- The paper introduces a novel neural representation that models the full 8D light transport operator for both near-field and far-field illumination.
- It decomposes the light transport into a directional albedo and a conditional density parameterized via an autoregressive normalizing flow, reducing variance and improving accuracy.
- Experimental results demonstrate a 2–4x reduction in reconstruction error and up to 20x speedup in rendering complex assets compared to standard methods.
8DNA: 8D Neural Asset Light Transport by Distribution Learning
Introduction and Context
Accurate simulation of global illumination phenomena––including subsurface scattering, volumetric and fiber-based interactions, and interreflections––is essential for photorealistic rendering of complex assets, yet these effects are prohibitive to simulate using path tracing due to their high-dimensional light transport and expensive sampling requirements. This work introduces 8D Neural Asset (8DNA), a neural representation that explicitly models the full 8D light transport operator F(xo,ωo,xi,ωi) for 3D assets. Unlike prevalent approaches that assume the far-field (reducing the parametrization to 6D and integrating over the incident position), 8DNA captures the spatially and directionally resolved mapping from incident to exitant radiance, thus enabling accurate rendering under both near-field and far-field illumination.
The key contribution lies in formulating light transport learning as a conditional distribution estimation problem, bypassing the high-variance regression endemic to direct 8D transport fitting. This enables efficient, unbiased learning from path-traced samples and yields a neural asset that is both importance-samplable and renderer-agnostic.
Methodology
Decomposition and Distribution Learning Framework
The 8D light transport operator F is decomposed into a color-dependent survival probability (directional albedo) α(xo,ωo) and a conditional probability density p(xi,ωi∣xo,ωo) that describes the global-scattering distribution. The survival probability is modeled using an MLP, and the scattering distribution is parameterized using an autoregressive, vector-valued normalizing flow.
Training is performed in a forward-sampling paradigm reminiscent of path tracing: random outgoing boundary configurations are sampled, and path tracing is used to generate incident configurations and associated throughput terms. The negative log-likelihood is minimized for p, and an L2 loss is employed for α, yielding unbiased and inherently low-variance stochastic gradient estimates.
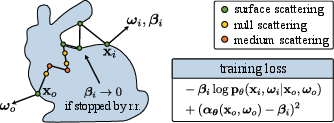
Figure 1: Training proceeds by tracing random outgoing rays, recording their interaction sequences and path throughput; the output configurations are used as training tuples in the loss computation.
Parameterization and Normalizing Flow
The mapping from asset-boundary coordinates and incident directions is achieved via a bounding-box proxy: incident rays are parameterized by their intersection points with the bounding geometry and expressed in cylindrical coordinates, avoiding non-injective mappings and singularities inherent in spherical coordinates. The normalizing flow employs rational quadratic splines for density estimation, with four sequentially conditioned MLPs modeling the joint distribution over the 4D incident configuration space for each outgoing configuration and color channel.
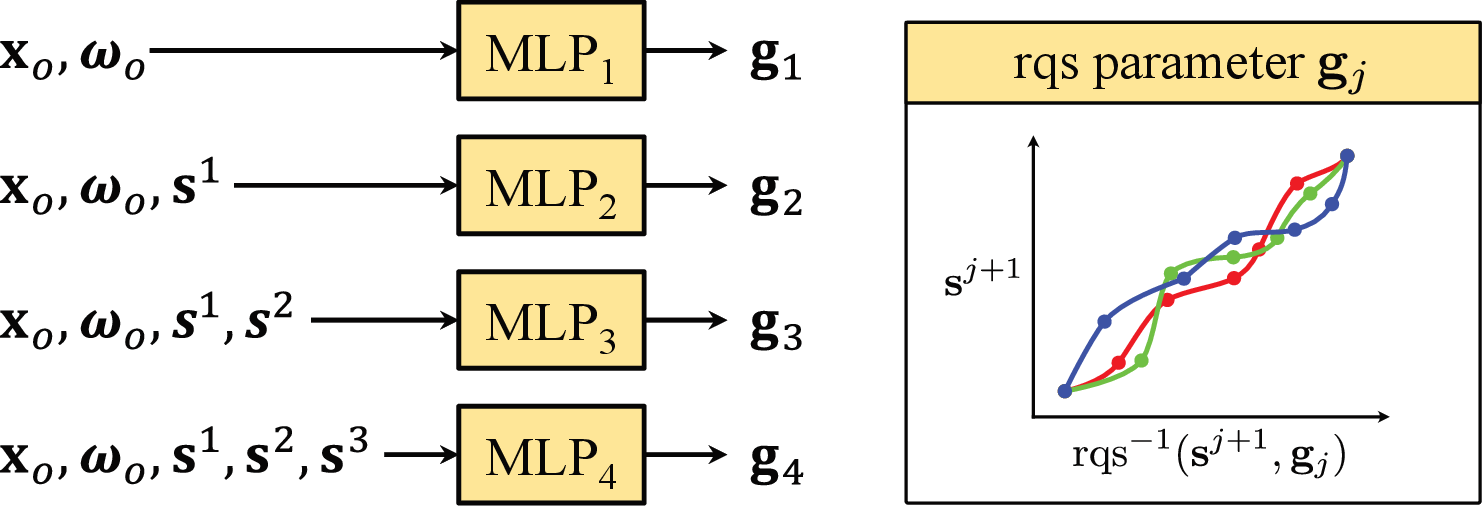
Figure 3: The vector-valued normalizing flow models the incident ray distribution with an autoregressive sequence of rational quadratic spline conditionals, each controlling the density for an individual coordinate given prior context.
