- The paper introduces POCA which uses bi-directional Pareto sorting to filter optimal samples and avoid ambiguous reward gradients.
- The methodology leverages adaptive curriculum planning by partitioning prompts using OCR-based ECDF scores to dynamically adjust sample difficulty.
- Experimental results on the AnyText benchmark demonstrate POCA's superior text accuracy, image coherence, and data efficiency compared to state-of-the-art models.
Pareto-Optimal Curriculum Alignment for Visual Text Generation: An Expert Analysis
Introduction and Motivation
Visual text generation faces an intrinsic challenge: the tension between maximizing textual accuracy and maintaining overall image coherence and aesthetic quality. Empirical observations indicate that current models, especially those utilizing auxiliary conditions such as glyph and positional cues, are unable to balance these conflicting objectives effectively, leading to diminished prompt-following and visual quality (Figure 1).

Figure 1: Illustration of the trade-off between image coherence and textual accuracy. The text generation model exhibits deficits in prompt-following and aesthetic appeal when aiming for high text fidelity.
Recent advances attempting to mitigate this issue, particularly using RL-based post-training methods (e.g., GRPO), rely on multi-reward optimization via weighted-sum aggregation. However, this approach introduces instability due to inconsistent reward signals, especially in environments with conflicting reward objectives such as OCR (text accuracy) and CLIP (text-image alignment) (Figure 2). The weighted-sum aggregation yields ambiguous gradients, causing suboptimal convergence.
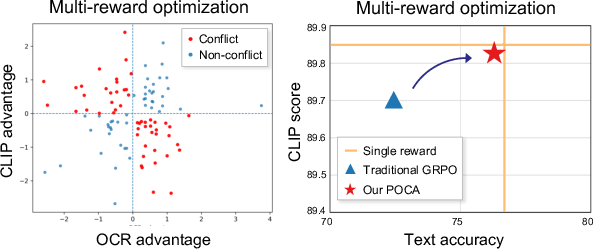
Figure 2: GRPO-based training suffers from conflicting reward signals among samples, leading to instability and suboptimal results in multi-reward optimization.
The second operational challenge is data efficiency in RL. Large prompt datasets foster generalization but escalate computational requirements, while small sets provide inadequate coverage and weak signal diversity. Existing approaches lack principled mechanisms for prompt selection driven by both reward structure and model progression.
POCA Framework
The paper proposes POCA—a unified framework integrating bi-directional Pareto-optimal sample selection and adaptive curriculum alignment—for robust multi-reward optimization in visual text generation. POCA consists of two synergistic components:
- Bi-directional Pareto Sorting: Instead of scalarizing rewards, POCA identifies both non-dominated (positively optimal) and fully dominated (negatively optimal) samples within the joint reward space. Only the Pareto set is used for policy updates, discarding ambiguous signals and achieving clean reward alignment.
- Adaptive Curriculum Planning: Model progression through the dataset is orchestrated via difficulty-aware scheduling. Prompt difficulty is quantified using ECDF normalization over mean OCR scores—selected based on its high variance and discriminative value. The scheduler partitions data into easy, medium, and hard bins, implementing an easy-to-hard progression tightly coupled to current model capabilities.
POCA operates in a staged manner: curriculum planning determines the learning sequence, feeding into training where bi-directional Pareto sorting filters the optimal samples for GRPO-based policy optimization (Figure 3).
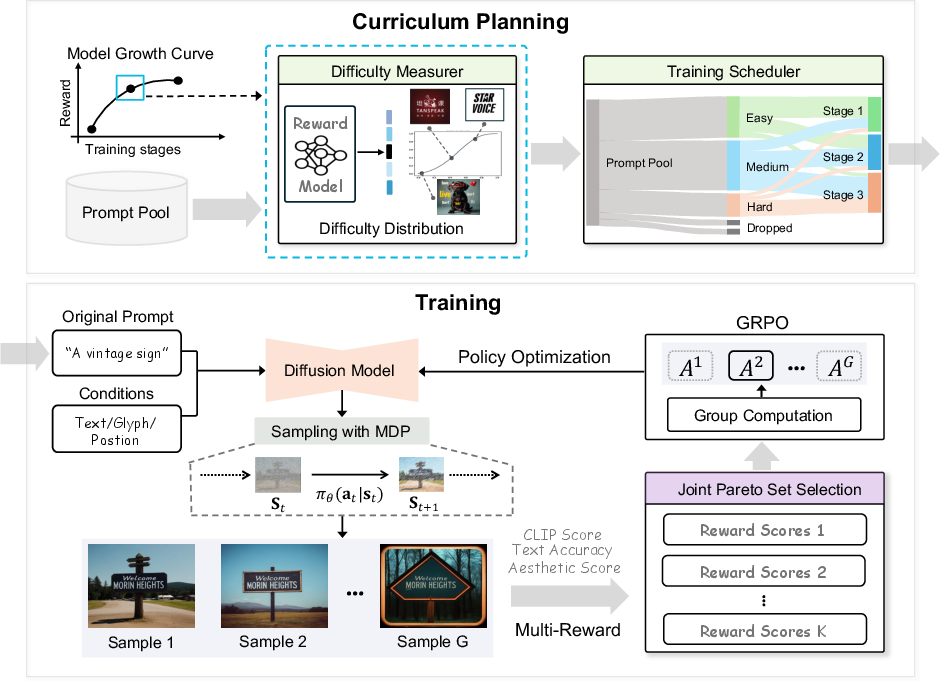
Figure 3: POCA workflow: Curriculum Planning organizes prompts from easy to hard, followed by bi-directional Pareto sorting in the Training stage for Pareto-set based optimization.
