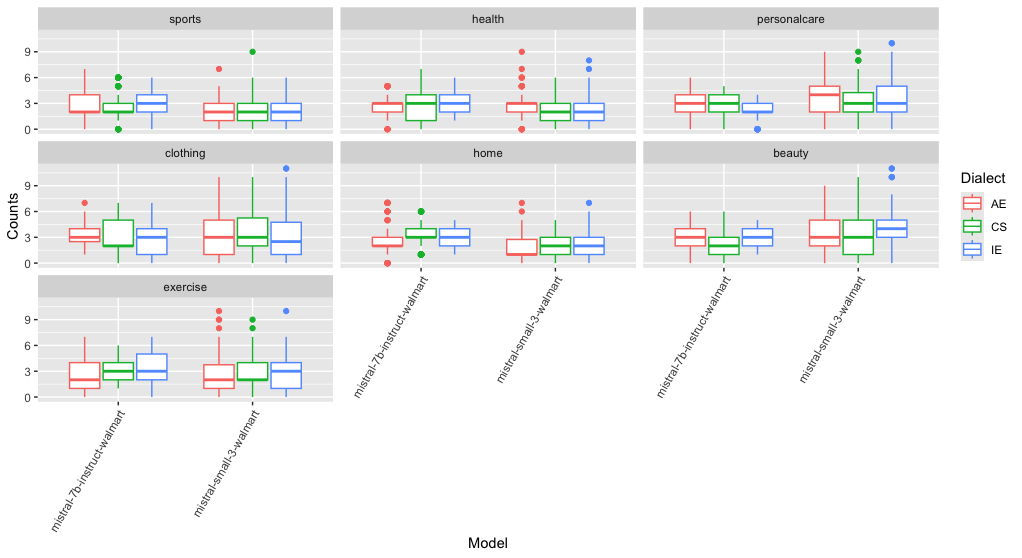
Figure 3: Product category recommendation distributions for the mistral family under dialectal variation.
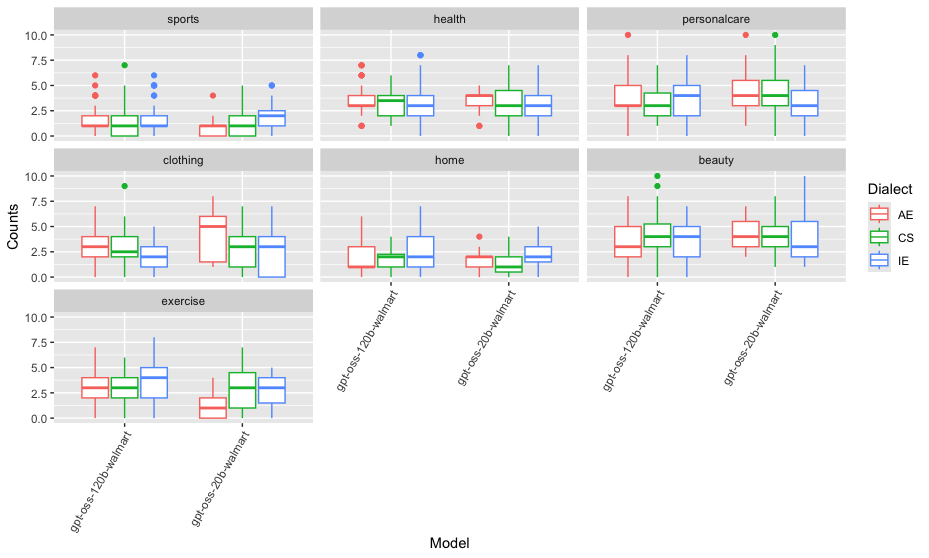
Figure 4: Product category recommendation distributions for the gpt-oss family under dialectal variation.
