- The paper presents a novel method to fully hide communication latency in distributed LLM training by decomposing collective operations into asynchronous P2P steps.
- It employs exact algorithms for all-gather and reduce-scatter, achieving over 99.7% communication overhead reduction and up to 36.9% lower end-to-end latency.
- The approach is versatile across data, tensor, and hybrid parallelism architectures, ensuring batch-size agnostic performance without compromising output fidelity.
CommFuse: Fine-Grained Communication-Compute Overlap for Distributed LLM Training
Motivation and Context
Scaling LLMs necessitates distributing computation across accelerators (GPUs, TPUs, NPUs), leveraging multi-dimensional parallelism to meet the demands of training and inference in modern deep learning architectures. However, as models are partitioned across these devices, collective communication operations (reduce-scatter, all-gather, and all-to-all) emerge as substantial bottlenecks—particularly for tensor parallelism (TP) and tensor-parallel sequence parallelism (TPSP). These bottlenecks arise from both communication latency and synchronization requirements, often limiting the scalability and efficiency of distributed workloads.
Existing solutions primarily attempt to overlap communication and computation, following two principal approaches: (1) decomposition of data into smaller chunks for asynchronous communication-compute overlap, as in Megatron-LM and MindSpeed; (2) decomposition of collective algorithms into finer P2P operations, as explored for TPUs and via graph transformation. Despite kernel fusion improvements and scheduling approaches, these solutions exhibit residual tail latency and synchronization constraints that hinder the full elimination of communication overhead. Moreover, overly granular data splits can reduce arithmetic intensity, shifting operations to memory-bound regimes and thus diminishing overall performance.
CommFuse is introduced to completely eliminate tail communication latency, achieving exact communication-compute overlap for distributed LLM training and inference. The approach systematically decomposes conventional all-gather and reduce-scatter into asynchronous peer-to-peer (P2P) communication steps, utilizing rank-adaptive and partitioned computation scheduling. CommFuse provides:
- Exact algorithms for all-gather (FuseAG) and reduce-scatter (FuseRS), using ring-based or bidirectional P2P communication decomposition, eliminating tail latency and intermediate synchronization.
- Versatile compatibility across data parallelism (DP), tensor parallelism (TP), TPSP, and Ulysses Parallelism (UP), including both training and inference.
- Batch-size agnostic overlap, robust to small batch regimes and long contexts.
- Implementation orthogonality with optimized kernels (e.g., Flash Attention), attention variants, and architectural components (MLP, attention, Mamba).
Theoretical guarantees establish that communication overhead is fully hidden when Tcomm≤Tcomp, and is minimized otherwise. CommFuse maintains exactness—no approximation or compression—preserving output fidelity.
Principles of Collective Communication Decomposition
CommFuse operates by breaking down collective communication into iterative rounds of asynchronous P2P transfers, meticulously scheduled with partial computation. Two principal collectives are targeted:
All Gather (AG): Each rank begins with a slice of data and sequentially gathers data from other ranks. Computation for the local data slice is prioritized, with communication steps interleaved so that computation for remote slices proceeds as data arrives. Upon completion, all ranks possess the union of slices.
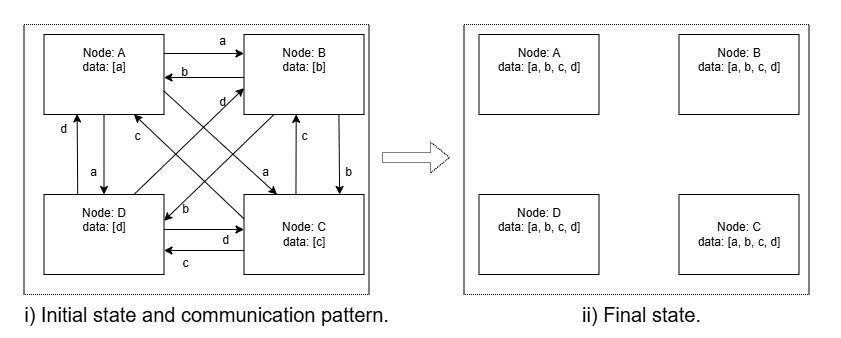
Figure 1: All Gather (AG) operation showing initial state and communication pattern on the left and final state on the right.
Reduce-Scatter (RS): Each rank holds a segment of data; communication and computation are interleaved so that partial reductions of slices from other ranks accumulate. The computation for the final resident slice is deferred, eliminating tail latency.