Direct-Indirect Separation
To further mitigate learning difficulty, direct (delta-like) scattering components––such as the refractive boundary response––are separated from indirect, global illumination. The analytic direct lobe is treated separately at both training and inference, with the network focusing exclusively on modeling the indirect, multi-bounce transport. This separation provides better accuracy for sharp features and reduces network capacity demands.

Figure 4: The analytic direct scattering, which is highly specular, is decoupled from the smooth indirect volumetric component, allowing the neural model to focus on global transport.
Integration with Path Tracing
At inference, the neural asset representation is used for importance sampling and evaluation of the light transport integral during path tracing. For each boundary interaction involving a neural asset, the path tracer samples an incident configuration using the flow and performs Multiple Importance Sampling (MIS) with the emitter-distribution. This mechanism ensures compatibility with legacy renderers and supports composition of multiple neural assets in complex scenes.
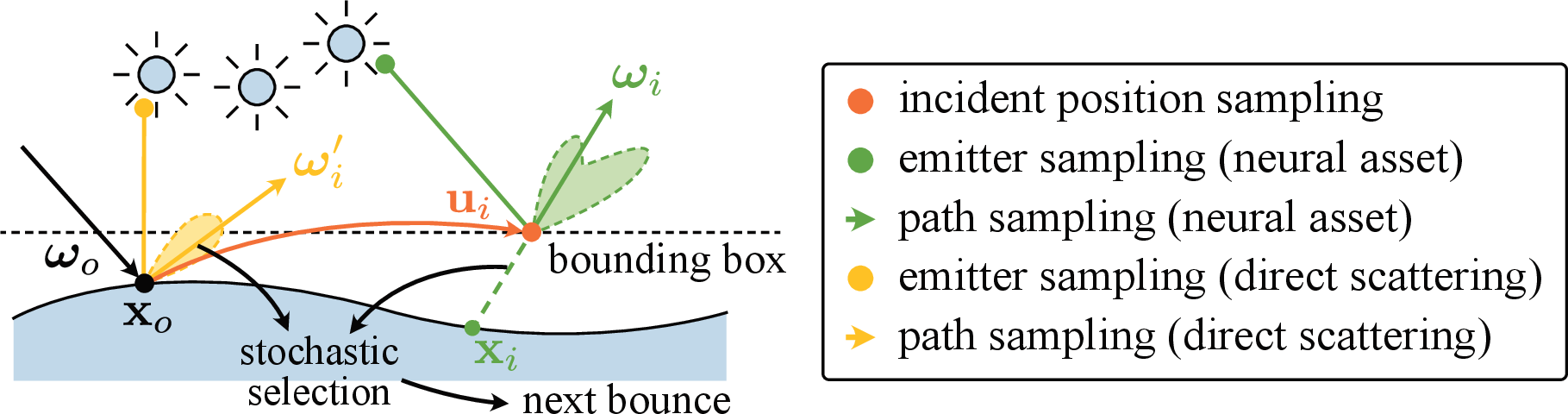
Figure 6: Path tracing with 8DNA augments the standard procedure by introducing MIS over sampled incident locations, with stochastic selection between analytic (direct) and neural (indirect) bounces.
Experimental Results
Experiments use assets with heterogeneous volumetric, surface-based, and fiber-based light transport effects. The evaluation is against standard path tracing and the representative 6D far-field neural regression baseline.
