LLMs Can Learn to Reason Via Off-Policy RL
Abstract: Reinforcement learning (RL) approaches for LLMs frequently use on-policy algorithms, such as PPO or GRPO. However, policy lag from distributed training architectures and differences between the training and inference policies break this assumption, making the data off-policy by design. To rectify this, prior work has focused on making this off-policy data appear more on-policy, either via importance sampling (IS), or by more closely aligning the training and inference policies by explicitly modifying the inference engine. In this work, we embrace off-policyness and propose a novel off-policy RL algorithm that does not require these modifications: Optimal Advantage-based Policy Optimization with Lagged Inference policy (OAPL). We show that OAPL outperforms GRPO with importance sampling on competition math benchmarks, and can match the performance of a publicly available coding model, DeepCoder, on LiveCodeBench, while using 3x fewer generations during training. We further empirically demonstrate that models trained via OAPL have improved test time scaling under the Pass@k metric. OAPL allows for efficient, effective post-training even with lags of more than 400 gradient steps between the training and inference policies, 100x more off-policy than prior approaches.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper studies how to teach LLMs to “reason” better using reinforcement learning (RL). It points out that the way people usually train LLMs with RL assumes the model is trained on its own latest behavior (“on-policy”), but in real systems that’s often not true. Instead, training often uses data from a slightly older or different version of the model (“off-policy”). The authors propose a new training method, called OAPL, that fully embraces this off-policy reality and still works well, simply, and efficiently.
What questions does the paper try to answer?
The paper asks two clear questions:
- Do we really need on-policy algorithms to improve LLM reasoning with RL?
- Can we build a simple, scalable off-policy RL algorithm that works better in practice?
Their answer: no, on-policy isn’t necessary; yes, a new off-policy method (OAPL) can be stable, effective, and efficient.
How did the researchers approach the problem?
Think of training as having two “roles”:
- Trainer: the part that updates the model’s brain (its weights).
- Inference engine: the part that quickly generates answers.
In modern systems, these two can get out of sync. Even if they share the same weights, they can compute slightly different scores for the same text because they use different software parts or because the inference engine is a few updates behind. That means the trainer learns from data that wasn’t produced by the current trainer—this is off-policy.
Most past approaches try to fix this mismatch by:
- Reweighting the old data to “pretend” it came from the current policy (called importance sampling), or
- Changing the inference engine so it exactly matches the trainer (which can slow things down).
Instead, OAPL accepts the mismatch and designs the training around it.
Here’s the everyday idea behind OAPL:
- Imagine you’re coaching a team using recordings from last week’s games (off-policy). You still want today’s team to improve, but you don’t want them to change so much that they stop playing like the recorded team entirely (they need a “tether”).
- OAPL adds a gentle tether (called KL regularization) that keeps the training policy from drifting too far from the inference policy. This tether says, “Improve your decisions, but don’t become completely different from how you’re currently generating answers.”
- It also learns how much better a specific answer is compared to the average answer for the same question (this is called the “advantage”). In simple terms: advantage = reward of this answer − smoothed average reward of all answers for that question.
How OAPL trains, step by step:
- Sync the trainer and the inference engine so they start aligned.
- Let the inference engine generate answers (possibly asynchronously).
- For each question, compare each answer’s reward to a smoothed average of rewards for that question (this average is computed using a soft “max” controlled by a parameter β, which smooths between “best answer wins” and “simple average”).
- Train the policy with a simple squared-error objective that pushes the model’s scores to match those advantages, while staying close to the inference engine’s behavior (the tether).
- Only occasionally re-sync the trainer and inference engine. Between syncs, it’s fully off-policy.
Analogy for the objective: You’re fitting the model’s “confidence boost” for an answer to how much better that answer actually is than the typical answer, while holding the model close to its current generator so it doesn’t spin out.
What’s special about OAPL compared to common methods:
- No importance weighting, no token deletion, and no tricky clipping heuristics.
- Works even when the inference engine is very lagged (hundreds of updates behind).
- Uses a simple regression loss, which tends to be stable.
What did they find?
In short: OAPL works well and is efficient.
