- The paper introduces GoClick, a 230M-parameter model that robustly grounds GUI elements using Florence-2's encoder-decoder architecture.
- It leverages a Progressive Data Refinement pipeline to curate a high-quality 3.8M sample dataset, enhancing both data efficiency and grounding accuracy.
- Experiments on seven benchmarks demonstrate high accuracy and reduced latency compared to larger models, enabling effective on-device autonomous GUI interaction.
GoClick: Compact GUI Element Grounding for Autonomous Interaction
Motivation and Context
Graphical User Interface (GUI) element grounding—a procedure for precisely localizing interface objects given natural language prompts—is pivotal for multimodal autonomous agents, especially when deployed on resource-constrained platforms such as mobile devices. While recent Vision-LLMs (VLMs) demonstrate high performance on visual grounding tasks, these typically feature large-scale architectures (≥ 2.5B parameters), rendering them impractical for edge device deployment due to latency and memory bottlenecks. Addressing this gap, the paper presents GoClick, a lightweight GUI grounding model that achieves high accuracy with only 230M parameters, thus advancing on-device viability without compromising grounding efficacy.
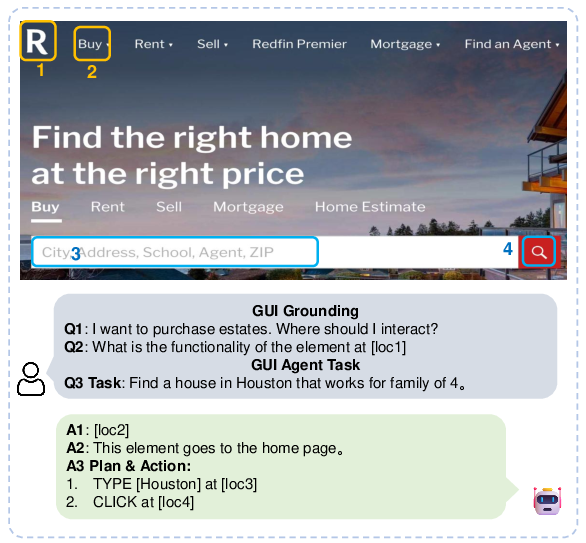
Figure 1: Illustration of GUI interaction by an agent automating GUI operations via robust element grounding.
Model Architecture and Design Choices
GoClick adopts the Florence-2 encoder-decoder architecture over popular decoder-only designs, capitalizing on the proven advantage of encoder-decoder models for narrow tasks at reduced parameter scales. The model pipeline incorporates a visual encoder (e.g., ViT) and concatenates visual embeddings with textual representations, enabling focused spatial localization rather than generic, expansive language generation.
The architectural decision stands in contrast to downsizing large decoder-only VLMs, which the paper shows results in suboptimal grounding under parameter budget constraints. Extensive experiments confirm the superiority of Florence-2’s structure for GUI grounding at scales down to 230M parameters, outperforming several competitive decoder-only variants with larger parameter counts.
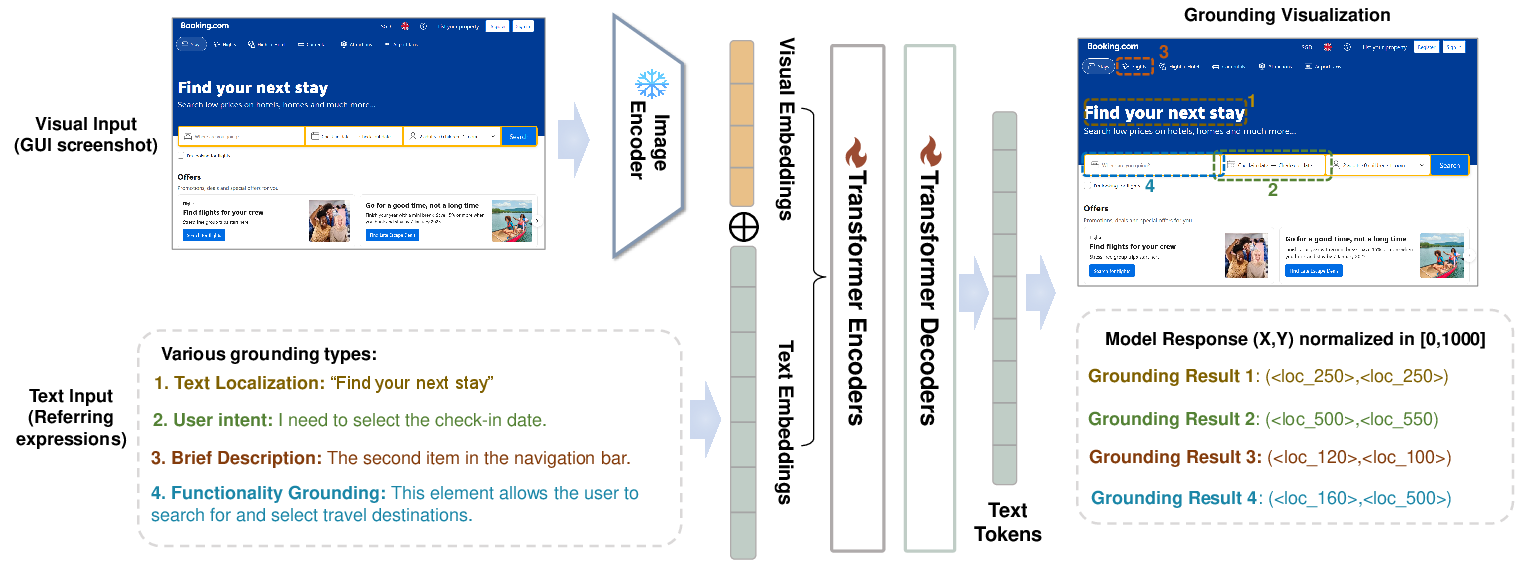
Figure 2: GoClick leverages Florence-2’s encoder-decoder architecture for efficient multi-modal spatial grounding.
