- The paper demonstrates that deductive, inductive, and abductive reasoning can be geometrically isolated as nearly orthogonal vectors using contrastive prompt pairs and linear probes.
- The complementary subspace-constrained refinement technique enhances reasoning by encouraging partial alignment among vectors, aligning LLM outputs closer to human-like integration.
- Steering along these refined vectors yields measurable performance gains on reasoning benchmarks, with improvements up to 1.76 points on tasks like deductive inference.
Knowledge Vectors for Logical Reasoning in LLMs
Motivation and Problem Statement
The paper "Knowledge Vector of Logical Reasoning in LLMs" (2604.23877) explores the geometric encoding of logical reasoning abilities within LLMs. Specifically, it investigates whether the canonical forms of logical reasoning—deductive, inductive, and abductive—can be represented as distinct, linearly manipulable vectors in activation space, and whether these representations are independent or interact, as suggested by cognitive science theories of human reasoning.
Human reasoning does not strictly separate these modes; rather, complex inference emerges from their cooperation, as seen in cognitive science. The authors thus aim not only to verify separability and steerability of these reasoning vectors, but also whether LLMs can benefit from explicit complementarity between reasoning types via representation engineering.
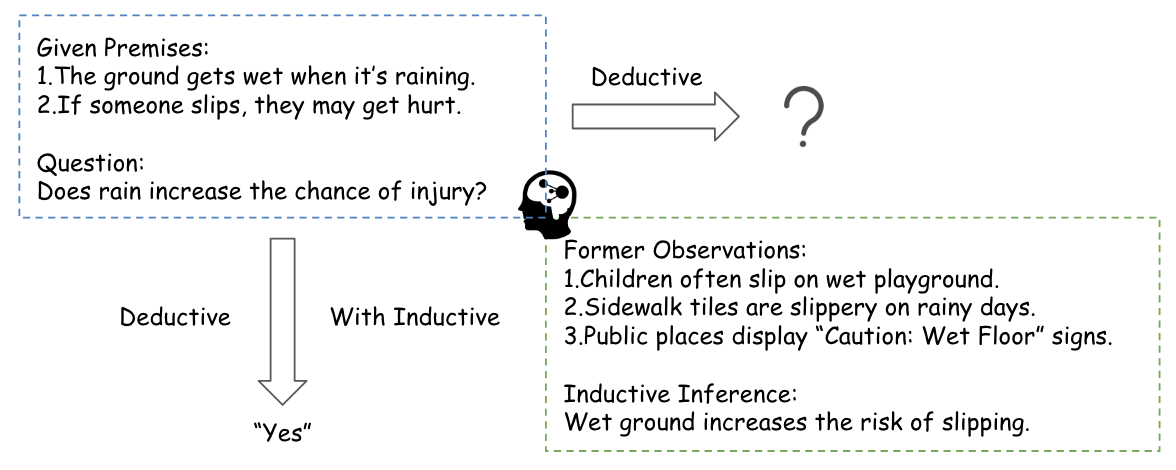
Figure 1: An example of complementary reasoning deployment in human cognition, where inductive premises inform deductive chains.
Extraction and Geometric Analysis of Reasoning Vectors
The authors utilize contrastive prompt pairs to induce successful versus failed instances of each reasoning type, extract residual stream activations at intermediate model layers, and optimize linear probes, producing reasoning vectors (θd, θi, θa) corresponding to deductive, inductive, and abductive reasoning, respectively.
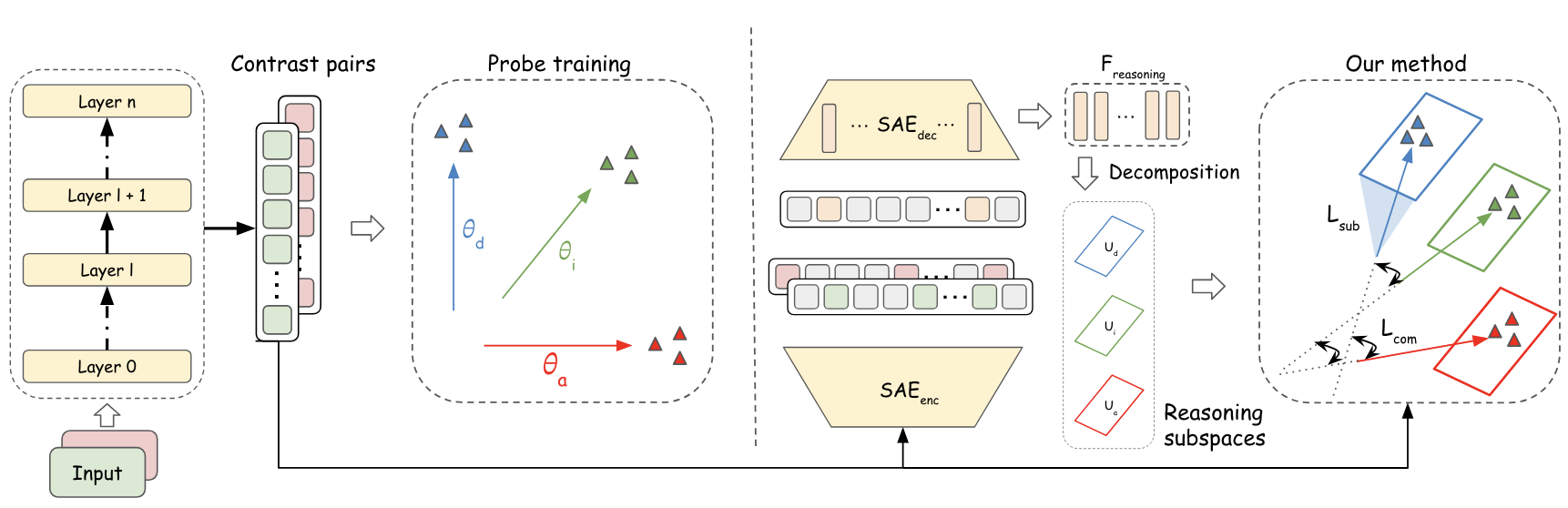
Figure 2: Schematic of naive (contrast-based) versus complementary (subspace-constrained) extraction of reasoning vectors.
Orthogonality of Reasoning Representations
Empirical cosine similarity analysis reveals that these vectors are nearly orthogonal (cosine ≈ 0), suggesting each reasoning form occupies a largely distinct direction in activation space, without spontaneous geometric overlap.