Algorithmic Details
Bi-directional Pareto Sorting leverages the dominance relationship across K reward dimensions: a sample is non-dominated if no other sample outperforms it across all rewards, and fully dominated if it is outperformed in all rewards. Both sets are used for positive and negative credit assignment in policy updates, ensuring maximal Pareto-front coverage and penalizing poor trade-offs.
Analyses show that the bi-directional approach outperforms both one-directional (non-dominated only) and fully dominated-only sorting in expanding the global Pareto frontier and higher likelihood for optimal solutions (Figure 4, Figure 5).
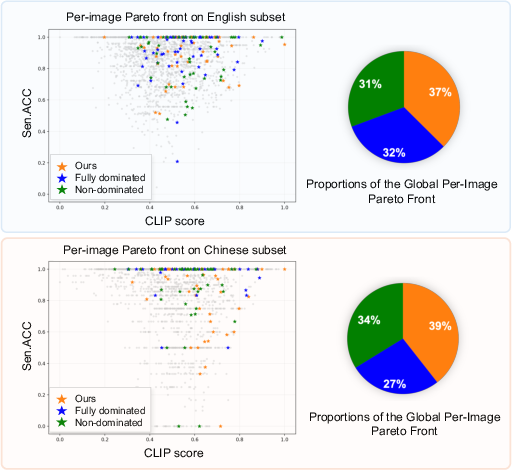
Figure 4: Fraction of globally non-dominated solutions contributed by each method, with bi-directional Pareto sorting yielding maximal coverage of the Pareto front.
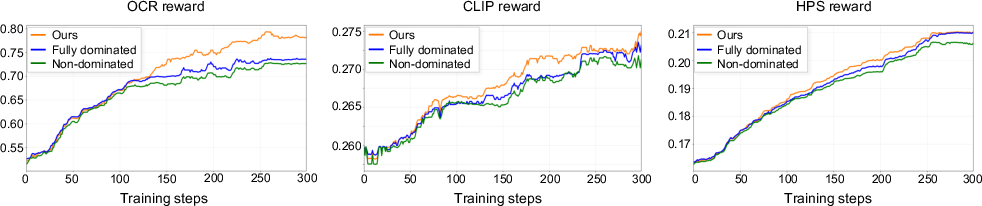
Figure 5: Reward curves for Pareto selection algorithms; bi-directional sorting secures consistently higher reward performance across metrics.
Adaptive Curriculum utilizes the OCR reward as a difficulty metric given its substantial range and variance (Figure 6). Training stages dynamically adjust the proportion of easy, medium, and hard samples, guided by percentile thresholds of ECDF values, minimizing both trivial and intractable samples to accelerate optimal convergence.
