- The paper presents SPARD, a framework that fuses progress-aware reward adaptation (PAWA) and reward-attributed data rebalancing (RADR) to optimize multi-objective RL alignment.
- The paper demonstrates improved convergence and stability across diverse domains, including creative writing, code generation, and chat, by dynamically prioritizing objectives.
- The paper validates SPARD’s efficacy through rigorous empirical evaluations, showing significant performance gains over traditional static aggregation methods.
SPARD: Self-Paced Curriculum for RL Alignment via Integrating Reward Dynamics and Data Utility
Motivation for Dynamic Multi-Reward RL Alignment
The post-training phase of LLM development has shifted focus from single, verifiable tasks to complex, open-ended real-world scenarios, necessitating richer multi-objective reward formulations. The standard practice aggregates rewards from diverse dimensions—correctness, fluency, instruction adherence, creativity, etc.—into a scalar signal using fixed weights, but this ignores learning non-stationarity, asynchronous capability convergence, and data heterogeneity. Fixed reward weights drive inefficient gradient allocation, causing over-optimization in saturated dimensions and stagnation in latent bottlenecks. Furthermore, data informativeness is dimension-specific; a training batch optimizing correctness may be non-optimal for fluency or creativity.
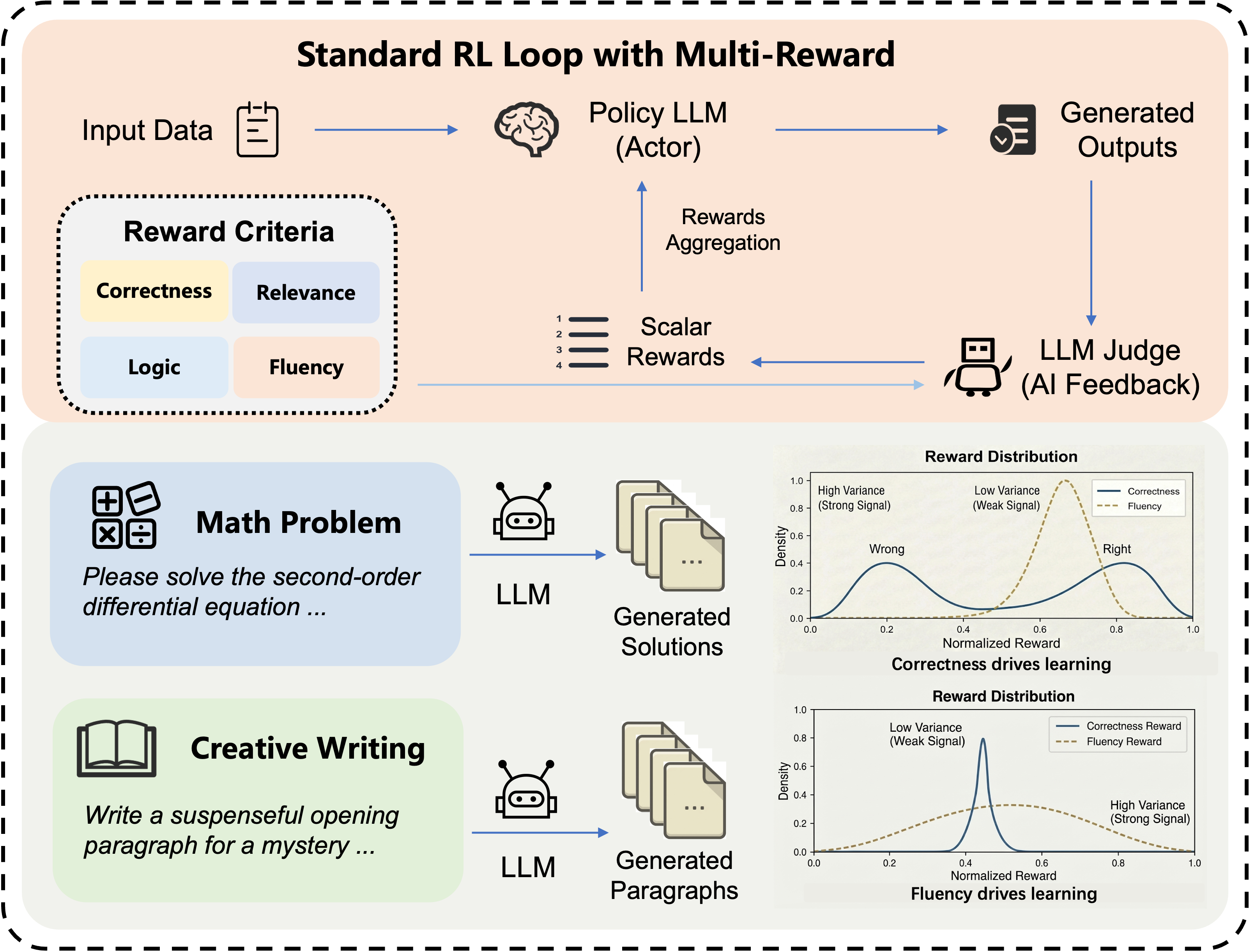
Figure 1: Schematic of the Multi-Reward RL loop and data heterogeneity; each data sample influences different reward dimensions.