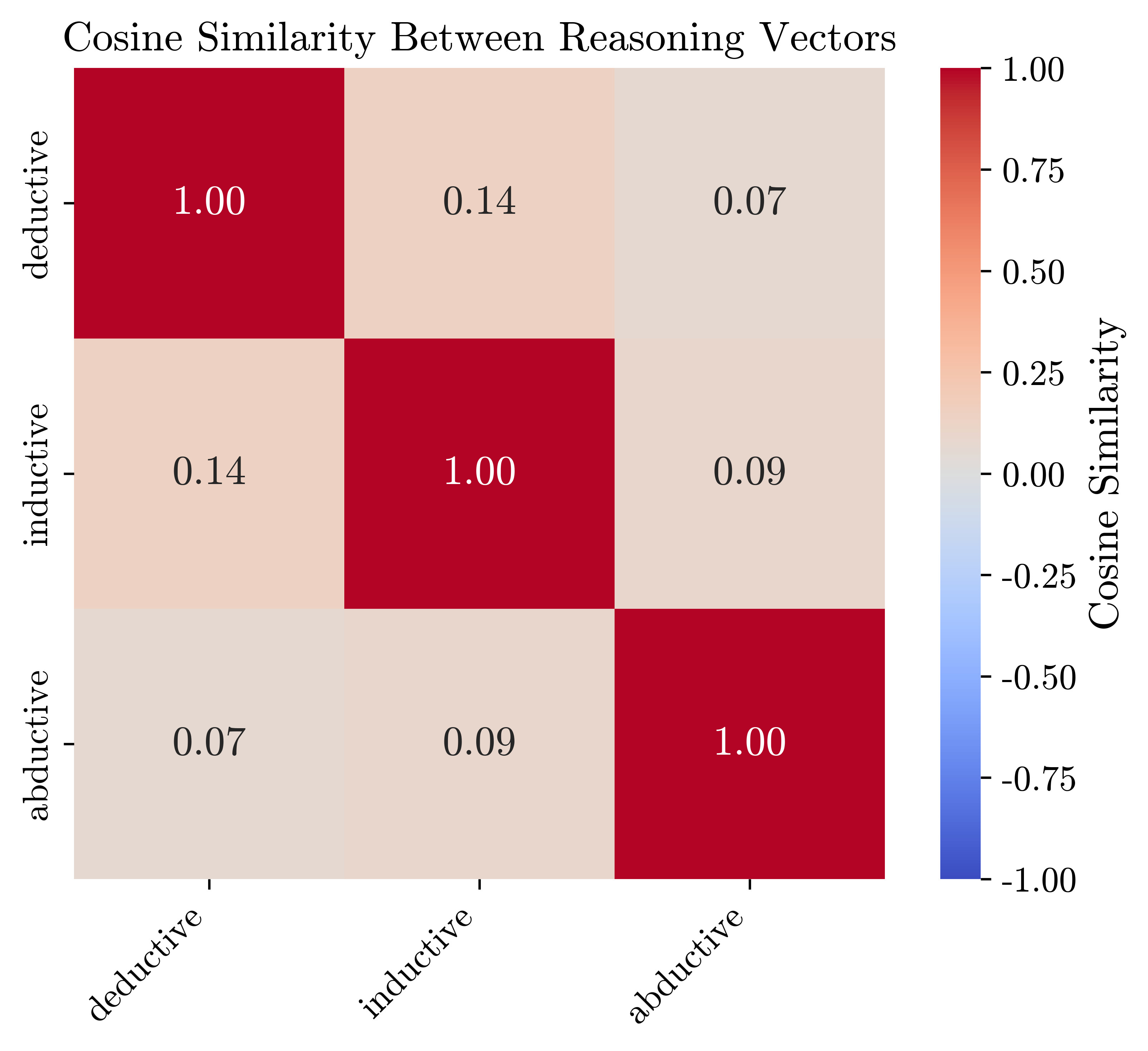
Figure 3: Cosine similarity heatmap confirms the near-independence of vectors for different reasoning types in the model.
This is in direct tension with cognitive findings that reasoning types interact and re-use common subcomponents. The independence found here highlights a structural mismatch between current LLM representation and human mental models.
Steering and Baseline Results
Steering models along these vectors improves benchmark performance on dedicated datasets for each reasoning type. The improvement supports the interpretability and causal efficacy of these directions, confirming the adequacy of the linear representation assumption for logical reasoning knowledge in activation space.
Complementary Subspace-Constrained Refinement
Complementary Enhancement Framework
To induce human-like interplay between reasoning modes, the authors propose a subspace-constrained refinement mechanism. This involves:
- A complementary loss that encourages partial alignment among reasoning vectors.
- A subspace constraint leveraging SAE-derived reasoning-specific subspaces, ensuring that refined vectors do not collapse onto each other and continue to encode unique aspects of each reasoning type.
This method is operationalized by combining probe loss, a complementary knowledge term (cosine-based), and subspace-preservation loss into a single objective.
Empirically, refined complementary reasoning vectors outperform both naive and baseline steering—yielding consistent (albeit modest) gains across all evaluated LLMs and reasoning tasks. For instance, on Llama-3.1-8B-it, complementary vectors raised accuracy on deductive, inductive, and abductive tasks by 1.24, 0.42, and 1.76 points, respectively, over mono-steering.
