- The paper demonstrates that catastrophic overfitting arises from weak-trigger overfitting akin to backdoor attacks.
- It introduces weight outlier suppression and backdoor-inspired fine-tuning techniques to enhance model robustness.
- Empirical analyses show that universal class-distinguishable triggers drive feature override, negatively impacting generalization.
Unifying Catastrophic Overfitting and Backdoor Mechanisms in Fast Adversarial Training
Introduction
"Unveiling the Backdoor Mechanism Hidden Behind Catastrophic Overfitting in Fast Adversarial Training" (2604.24350) presents a comprehensive theoretical and empirical analysis of catastrophic overfitting (CO) in Fast Adversarial Training (FAT). The authors propose a unified framework linking CO, backdoor attacks, and unlearnable tasks via the concept of trigger overfitting. Through systematic exploration of pathway division, feature predictions, and the emergence of universal class-distinguishable triggers, the work interprets CO as a weak-trigger variant of unlearnable tasks and leverages backdoor-inspired strategies for mitigation.
Catastrophic Overfitting Through the Backdoor Lens
Fast Adversarial Training, especially methods like FGSM-RS and FGSM-MEP, are computationally efficient but susceptible to CO, where models lose generalization beyond the adversarial attack used during training. The paper critically analyzes the core behaviors of CO—pathway division, feature overriding, and diverse forward predictions—and establishes their congruence with backdoor mechanisms.
The key insight is that CO, in FAT models, induces an adversarial pathway whose activation by adversarial perturbations mirrors feature overriding in backdoor attacks. This is systematically validated through distance confusion matrices and UMAP visualizations showing the collapse of inter-class separation in CO-affected models.
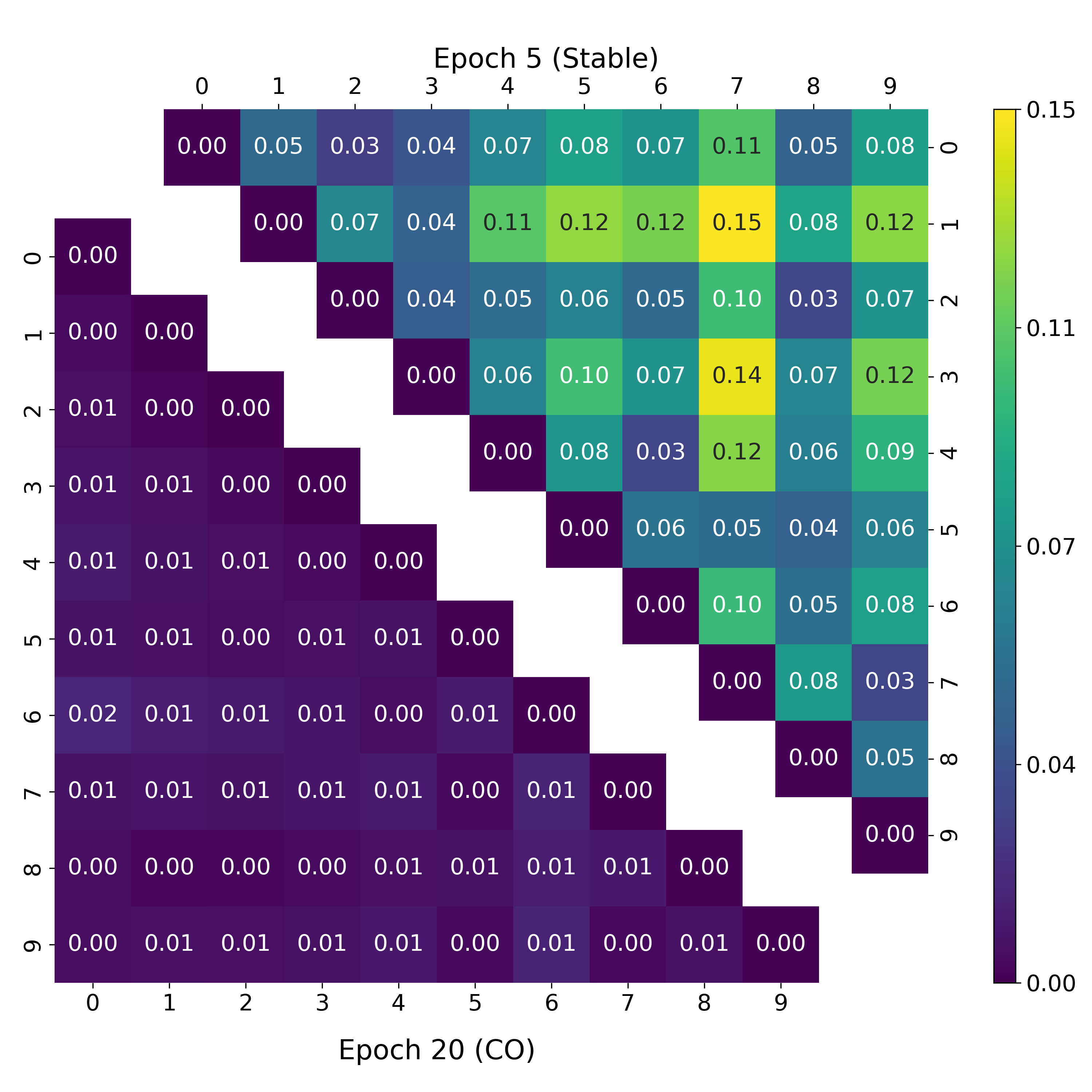
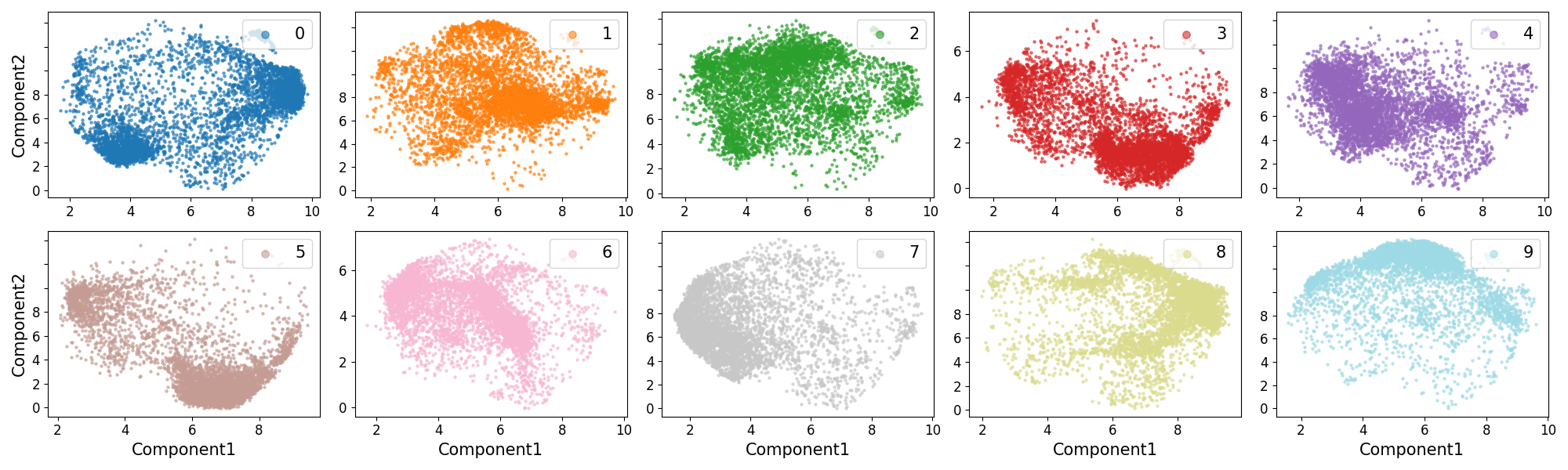
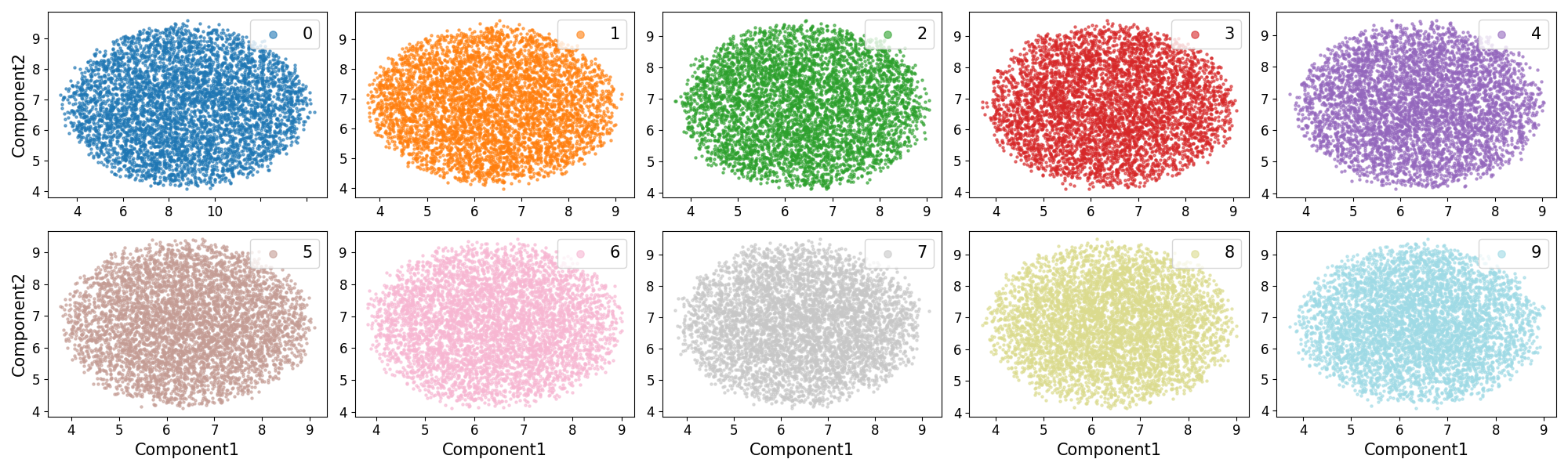
