- The paper introduces a novel LLM framework enabling automated generation of editable, engine-native 3D cutscenes.
- It presents a multi-agent system with dynamic delegation and closed-loop multimodal feedback to ensure cinematic quality.
- A hierarchical evaluation benchmark, CutsceneBench, validates tool correctness, narrative fidelity, and spatial-temporal integrity in generated scenes.
Cutscene Agent: LLM-Driven End-to-End Automated 3D Cutscene Generation
The generation of high-fidelity, narrative-rich 3D cutscenes remains a central workflow within modern video game and interactive media production, demanding coordinated effort across multiple disciplines—screenwriting, voice acting, animation, and cinematography. Existing generative AI paradigms for cinematic content—such as diffusion video models and LLM-based planners—are limited in their professional utility because they fail to produce editable, engine-native assets. Instead, most outputs exist as flat rendered videos or static structured data such as JSON, fundamentally precluding professional iteration, engine-native manipulation, and pipeline extensibility.
Prior works on LLM-driven virtual film production (e.g., “FilmAgent” (Xu et al., 22 Jan 2025), MovieAgent, VideoDirectorGPT (Lin et al., 2023)) and generative video pipelines (“Kling” [kuaishou2024kling], Sora, etc.) do not address the “editability gap”—the disconnect between generative outputs and industry-standard, semantically structured engine assets. These approaches typically lack persistent state awareness and agent-environment bidirectionality, and do not offer engine-agnosticity or composable tool abstraction. Furthermore, evaluation of cutscene generation has remained limited to ad-hoc scenario analysis with no standard multi-dimensional agentic benchmark.
System Architecture
Cutscene Agent introduces a tightly integrated, end-to-end LLM agent framework that realizes three primary contributions:
- Cutscene Toolkit: A Model Context Protocol (MCP)-based API library for Unreal Engine, exposing the entire authoring pipeline—including modular character, camera, and asset management, and realtime scene perception—as composable, engine-agnostic tools. The toolkit is tightly decoupled from LLM prompt engineering, allowing for backend-native extension and cross-engine portability.