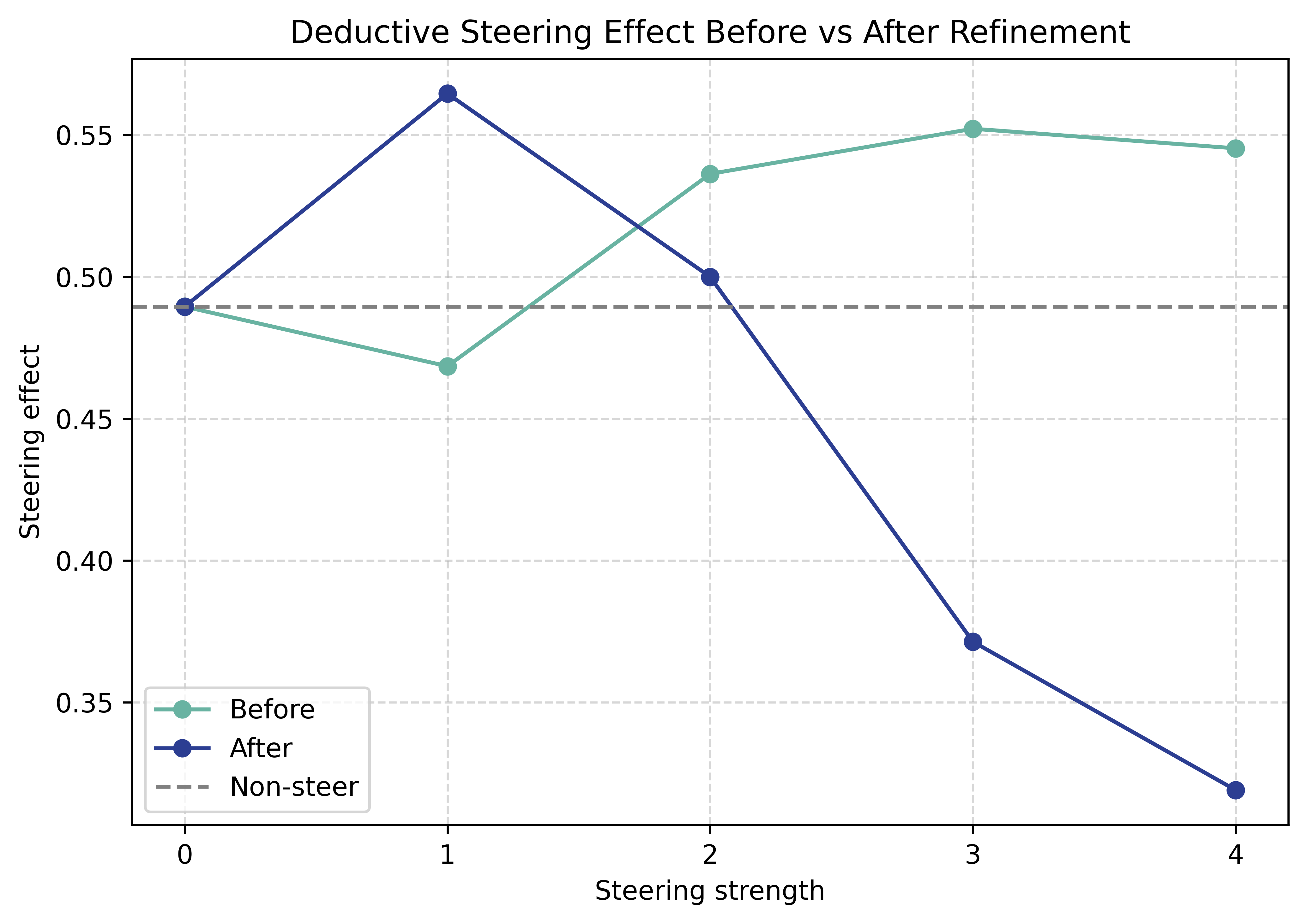
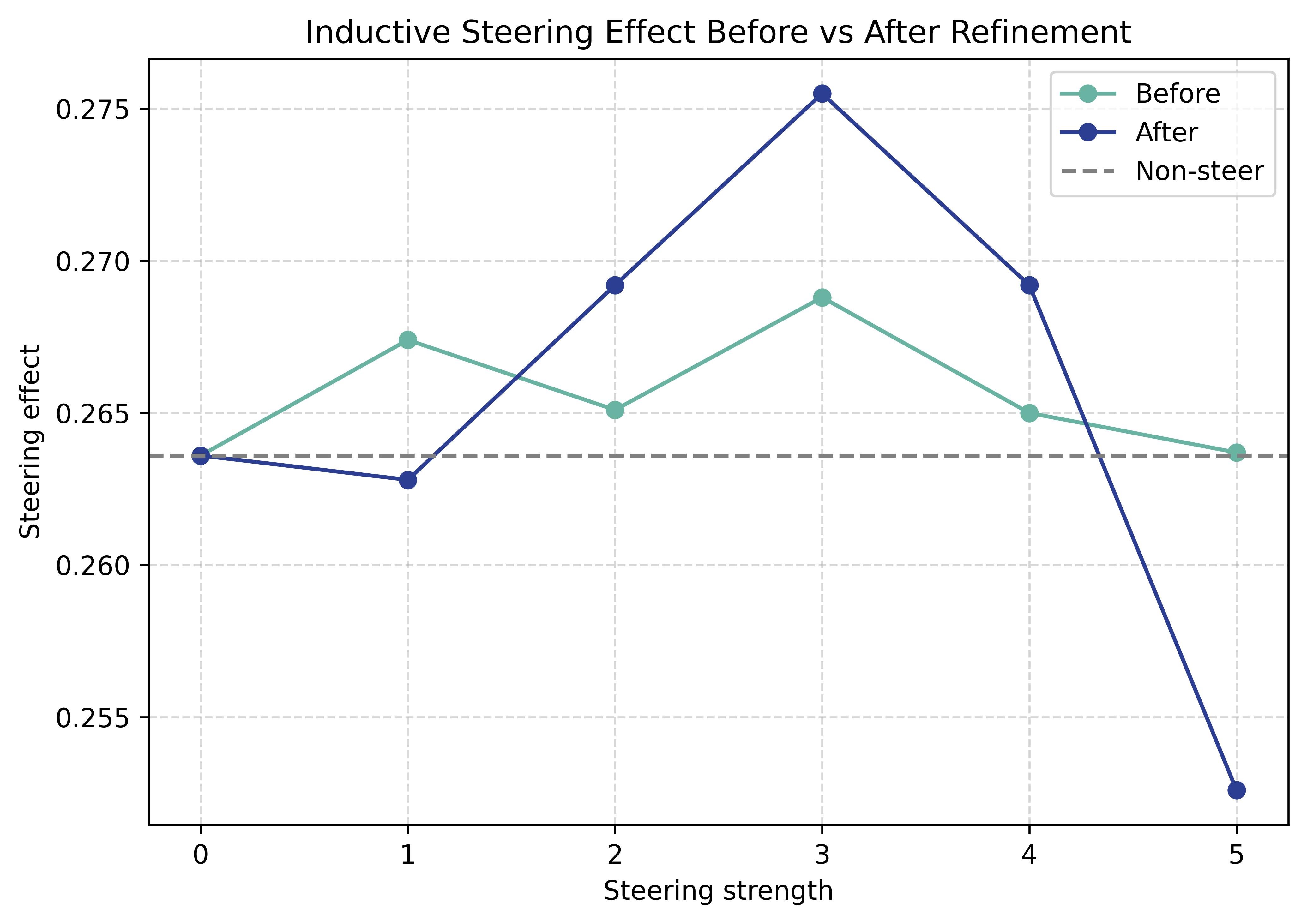
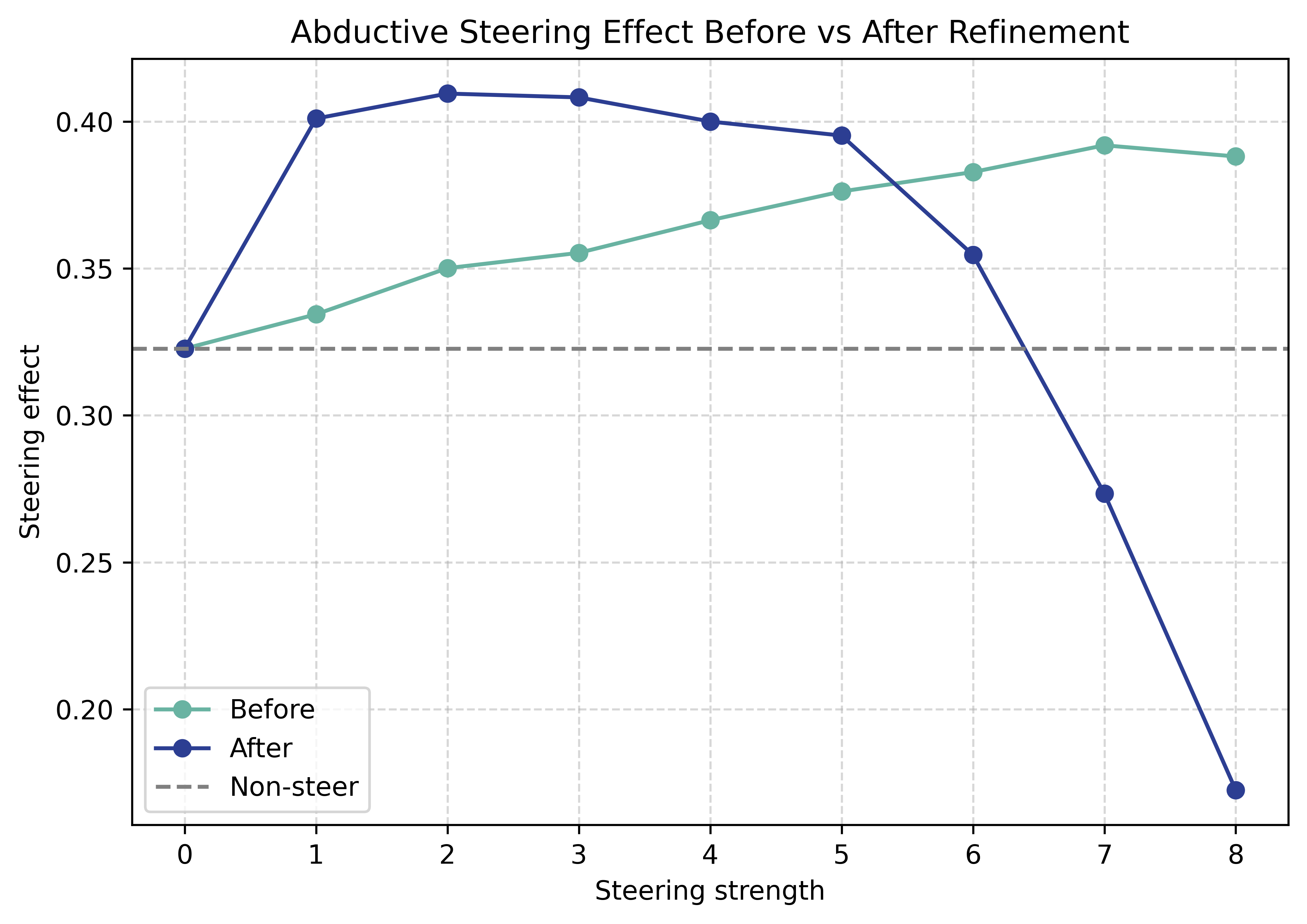
Figure 4: Post-refinement reasoning vectors achieve improved performance at lower steering strengths, indicating cleaner alignment.
Importantly, this approach generalizes: similar performance improvements are observed in architectural variants (e.g., Gemma-2-9B-it, GPT-OSS-20B) and in multi-step arithmetic reasoning benchmarks (GSM8K), supporting the task-salience and model-invariance of these engineered directions.
Mechanistic and Feature-Level Analysis
SAE Feature Attribution and Inter-Reasoning Transfer
SAE latent space analysis demonstrates that, after refinement, top reasoning features for each mode both retain distinctiveness and show enhanced overlap with salient features from other reasoning types—quantitatively confirming complementary knowledge transfer.
Figure 5: Top-5 refined features per reasoning type after subspace-constrained refinement.