Figure 1: Distance matrix and UMAP visualizations under FGSM-RS illustrate vanishing separation between class distributions under CO.
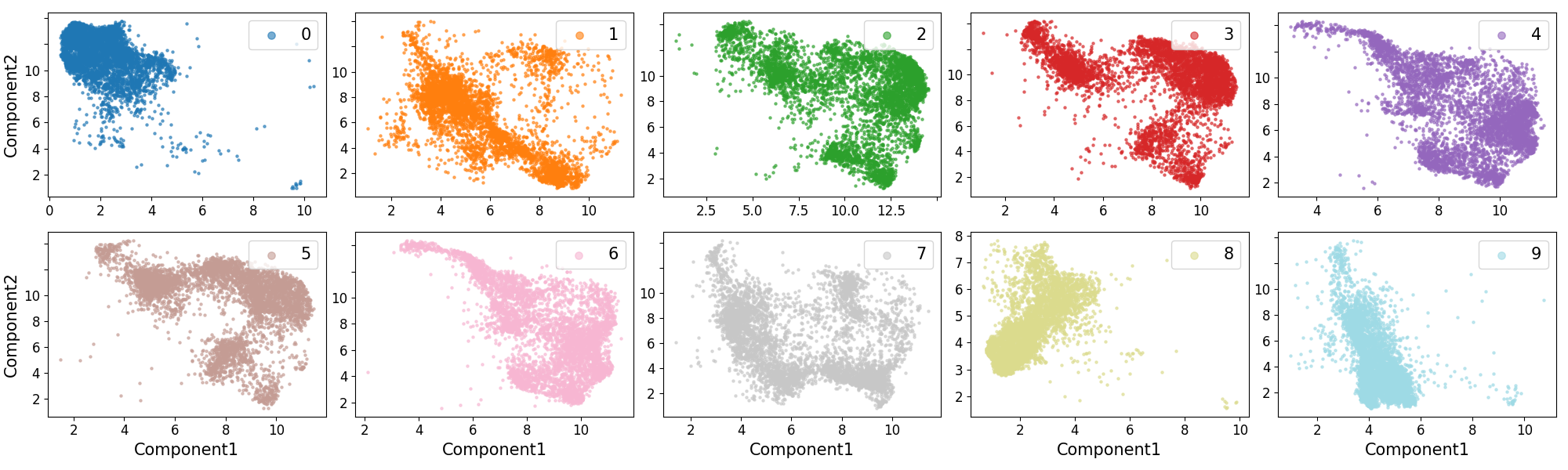
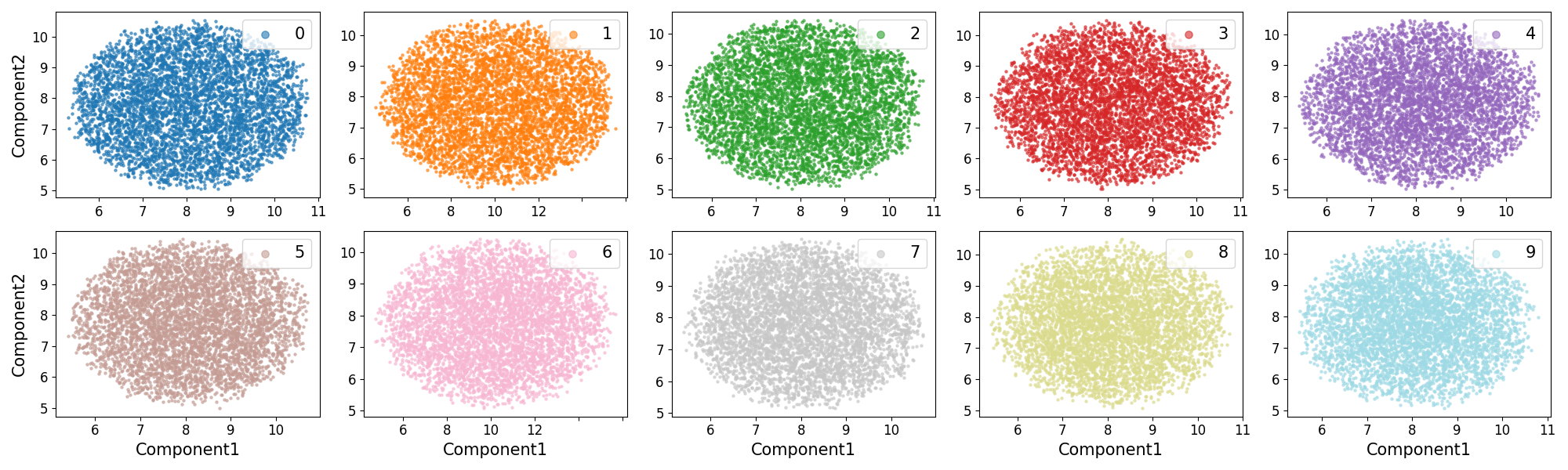
Figure 2: Distance matrix and UMAP visualizations under FGSM-MEP reinforce the similarity between CO and backdoor-induced trigger effects.
Quantitative results demonstrate that CO-affected models exhibit high accuracy for specific adversarial examples but fail to generalize to unseen attack types. This behavior parallels the overfitting to triggers in backdoor-infected and unlearnable settings.
Universal Class-Distinguishable Triggers and Trigger Overfitting
A novel aspect of the work is the identification of universal class-distinguishable (UCD) triggers within adversarial perturbations generated in CO-affected models. By computing class-wise expectations of the perturbation directions and introducing auxiliary constraints, the authors empirically verify that enforcing the forgetting of UCD triggers mitigates CO.
