- The paper's main contribution is introducing Distribution-aware Dynamic Guidance (DDG) that dynamically allocates per-sample perturbation budgets to reduce error amplification and catastrophic overfitting.
- It systematically analyzes group-wise confidence levels to demonstrate that low-confidence samples drive both the robustness–accuracy trade-off and overfitting, supported by detailed ablation studies.
- Experimental results on CIFAR-10, CIFAR-100, and Tiny-ImageNet confirm that DDG enhances adversarial robustness and clean accuracy while maintaining computational efficiency.
Mitigating Error Amplification in Fast Adversarial Training: An Authoritative Technical Essay
Introduction and Motivation
Fast Adversarial Training (FAT) provides computationally efficient adversarial robustness improvements by employing single-step attacks (notably FGSM-RS), but it suffers from catastrophic overfitting (CO)—a phenomenon wherein the model becomes highly specialized to the training attack, failing to generalize to unseen perturbations. Another core challenge is the robustness–accuracy trade-off: robustness gains often come at the expense of performance on clean inputs, a problem exacerbated by increased perturbation budgets.
This paper offers a systematic group-wise analysis revealing that low-confidence (frequently misclassified) samples are the principal drivers of both CO and the robustness–accuracy trade-off. Uniform adversarial guidance across all samples amplifies error reinforcement, leading to unstable optimization and spurious feature dependency. The authors propose Distribution-aware Dynamic Guidance (DDG), which dynamically modulates perturbation budgets and supervisory signals per input to anchor training around semantically meaningful boundaries and suppress error propagation.
Systematic Analysis of Guidance Strength
The paper introduces a fine-grained batch-wise confidence partitioning and demonstrates via extensive ablations that the destabilizing effect of large perturbations is concentrated in low-confidence samples. High-confidence samples exhibit resilience against increased perturbation budgets, while low-confidence samples are susceptible to CO upon exposure to strong adversarial guidance.
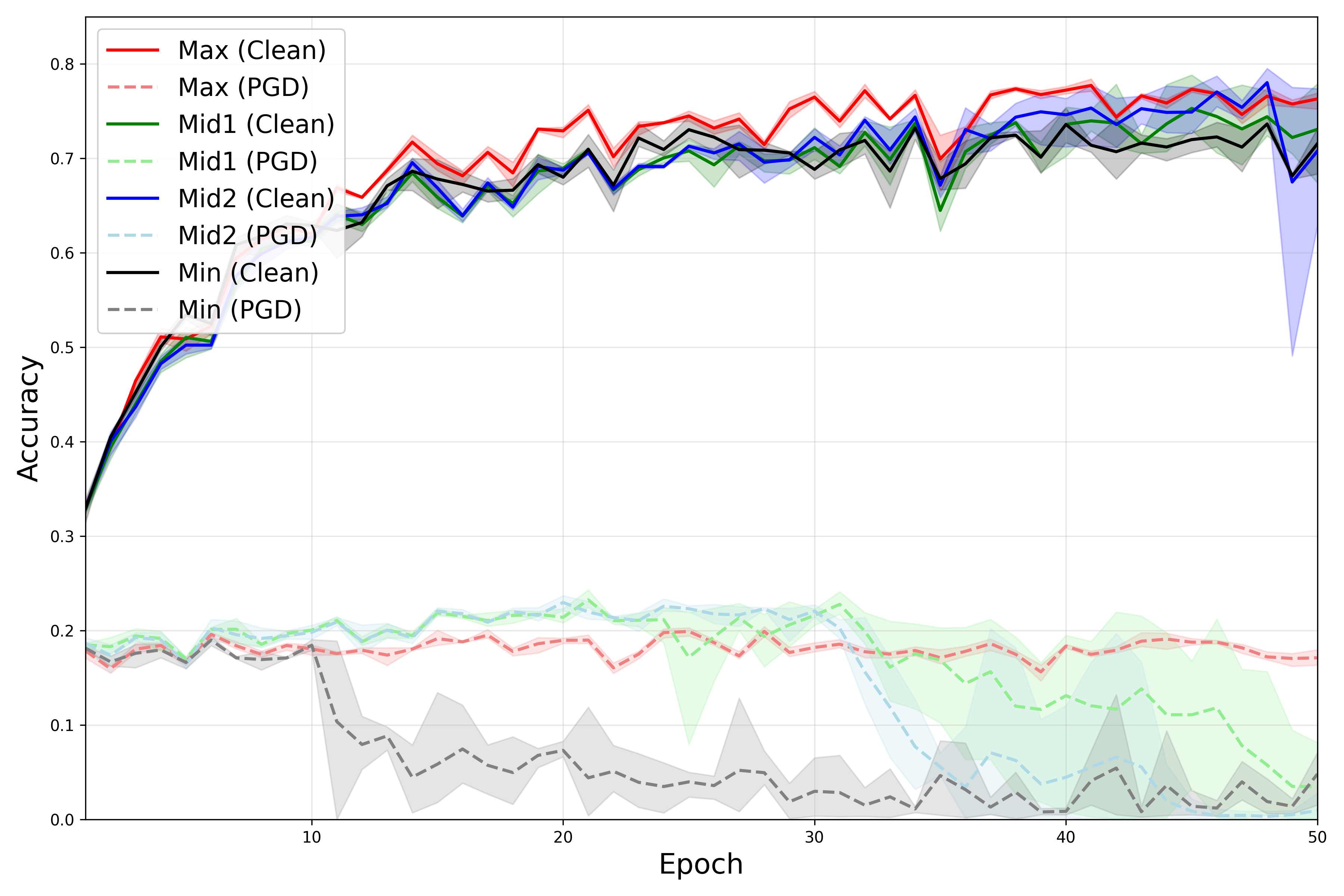
