- The paper presents a capability-oriented framework that employs adaptive test generation and automated oracles to pinpoint failure causes in VLN agents.
- It leverages search-based fuzzing and modular oracle evaluation to isolate errors in perception, memory, planning, and decision-making components.
- Experiments show a 23.3%–33.7% increase in failure discovery and high repairability via oracle intervention, enhancing diagnostic precision.
Capability-Oriented Failure Attribution in VLN Agents: An Expert Perspective on CanTest
Introduction
The paper "Where Did It Go Wrong? Capability-Oriented Failure Attribution for Vision-and-Language Navigation Agents" (2604.25161) introduces CanTest, a novel framework targeting high-fidelity testing and failure attribution in Vision-and-Language Navigation (VLN) agents. VLN agents integrate perception, memory, planning, and decision modules, creating a complex, interdependent pipeline. Traditional system-level testing approaches fail to provide actionable insights into which specific capabilities are deficient, hindering the debugging and improvement of such agents. CanTest directly addresses this challenge through capability-oriented test case generation, automated construction of capability oracles, and a feedback-driven attribution mechanism.
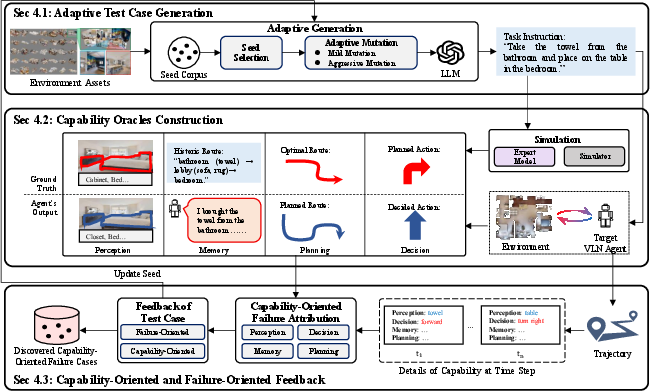
Figure 1: The CanTest framework combines adaptive test generation, capability-level oracles, and feedback-driven iterative case generation for VLN agents.
CanTest Framework: Modular Design for Capability Attribution
Adaptive Test Case Generation
CanTest's first module is an adaptive case generation pipeline that leverages search-based fuzzing. Seed instructions are generated using environmental assets (e.g., room/object annotations from the HM3D dataset), then mutated using either "mild" (small semantic edits) or "aggressive" (structural changes) operators, selected on the basis of feedback scores from previous evaluation rounds. This drives exploration towards scenarios most likely to expose new or diverse failures.

Figure 3: Illustration of mild mutation (object substitution within the same room) versus aggressive mutation (room and object substitution), enabling targeted test diversity.
Capability-Oriented Oracles
Central to CanTest is the construction of capability-oriented oracles, providing independent evaluators for perception, memory, planning, and decision. The perception oracle utilizes weighted IoU to compare object/landmark identification, leveraging expert annotations or reference models. The memory oracle quantifies the agent’s recall by comparing historic observations (semantic similarity, evaluated via LLM prompts) to ground truth. Planning is evaluated with normalized Dynamic Time Warping (nDTW) between the agent's trajectory and an expert’s path. The decision module is assessed by direct action correspondence to planned steps.
Capability failure is defined as a deviation in the module’s output from this oracle, and not every module error is immediately associated with full task failure. Distinguishing between error propagation and originating faults is crucial for precise attribution.
Capability-Oriented Failure Attribution via Feedback
CanTest employs a two-level feedback mechanism for case selection and mutation. System-level (failure-oriented) feedback measures the task completion success, while capability-oriented feedback normalizes oracle errors within a seed corpus and incorporates adaptive weights (via λCx) to ensure all capabilities are stressed during testing. Failure attribution is based on causal intervention: if correcting a capability error at time t (using the oracle’s output) causes a failure trajectory to succeed, the tool attributes the failure to that capability at that timestep, selecting the earliest such instance in the chain for final attribution.
Experimental Analysis and Results
Failure Discovery and Attribution
Across three SOTA VLN agents (ApexNav, MGDM, Mem2Ego), CanTest consistently discovers 23.3%–33.7% more failure cases than the strongest baseline (VLATest), as depicted in Figure 3. The unique design of capability oracles underpins this improvement, enabling generation of test cases that are informative for module-level errors rather than only for task-level failures.