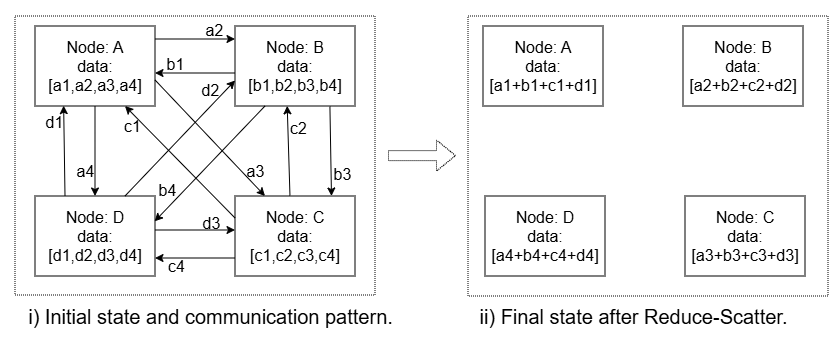
Figure 2: Reduce-Scatter (RS) operation showing initial state and communication pattern on the left and final state on the right.
Both AG and RS can be efficiently implemented in a ring topology:
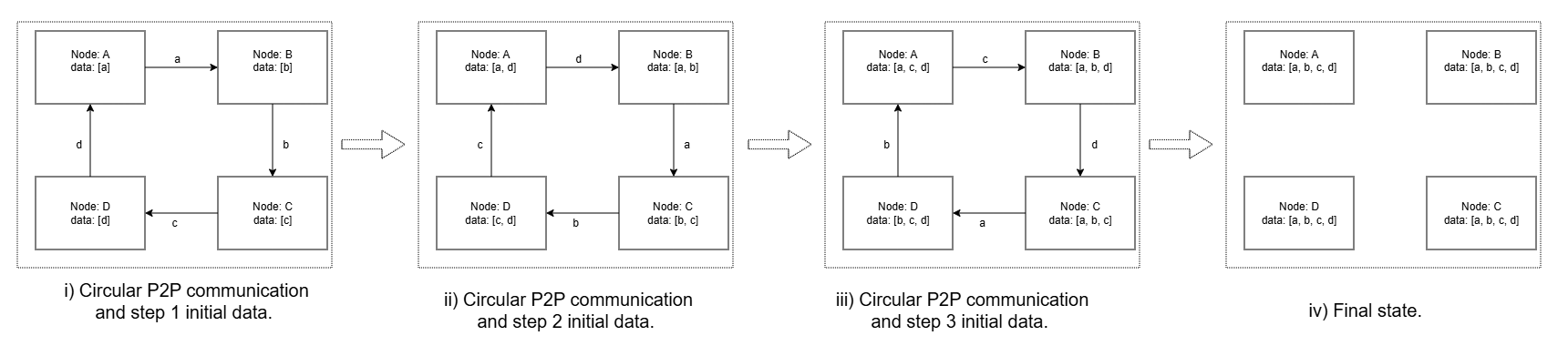
Figure 3: Ring implementation of All-Gather operation showing example for four compute ranks.
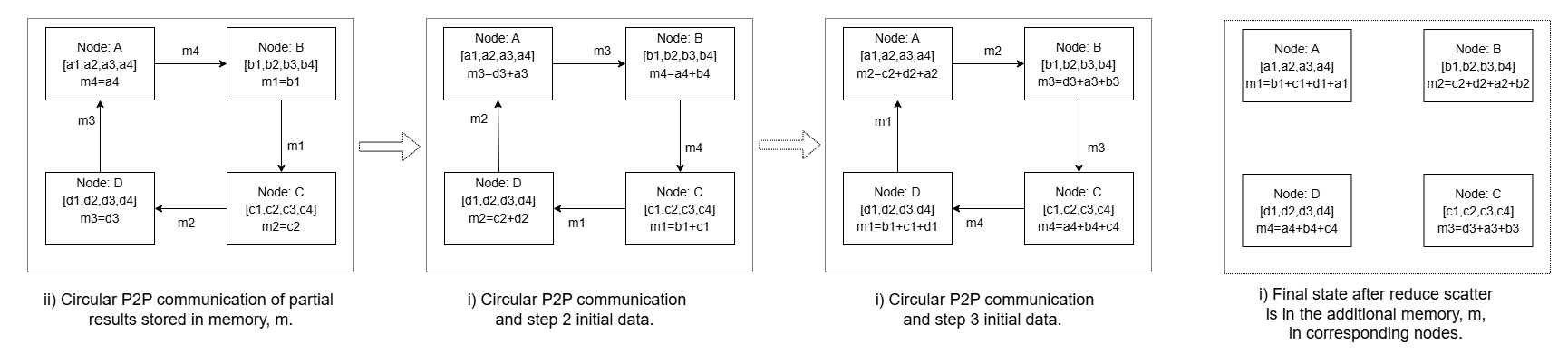
Figure 4: Ring implementation of Reduce-Scatter operation showing example for four compute ranks.