Comparative analysis across standard backdoor attacks, unlearnable tasks, and CO models reveals that the dominant difference is the strength of the trigger: CO is a weak-trigger analogue, retaining moderate clean accuracy relative to backdoor (strong trigger) and unlearnable (strong, universal trigger) paradigms.
Backdoor-Inspired Mitigation Strategies
To systematically resolve CO, the work adapts several backdoor defense strategies:
- Fine-tuning techniques: Vanilla fine-tuning, linear probing, reinitialization-based methods, and feature shift tuning are applied to recalibrate the model post-CO.
- Weight outlier suppression: Motivated by weight poisoning insights from backdoor literature, the authors introduce a regularization term penalizing weights that deviate excessively from the layer-wise mean. This suppresses the formation of adversarial pathways and fosters stable, robust learning.
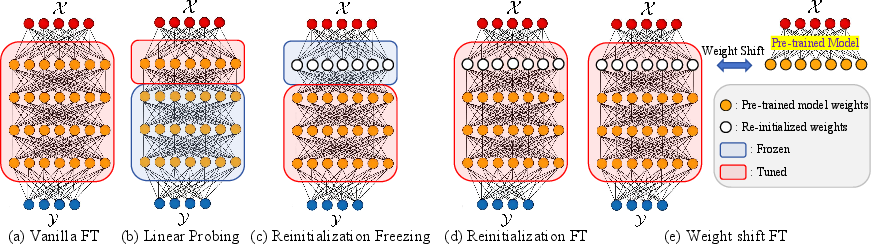
Figure 3: Backdoor fine-tuning techniques in action, demonstrating efficacy in recalibrating CO-affected models.