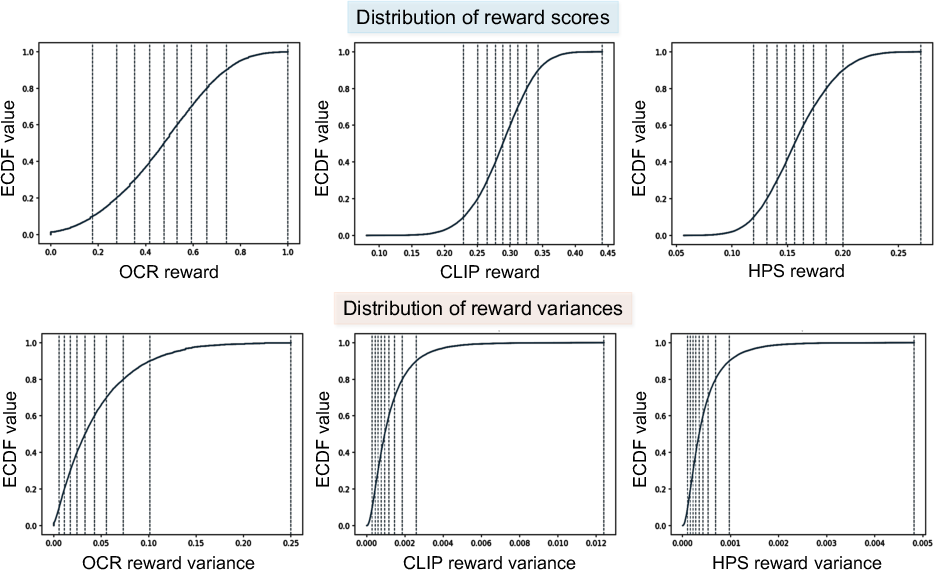
Figure 6: ECDFs for OCR, CLIP, and HPS rewards illustrate that OCR provides greater inter-percentile variance, supporting its utility as a difficulty measure.
Experimental Results
Quantitative Evaluation: On the AnyText benchmark, POCA consistently surpasses state-of-the-art models, including AnyText2 and GRPO baselines, in Sen.ACC, CLIP, and HPS metrics. Ablation studies confirm POCA's superior data efficiency: models trained on 1k samples with POCA achieve comparable performance to Pareto-guided GRPO trained on 10k samples, evidencing strong data scalability.
Qualitative Analysis: POCA delivers more faithful instruction-following and yields visually coherent outputs across both English and Chinese prompts (Figure 7, Figure 8, Figure 9, Figure 10, Figure 11).

Figure 7: POCA achieves superior text accuracy, image alignment, and aesthetics compared to baselines on AnyText-benchmark.

Figure 8: POCA demonstrates enhanced performance on complex prompts, handling fine-grained instructions and aesthetic requirements.
A human preference study confirms POCA's advantage in text accuracy, prompt compliance, and visual appeal (Figure 12).
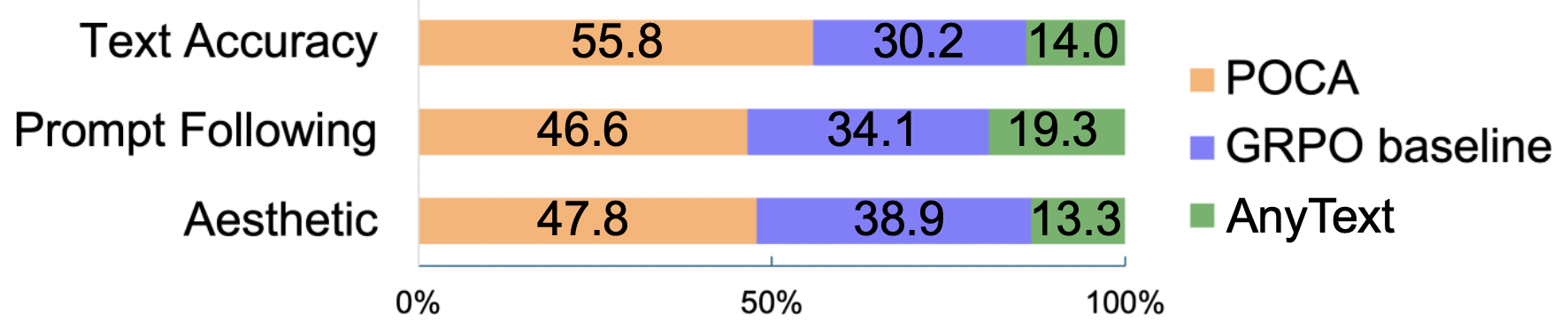
Figure 12: Human study preference win rates; POCA outperforms AnyText and GRPO baselines in all categories.
Additional visualizations reinforce that POCA maintains image coherence and semantic alignment even under complex prompt requirements (Figure 9, Figure 10, Figure 11).