Prior RL-based alignment frameworks (e.g., RaR (Gunjal et al., 23 Jul 2025), MPO (Kim et al., 28 Apr 2025), DRBO [2025.findings-emnlp.468]) either fuse reward signals using static strategies or apply dynamic prioritization solely at the reward level, neglecting data-response relationships and real-time learning progress. Curriculum learning methods such as Rubicon and Omni-Thinker (Li et al., 20 Jul 2025) address data variance via staged schedules but lack adaptive mechanisms responsive to the evolving model performance landscape.
SPARD Framework: Progress-Aware Reward and Data Scheduling
SPARD (Self-Paced Automated RL Alignment via Reward Dynamics and Data Utility Integration) is designed to synchronize the optimization trajectory with online learning progress across multiple reward dimensions and data categories. It comprises two synergistic mechanisms:
- Progress-Aware Weight Adaptation (PAWA): Dynamically updates reward weights according to reliable performance gains, computed via EMA-based statistics and LCB principles. This amplifies focus on dimensions with maximal robust acquisition, preventing over-allocation to stagnant tasks and catastrophic forgetting.
- Reward-Attributed Data Rebalancing (RADR): Realigns training sample importance by quantifying reward-data category attribution using statistical score dispersion (MAD). Data weights are iteratively adapted through temperature-controlled Boltzmann normalization and EMA smoothing, ensuring high-impact categories are prioritized for targeted objectives.
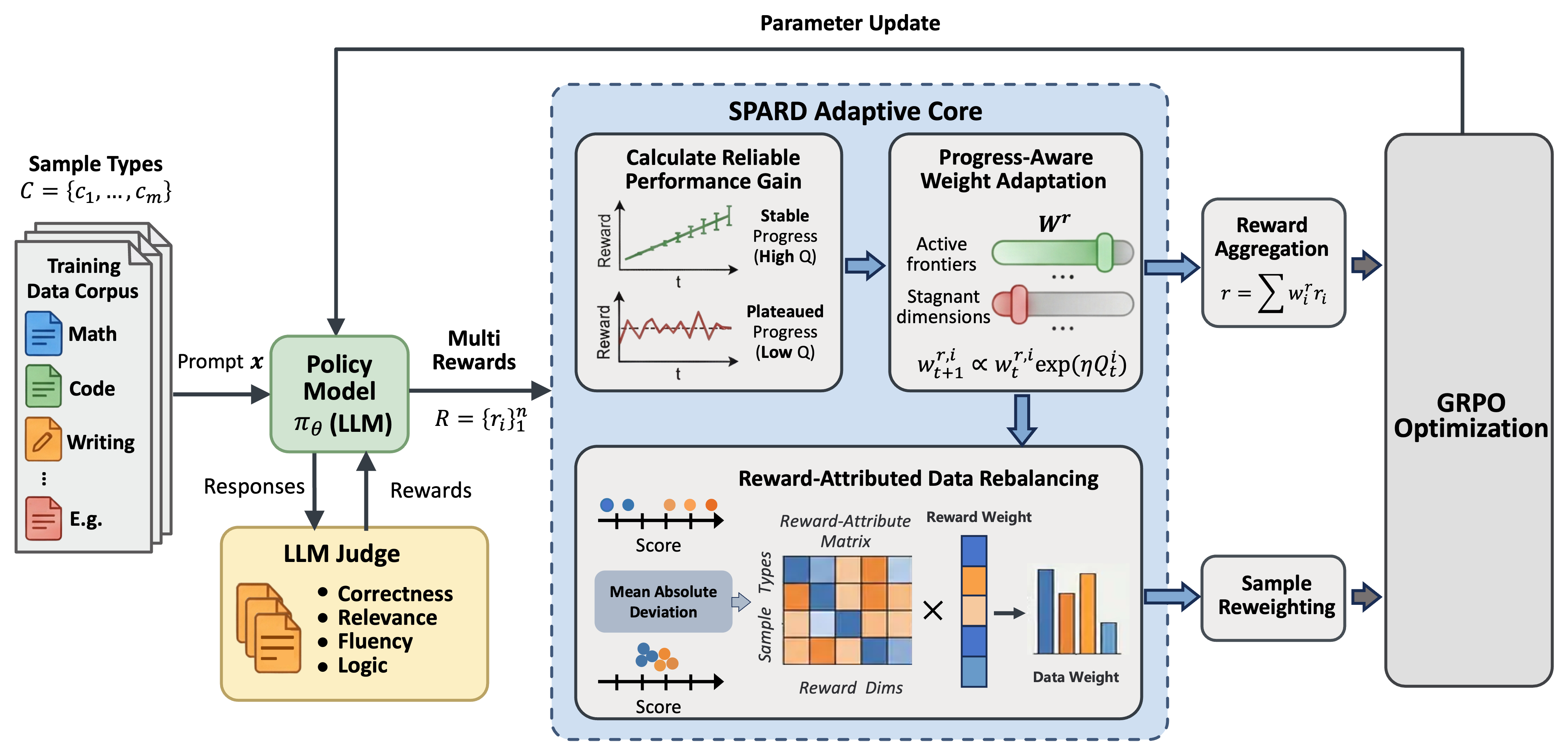
Figure 2: SPARD’s architecture, illustrating PAWA for reward weight adaptation and RADR for reward-attributed data selection.
SPARD maximizes marginal gradient utility under constrained compute, enforcing smooth optimization trajectories via KL-regularized Online Mirror Descent. The closed-form exponentiated gradient update for reward weights stabilizes rapid adaptation, harmonizing improvement across latent proficiency frontiers.
