- The paper introduces MPD, a dual-stage framework that isolates hallucination components via semantic disentanglement and targeted parameter editing.
- MPD achieves a 23.4% reduction in hallucinated outputs and maintains 97.4% of the original generative quality across standard benchmarks.
- The method offers efficient intervention with minimal inference cost, preserving hidden feature distributions and ensuring robust multimodal reasoning.
Introduction and Motivation
Large Vision-LLMs (LVLMs), which integrate vision encoders with LLM backbones, excel in multimodal understanding and generative tasks but are prone to generating hallucinations, i.e., semantic content in outputs not supported by visual inputs. These hallucinations manifest as fabricated objects, incorrect attributes, or erroneous spatial relationships, which undermine model reliability, especially for downstream tasks or safety-critical deployments.
Traditional approaches to hallucination mitigation depend heavily on fine-tuning with curated datasets, incurring high annotation and compute costs, hampering scalability. Representation intervention methods that edit model parameters or hidden representations offer an efficient alternative but often degrade the model’s general generative capability due to coupled extraction of hallucination and semantic components and indiscriminate parameter modifications.
This work introduces the MPD framework—a dual-stage, training-free intervention designed to suppress hallucinations in LVLMs while preserving generative fluency. The key innovations are semantic-aware disentanglement for isolating hallucination directions and interpretable, selective parameter editing constrained to hallucination-relevant weights.
MPD: Semantic-Aware Disentanglement and Targeted Model Editing
The MPD framework proceeds in two well-structured stages:
MPD constructs contrastive input pairs: prompt-image combinations yielding faithful (grounded) and hallucination-induced outputs. Token-level representations from these responses, extracted across selected transformer layers, are analyzed via SVD to define the faithful semantic subspace. The hallucinated components are isolated through orthogonal projection onto the complement of this subspace, ensuring disentanglement from core semantic content.
Theoretical analysis substantiates the effectiveness of this projection-based approach over naive differencing, showing strictly lower estimation error with respect to the true hallucination-specific signal.
Interpretable, Selective Parameter Editing
Having isolated hallucination-driving components in the hidden state, MPD identifies the subset of weight vectors most correlated with these components via cosine similarity. Only these selected parameters (typically a small fraction of total weights) are projected out of the hallucination subspace, minimizing collateral disruption to unrelated behaviors. This sharply contrasts with methods such as Nullu and VCD, which target larger parameter sets and induce substantial shifts in the overall feature distribution.
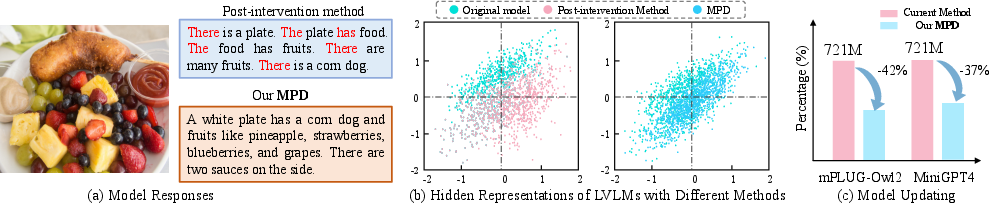
Figure 1: Comparison between conventional representation-intervention methods and MPD—MPD yields coherent outputs with fewer parameter updates and minimal feature drift.
Empirical Evaluation
MPD’s efficacy is benchmarked on multiple axes: sentence-level and instance-level hallucination (CHAIRS and CHAIRI), object presence accuracy (POPE and OPOPE), and generic generative quality (BLEU, GPT-4V metrics). Experiments are conducted on strong LVLMs (MiniGPT-4, mPLUG-Owl2, and LLaVA-1.5-7B) with state-of-the-art competitive baselines, including decoding-time (DoLa, HALC), decoding refinement (OPERA), and representation projection (Nullu).
MPD demonstrates consistent hallucination reduction: averaging 23.4% fewer hallucinated outputs, and outperforming all baselines on CHAIR and POPE. For instance, on LLaVA-1.5-7B, MPD reduces CHAIRS to 12.8 and CHAIRI to 4.2, surpassing Nullu and other related approaches.
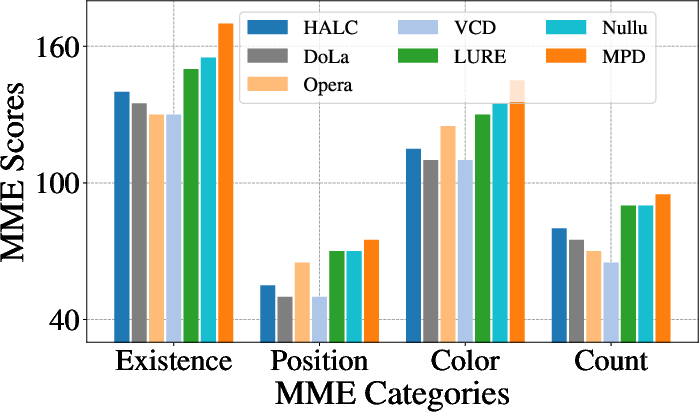
Figure 2: Comparisons of MME scores across main baselines and the proposed MPD method.
MPD also achieves the highest F1 scores on the POPE and OPOPE object grounding benchmarks, indicating robust object presence reasoning across random, popular, and adversarial settings.
