- The paper introduces a novel framework for accent identification by combining voice conversion-based data augmentation with non-timbral embedding methods.
- It demonstrates that kNN-VC outperforms RVC in preserving accent cues while significantly reducing speaker identity, as evidenced by improved F1 scores and accuracy.
- The non-timbral embeddings proved effective for both robust accent identification and accent-controlled TTS, setting new benchmarks on the GenAID dataset.
Robust Accent Identification via Voice Conversion and Non-Timbral Embeddings
Introduction
The work entitled "Robust Accent Identification via Voice Conversion and Non-Timbral Embeddings" (2604.25332) addresses the longstanding challenge of reliable automatic accent identification (AID) across unseen speakers, a problem compounded by the entanglement of accentual and speaker-specific cues and the lack of balanced, large-scale, speaker-diverse datasets. By leveraging recent advancements in voice conversion (VC) as a data augmentation technique and introducing non-timbral, speaker-invariant embeddings for accent modeling, this work establishes new state-of-the-art results on the GenAID benchmark for 13-accent classification. The approach is motivated by the empirical findings that existing augmentation strategies can distort accent cues or fail to generalize to new speakers, and that adversarial or disentanglement-based representations can mitigate—but not fully eliminate—speaker-accent entanglement.
Methodology
Two primary strategies structure the research:
- Speaker Augmentation via Voice Conversion: The authors evaluate the application of two VC methods—Retrieval-based Voice Conversion (RVC) and k-Nearest Neighbors Voice Conversion (kNN-VC)—for data augmentation. Training utterances are converted into new speaker voices while maintaining the source accent, increasing both apparent speaker diversity and forcing downstream classifiers to acquire speaker-invariant, accent-relevant features.
- Specialized Non-Timbral Embeddings: Independently, the work explores representations explicitly designed to minimize timbral (speaker-specific) cues while retaining accent and prosodic information. Notably, they contrast LID (language identification) embeddings (from MMS-LID) against WNTA64 embeddings, the latter isolated from a prosody- and accent-centric layer of a pretrained model. These embeddings are input to a shared feed-forward classifier with two heads: one for accent identification, the other for adversarial speaker prediction, regularized by KL divergence, as shown in the model architecture.
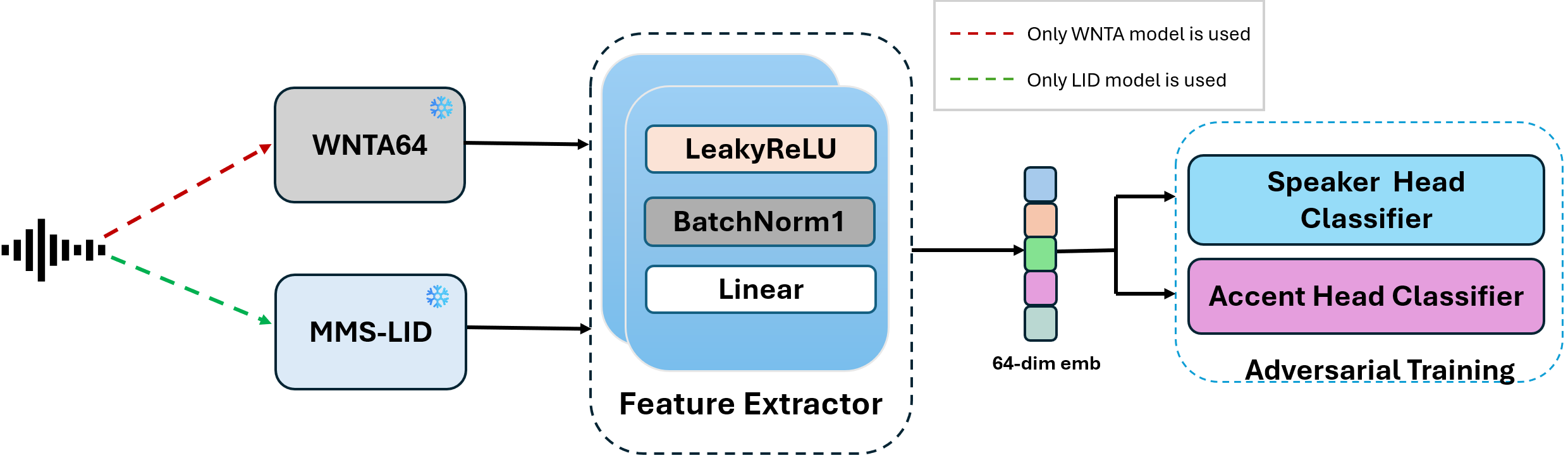
Figure 1: Architecture of the AID model, leveraging either LID or non-timbral embeddings with dual heads for accent and speaker discrimination under adversarial KL regularization.