Empirical Evaluation
SPARD was evaluated on multiple scales (Qwen2.5-7B-Instruct, Qwen3-8B), training on the WildChat-IF dataset, partitioned into Creative Writing, Code Generation, Knowledge QA, and Text Transformation categories—each annotated through LLM classifiers.
Baselines: SFT, DPO, GRPO with reward model (GRPO-rm), static average aggregation (GRPO-avg), and implicit aggregation (GRPO-imp).
Benchmarks: General Capability (IFEval, GPQA, LiveCodeBench), Creative Writing (CW, Arena-Hard), Chat (WildBench, MT-Bench).
SPARD consistently delivers peak average performance across domains, outperforming both static aggregation and reward model-driven RL methods—especially in challenging, open-ended domains such as creative writing and real-world chat. GRPO-avg, while better than GRPO-rm and GRPO-imp due to transparency in optimization targets, is inferior to SPARD due to its inability to adaptively prioritize objectives in response to dynamic training progress.
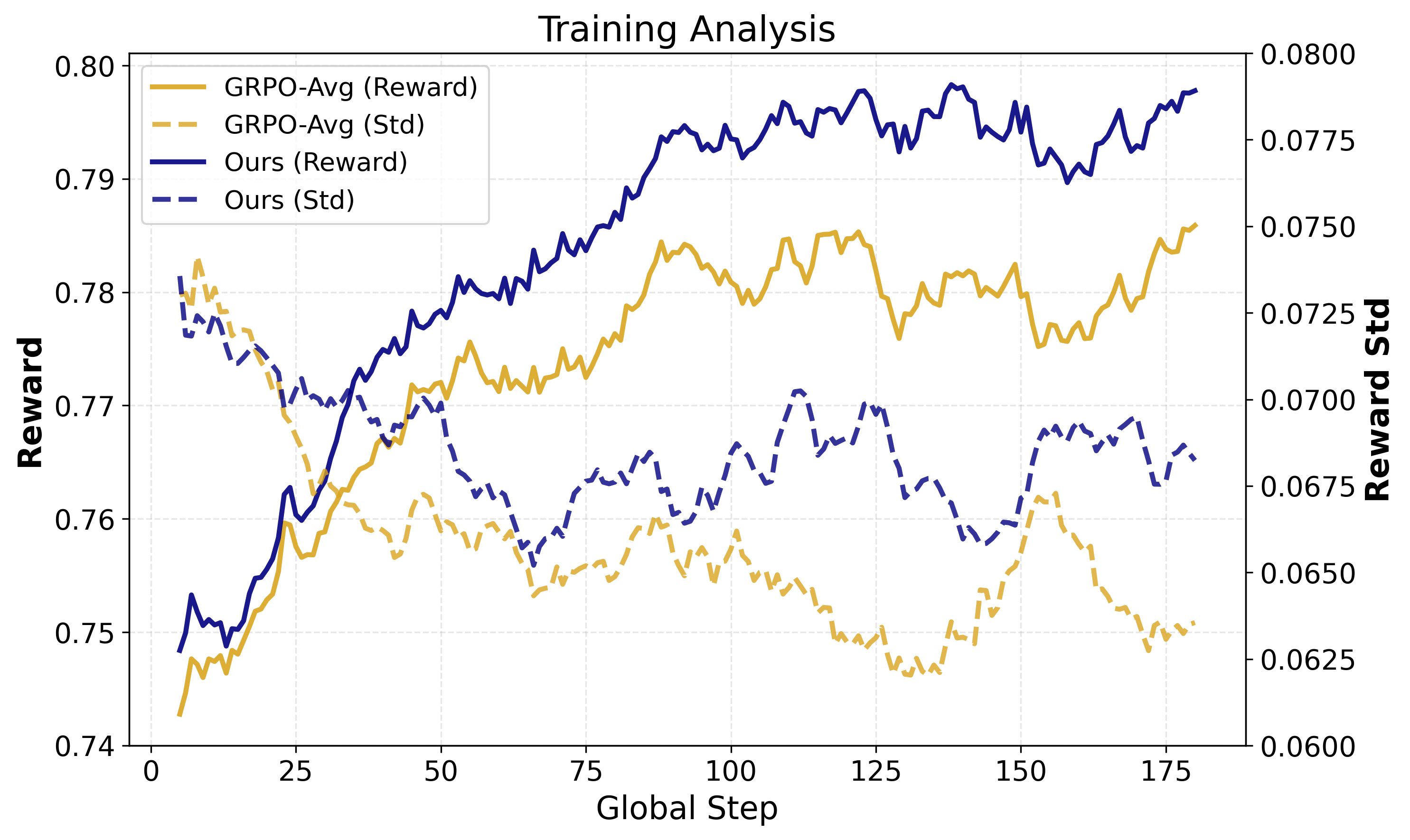
Figure 3: EMA-smoothed training trajectories for Qwen2.5-7B-Instruct under different RL alignment schemes.
SPARD achieves both faster convergence and lower variance in reward-dimensional training, indicating enhanced optimization stability and resistance to stochastic sensitivity.
Multi-Dimensional Reward Analysis
Eight reward metrics (instruction-following, correctness, fluency, detail, logic, relevance, structure, tune) are independently tracked. SPARD demonstrates pronounced gains in creative writing and chat domains while maintaining parity in verifiable instruction following and coding, confirming its ability to stimulate improvements in subjective, high-entropy tasks without sacrificing performance in deterministic ones.