Preservation of General Generative Capacity
A critical evaluation criterion is to ensure hallucination suppression does not compromise the general expressive and reasoning power of LVLMs. On LLaVA-Bench, MPD solutions preserve 97.4% of the original BLEU and detailedness scores, with GPT-4V human-like evaluations corroborating improved accuracy and informativeness post-editing.
Comprehensive MME (Existence, Count, Position, Color) results reveal that MPD not only maintains accuracy but frequently achieves the best results—highlighting that suppression of hallucinations does not come at the expense of structured perception and reasoning.
Feature Distribution Integrity
Representation-level analyses via PCA of token embeddings show that, in contrast to broader parameter-editing approaches, MPD closely preserves the alignment of hidden feature distributions; the shifts induced in the feature manifold are minimal, attesting to the selectivity of its intervention mechanism.
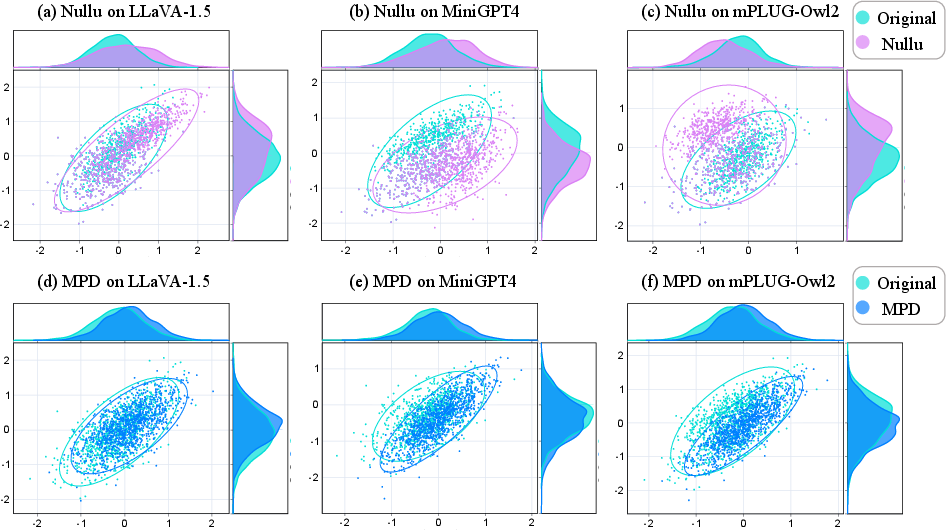
Figure 3: Distribution of hidden representations before and after editing across LVLMs; MPD maintains high distributional alignment while suppressing hallucinations.
Efficiency and Practical Scalability
MPD incurs virtually no additional inference cost—computation is limited to an efficient, offline parameter update prior to deployment. Latency and memory usage remain comparable to standard LVLM inference, with no need for auxiliary modules at runtime, making MPD suitable for real-world or resource-constrained deployments.
Notably, ablation analyses show that hallucination-driving semantics are highly localized: performance saturates when editing a small number of top-aligned weights, reflecting practical editability and minimal risk of catastrophic forgetting or overfitting.
Case Studies and Qualitative Insights
Exemplar cases from LLaVA-Bench illustrate MPD’s practical benefits. Whereas standard LVLMs hallucinate visual entities antagonistic to the observed content (e.g., hallucinating "Mount Fuji" in a Hawaii scene or adding fictional food items), MPD-edited models provide visually consistent, grounded descriptions, thereby reducing the risk of semantically misleading model outputs.

Figure 4: Case studies from the LLaVA-Bench set, showing improved factual alignment and reduced hallucinations with the MPD intervention.
Theoretical and Practical Implications
MPD offers a pathway for efficient, structured suppression of multimodal hallucinations without recourse to costly re-training or elaborate decoding pipelines. Its two-stage disentanglement and intervention design is generically applicable and independent of model architecture, promising extensibility to next-generation LVLMs and potential for transfer into related forms of undesirable generation phenomena (e.g., toxicity, bias).
Critically, the selective nature of MPD exposes avenues for model interpretability at the granularity of parameter attribution to specific error modalities. Its plug-and-play functionality makes it adaptable to evolving use-case requirements, future architectures, and real-time contexts.
Limitations and Future Prospects
Despite strong empirical performance, MPD is not a universal solution for all forms of hallucination—its effectiveness is bounded by the capability to accurately construct contrastive question pairs and to extract orthogonal hallucination subspaces. Domain-shifted, ambiguous, or long-form generation under sparse supervision remain challenging scenarios. Moreover, the framework is agnostic to data and prompt-driven biases and does not address stylistic or high-level semantic consistency.
Future research is likely to explore tighter integration of such representation-based editing with causal tracing, continual learning, or DPO-oriented multimodal alignment. Extensions to tasks with more entangled or abstract hallucination types (outside strict object-level grounding) and automated selection of hallucination-driving subspaces may further generalize MPD’s utility.
Conclusion
MPD sets a new standard for mitigating hallucinations in LVLMs, achieving strong reductions in hallucination rates without incurring performance penalties or significant computational overhead. Its semantic-aware disentanglement paired with highly targeted editing provides a principled and practical approach, with empirical evidence establishing its superiority across a spectrum of challenging vision-language benchmarks. The methodology strategically bridges the efficiency-effectiveness gap inherent in prior art, supporting practical, trustworthy deployment of LVLMs (2604.20366).