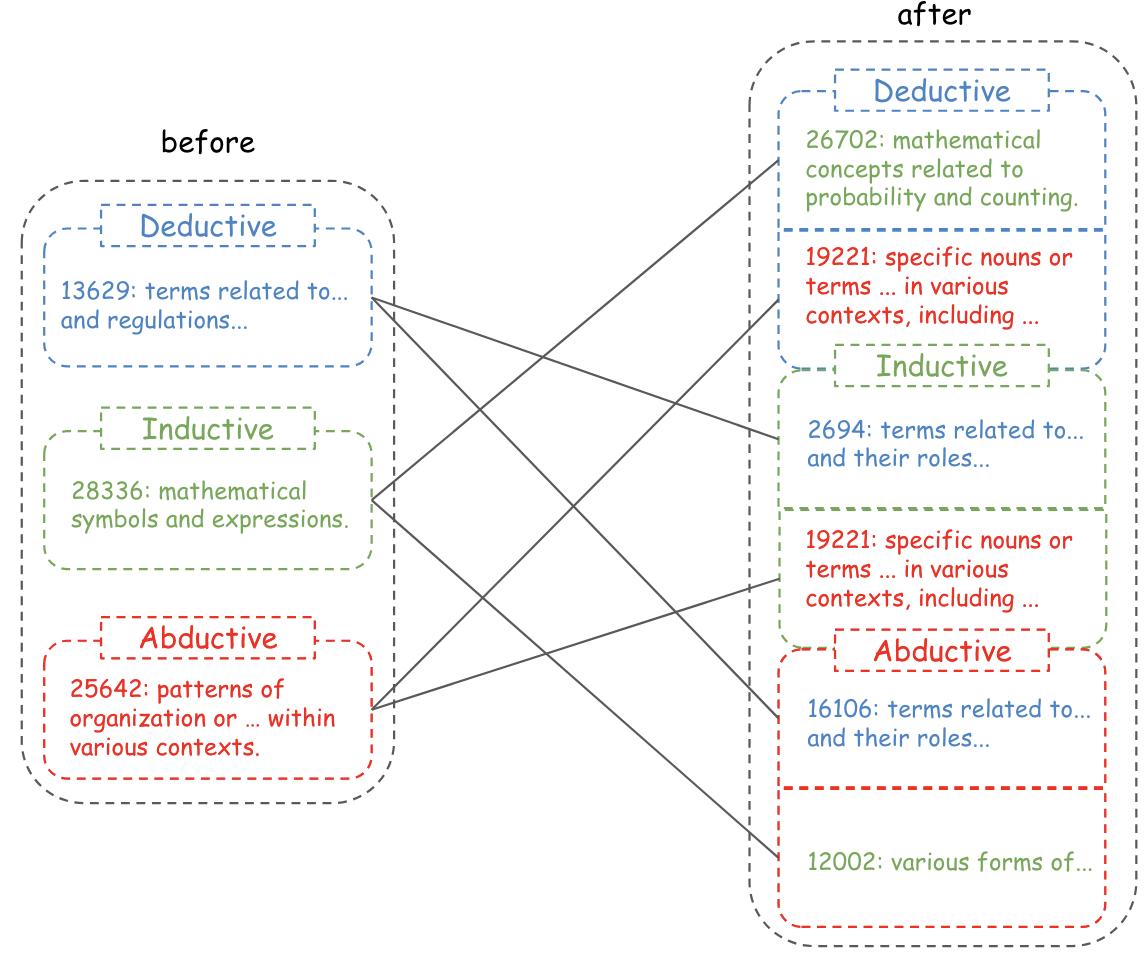
Figure 6: Top feature activations for deductive reasoning post-refinement closely resemble those of previously dominant inductive and abductive features, indicating semantic transfer.
Broader co-activation distribution analysis (over top-k features) indicates that deductive and inductive reasoning move closer in representational geometry post-refinement, while abductive becomes more specialized.
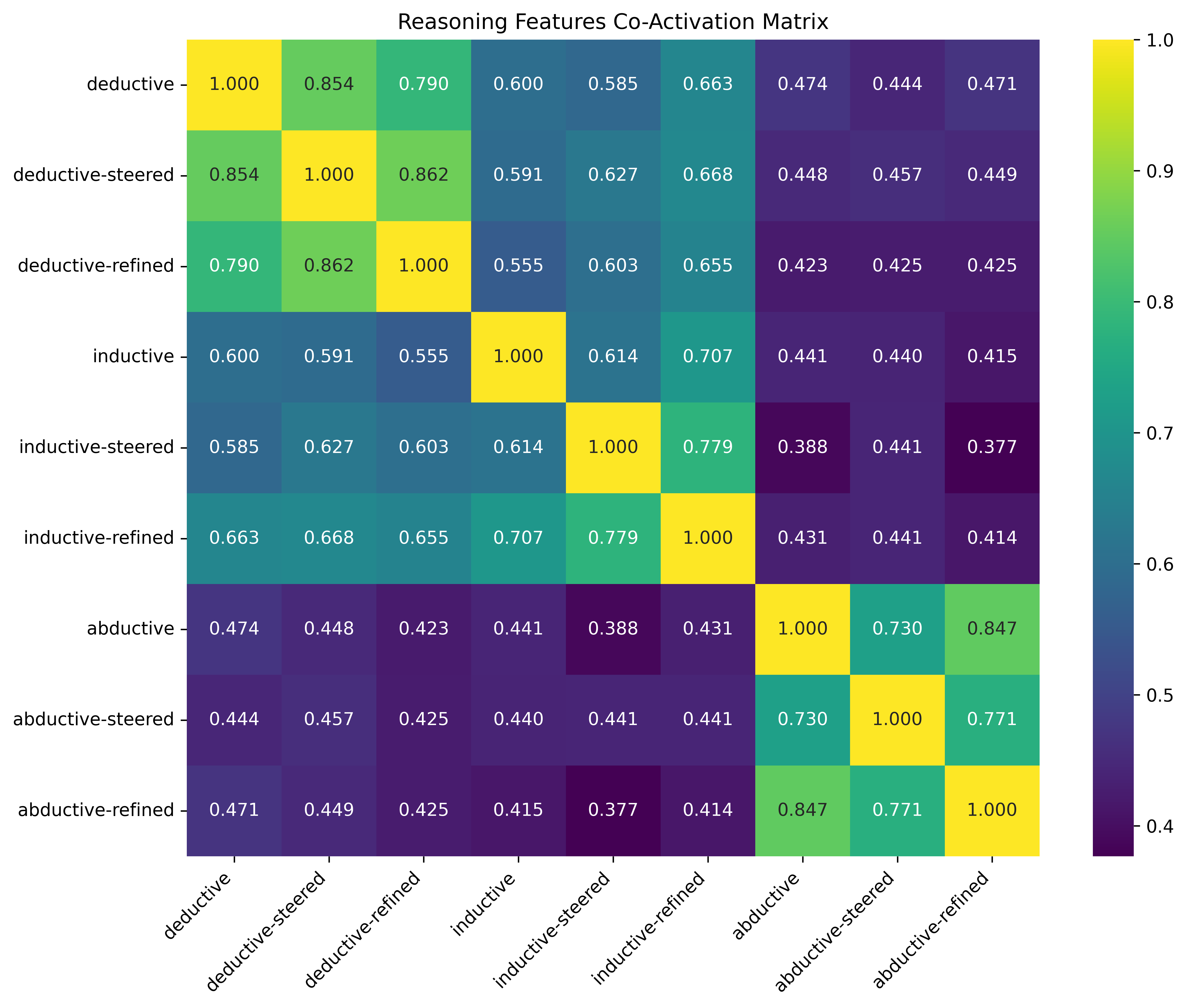
Figure 7: Co-activation matrix shows increased deductive-inductive overlap, decreased abductive similarity, post-refinement.
Circuit and Attention-Level Causal Tracing
Activation patching over attention heads reveals that refined steering preserves core activations, increases localization/sparsity in key heads, and occasionally recruits new heads strongly associated with complementary reasoning content.