Progressive Data Refinement Pipeline
GoClick’s efficacy stems from not only its architecture but also rigorous training data refinement. The authors curate a massive 10.8M-sample dataset, spanning diverse RE types: Alt-texts, Brief Descriptions, Action Intents, and Functionality Descriptions. Recognizing the limits of small models and the heterogeneity of GUI tasks, the Progressive Data Refinement (PDR) pipeline is used to enhance core sample quality through:
- Coarse-grained filtering (removing outdated GUI patterns and non-grounding tasks)
- Fine-grained adjustment (tuning inclusion ratios for task types across data sources)
This process yields a high-quality 3.8M core set, verified empirically to result in substantial accuracy improvements and training efficiency.
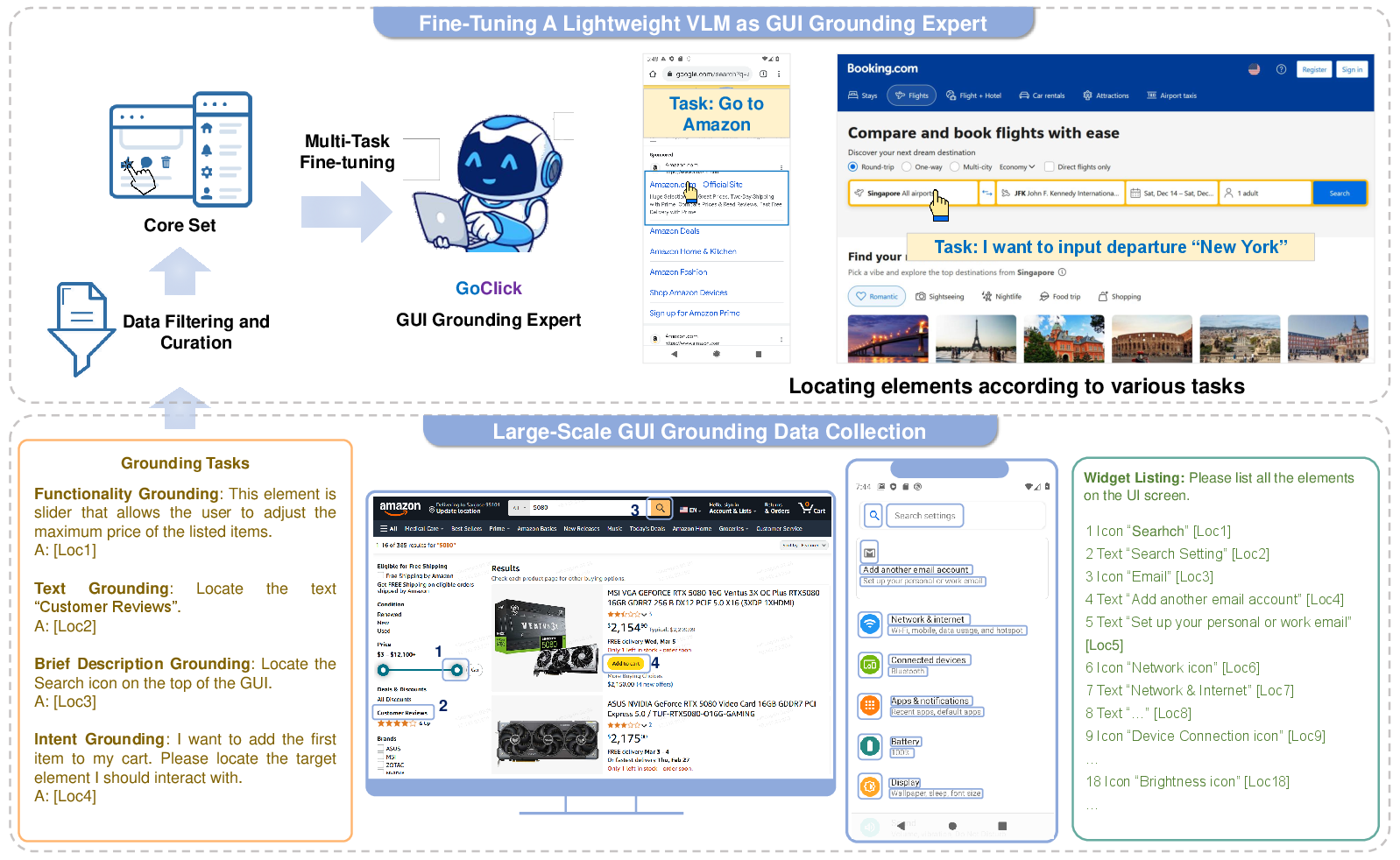
Figure 3: Data generation and refinement: diverse GUI grounding tasks are filtered and balanced to create the core training set.
Experimental Results
Speed-Accuracy Tradeoff