Accuracy and Variance
8DNA consistently achieves lower MSE compared to far-field neural baselines, especially under near-field lighting. Tabled quantitative results show a typical improvement factor of 2–4x in reconstruction error (MSE) for challenging scenes, and the qualitative comparisons indicate faithful reproduction of fine volumetric and view-dependent effects missed by the far-field models.

Figure 2: Qualitative comparison reveals that 6D far-field methods consistently overestimate incoming radiance in occluded or shadowed areas, while 8DNA better matches path-traced ground truth.
Regarding variance and inference efficiency, the 8DNA model reduces rendering variance substantially compared to pure path tracing, particularly for assets with long or complex internal scattering paths (e.g., translucent volumes, hair). While the far-field model yields lower variance for surface-only or simple cases, this advantage is offset by its inaccuracy. Equal-time comparisons show that 8DNA enables 2–20x speedups for difficult cases, with convergence improvements increasing alongside scene complexity.
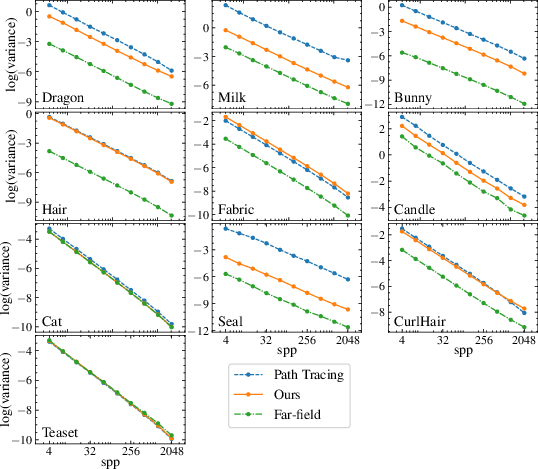
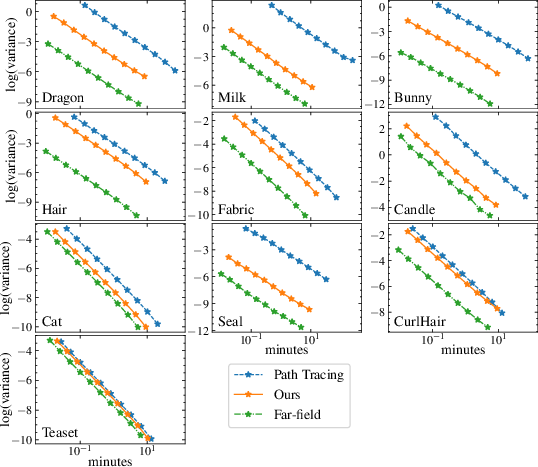
Figure 5: Log-log convergence plots of rendering variance versus samples per pixel and rendering time highlight superior variance reduction for 8DNA, especially for assets with volumetric and anisotropic scattering.
Training Efficiency
Distribution learning with 8DNA enables training from forward path-sampled tuples, which are orders-of-magnitude cheaper to generate than the high-spp Monte Carlo solutions needed for regression-based (far-field) training. The overall end-to-end time to generate and train assets is reduced by up to 3x for volumetric assets, with on-the-fly data sampling preventing network overfitting.
Ablations and Limitations
Smaller networks and reduced spline resolutions demonstrate trade-offs in speed versus reconstruction fidelity. Alternative bounding geometry proxies (convex hull, sphere) also affect inference variance, with tighter bounding areas generally yielding better results.
The principal limitation is that assets are pre-baked in isolation. Thus, introducing new occluding geometry inside the convex hull at deployment time induces inconsistencies, as the neural asset cannot account for altered internal scattering or occlusion. High-frequency interreflections and caustics also remain outside the expressivity of current normalizing flows.