Figure 1: CO analysis highlights group-wise susceptibility, with low-confidence samples being highly vulnerable to error amplification.
Subsequent trade-off analyses with perturbation budget modulation across 32 confidence groups corroborate that reducing adversarial pressure on misclassified samples yields measurable improvements: clean accuracy gains (+1.06), PGD robustness (+0.47), and C&W robustness (+0.41) are achieved via budget reduction for the lowest-confidence group. Conversely, increasing budget for high-confidence samples marginally enhances robustness but can degrade clean accuracy.
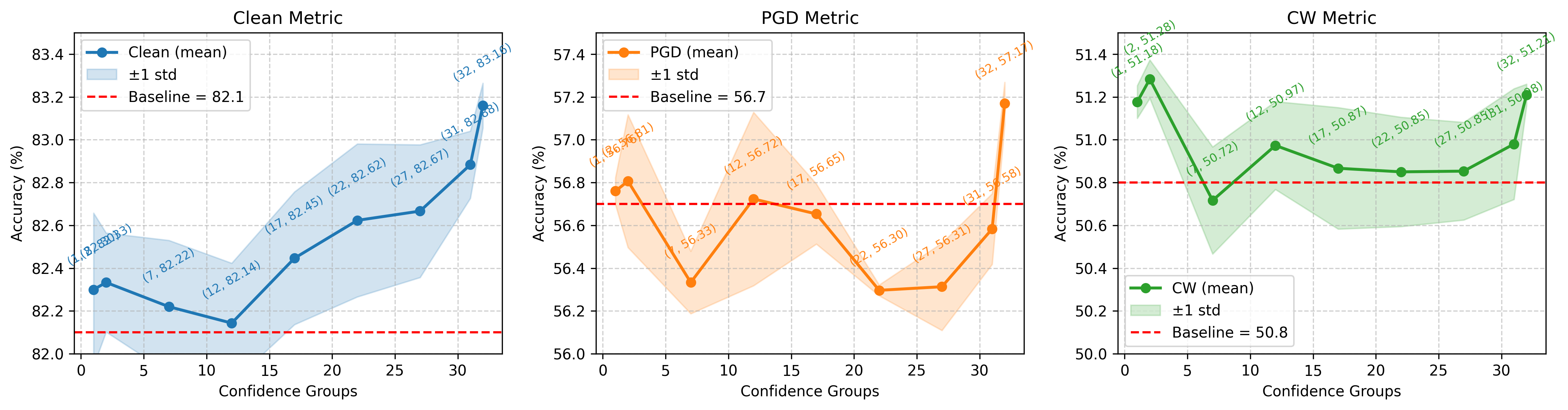
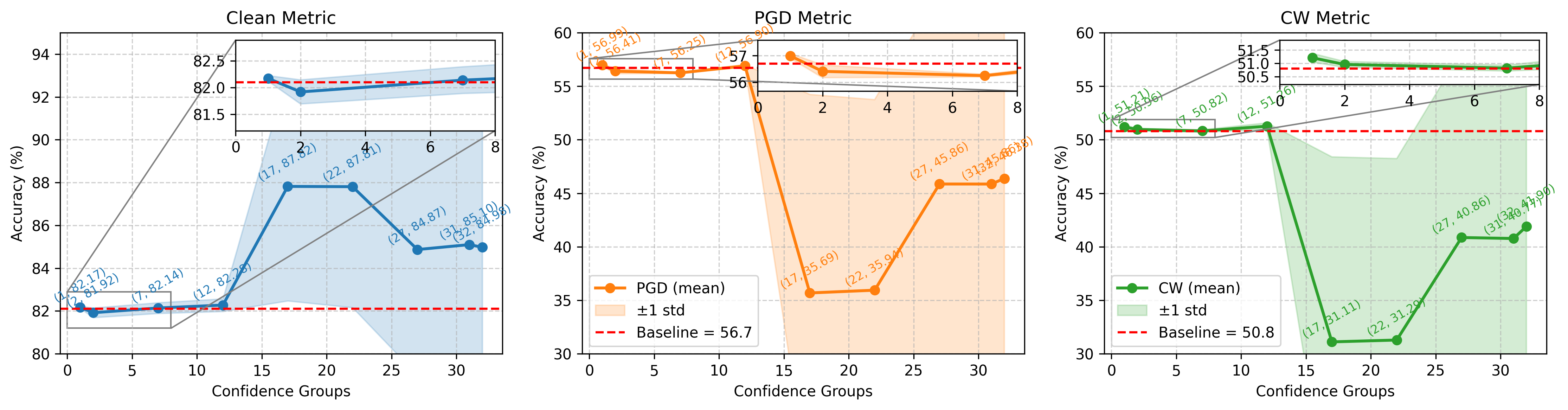
Figure 2: Modulating perturbation budgets for descending confidence groups demonstrates clean-robustness trade-off characteristics.
Further ablation of supervision signal strength via label relaxation confirms that error mitigation for low-confidence samples substantially improves both clean and adversarial accuracies (+1.18/+1.40 for clean/PGD). However, excessive relaxation for mid-confidence samples destabilizes training due to rapidly fluctuating group membership.