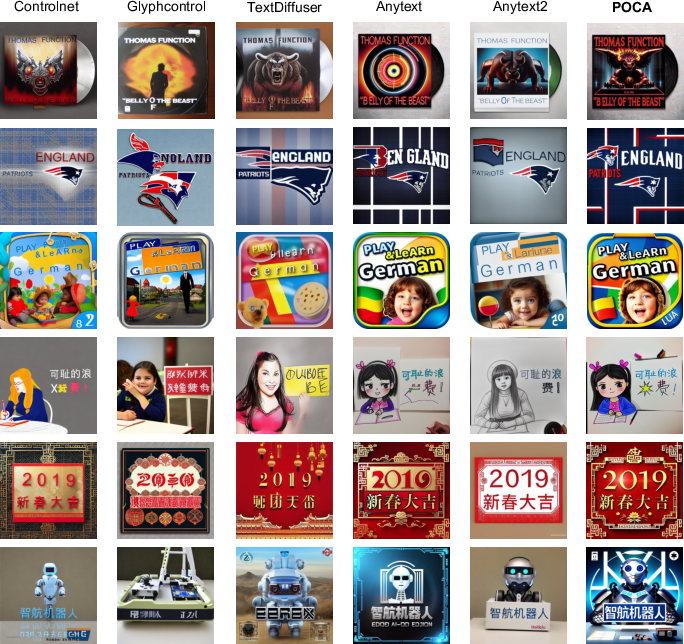
Figure 9: POCA achieves a balanced compromise between text accuracy, coherence, and aesthetics, outperforming SOTA baselines.
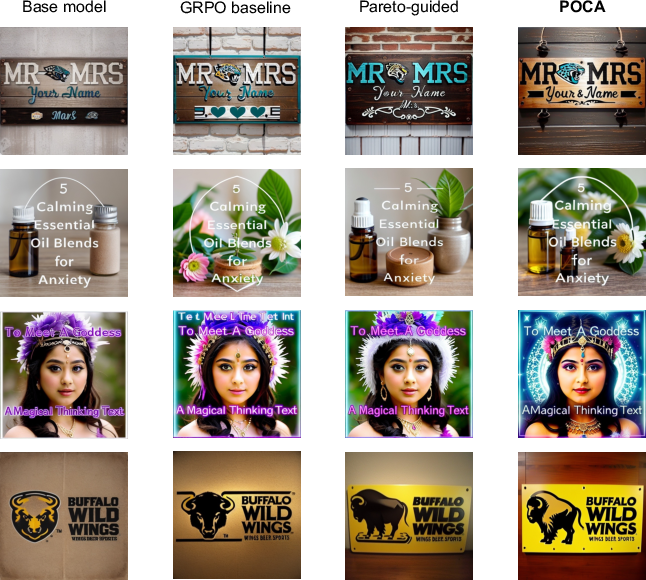
Figure 10: GRPO baseline yields visually unbalanced images under conflicting rewards, while POCA maintains semantic and aesthetic fidelity.

Figure 11: POCA outperforms baselines in complex instruction-following, achieving higher control over fine-grained details.
Comparative Analysis and Scalability
POCA effectively generalizes to larger diffusion models (e.g., Glyph-SDXL-v2), with Pareto-guided curriculum learning yielding performance gains across all metrics. Comparisons with RPO (harmonic mean aggregation), Curriculum-DPO, and other multi-reward RL frameworks confirm POCA's superiority, especially on text accuracy and multi-metric alignment.
Implications and Future Directions
Practically, POCA enables efficient policy alignment in visual text generation under conflicting reward objectives, circumventing the limitations of naive reward scalarization and costly brute-force prompt sampling. Theoretically, the bi-directional Pareto-guided approach paves the way for general multi-objective RL in generative pipelines, expanding the scope of curriculum learning from human-specified to reward-driven, difficulty-adaptive training. The integration of dynamic curriculum with RL may be extended to reinforcement learning from human feedback (RLHF) in multimodal LLMs, and scalable alignment in complex domain adaptation scenarios.
Future developments may focus on:
- Extending bi-directional Pareto sorting to higher-dimensional reward spaces and more granular sub-objective selection.
- Incorporating active learning for curriculum scheduling, leveraging sample informativeness for reward exploration.
- Generalizing POCA to video/text generation and cross-modal generative instruction tuning, where reward signals become more diverse and potentially more contradictory.
Conclusion
POCA delivers principled, efficient multi-reward optimization for visual text generation, leveraging bi-directional Pareto-optimal sample selection and adaptive curriculum planning to resolve instability and inefficiency in conflicting reward scenarios. The framework demonstrates improved convergence, superior balance across reward metrics, and robust data efficiency, with strong performance in both quantitative and qualitative benchmarks. POCA is a scalable and generalizable approach for multi-objective RL in generative models, with future potential in multimodal alignment and complex reward-driven curriculum strategies.

