- The paper introduces a multi-faceted framework combining structured linguistic metrics, rubric-guided LLM evaluation, and supervised prediction models to quantify review quality.
- It presents empirical analysis showing that structured features often outperform LLM-based regressors using a dataset of 753 reviews from diverse venues.
- The framework enhances reviewer training and editorial triage through scalable, interpretable measures integrated into existing review workflows.
PeeriScope: A Multi-Faceted Framework for Evaluating Peer Review Quality
Motivation and Framework Design
The peer review process is integral to scientific publishing yet remains highly susceptible to variability, biases, and lack of standardization. The increasing prevalence of LLM-assisted reviewers raises further concerns about depth, domain reasoning, and actionable critiques. Conventional quality assessment approaches struggle with sparse, fragmented datasets and lack scalability or interpretability. PeeriScope addresses these limitations by presenting a modular platform for multi-dimensional assessment, integrating structured linguistic metrics, rubric-guided LLM evaluation, and supervised prediction.
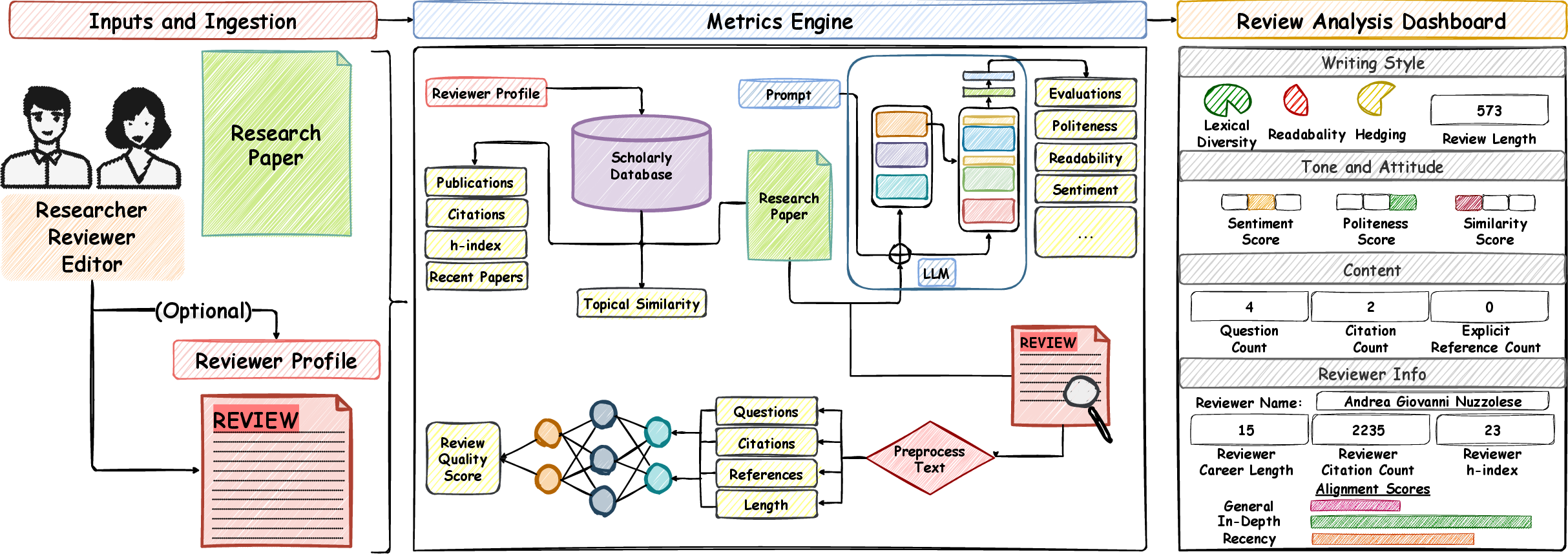
Figure 1: Overview workflow of PeeriScope highlighting the integration of structured, LLM-based, and supervised metrics.
PeeriScope's architecture is designed for computational efficiency, transparency, and seamless integration into editorial or reviewer workflows. Input modalities include both direct review text and OpenAlex metadata, enabling the extraction of reviewer topical-alignment and citation-based attributes. The review analysis dashboard provides intelligent visualizations, exposing a multidimensional view rather than reducing quality to a single composite score.
Metric Classes and Evidence Sources
Structured Metrics
Structured metrics are inspired by established peer review assessment literature and appear in three principal categories:
- Writing style and readability: Length, hedging (epistemic stance), lexical diversity, and Flesch Reading Ease are computed as proxies for clarity and thoroughness.
- Tone and reviewer attitude: Metrics such as politeness (linked to fairness and receptivity), sentiment polarity, and review-paper similarity are generated using neural and cue-based classifiers and reference metadata.