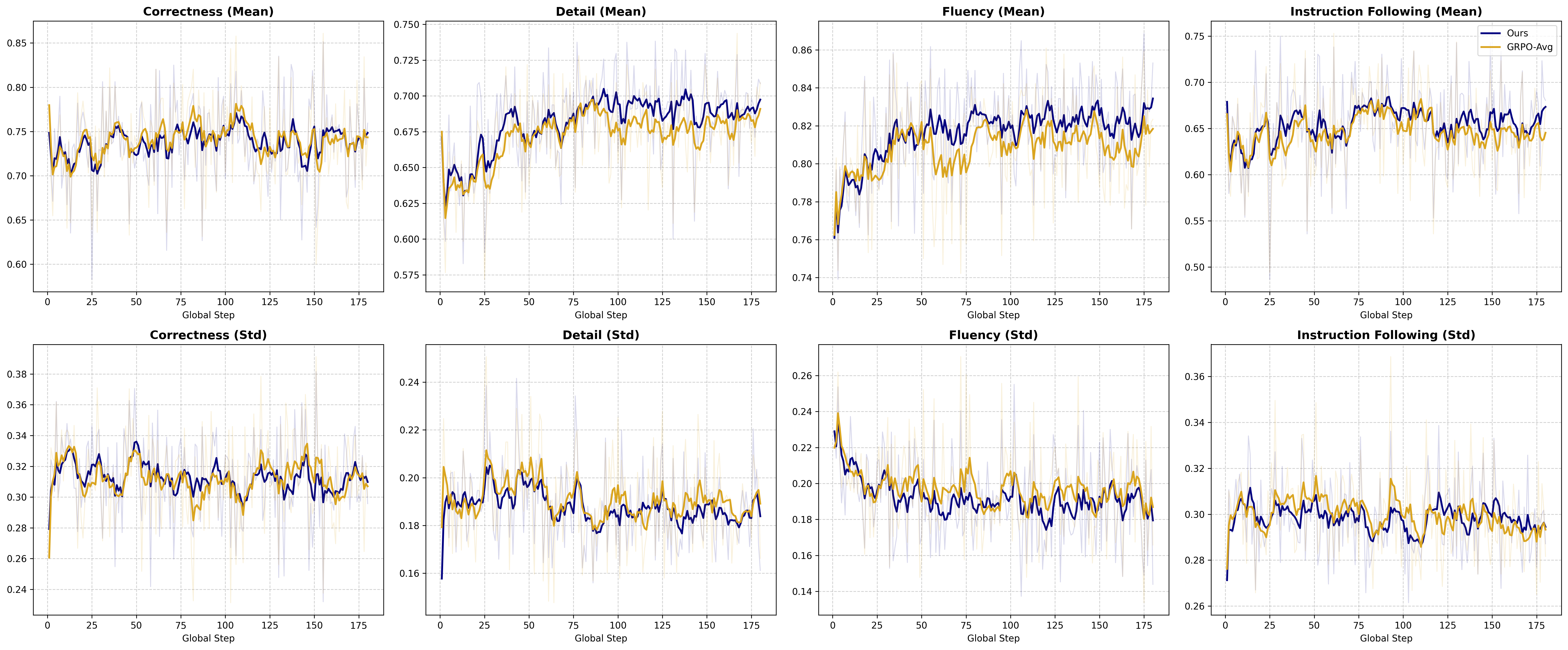
Figure 4: Reward-specific training dynamics for Correctness, Detail, Fluent, and Instruction-Following.