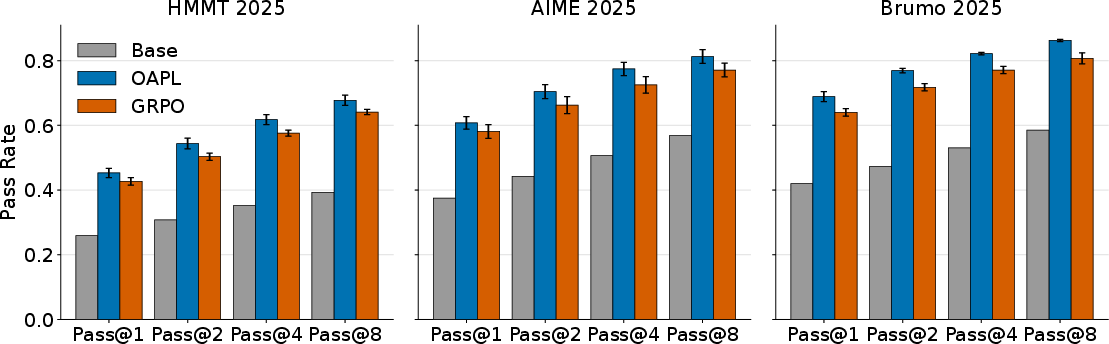
On math reasoning benchmarks (AIME-25, HMMT-25, BRUMO-25):
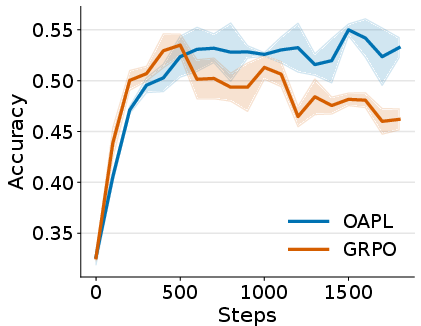
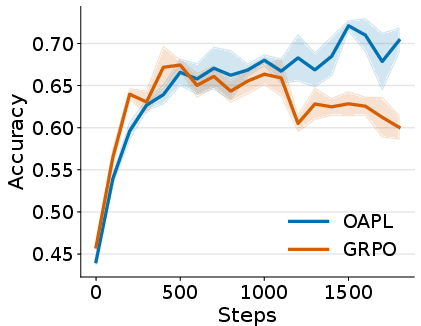
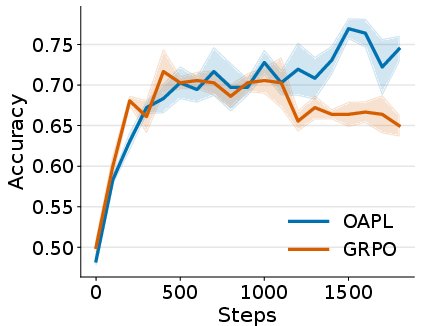
- OAPL generally beats a strong baseline called GRPO (a popular on-policy method), even when GRPO adds importance sampling to handle off-policy data.
- OAPL trains more stably: its performance curves are smoother and reach higher accuracy.
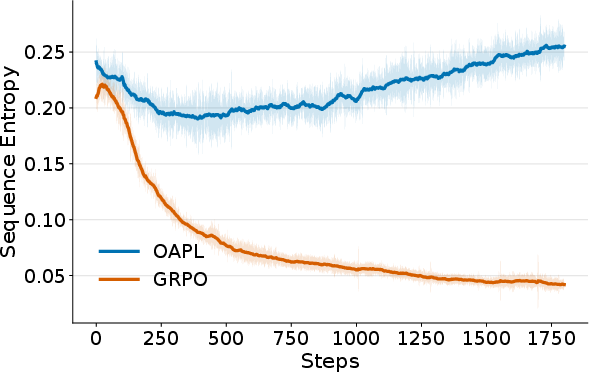
- OAPL maintains higher “entropy” (variety) in its answers during training, which helps with Pass@k (explained below).
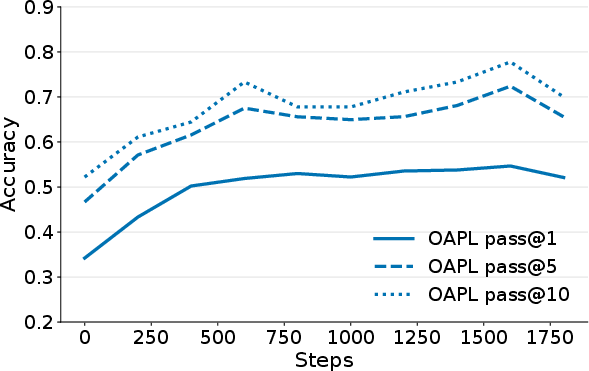
- It scales better with Pass@k (the model gets more benefit when allowed to try more attempts per question).
Pass@k explained:
- Imagine you allow the model k chances to answer a question. Pass@k is the percentage of questions the model gets right in those k tries. Higher k means more chances.
- OAPL improves Pass@k across k from small to large, often more than GRPO and the base model, suggesting it learns genuinely better strategies—not just sharper guesses.