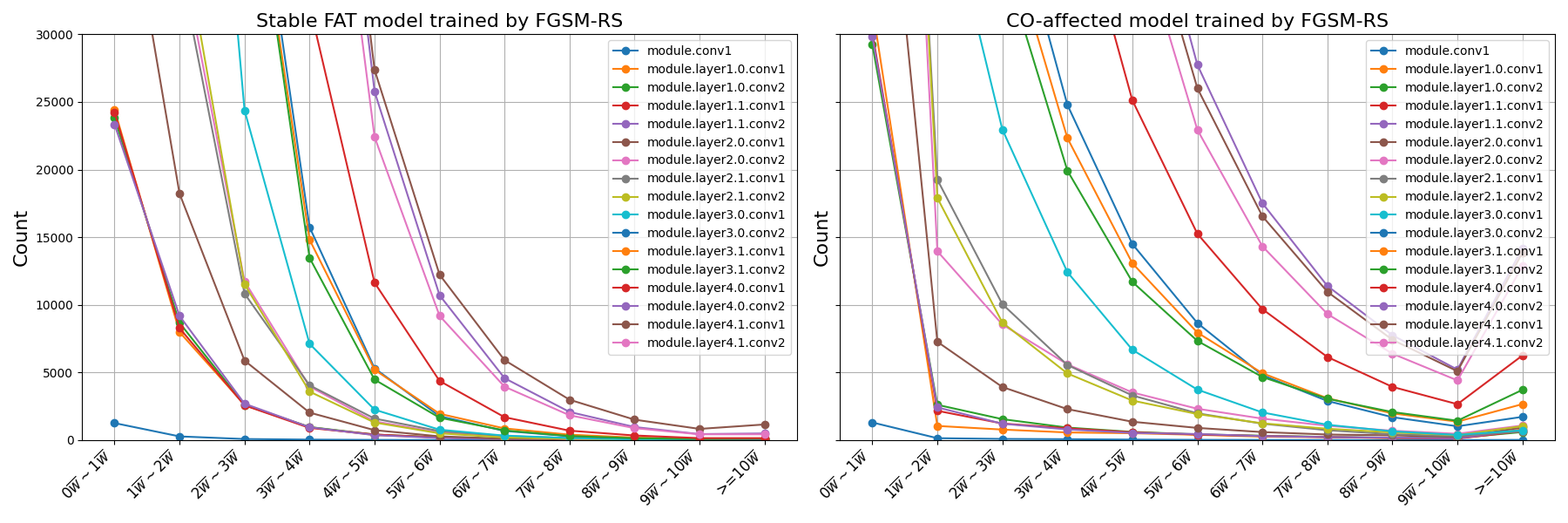
Figure 4: Weight distribution analysis reveals characteristic weight outliers in CO-affected models, which are suppressed by the proposed regularization.
Extensive empirical results validate the effectiveness of these strategies, achieving superior or comparable robustness to state-of-the-art methods such as PBD, without sacrificing clean accuracy.
Comparative Training Dynamics and Ablation Analyses
The training dynamics indicate that fine-tuning, though temporarily effective, does not provide permanent immunity from CO, as trigger overfitting can recur. The weight outlier suppression constraint, however, maintains consistent stability.