GoClick’s performance is evaluated on seven GUI grounding benchmarks (FuncPred, ScreenSpot, ScreenSpot-v2, MOTIF, RefExp, VisualWebBench EG and AG), using Grounding Accuracy, Time-To-First-Token (TTFT), and Time-Per-Output-Token (TPOT) as metrics. GoClick not only consistently surpasses competing lightweight models—often achieving parity with or outperforming 7B+ models—but also offers a marked reduction in inference latency and model size. For example, GoClick achieves 78.5% ScreenSpot accuracy with only 0.8B parameters, outperforming both Qwen2VL-2B and SLiME-Gemma-2B and matching Qwen2VL-7B.
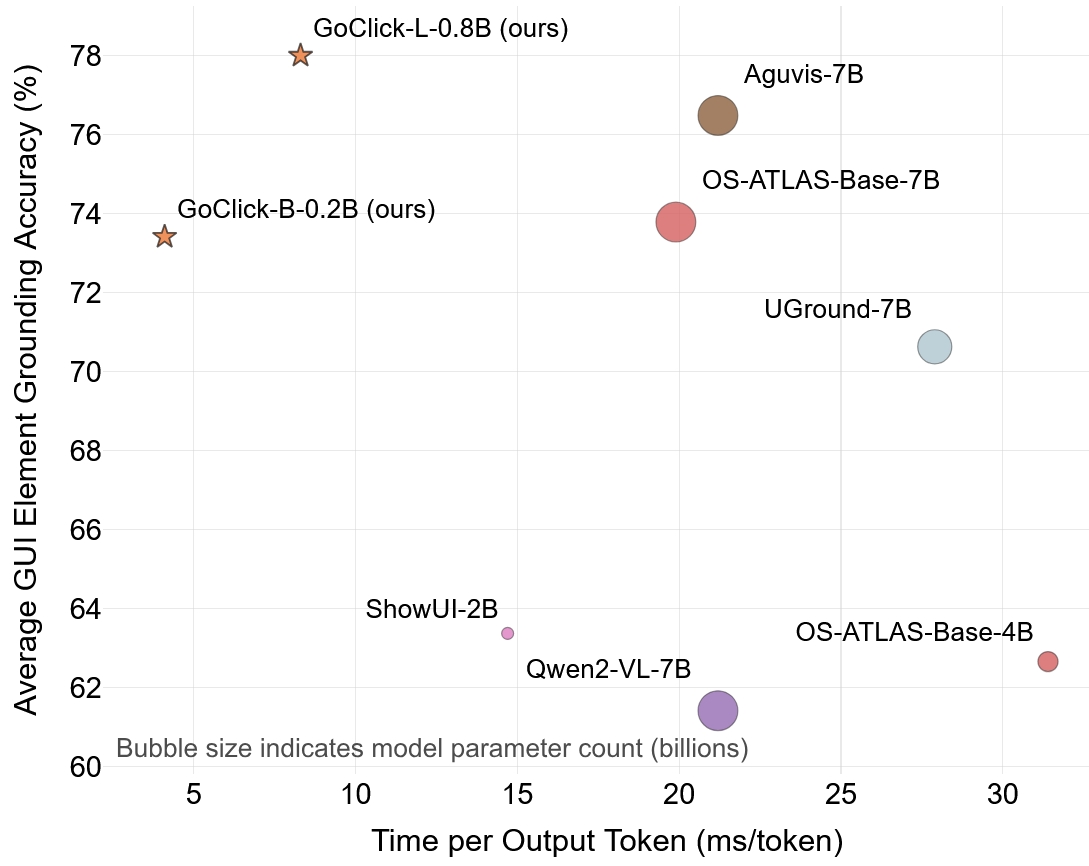
Figure 4: GoClick attains superior grounding accuracy at reduced model size and increased inference speed compared to competitive VLMs.
Architectural Ablation
Comparative studies between encoder-decoder and decoder-only model variants, fine-tuned on the same dataset, further validate GoClick’s architecture. Florence-2-based GoClick surpasses decoder-only alternatives even at higher parameter scales, demonstrating robustness across all GUI domains and task types. The model also exhibits lower performance differentials between text (easy) and icon (hard) grounding tasks, underscoring cross-domain generalizability.
Data Efficiency