- Multi-Agent System: A hierarchical agent system in which a director agent orchestrates specialist subagents (handling animation, cinematography, audio) via dynamic delegation. Context awareness is achieved through automatic Level Sequence state injection, while subagent execution is sand-boxed through strict tool whitelisting. Critically, a closed-loop visual feedback mechanism leverages multimodal LLMs to iteratively refine composition and animation via perception-driven correction cycles.
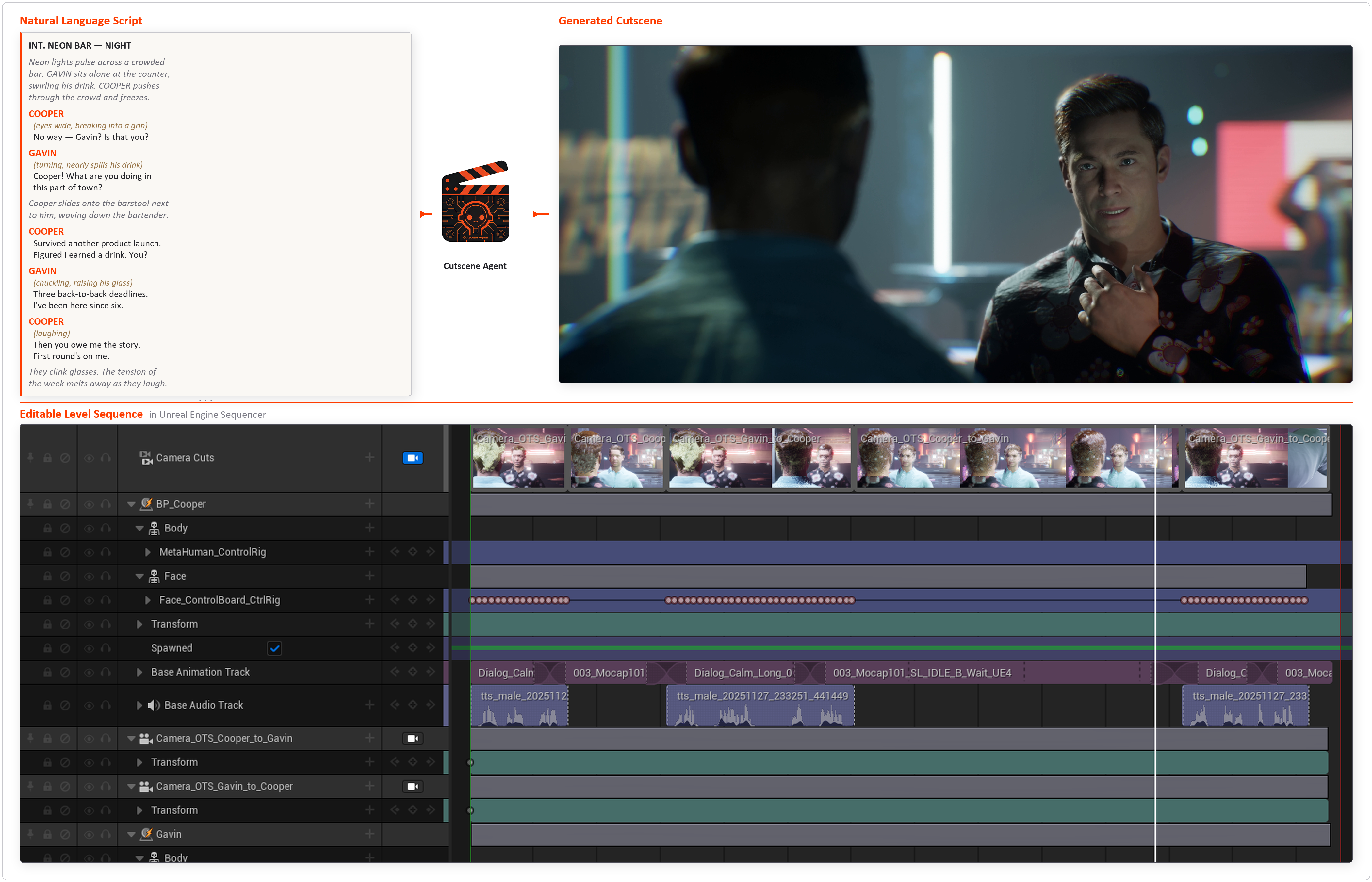
Figure 1: The end-to-end pipeline generates editable UE assets from scripts, with all tracks and sequences fully artist-editable post-generation.

Figure 2: Structure of Cutscene Toolkit modules and corresponding MCP interface tools.
- Hierarchical Evaluation (CutsceneBench): The CutsceneBench benchmark introduces three evaluation layers: tool-use correctness (valid tool calls, parameter and dependency consistency), sequence structural integrity (track completeness, camera coverage, temporal alignment), and narrative/cinematic quality (LLM-judged script fidelity, character consistency, cinematography, and timing). This framework uniquely captures the multi-dimensional requirements of professional cutscene generation and permits cross-model, cross-scenario stratified analysis.
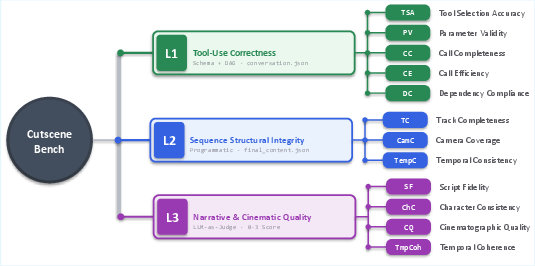
Figure 3: Evaluation layers for CutsceneBench, from atomic tool correctness to narrative and cinematic assessment.
The toolkit design is highly modular, relying on MCP for transport, with task scheduling, context-aware prompt assembly, category-driven call compression, and robust main thread execution.
Technical Advances
MCP-Based Engine Integration
Unlike approaches relying on brittle hardcoded APIs or static action libraries, the MCP Cutscene Toolkit exposes all major cutscene operations via schema-validated, engine-agnostic, semantically rich structured function calls and query interfaces. Bidirectionality is preserved: the agent always receives the current canonical scene state before every decision, ensuring ability to synchronize and compose long-range tool trajectories. Abstractions such as relative positioning identifiers, semantic camera templates, and dynamic asset management (including real-time ingestion of TTS and facial animation) enable scalable, context-agnostic agent logic.

Figure 4: A library of camera templates for semantic cinematography, parameterized by scene context and character geometry.