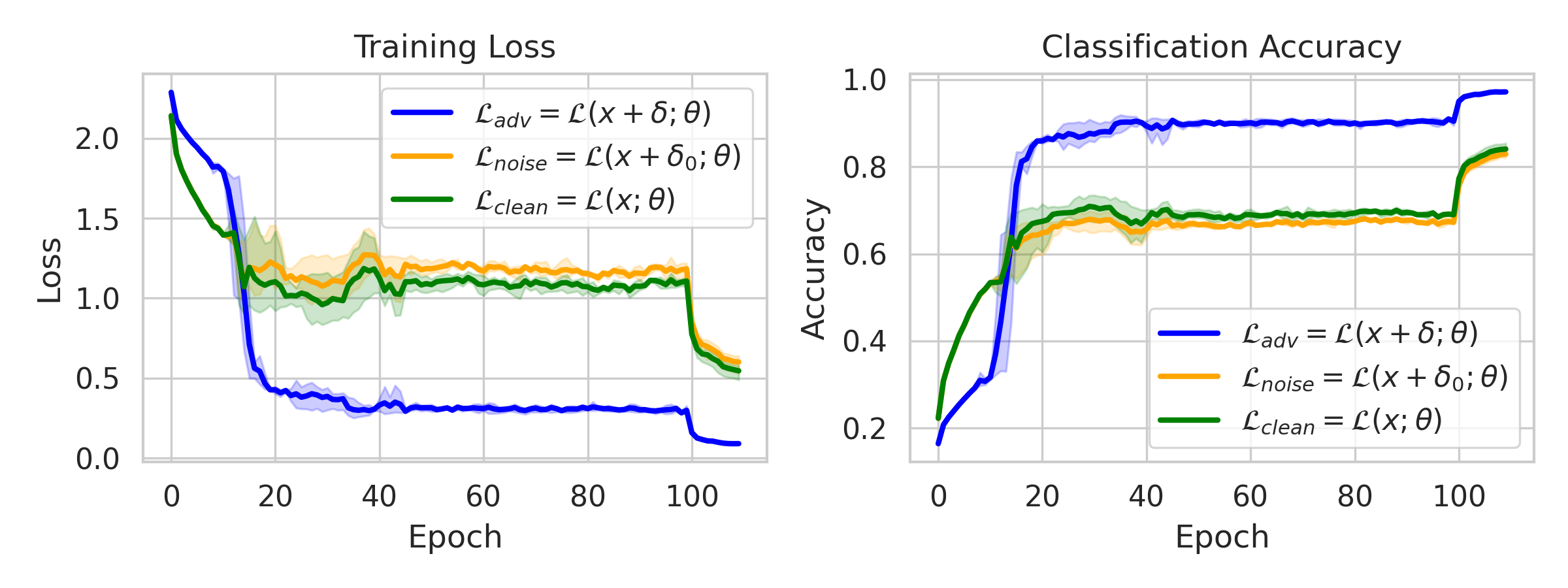
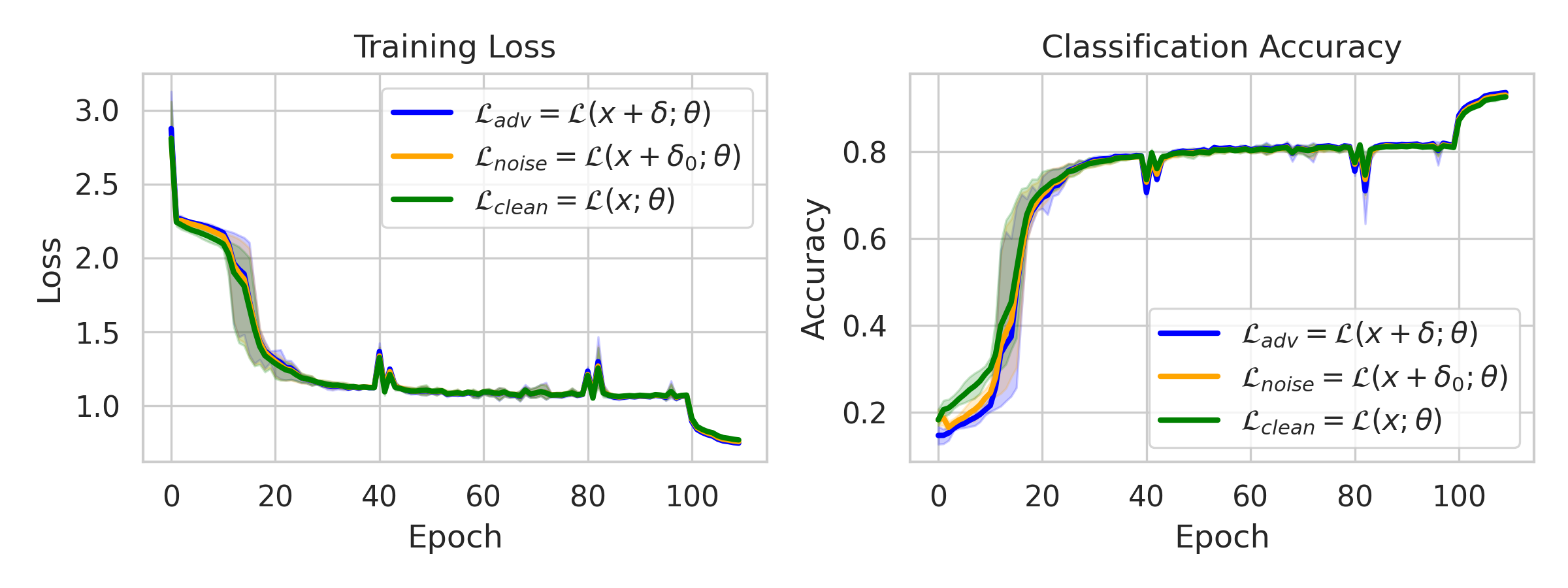
Figure 5: Training dynamics of FAT methods reveal abrupt onset of CO and its suppression via the proposed strategies.