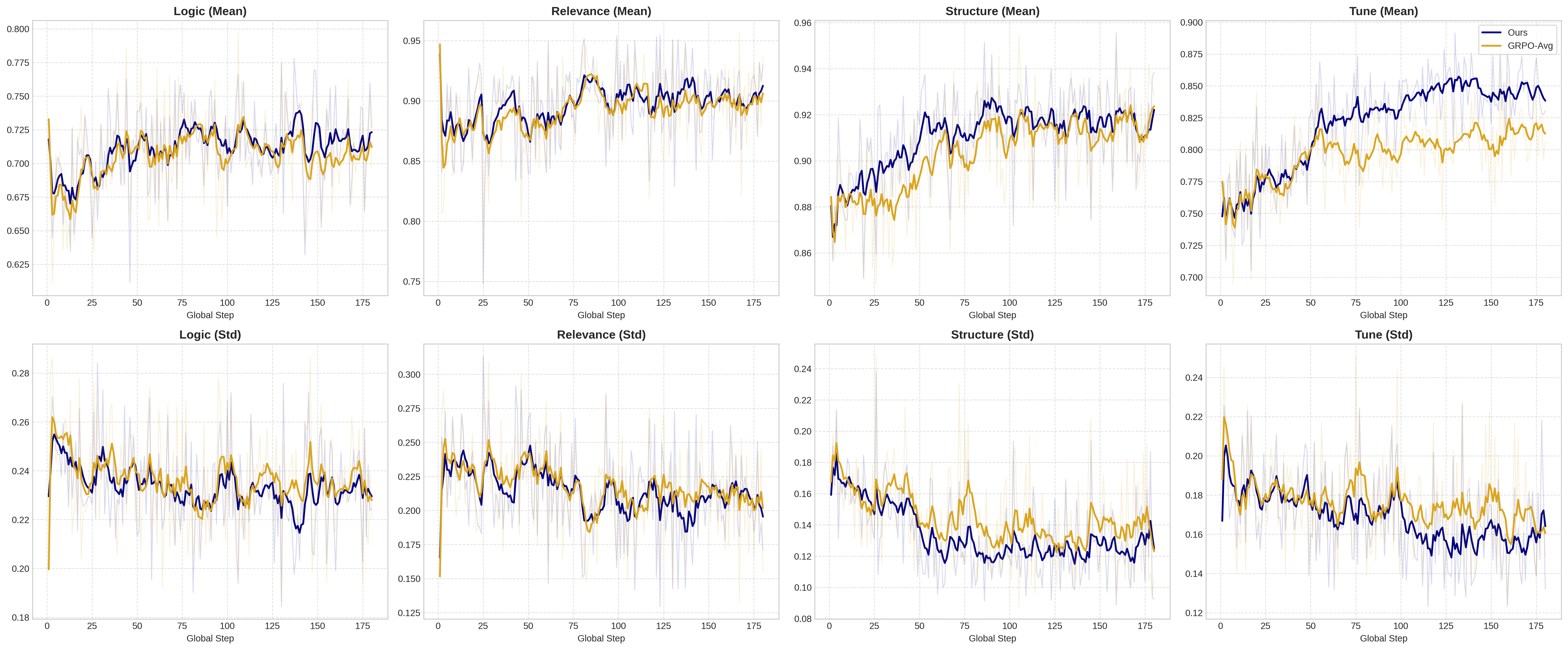
Figure 5: Reward-specific training dynamics for Logic, Relevant, Structure, and Tune.