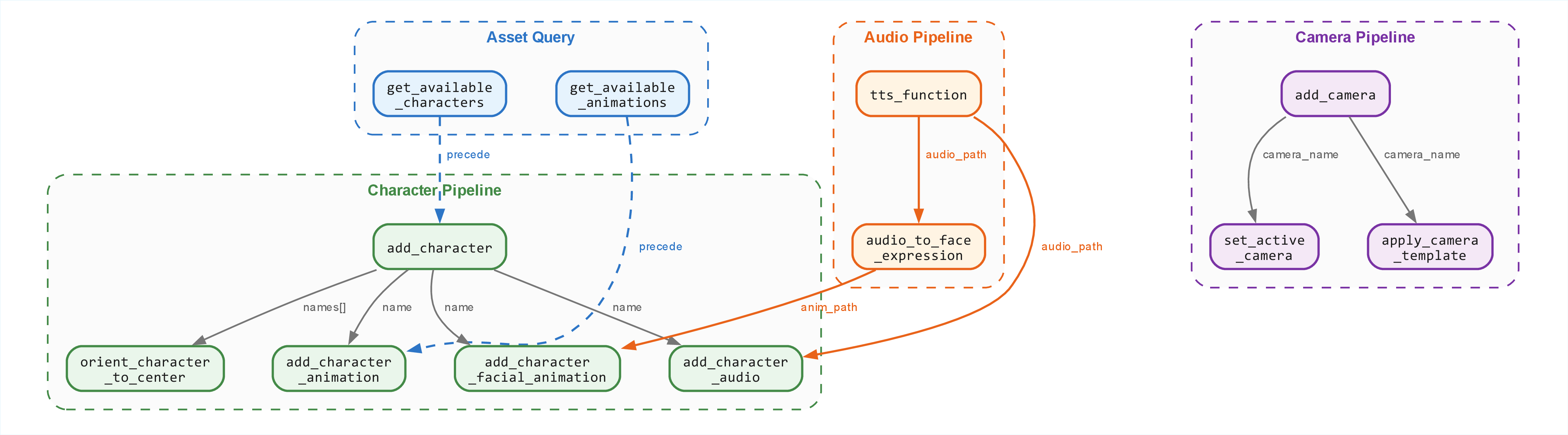
Figure 5: Explicit inter-tool DAG expressing all parameter and ordering dependencies within the toolkit. Critical for automated dependency compliance.
Multi-Agent Workflow Orchestration
The director agent applies dynamic prompt assembly, context window-aware history compression, and on-demand subagent delegation. Subagents have isolated context and tool privilege, minimizing error propagation and enabling reusable, specialization-driven micro-pipelines (e.g., for camera planning vs. animation assignment).
A core innovation is the closed-loop vision feedback subagent, which injects rendered frames into a multimodal LLM for visual analysis, compositional correction, and perception-driven refinement—marking a significant shift from text-only, sightless LLM pipelines.
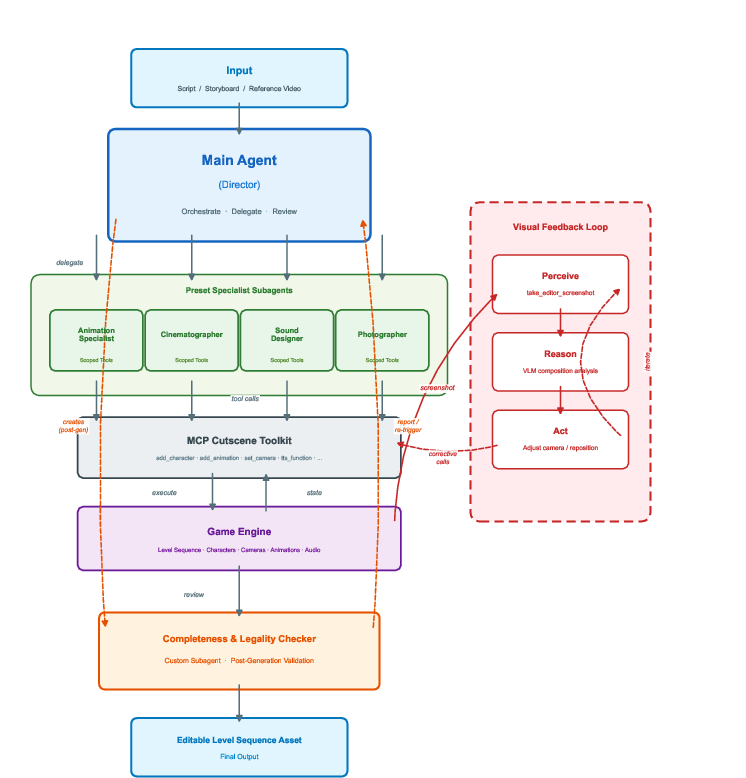
Figure 6: System overview: the director LLM delegates to domain subagents and closes the loop via visual-multimodal feedback.
Context Compression and State Synchronization
Cutscene Agent advances context management by distinguishing between high-density mutation commands (which are compressed once their effect is state-persistent) and low-frequency queries (which are always retained or replaced with the latest valid instance). This policy maximizes context window utility for long-horizon tasks (typical cutscenes require 60+ calls).