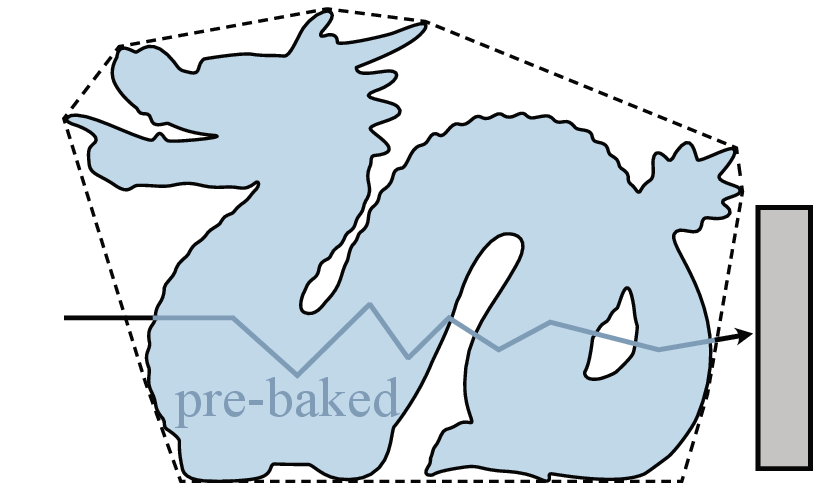
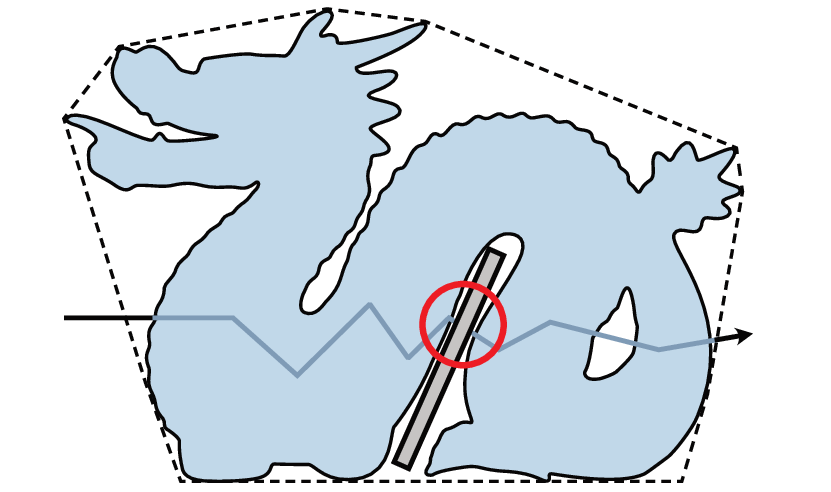
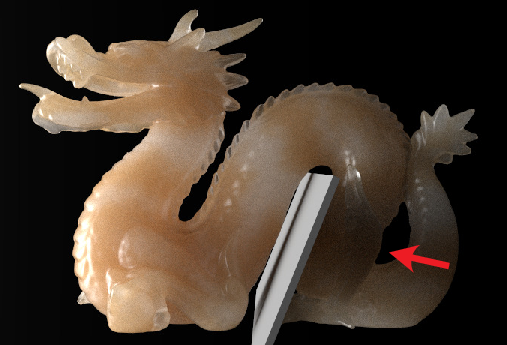
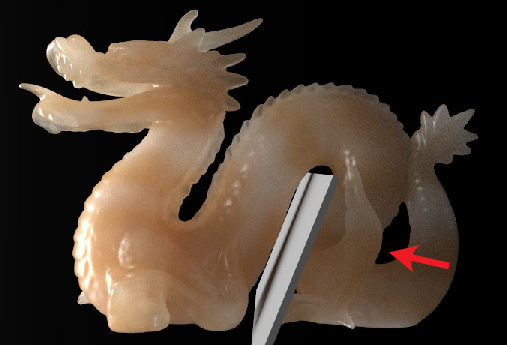
Figure 10: Example failure: inserting occluding geometry inside the asset's convex hull leads to unmodeled occlusion effects that the pre-baked transport cannot reproduce.
Implications and Future Directions
8DNA provides a renderer-agnostic, query-efficient, and fully relightable neural asset formulation capable of encapsulating general multi-bounce, near-field light transport within a general 8D framework. This enables high-fidelity asset sharing, rapid relighting, and modular scene composition without the need for custom light transport implementations or costly online simulation. The approach is theoretically generalizable to any non-emissive asset for which the internal scattering is convex-hull bounded and static during deployment.
Potential future research directions include:
- Incorporating local geometric context into the neural representation to dynamically account for proximate occluding geometry.
- Developing more expressive, adaptive normalizing flows (potentially with attention or mixture-of-experts architectures) to capture high-frequency caustic and interreflection phenomena.
- Extending to time-resolved (transient) or spectral domains for broader physical realism.
- Integration with hybrid real-time rendering systems, exploiting the fast inference and low-variance sampling properties in production hardware pipelines.
Conclusion
The 8DNA framework establishes a robust methodology for neural asset-based light transport precomputation by framing the task as conditional density estimation in a high-dimensional domain. It achieves higher visual fidelity and sampling efficiency compared to both path tracing and prior regressed neural transport bases, particularly for volumetric and fiber-rich assets illuminated by spatially localized lights. The method strikes a compelling balance between accuracy, efficiency, and modular reusability, with clear paths for enhanced expressivity and generalization in future neural rendering systems.
(2604.25129)