Learning Dynamics: Reward and Data Weight Adaptation
SPARD’s reward and data weights evolve continuously throughout training, adapting to the real-time feedback landscape. Early training allocates maximal attention to text transformation, rapidly enhancing instruction-following capabilities. Code-related weights peak early and decline once saturation is achieved, while QA and creative writing data weights rise in later stages as these domains require prolonged optimization due to intrinsic subjectivity.
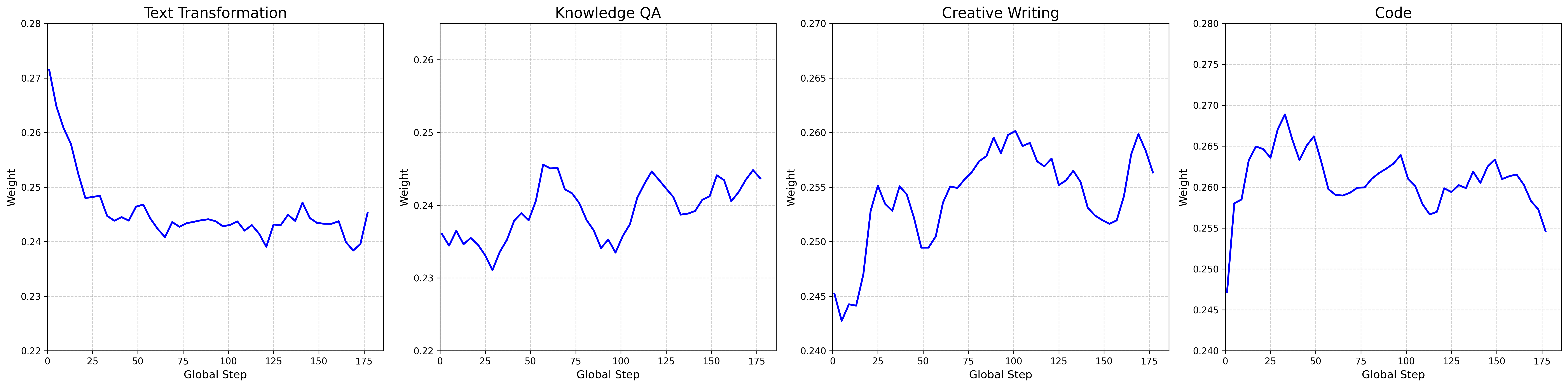
Figure 6: Data weight change trajectories highlight initial dominance of text transformation, with later ascendancy of QA and creative writing.