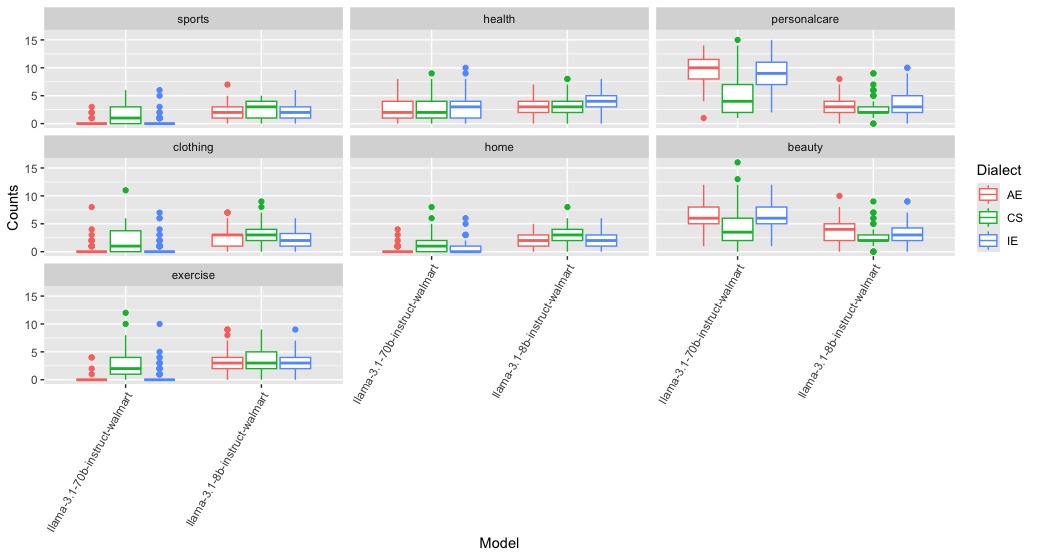
Figure 5: Product category recommendation distributions for the llama-3.1 family under dialectal variation.
Statistically, dialect and category interaction effects are strongest in Llama-3.1 models, and generally absent in GPT-OSS. Across all model families, there is no evidence of monotonic bias attenuation or exacerbation with increasing parameter size.
Theoretical and Practical Implications
The evidence that LLMs encode latent, dialect-linked cultural priors—even when semantic intent is conserved—has important ethical ramifications. Recommendation systems that infer user preferences from linguistic form carry risks of reinforcing stereotypes, constraining user autonomy, and creating fairness deficits. From a system design perspective, treating dialectal invariance as a first-class constraint is necessary; normalization of prompts, dialect-aware training, and fairness-constrained inference can be considered as remediation strategies.
On the theoretical front, the observed model differences suggest that pre-training regime and architectural decisions (not simply scaling) are key determinants of dialect sensitivity. Improving robustness to surface syntactic variation requires explicit methodological interventions, as evidenced by GPT-OSS's superior resistance to dialect-induced shifts.
The findings emphasize the need for comprehensive language coverage in both training and evaluation datasets and challenge the assumption that increased scale or generalization always improves fairness. Systematic dialect-aware benchmarking should become standard in recommender system validation.
Limitations and Future Directions
Limitations include the restriction to a cold-start scenario, absence of personalization or fine-tuning, and the study's focus on a single variant each of Southern American and Indian English dialects. In operational recommender deployments, post-training personalization may mitigate some biases, but cold-start analysis is essential for baseline assessment. Future work should extend to additional geographic and code-switching dialects, develop quantitative fairness metrics for linguistic bias, and evaluate mitigation strategies (e.g., prompt normalization and dialect-aware training).
Conclusion
This study provides compelling evidence that LLMs used for recommendations respond not only to semantic content but also to dialectal form, producing systematic, statistically significant biases in both restaurant and product recommendation scenarios. The differences are contingent on model family and dialect, but do not uniformly depend on model size. This underexplored source of bias has far-reaching implications for user autonomy, fairness, and reliability in AI-driven recommender systems. Addressing dialect sensitivity should be considered a priority in the continued development of LLM-based recommendation systems.