Ablation studies show that naive ℓ2 regularization or simple weight clipping are inadequate, emphasizing the necessity of tailored weight outlier suppression.
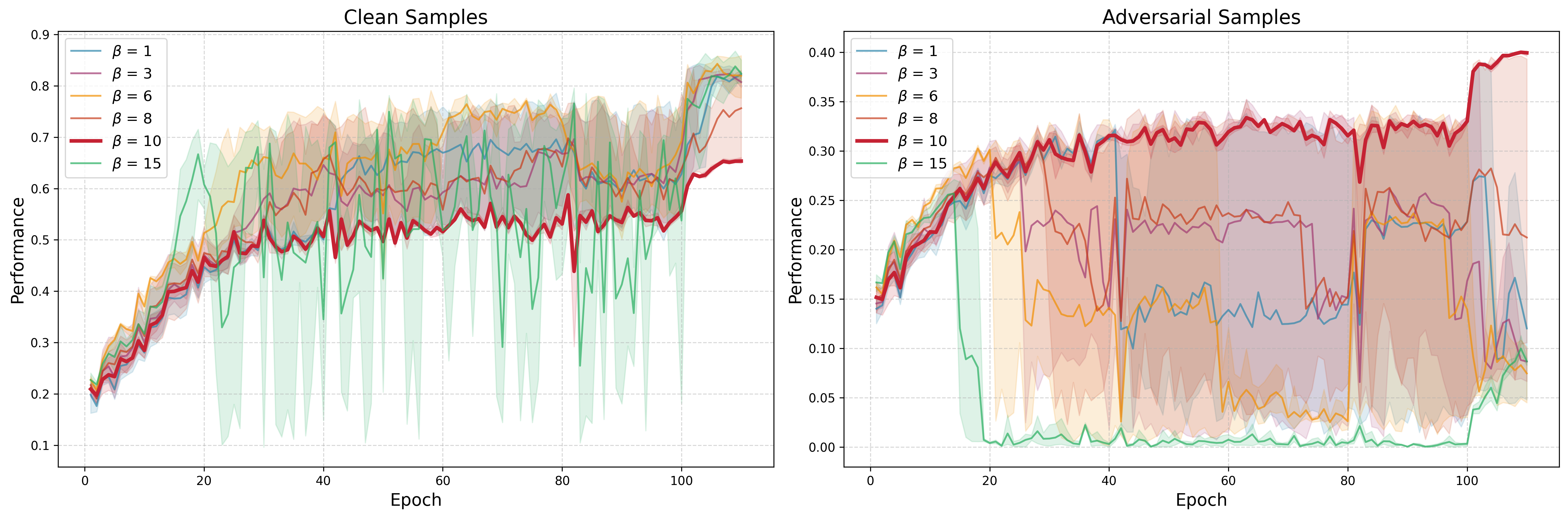
Figure 6: Ablation studies on the hyperparameter β reveal its critical impact on balancing suppression of weight outliers and maintaining model performance.
Single-Step vs. Multi-Step Adversarial Training
The analysis extends to comparative studies between FGSM-based (single-step) and PGD-based (multi-step) adversarial training. FGSM-based approaches restrict adversarial direction diversity, leading to CO and uniform prediction behavior on intra-class adversarial examples. In contrast, PGD identifies semantically coherent adversarial directions, preventing CO.