Rigorous ablation in the PDR pipeline reveals decisive trends: inclusion of outdated GUI samples or dual REG tasks (expression generation with same targets) degrades performance, and naive aggregation from some sources can induce catastrophic overfitting. By finely tuning task ratios per source, GoClick’s final accuracy outstrips models trained on larger, unrefined datasets, demonstrating parameter and data efficiency.
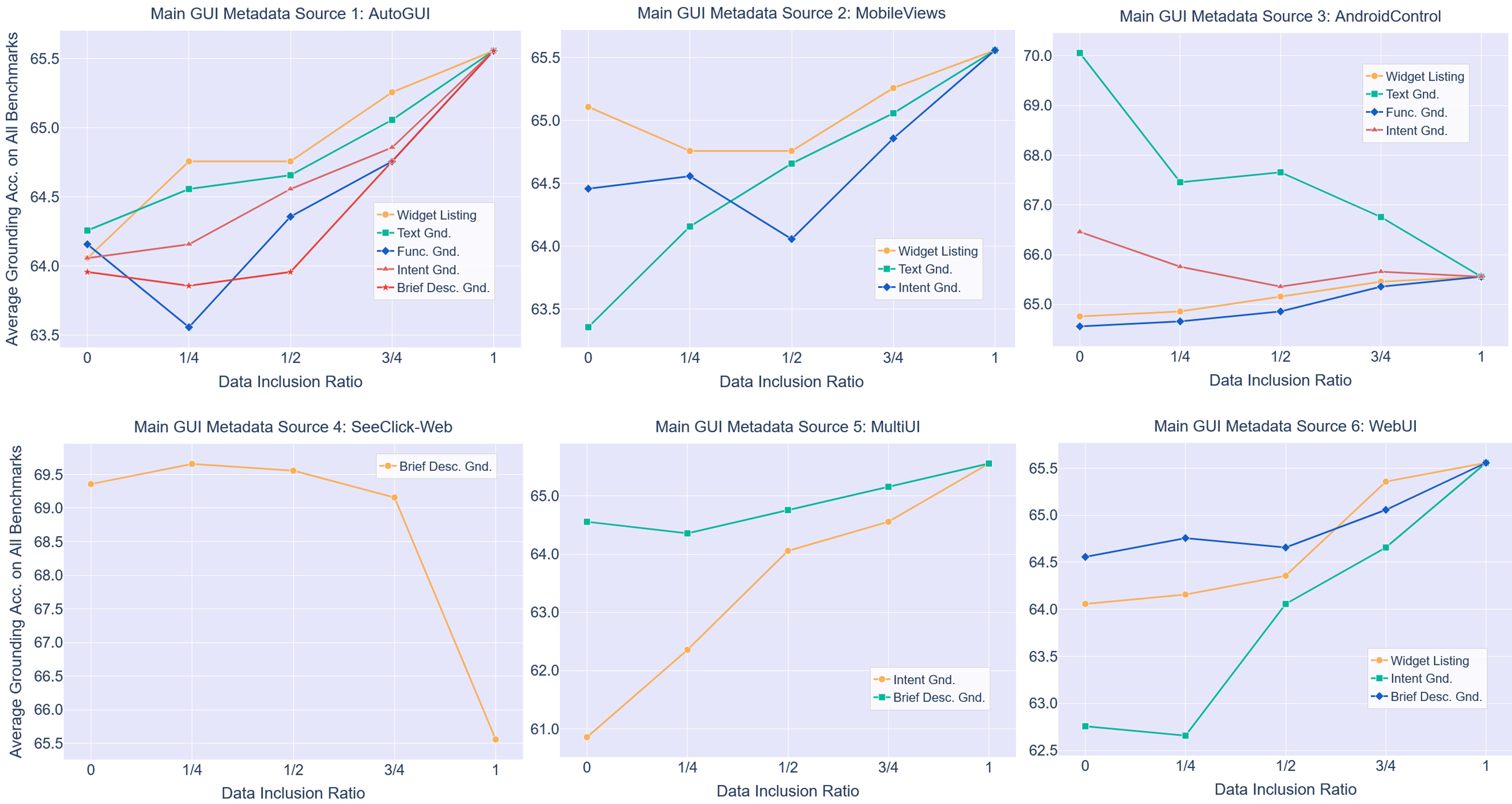
Figure 5: Empirical analysis of task inclusion ratios verifies that not all data are beneficial and that careful curation drives performance gains.
Applications: Device-Cloud Collaboration Agents
GoClick's utility is demonstrated in collaborative frameworks where planning (reasoning and task decomposition) is performed by proprietary large-scale cloud models, while element grounding is handled by GoClick locally. This two-stage approach, assessed on several agent benchmarks (AITW, AndroidControl, GUIAct), yields dramatic improvements in step success rate and click accuracy over both standalone proprietary models and systems using SoM prompting. GoClick's grounding expertise enables agents to resolve fine-grained visual coordinates, a longstanding bottleneck for proprietary planners.