The CommFuse instantiation further leverages interleaved computation to maximize overlap:
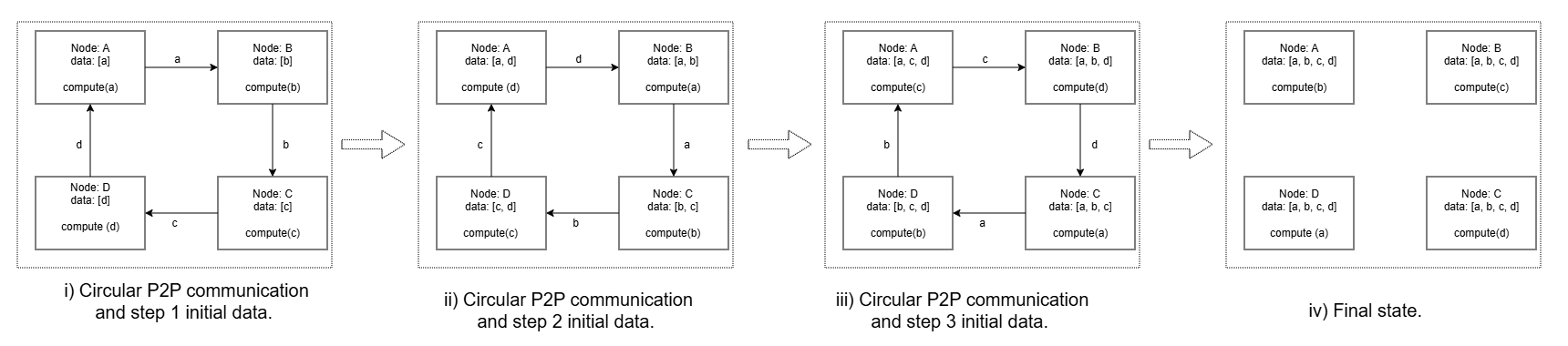
Figure 5: Four-rank example of Fuse All Gather, showing the ring-ordered breakdown of the collective into peer-to-peer communication steps with interleaved partial-output computation to achieve compute–communication overlap.
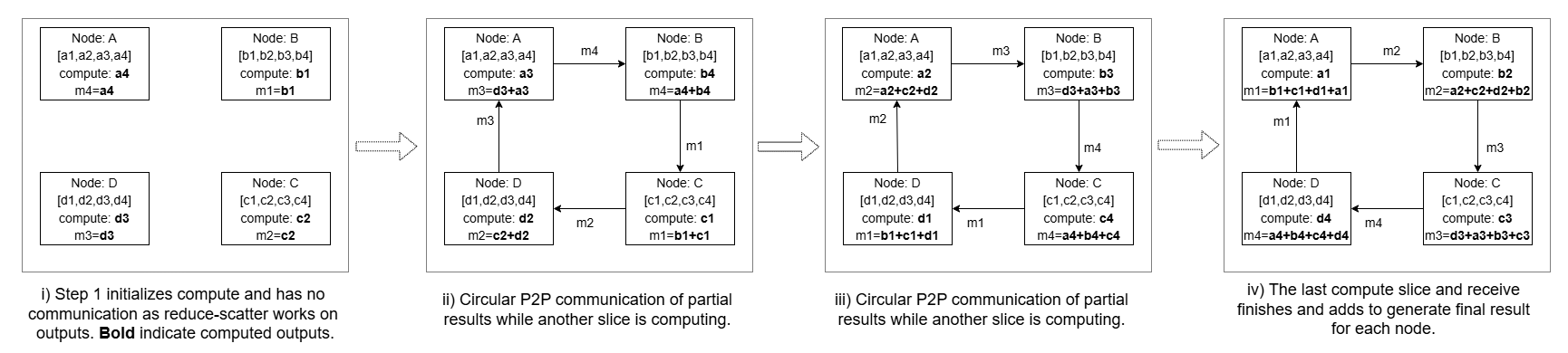
Figure 6: Four-rank example of Fuse Reduce Scatter, showing the ring-ordered breakdown of the Reduce Scatter collective into peer-to-peer communication steps with interleaved partial-output computation to achieve compute–communication overlap.
