- The paper presents a dynamic regret minimization framework that compares causal controllers to k-lookahead benchmarks to balance exploitation and risk.
- The methodology employs a novel Regret-Bellman operator and prefix dynamic programming to yield finite-memory, stationary policies with theoretical guarantees.
- Numerical experiments in inventory management show that regret-optimal controllers outperform both nominal MDP and robust strategies under shifting and uncertain demands.
Regret-Optimal Control in Finite-State Disturbance-Driven Systems
The paper addresses causal policy design in finite-state disturbance-driven systems, where uncertainties are exogenous disturbances that may not conform to classical i.i.d. stochastic models. Traditional stochastic MDPs optimize expected performance under assumed distributional knowledge, while robust control targets worst-case disturbance realizations, often resulting in conservative control actions. In contrast, this work leverages a dynamic regret framework, comparing causal controllers to lookahead benchmarks evaluated under the same disturbance sequence. This allows the designed policy to remain competitive in favorable regimes while preserving non-trivial performance metrics in adversarial environments.
The system dynamics follow
st+1=f(st,at,wt)
where st is the state, at is the action, and wt is the exogenous disturbance at time t, all taking values in finite sets. The controller's decision rule is causal, depending on the observable history. The regret is measured against a k-lookahead policy—one with access to disturbances up to k steps into the future—on the same pathwise disturbance realization, promoting a strong instance-wise performance comparison.
Theoretical Contributions
The authors rigorously formulate the worst-case dynamic regret minimization as a min-max optimization:
- Objective: Minimize the maximum regret (defined as the difference in cumulative reward between causal and lookahead policies) across all disturbance sequences and lookahead policies.
- Benchmark Policy Class: The lookahead benchmark, Πk, encompasses all deterministic policies with k-step lookahead, subsuming causal policies (k=0).
To resolve the challenge that the regret objective involves two information patterns (causal and st0-lookahead) on the same sequence, the authors provide a constructive solution based on two nested dynamic programming (DP) formulations:
- Regret-Bellman Operator: Defines a min-max DP recursion over an augmented state comprising the causal and lookahead states, along with the st1-long disturbance window. Uniqueness and contractivity of the fixed-point (st2) are established in the infinite-horizon, discounted setting.
- Prefix DP: Handles the first st3 decision epochs where the information patterns do not align. The value function for this DP uses st4 as the terminal cost, synthesizing an optimal regret-minimizing policy from time st5.
Theorem 1 asserts that the optimal regret is computed via the prefix DP's initial value, and the corresponding regret-optimal policy is stationary for st6, depending only on st7, resulting in a controller implementable with finite memory.
The method extends, with modifications, to the finite-horizon case, introducing terminal tail values to address incomplete lookahead over the planning horizon.
The paper evaluates the regret-optimal controller in the context of inventory management, specifically lost-sales systems with Poisson and HMM-structured demand disturbances. The comparison involves:
- MDP Controller: Designed for nominal (average case) demand.
- Robust Controller: Designed for worst-case disturbance minimization.
- Regret-Optimal Controllers: Designed for st8 lookahead, independent of demand model specification.
In i.i.d. Poisson disturbances, regret-optimal controllers interpolate between MDP and robust controllers, adapting dynamically to the demand rate:
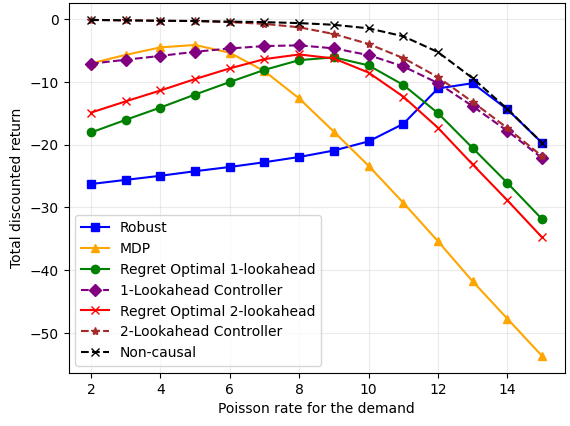
Figure 1: Performance comparison of causal controllers for the inventory management.
For non-i.i.d. demands, modeled via a 2-state hidden Markov process, reward trajectories demonstrate the adaptability of regret-optimal policies. In low-demand regimes, they approach the nominal controller; in high-demand regimes, they exhibit robustness akin to the robust controller. For intermediate regimes, the regret-optimal controllers outperform both baselines, highlighting their practical utility when disturbance structure is only partially known or shifts over time.