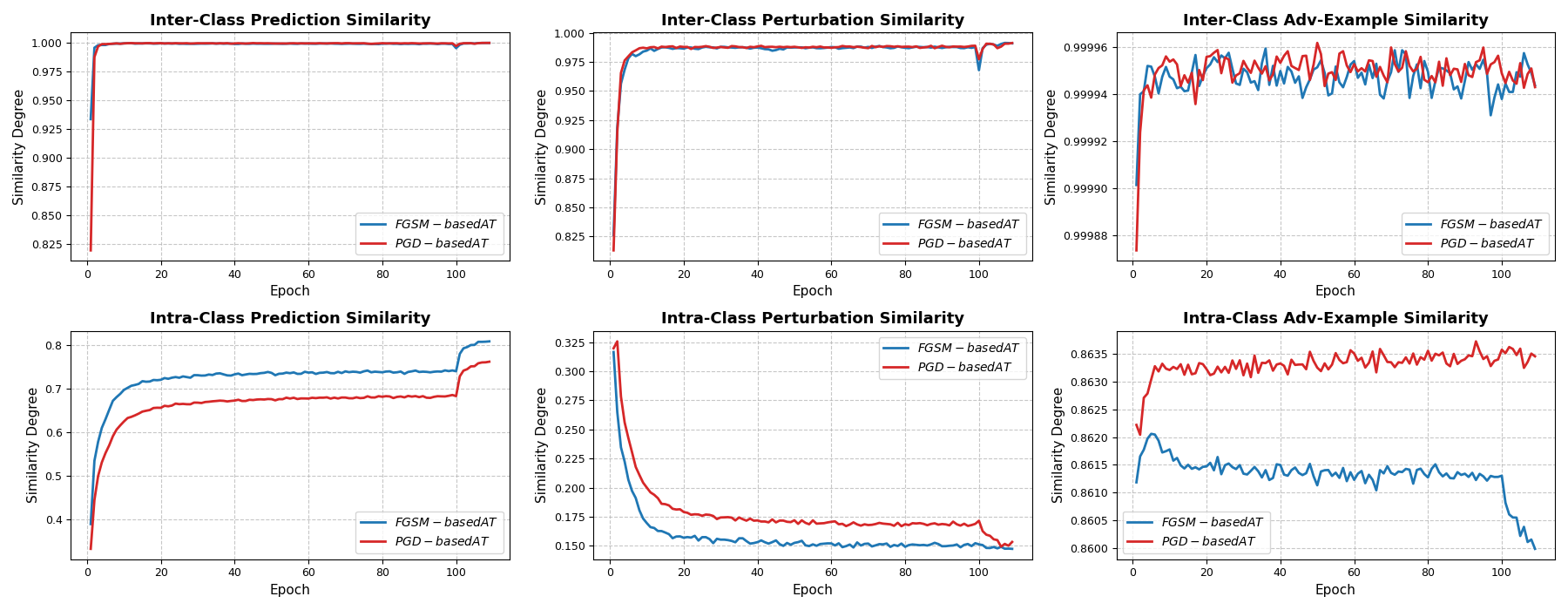
Figure 7: Comparison between FGSM-based AT and PGD-based AT highlights the uniqueness of CO in single-step settings.
Transferability and Implications
Backdoor-inspired techniques designed for CO are shown to generalize to class-wise unlearnable tasks under moderate perturbation budgets, providing robust defense at a lower computational cost than adversarial training. However, under extreme perturbations, effectiveness diminishes as weight anomalies no longer correlate with label-perturbation association.
Theoretical implications solidify trigger overfitting as a unifying theme underlying CO, backdoor attacks, and unlearnable tasks. Practical implications suggest that regularized weight distributions should be a core design criterion for robust FAT.
Conclusion
This paper presents a principled, unified theoretical framework for understanding and mitigating catastrophic overfitting in fast adversarial training, rooted in backdoor mechanisms and trigger overfitting. Through rigorous behavioral and weight-space analyses, it provides actionable mitigation strategies and bridges the gap between CO, backdoor attacks, and unlearnable tasks.
Future directions include explicit extraction and manipulation of UCD triggers for more precise control of robustness-accuracy trade-offs and extending trigger-based analyses to other adversarial attack paradigms. The study foregrounds the importance of weight-space regularization and path decomposition for stable and effective adversarial defenses in neural networks.