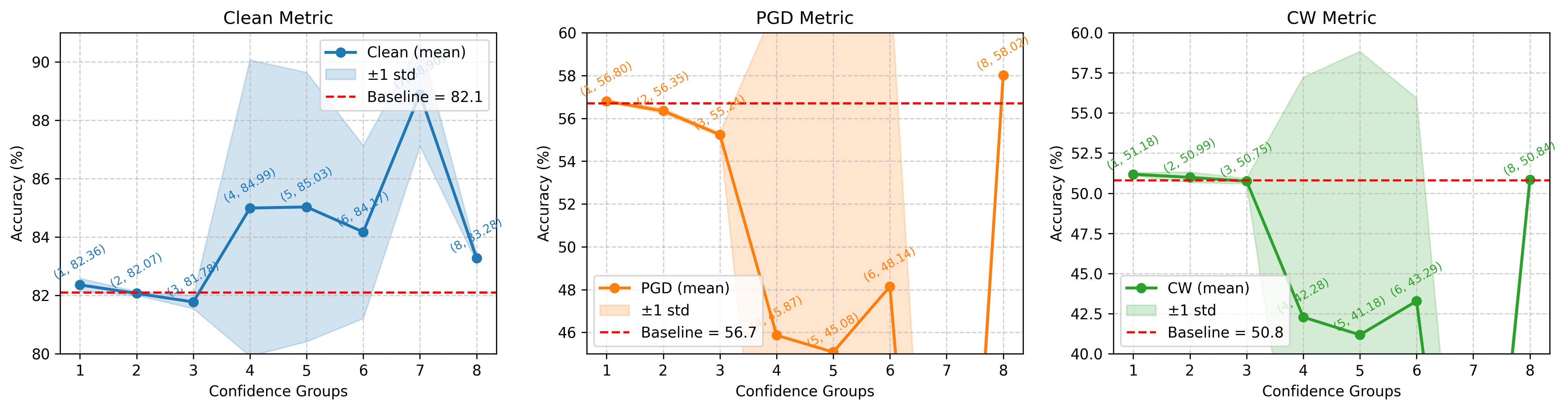
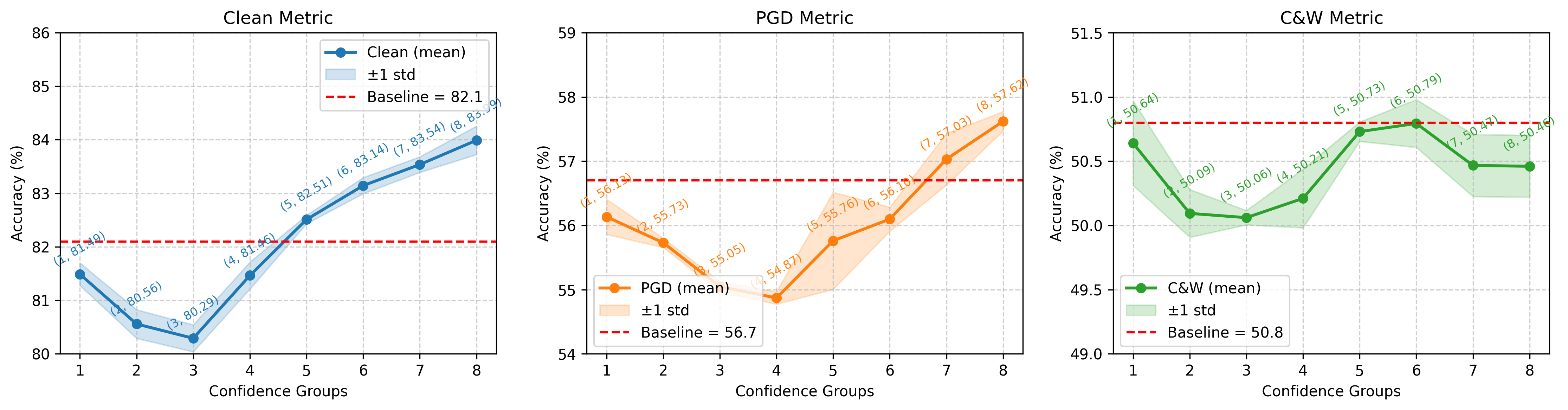
Figure 3: Supervision strength ablation visualizes the delicate interplay between label relaxation, prediction stability, and robust generalization.
Distribution-aware Dynamic Guidance (DDG)
The DDG framework assigns per-sample, confidence-ranked perturbation budgets via:
ξi=ξbase+κ[tanh(ri−τ1)−tanh(τ2−ri)]
This allocates stronger perturbations to high-confidence samples and reduced budgets to low-confidence samples, preventing reinforcement of spurious correlations in unstable regions. The adversarial input generation incorporates history-based initialization and a minimum step-size floor for numerical stability.
Supervisory signals are dynamically modulated:
- For correctly predicted samples, vanilla soft guidance is applied.
- For misclassified samples, positive class reinforcement decays with batch accuracy, and negative class suppression inversely scales with class cardinality.
A smoothing regularization term balances gradient instability induced by dynamic guidance, enforcing batch-wise prediction consistency and penalizing misclassified examples.