- Substantive content and coverage: These include explicit section and figure references, citation mentions, and engagement via classifier-detected questions. Topical alignment—computed via SPECTER embeddings—along with citation counts and tenure, augments reviewer profile analysis.
LLM-Based Rubric Metrics
LLM-based evaluations are employed for abstract, hard-to-capture dimensions like constructiveness, fairness, factuality, and overall utility. PeeriScope uses rubric-guided scoring with Qwen-3-8B as the main judge, although the system is model-agnostic and supports other LLMs (e.g., GPT-4o, Phi-4). Each qualitative dimension is paired with a scoring rubric anchored in editorial guidelines, allowing systematic mapping of review text to ordinal scores across aspects including comprehensiveness, actionability, objectivity, vagueness, and sentiment.
Empirical results demonstrate that GPT-4o achieves the strongest alignment with human expert judgments across these rubrics, but absolute correlation values remain modest (maximum tau = 0.359 for overall quality). This underscores the necessity for calibration and hybrid systems, as indicated by prior LLM-evaluation studies (Li et al., 2024, Gu et al., 2024).
Supervised Quality Estimation
PeeriScope synthesizes heterogeneous evidence sources using supervised prediction models trained on expert-annotated datasets. Lightweight regressors (linear, random forest, MLP) employ structured and LLM-derived features for computationally efficient and interpretable scoring. Additionally, a fine-tuned LLaMA3-8B (using LoRA and quantization) directly regresses to human-provided continuous scores, but empirical validation reveals that simpler structured-feature models generally outperform LLM-based regressors for quality alignment.
This finding is backed up by cross-validation on 753 reviews sampled from diverse venues, with a two-layer MLP achieving the peak agreement with expert scores.
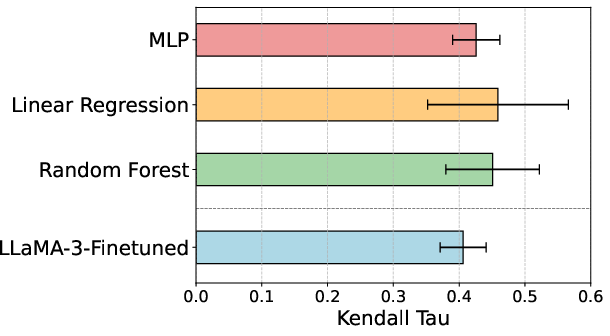
Figure 2: Kendall’s tau correlation between human-evaluated and supervised overall quality estimators, revealing higher agreement for structured-feature models.
Empirical Validation and Deployment
PeeriScope undergoes rigorous testing by contrasting its scores against trained human raters across thirteen discrete quality dimensions and a continuous overall rubric. The public dataset (753 reviews, 200 papers) encompasses both human and LLM-generated reviews, covering multiple domains. The platform achieves interpretable and scalable auditing, reviewer self-assessment, and editorial triage. Analyses reveal that structured features and supervised regressors maintain high predictive fidelity, demonstrating the limits of zero-shot LLMs as sole judges.
Deployment is supported via a REST API and interactive dashboard, with privacy preserved through ephemeral in-memory computation and minimal data retention. The system is modular, facilitating integration into editorial workflows and adaptation for broader scientific review analytics.
Implications and Future Directions
PeeriScope contributes materially to the infrastructure for automated peer review evaluation, offering extensibility in metrics and cross-domain applicability. The platform’s empirical results reinforce the utility of structured linguistic signals even in the era of LLMs, suggesting hybrid approaches as the optimal path forward. The modest correlation values for LLM-as-a-judge validate concerns about context dependence and latent reasoning gaps previously raised in peer review assessment literature (2604.24071, Li et al., 2024).
Practical implications include improved reviewer training, standardized quality benchmarking, and algorithmic auditing for editorial triage. Theoretically, PeeriScope provides a robust testbed for exploring metric calibration, fairness mitigation, and context-sensitive feedback for both human and AI reviewers. Future development may entail model-stacking, leveraging broader peer-review datasets, and adapting rubrics to evolving standards in scientific communication.
Conclusion
PeeriScope advances the state-of-the-art in peer review quality assessment by integrating interpretable structure, rubric-controlled LLM evaluation, and supervised prediction. The system’s methodological rigor, empirical validation, and flexible deployment position it as a foundational tool for scalable review analysis and transparent auditing. Lessons from PeeriScope emphasize the continued relevance of structured linguistic features, the limits of zero-shot LLM evaluation, and the necessity for hybrid models in automatic judgment tasks. The framework enables practical interventions and theoretical exploration in the ongoing evolution of scientific peer review and assessment methodologies.