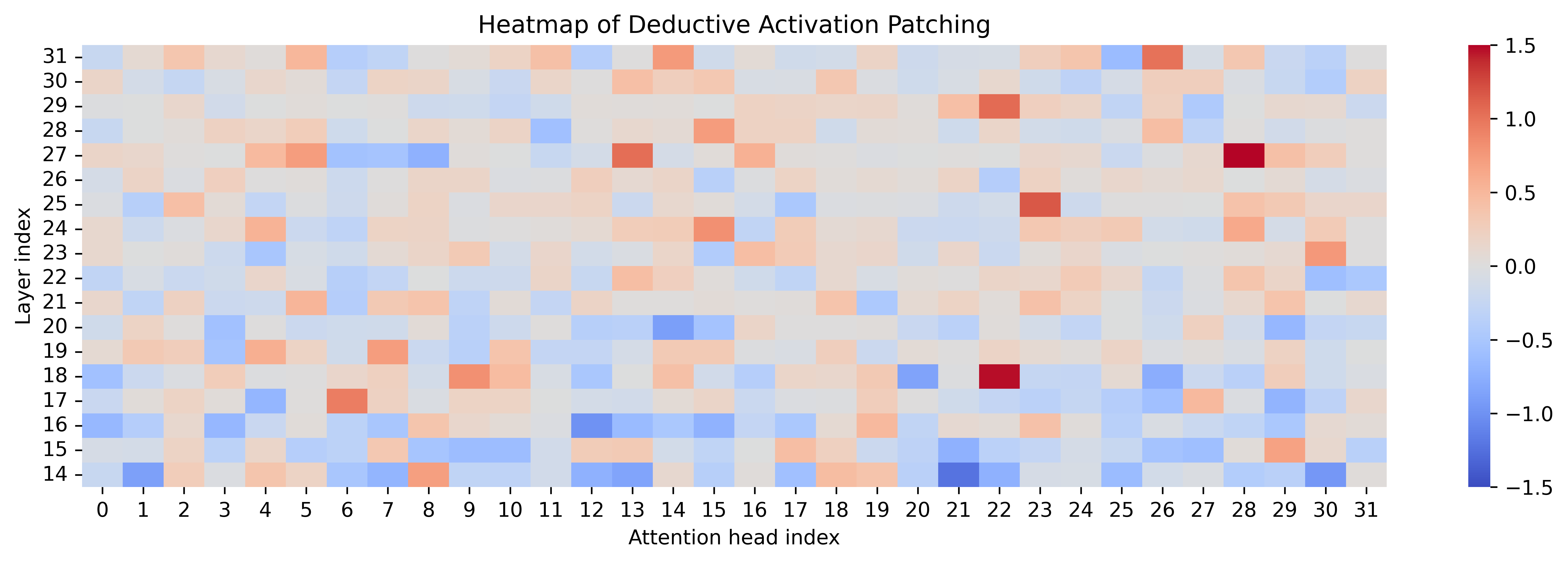
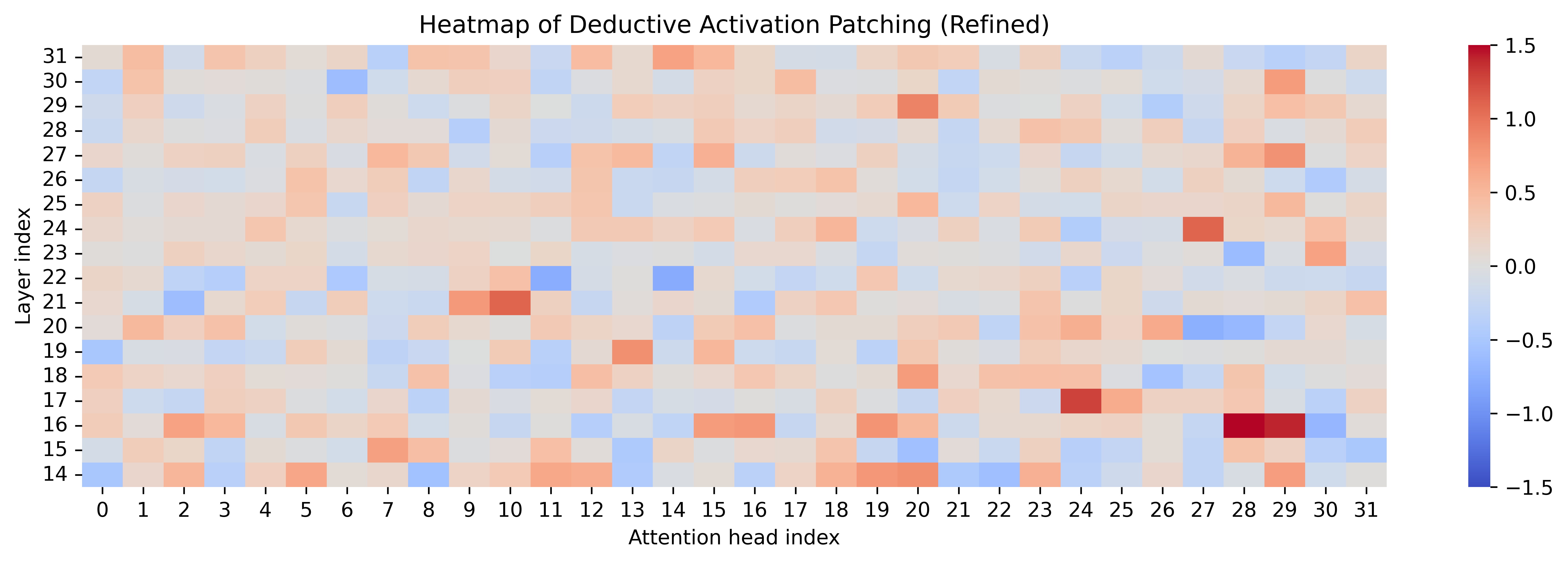
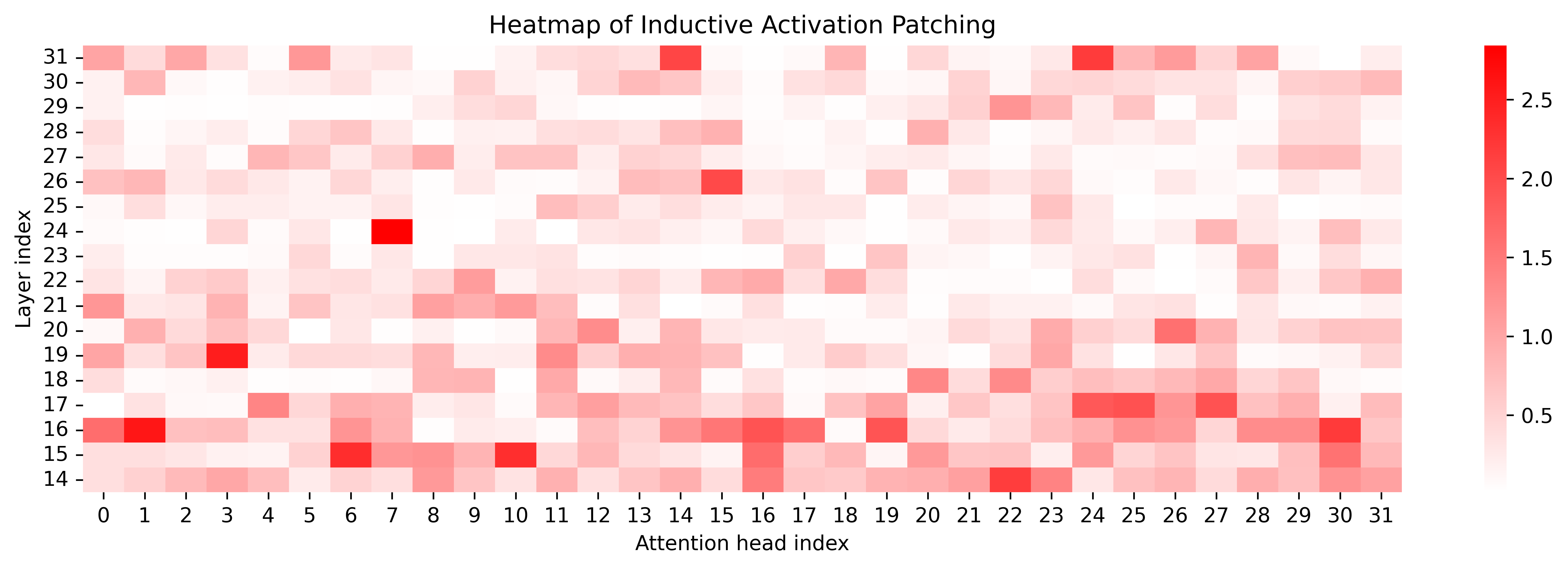
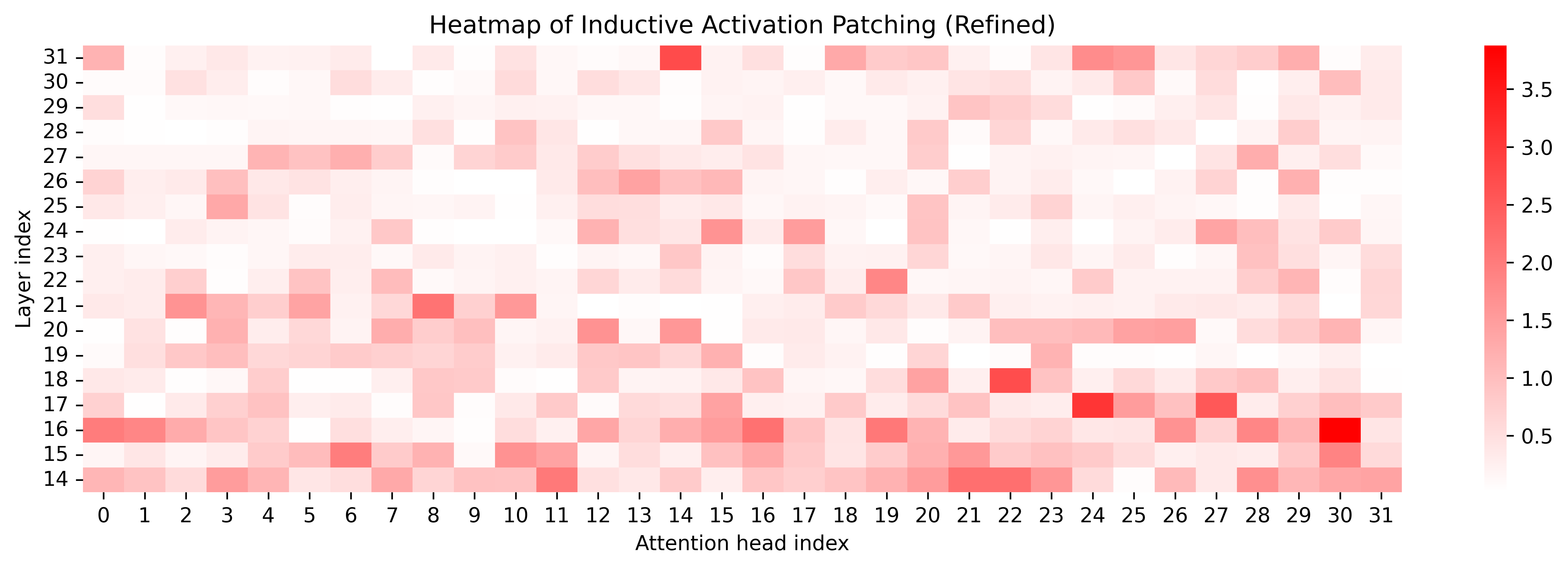
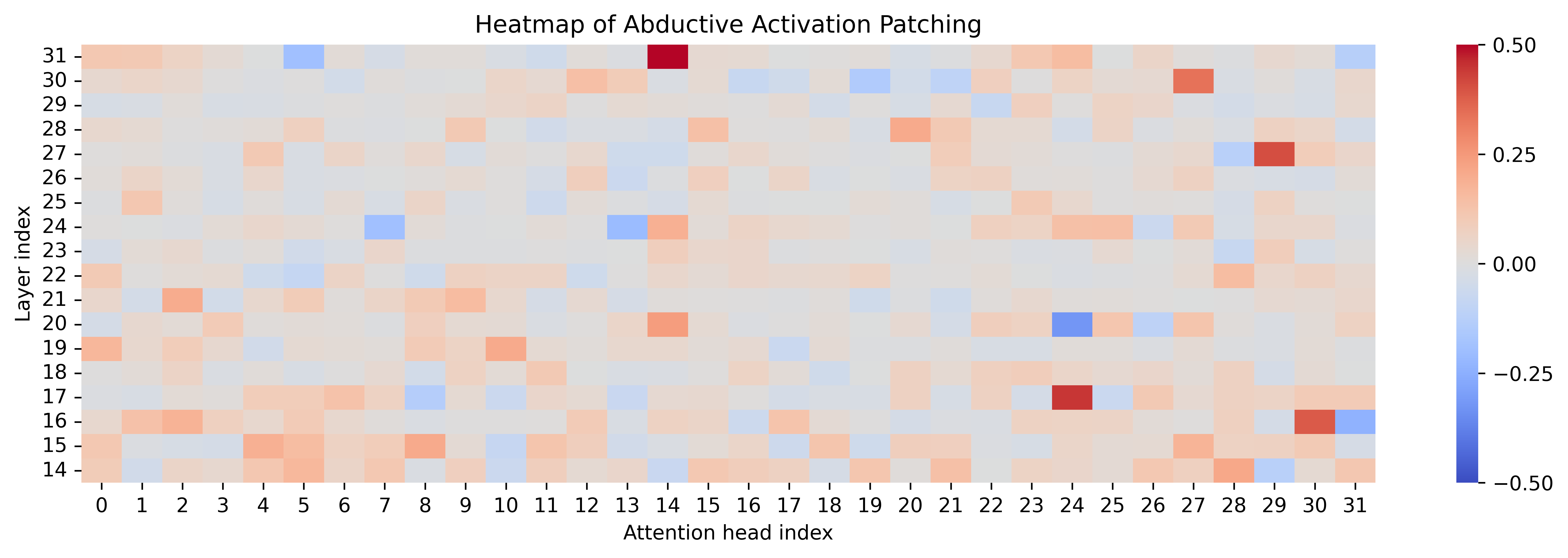
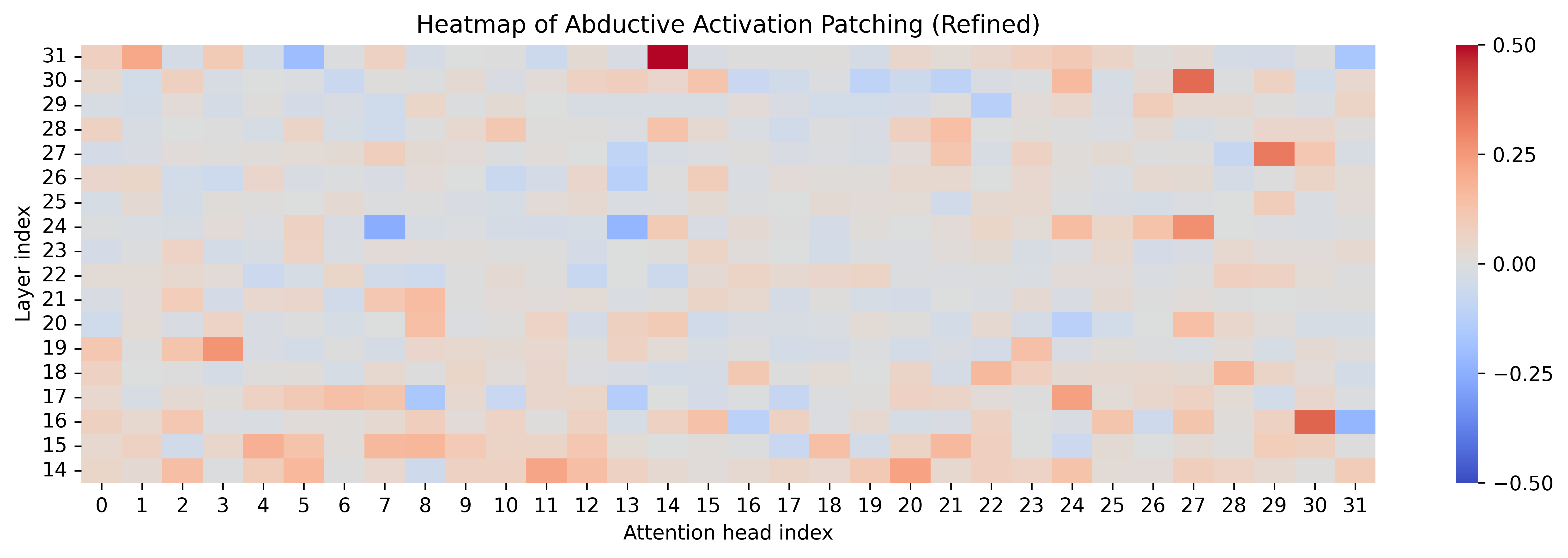
Figure 8: Attention patching heatmaps contrasting naive and refined steering across reasoning types; refined vectors strengthen targeted and complementary activations.
Span-Level Linguistic Analysis
Through log-likelihood shift analysis, representative text spans strongly aligned with each reasoning vector are isolated. Deductive vectors highlight causal connectives (therefore, since), inductive vectors focus on generalization cues, and abductive vectors attend to plausibility/uncertainty expressions. This further supports the semantic specificity of steering.
Theoretical and Practical Implications
These findings have several implications:
- Theoretical: The geometric independence of LLM reasoning representations contradicts cognitive models, suggesting representational divergence between deep learning and human reasoning despite similar observable outputs. The proposed refinement regime improves alignment with cognitive expectations, but the independence prior to intervention is notable.
- Interpretability: The successful extraction and manipulation of reasoning vectors via linear probes and subspace methods supports the burgeoning field of mechanistic transparency in foundation models. SAE-based analyses identify explicit semantic features, opening routes for deeper interpretability work and circuit-level tracing.
- Practical: Complementary steering provides a mechanism for controllable, compositional reasoning enhancement across tasks, improving model robustness and generalization. The approach can potentially inform better LLM architectural designs, calibration protocols, or tailored instruction tuning strategies for complex reasoning workloads.
Future Directions
Potential research avenues include:
- Extending complementary subspace refinement to finer-grained or hybrid reasoning categories (e.g., analogical, counterfactual).
- Generalizing to multilingual and multimodal models.
- Systematically mapping reasoning dynamics across more diverse architectures and broader cognitive benchmarks.
- Leveraging this framework for targeted model editing, interpretability, and alignment interventions.
Conclusion
The paper rigorously establishes that deductive, inductive, and abductive reasoning knowledge can be linearly isolated in LLM activation space—with initial findings indicating orthogonality, in conflict with human cognitive integration. The introduction of SAE-guided complementary refinement induces improved reasoning transfer, interpretability, and task performance, and yields a practical mechanism for more cognitively plausible, controllable reasoning in LLMs. These insights are a substantive contribution to the understanding and engineering of flexible, interpretable reasoning modules within large-scale neural LLMs.