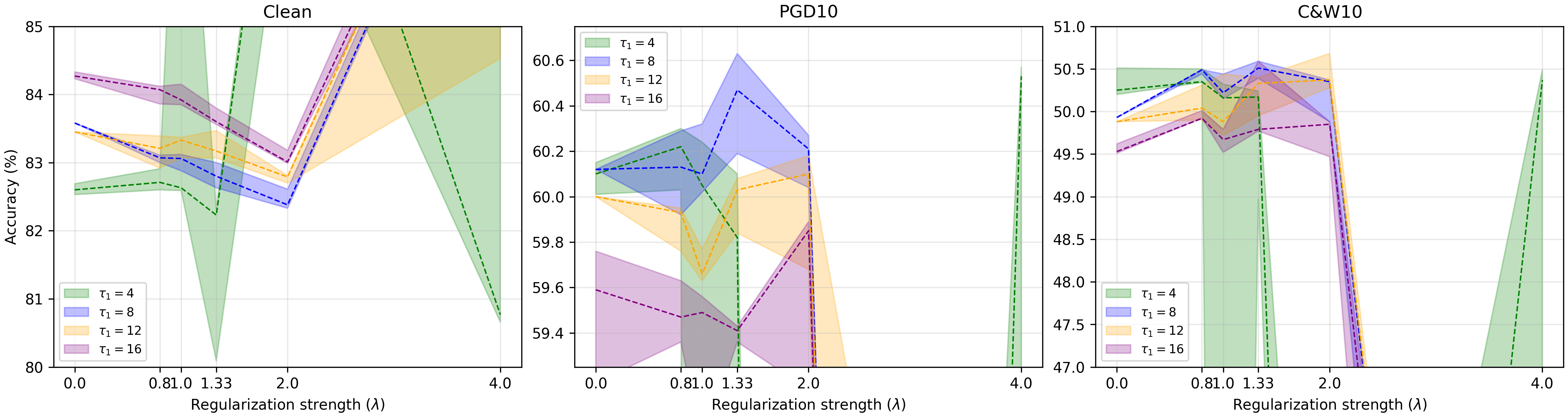
Figure 4: Impact of τ1 hyperparameter tuning on DDG performance as a function of the confidence transition region.
Experimental Results and Ablation Analysis
On CIFAR-10, DDG achieves superior robustness (FGSM: 68.44%, PGD-10: 60.44%, APGD: 59.48%) while maintaining competitive clean accuracy (82.67%), outperforming both single-step and multi-step SOTA methods. Final checkpoint stability matches best-epoch robustness, indicating successful mitigation of robust overfitting—DDG's differentiation from previous works such as TDAT, FGSM-PGK, and FGSM-PGI is quantitatively substantiated.
On CIFAR-100, DDG yields robustness improvements (FGSM: 40.96%, PGD-10: 34.32%, clean: 57.98%), again dominating SOTA baselines. On Tiny-ImageNet, DDG achieves optimal adversarial accuracy (BIM: 24.30%, PGD-10: 24.35%, APGD: 23.85%) with competitive clean scores, demonstrating scalability and generalization.
Ablation studies detail the contributions of perturbation budget allocation (PBA), supervision signal adjustment (SSA), and gradient smoothing (GS), with full DDG attaining the best robustness–accuracy balance. Scaling experiments on positive and negative label adjustments in ysr show clean and PGD gains with only minor losses under specialized attacks (C&W).
Hyperparameter analysis indicates that increasing τ1 yields higher clean accuracy but diminished robustness, while increasing λ enhances robustness but reduces clean accuracy—the overall variational window remains modest.
Practical and Theoretical Implications
DDG delivers an efficient, scalable framework capable of mitigating error amplification and overfitting in FAT, fostering robust generalization with negligible computational overhead relative to multi-step AT. Its per-sample adjustment mechanism parallels curriculum-based learning and granularity-aware defense, and the paradigm may inform future work on adversarial training for other domains (e.g., vision transformers, multimodal contrastive learning). The group-wise confidence-guided approach addresses the central limitation of uniform adversarial guidance, offering a principled method for balancing robustness and accuracy.
DDG's architecture-agnostic methodology, reliance on prediction-state statistics, and dynamic parameter modulation position it as a strong candidate for robust model deployment in high-stakes and security-critical environments. Further theoretical exploration into the links between prediction confidence, perturbation sensitivity, and error propagation may catalyze advancements in robust optimization and generalization theory.
Conclusion
The paper presents Distribution-aware Dynamic Guidance (DDG) as a principled approach to mitigating catastrophic overfitting and the robustness–accuracy trade-off in fast adversarial training. Systematic empirical analysis and dynamic per-sample budget allocation combined with adaptive supervision and regularization yield substantial improvements across standard benchmarks. DDG's insights and methodologies have promising implications for the design of more robust, efficient adversarial training systems in future deep learning research (2604.24332).