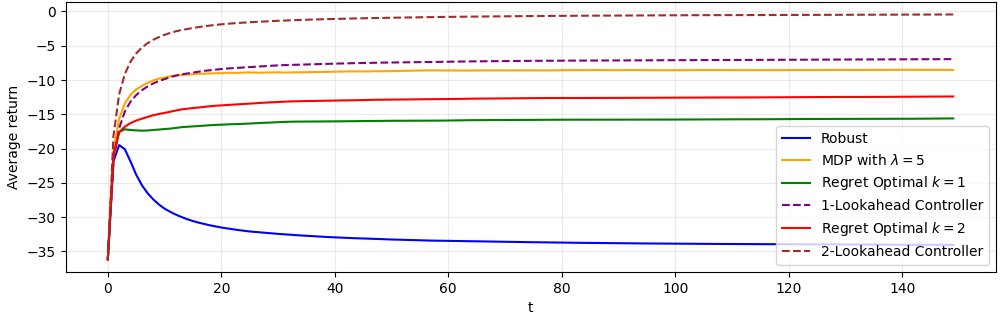
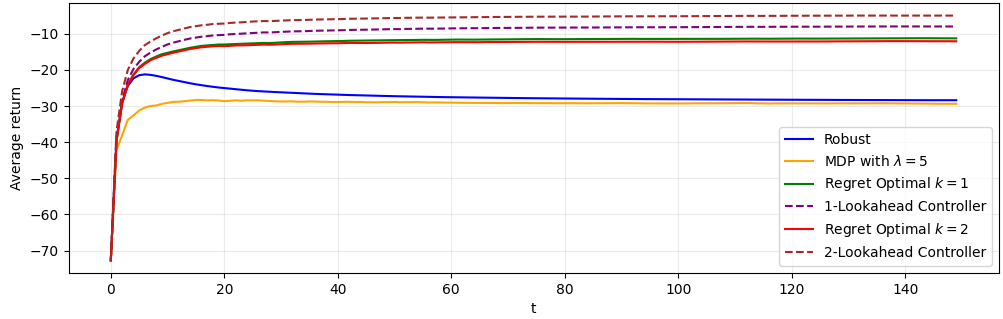
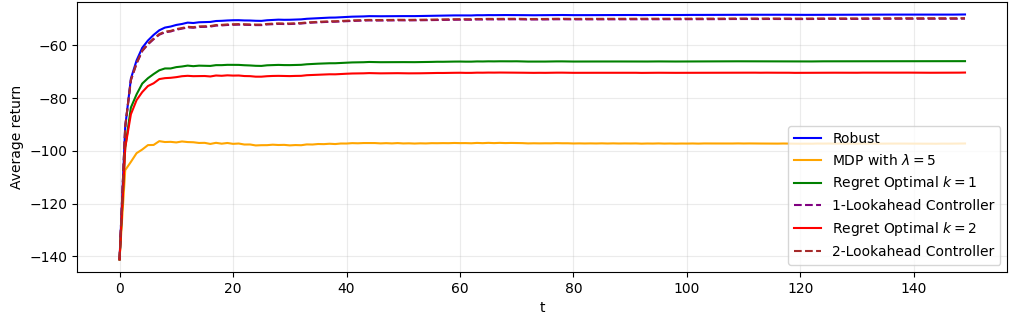
Figure 2: Reward over time for demand regime st9. Regret-optimal controllers balance between nominal and robust policies in HMM-driven demand.
Implications and Future Directions
The regret-optimal framework bridges the gap between MDPs (model-based, stochastic-optimal) and robust control (worst-case optimal), synthesizing policies that interpolate between exploitation and risk aversion without requiring prior knowledge of the disturbance's statistical structure. The fixed-point Regret-Bellman operator is structurally similar to the standard Bellman operator but operates on a higher-dimensional state encompassing both causal and lookahead dynamics.
Practical implications include:
- Distribution-Free Design: Effective when the disturbance distribution is ambiguous or nonstationary.
- Finite-Memory Implementation: The policy's stationarity and dependence on a finite window enable tractable real-world deployments.
- Superior Empirical Performance: Demonstrated situations where regret-optimal controllers surpass both MDP-based and robust policies, especially in environments with temporally structured uncertainties.
Future research directions include:
- Partial Observability: Extending the framework to POMDP-like settings.
- Semi-Stochastic and Distributionally Robust Control: Adapting the regret-based machinery to contexts where disturbance models are only partially known or specified adversarially within ambiguity sets.
- Integration in RL Algorithms: Employing the Regret-Bellman operator as an alternative to classical value iteration for learning in uncertain, structured environments.
Conclusion
This work establishes a mathematically principled, implementable regret-optimal control paradigm for finite-state systems under adversarial disturbances. The dual dynamic programming construction—Regret-Bellman and prefix DPs—yields both theoretical guarantees and empirical advances, offering a new approach to risk-robust, performance-competitive control when disturbance statistics are unknown or changing. The results motivate further development in regret-based adaptive control and reinforcement learning, particularly in data-driven and distributionally ambiguous environments.