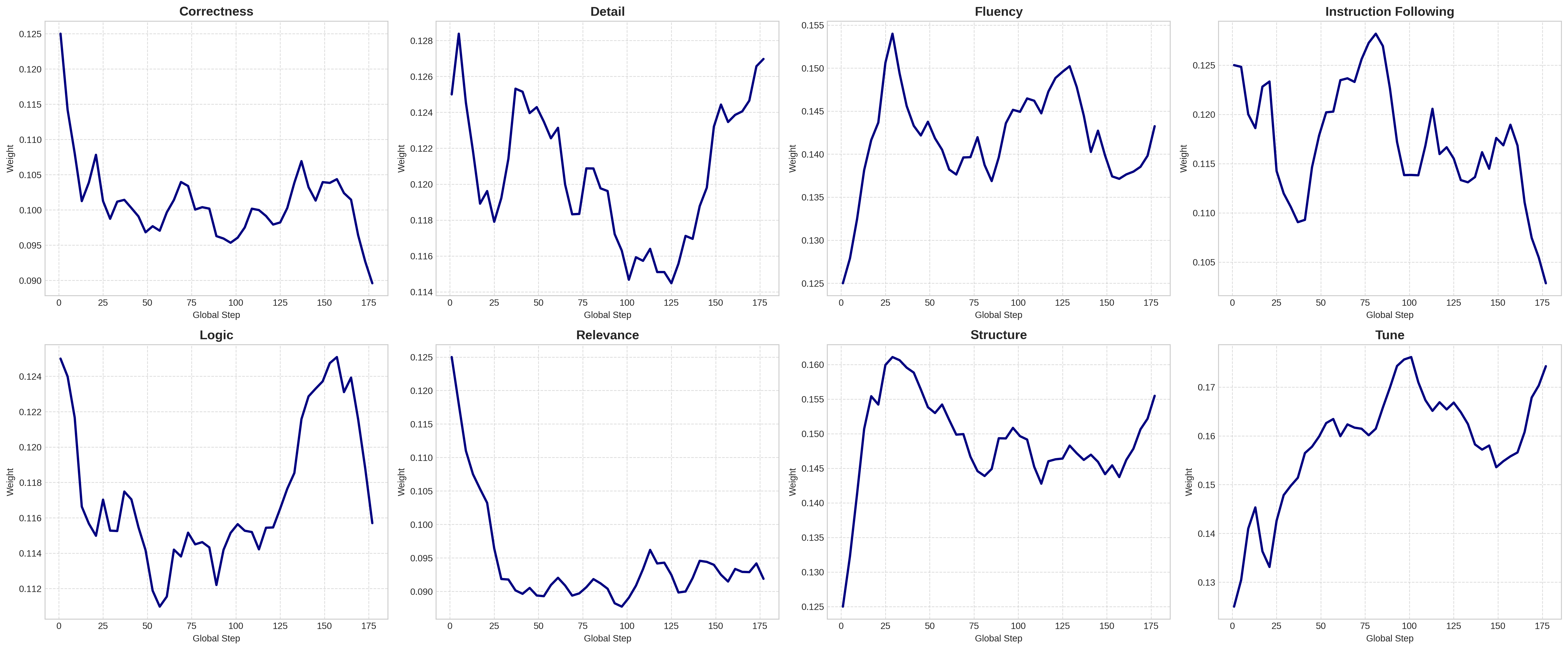
Figure 7: Reward weight change trajectories reflect persistent realignment to dominant learning objectives.
Ablation Studies and Scalability
Ablation studies confirm the necessity of both PAWA and RADR. Experiments removing either mechanism degrade performance in their respective target domains—without PAWA, open-ended creative and chat tasks suffer; without RADR, general capability stagnates due to inefficient sample utilization. Both mechanisms are robust across backbone scales; SPARD’s benefits are stable for smaller models, and for larger models, optimization gains concentrate in scientific reasoning and multi-turn dialogue.
Practical and Theoretical Implications
SPARD supremely enhances reinforcement learning-based LLM alignment by integrating reward dynamics and data utility, efficiently allocating optimization resources. It is computationally equivalent to multi-reward GRPO, as PAWA and RADR rely only on statistics from generated rewards, not on additional inference calls.
Practically, SPARD is ideal for scenarios demanding rapid, balanced alignment across heterogeneous objectives. Theoretically, SPARD establishes the necessity for progress-aware adaptive scheduling in multi-objective RL, serving as a template for future curriculum learning research. Potential extensions include non-linear reward aggregation, generalization to multimodal domains, and automated curriculum structures responsive to evolving feedback without explicit annotation.
Conclusion
SPARD introduces a principled self-paced RL alignment framework, coupling progress-aware reward adaptation and reward-attributed data rebalancing. Extensive experiments demonstrate its superiority in harmonizing multi-task proficiency and boosting both optimization efficiency and stability. SPARD’s architecture reveals the critical role of real-time curriculum scheduling in alignment of open-ended generative models. Future developments should target nonlinear reward functions and multimodal generalization.