Figure 4: CanTest outperforms all system-level and SOTA baselines in failure case discovery across VLN models.
Moreover, CanTest produces the broadest and most precise failure-attribution statistics for all modules, outperforming both native and +OA augmented versions of existing testing frameworks. This enables comprehensive coverage and supports granular diagnosis of observed behaviors in VLN agents.
Qualitative Analysis: Failure Modes
The framework surfaces interpretable, actionable failure cases directly attributed to specific capabilities (Figure 4). For example, perception errors include missed landmark identification, memory errors manifest as route forgetfulness, planning failures as suboptimal or looping trajectories, and decision faults as divergence from planned actions.
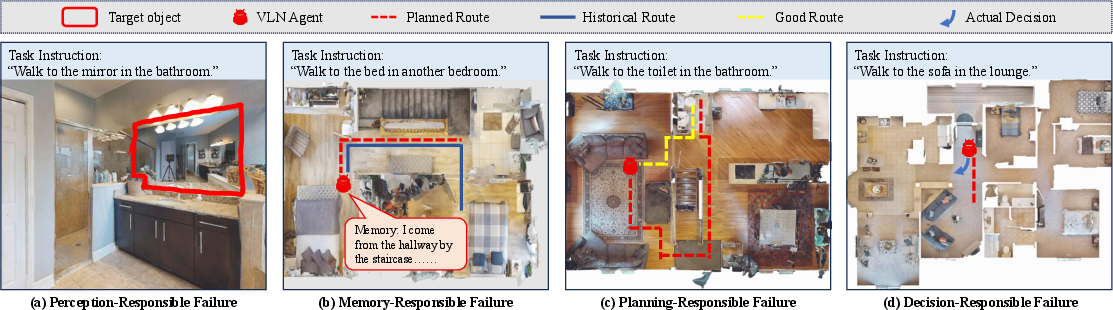
Figure 5: Representative examples of failures caused by perception, memory, planning, and decision modules, as discovered by CanTest.
Fidelity of Oracles and Repairability
Over 80% to 96% of failures attributed by CanTest to specific modules are "repaired" through oracle intervention—replacing the module's output with the oracle's correction converts the failure trajectory into a success. This quantifies the high precision and low false attribution rate of the capability oracles, underscoring their utility for diagnosability and system improvement.
Ablation Study
Ablation experiments demonstrate that both failure- and capability-oriented feedback are necessary for coverage maximization; disabling either significantly reduces the number of identified failures (Figure 5). The balanced combination provides robust pressure across diverse agent weaknesses.

Figure 2: Ablation study results corroborate the necessity of both feedback modalities for maximizing discovery and attribution coverage.
Practical and Theoretical Implications
From a practical perspective, CanTest raises the diagnosis granularity for embodied agents, shifting from opaque system-level pass/fail metrics to a modular, interpretable, and debuggable regime. This allows the targeted augmentation of individual capabilities, facilitating data augmentation, curriculum learning, or module-specific retraining efforts.
Theoretically, CanTest introduces an automated, feedback-driven, causality-aware testing paradigm broadly applicable to any modular agent architecture combining perceptual, memory, planning, and decision domains. Its requirement for access to expert oracles, while limiting in some real-world sim2real deployments, can be addressed through semi-supervised or human-in-the-loop variants, as discussed in the paper's limitations.
Limitations and Directions for Future Work
The reliance on high-fidelity experts for oracle construction remains a limiting assumption in real-world deployment. Adapting CanTest to physical environments will necessitate weaker or surrogate oracles, perhaps distilled from demonstration or selective annotation. The potential integration with uncertainty estimation frameworks and active learning feedback in lifelong robotic systems remains a promising development direction. Handling long-horizon credit assignment, as addressed here in the VLN context, will become increasingly critical as embodied agents are deployed in richer, multi-agent, and continuously evolving settings.
Conclusion
CanTest delivers capability-oriented, interpretable, and high-fidelity failure attribution for VLN agents, outperforming state-of-the-art testing frameworks in both failure-case discovery and module-level fault localization. By decoupling and targeting perception, memory, planning, and decision-making pipelines, it provides actionable insights for agent improvement and sets a compelling methodological precedent for modular testing and attribution in embodied AI. Its design is extensible to future architectures and more complex, integrated agent environments.