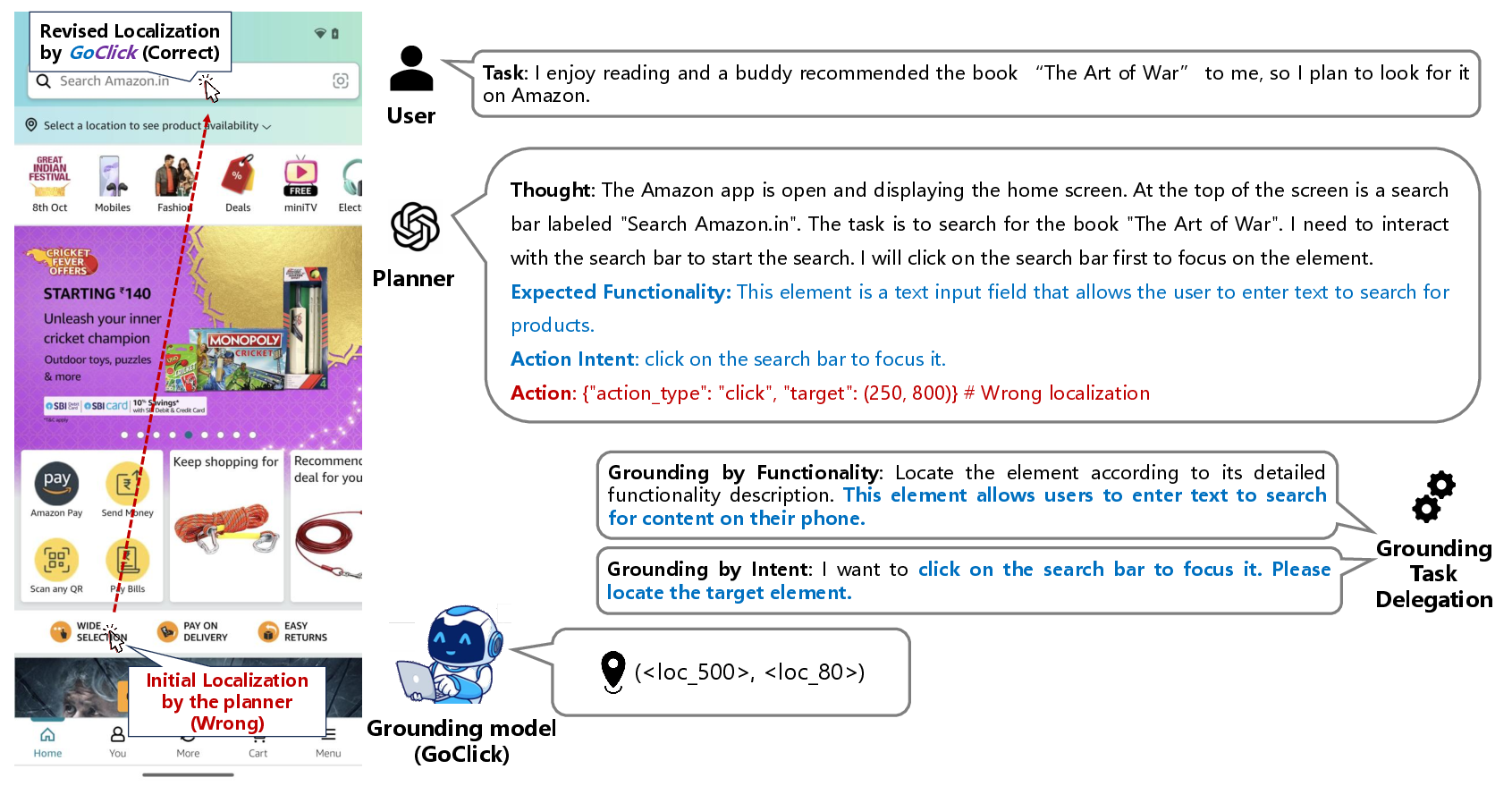
Figure 6: Device-cloud agent architecture: reasoning and planning by cloud VLMs, spatial grounding by lightweight GoClick deployed on device.
Practical and Theoretical Implications
GoClick establishes that:
- Architectural selection tailored for narrow spatial localization tasks results in significant accuracy improvements under severe resource constraints, supporting the premise that encoder-decoder models are preferable at low parameter scales for grounding-like tasks.
- Systematic data refinement—removing potentially harmful and redundant training signals—can substantially enhance grounding performance and efficiency, challenging the long-held notion that more data invariably leads to better models, especially under strict deployment requirements.
- Division of labor between planning (cloud) and grounding (device) enables a practical pathway toward robust autonomous GUI agents on mobile and embedded systems, expanding the operational frontier of multimodal AI.
The results imply that future developments should further investigate meta-learning or game-theoretic approaches for sample value estimation and explore expanding encoder-decoder architectures to cover more complex GUI interaction tasks, including reasoning and sequential planning.
Conclusion
GoClick exemplifies a strategic combination of lightweight architecture and refined training data for expert GUI element grounding. Empirical evaluation across benchmarks and agent tasks demonstrates strong speed-accuracy tradeoffs and deployment feasibility. Integration into device-cloud multi-stage agents validates GoClick’s practical utility, surpassing both standalone proprietary and competitive SoM-augmented solutions. Challenges remain in generalizing architectural insights to broader GUI tasks and automating the sample selection process, but the foundations laid by GoClick suggest promising avenues for high-performance, resource-constrained multimodal agents.