Attention layers with conventional chunk-based RS suffer from communication overhead, illustrated as:
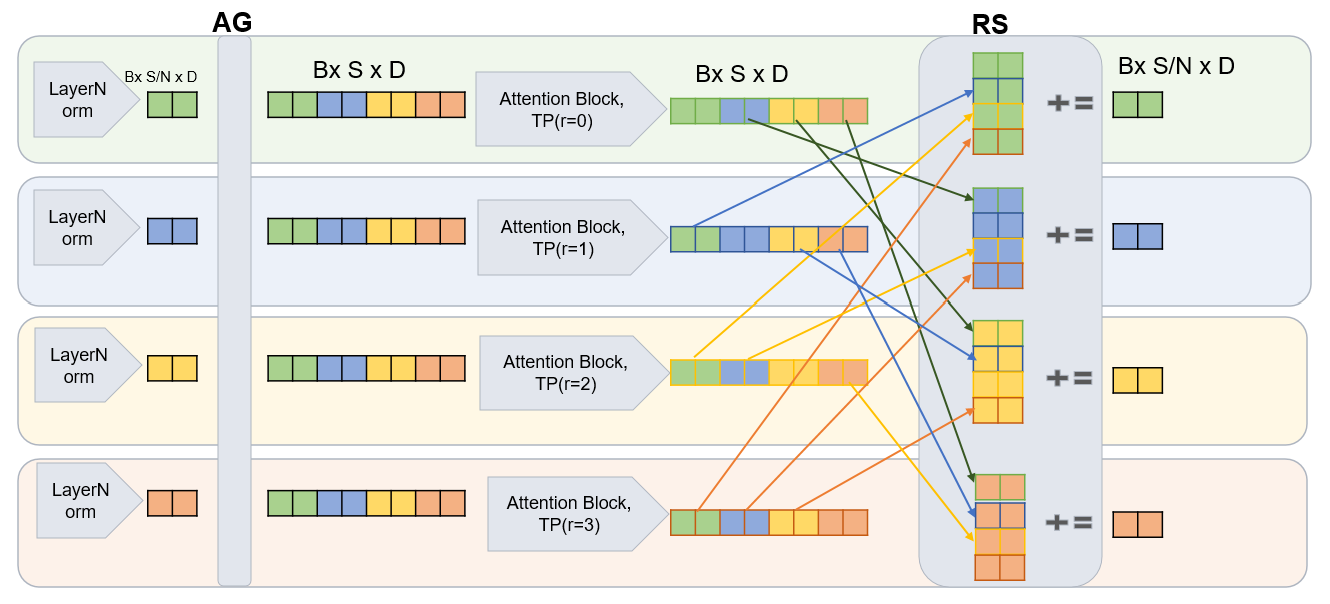
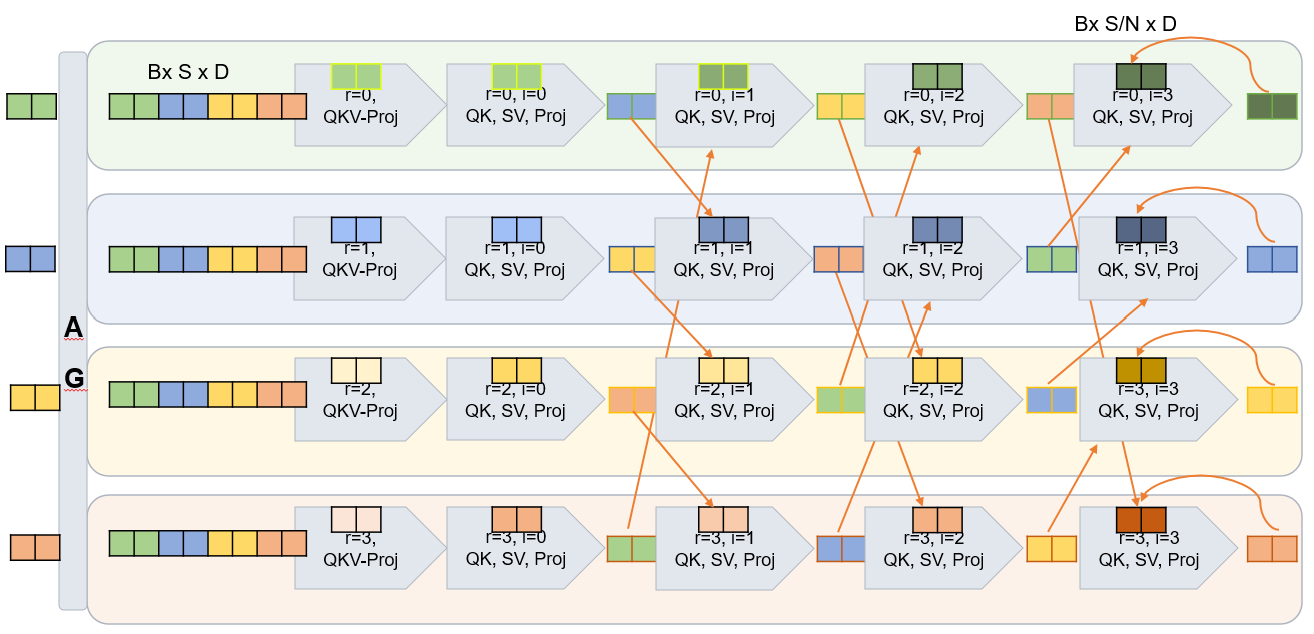
Figure 7: Attention with tensor parallelism (TP) using non overlapped reduce-scatter resulting in communication overhead.
Architectural Instantiations
CommFuse is instantiated for MLP, attention, and Mamba layers. FuseRS enables efficient row-parallel projections (MLP), and both row-parallel and query split attention for transformer models. The latter splits queries and interleaves computation with asynchronous communication, enabling deeper overlap in attention-heavy contexts. CommFuse extends to UP for extremely long sequences, redistributing attention heads via all-to-all pattern and overlapping computation across query slices.
Layer-specific implementations are batch-size independent and maintain compatibility with kernel-level optimizations, including Flash Attention.
Empirical Results
Experimental evaluation demonstrates strong quantitative results:
- MLP Layer (4096 hidden dim, TP=4): CommFuse achieves a 99.8% reduction in communication overhead and a 36.9% reduction in end-to-end latency versus baseline, outperforming chunked data slicing approaches (84% overhead reduction, 31.4% latency reduction).
- Attention Layer: CommFuse instantiations (row-parallel, query split) yield up to 20%+ additional latency reduction relative to slicing-based overlap methods under varying batch and sequence lengths.
- Scaling: CommFuse maintains 99.7-99.8% communication overhead reduction across all tested sequence lengths, consistently outperforming data slicing.
- Generalization: The overlap achieved is robust across context lengths, batch sizes, and layer types.