The two strategies are complementary: VC-based augmentation enhances the diversity of the training set, targeting speaker-accent disentanglement at data level, while non-timbral embeddings structurally enforce accent-centric invariance at the representation level.
Evaluation and Results
The primary evaluation dataset is GenAID, which features a speaker-disjoint split robust to overlap between training and test subjects. Performance is measured via F1, accuracy, precision, and recall on previously unseen speakers.
Voice Conversion Analysis
Through objective scoring (cosine similarity of ECAPA-TDNN speaker embeddings for timbre shift, accent classification accuracy, and accent embedding cosine similarity [AECS] for accent preservation), it is shown that:
- Both RVC and kNN-VC systems substantially shift speaker identity in converted utterances (mean speaker similarity to source: 0.19 for RVC, 0.18 for kNN-VC), with kNN-VC achieving higher similarity to the target, signifying more precise timbre transplantation.
- Critically, accent similarities as measured by AECS remain above the threshold for preservation (>0.80), with kNN-VC yielding improved accent consistency (AECS = 0.90) versus RVC (AECS = 0.84), supporting the hypothesis that VC can decouple timbre and accentual cues without degrading accent classifiability.
- Augmenting baseline AID models with VC-generated speech (either RVC or kNN-VC) improves F1 from 0.55 to 0.60/0.65 and accuracy from 0.56 to 0.61/0.66, with kNN-VC consistently outperforming RVC, confirming the link between VC quality and accent robustness.
- Using WNTA64 non-timbral embeddings yields an F1 of 0.66 and accuracy of 0.66, outperforming both LID embeddings and the augmented and non-augmented baselines.
- The marginal benefit of further VC-based augmentation on non-timbral models is negligible, evidencing that WNTA64 embeddings already encode sufficient speaker invariance.
Accent-Controlled Text-to-Speech
The authors extend the application of non-timbral embeddings to accent-controlled TTS. In a controlled comparison between TTS systems conditioned on GenAID vs WNTA64 accent embeddings combined with WTA timbre features, accent transfer fidelity (as scored by the GenAID classifier) is consistently higher for the WNTA64-based system. For example, for the US accent, the F1 increases from 0.52 (GenAID) to 0.56 (WNTA64), with similar gains across other accents.
Discussion
The results collectively demonstrate that carefully selected VC methods, when properly assessed for accent preservation, can function as effective speaker augmentation techniques in AID, promoting generalization. More notably, non-timbral, accent-centric embeddings, particularly WNTA64, provide a structurally grounded solution that outperforms representation-agnostic augmentation.
Strong claims substantiated by the results include:
- WNTA64 embeddings enable robust AID on unseen speakers, outperforming previous methods by a substantial margin (0.66 F1 vs prior 0.55 baseline).
- VC-based augmentation is only additive for models lacking explicit accent disentanglement; once robust non-timbral embeddings are available, further speaker augmentation provides no measurable improvement.
- Accent-centric embeddings facilitate high-fidelity accent transfer in TTS beyond their recognition utility.
Implications and Future Directions
From a practical standpoint, these findings significantly impact the development of accent-agnostic speech interfaces, sociolinguistic analytics, and accent synthesis. Non-timbral embedding approaches can be seamlessly integrated into recognition and generative pipelines to enable accent control without speaker leakage, crucial for privacy and fairness. Furthermore, the demonstrated evaluation protocol centered on speaker-disjoint splits and objective accent retention metrics establishes a more rigorous assessment framework for accent technology.
Theoretically, the decoupling of accent and speaker through both data and representational means opens further research paths in unsupervised, cross-lingual, and zero-shot accent modeling. Future advancements could include the design of more sophisticated embedding architectures with finer-grained disentanglement, joint training of recognition and synthesis systems leveraging shared accent representations, and extension to under-resourced accents and languages.
Conclusion
This work evidences that state-of-the-art AID performance for unseen speakers is achievable via VC-driven data augmentation and, more effectively, through non-timbral, speaker-invariant representations. The integration of these approaches constitutes a robust framework for accent identification and controllable TTS, with broad future applications in adaptive and inclusive speech technologies.