Robustness to Spatial and Structural Pathologies
To address LLM numeric and spatial failures, all spatial tool APIs operate on semantic references (e.g., “face character A” rather than explicit Euler angles). Automated collision detection, state validation, and sequence track completeness checks are performed by post-hoc custom subagents, ensuring sequences remain within geometric and temporal constraints.
Hierarchical Evaluation and Results
CutsceneBench exposes unique challenges: lack of single canonical ground truth (many valid cutscenes per script), long-horizon compositional dependencies, cumulative stateful side effects, and the requirement for creative as well as technical scoring. Layered evaluation metrics—tool selection/parameter/dependency compliance, track/camera/temporal completeness, LLM-as-judge for script/character/cinematography/timing—enable fine-grained model comparison.
Key Numerical Findings:
- Top flagship models (Claude Opus 4.6, GPT-5.4, Claude Sonnet 4.6) achieved nearly perfect tool selection, parameter validity, and dependency compliance (>99.3%) and approached full sequence and camera coverage.
- Call completeness and camera coverage formed the major axis of differentiation among market-leading LLMs: e.g., Camera Coverage ranged from 96.4% (top) to 73.9% (lower), with consistent underperformance by middle-size models (e.g., Qwen 2.5-72B, ~56%).
- Narrative and cinematic quality (LLM-as-judge, max 100): upper-bound models scored 50.2 (Claude Opus 4.6), with lower-middle flagships at 25–30, and middle-size models failing to achieve viable structural outputs.
- Performance dropped with scenario complexity, especially for call completeness and cinematic differentiation. Multi-character spatial reasoning and cross-track temporal consistency remain bottlenecks.
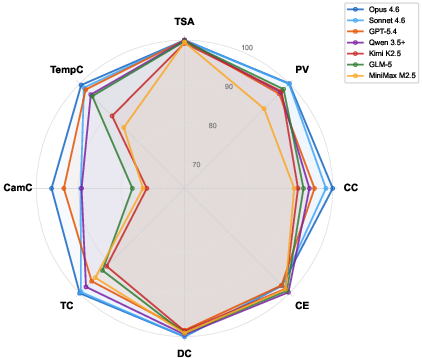
Figure 7: Radar chart of L1/L2 metrics. Camera Coverage (CamC) exhibits largest inter-model gap.
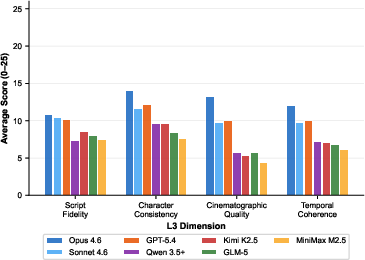
Figure 8: Layer 3 narrative/cinematic per-dimension scoring; Cinematographic Quality shows highest model stratification.
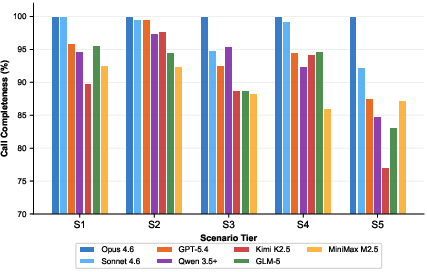
Figure 9: Scenario-wise breakdown of call completeness. Task-complexity amplifies capability stratification.
Implications and Future Directions
Practically, this framework dramatically lowers the barrier for comprehensive, editable cutscene asset generation, enabling rapid iteration by both smaller studios and non-expert users. The theoretical implications are twofold: (1) editability-preserving agentic pipelines are a significant step toward fully multi-modal generative environments; (2) multi-step dependency and stateful orchestration introduce new dimensions of agentic evaluation distinct from single-step or stateless benchmarks.
Future directions include expansion to non-dialogue cutscenes (action, crowds), tighter real-time asset synthesis integration (on-device TTS, generative motion), porting the MCP toolkit to other industry-standard DCCs (Unity, Blender), and support for persistent cross-cutscene narrative arcs (maintaining world and character state).
Conclusion
Cutscene Agent presents a robust, extensible, and empirically validated framework for fully automated, editable 3D cutscene generation, thoroughly bridging the editability gap that limits prior LLM and video diffusion approaches. By combining an MCP abstraction layer, compositional long-horizon multi-agent orchestration, closed-loop multimodal feedback, and a multi-layered evaluation benchmark, this work establishes a new practical and research foundation for agentic content generation in interactive media and professional digital content pipelines (2604.25318).