These improvements are achieved without any loss of numerical fidelity.
Implications and Future Directions
The elimination of tail latency via fine-grained dependency scheduling fundamentally enables scalable, efficient intra-layer model parallelism across nodes—not just within single-node device constraints. This unlocks the ability to train and serve LLMs with larger layers, reduces operational cost, and improves energy efficiency. CommFuse's compatibility with hybrid parallelism and modular architecture (TP, TPSP, UP) positions it for broad adoption in heterogeneous accelerator clusters.
On the theoretical side, CommFuse provides a framework for deriving latency-optimal scheduling in distributed computation graphs, applicable in principled ways to diverse neural architectures (Transformer, Mamba, multimodal, vision transformers). As model sizes and distributed infrastructures grow, further kernel fusion, dynamic overlap scheduling, and heterogeneity-aware extensions are likely avenues for continued progress.
Conclusion
CommFuse delivers an exact, scalable solution for compute-communication overlap in distributed LLM training and inference. By decomposing collective communication algorithms and tightly scheduling computation, it eliminates tail latency and synchronization bottlenecks inherent in mainstream approaches. Strong empirical gains in FLOPS utilization and end-to-end latency indicate practical efficacy and theoretical optimality in communication-bound regimes. The approach generalizes across architectural and parallelization strategies, offering a robust mechanism for future AI workloads requiring distributed scalability (2604.24013).