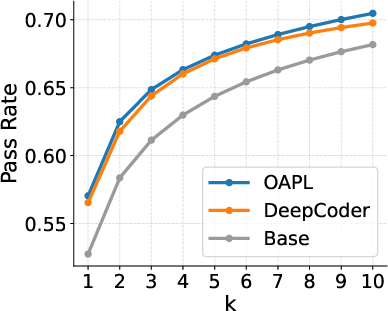
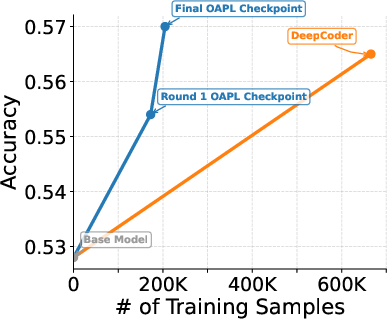
On code generation (LiveCodeBench):
- The authors train a model with OAPL using a highly off-policy setup (the inference engine lags by ~400 gradient updates).
- Their model matches or slightly outperforms “DeepCoder,” a public model trained with GRPO plus extra heuristics.
- OAPL reaches this with about three times fewer training samples (more sample-efficient).
Robustness to lag:
- Even when the inference engine is synced only every 100 training steps, OAPL stays stable and keeps improving—showing it handles strong off-policy settings well.
Why is this important?
- Real-world training systems are asynchronous and often off-policy. OAPL is designed for that reality, so it fits modern infrastructure without heavy surgery.
- It reduces the need for complicated fixes (like importance sampling and special clipping), making training simpler and potentially faster.
- It improves reasoning ability, stability, and test-time scaling (better Pass@k), which matters for tasks like math and coding that need careful thinking.
- It’s sample-efficient—getting good results with fewer generated examples—saving time and compute.
What could this mean for the future?
- Off-policy RL might become the default way to post-train reasoning LLMs, aligning better with practical systems.
- We could train models more asynchronously and reuse old data more effectively, including human or offline datasets.
- The OAPL idea (tethering to the current generator while learning advantages) could inspire new algorithms that are both simple and robust.
- Better stability and scaling mean more reliable models in real applications: tutoring, coding assistants, scientific reasoning, and more.
Overall, the paper suggests a shift in mindset: instead of forcing training to be perfectly on-policy, embrace off-policy data and design the algorithm around it. That can make LLMs reason better, train more smoothly, and use fewer resources.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points summarize concrete gaps and open questions left unresolved by the paper, prioritized to guide future research and experimentation:
- Convergence guarantees under function approximation: No proof or finite-sample analysis shows that minimizing the squared regression objective converges to the KL-regularized optimum when using neural policies, approximate , and asynchronous updates with a periodically changing reference .
- Impact of policy lag on stability and optimality: The method empirically tolerates lags up to 100 (math) and ~400 (code), but lacks a principled characterization of how performance degrades with lag and the KL divergence between and ; bounds or diagnostics linking lag, KL drift, and learning stability are missing.
- Sensitivity to the two temperatures ( for and for regression): The paper introduces separate ’s without a principled selection strategy or theoretical rationale; no ablation quantifies their effect on bias/variance, stability, and Pass@k scaling.
- Robustness to reward scaling and non-binary rewards: The estimator and theory are motivated for binary rewards; it remains unclear how OAPL behaves under graded rewards (e.g., partial credit, multi-test-case code rewards) and whether specific normalization or clipping improves stability.
- Group size for the log-sum-exp estimator: There is no analysis of how affects estimator bias/variance, sample efficiency, and training dynamics across tasks; guidance on minimal for reliable is missing.
- Mixtures of behavior policies and buffer management: OAPL clears the buffer at each sync to avoid mixed distributions. The trade-off between estimator purity and sample reuse is unquantified, and principled methods for handling mixed-policy data (e.g., per-group normalization, weighting, or stratified buffers) are unexplored.
- Use with purely offline datasets (no access to behavior-policy log-probs): OAPL requires for each sample; adaptation to offline corpora lacking behavior-policy log-probabilities (e.g., human-generated data) is not addressed.
- Calibration of log-probabilities across engines: The method directly uses log-probs from , yet the paper does not quantify or correct systematic biases caused by kernel differences, quantization (FP16/BF16), or MoE routing mismatches between trainer and inference engines.
- Fairness and breadth of baselines: Comparisons are limited to GRPO with importance sampling; there is no empirical comparison to other recent off-policy LLM RL methods (e.g., REBEL/REFUEL/AGRO, tapered off-policy REINFORCE, trust-region masking, Q-learning variants), leaving relative advantages unverified.
- Credit assignment at token/process level: OAPL optimizes sequence-level rewards without exploring process/step-level rewards, token-level advantages, or off-policy value learning for improved credit assignment on long-horizon reasoning tasks.
- KL regularization to the reference (pretrained) policy: The paper omits KL-to-reference during training. The impact of OAPL on alignment, safety, style preservation, and catastrophic drift relative to the base model is not evaluated.
- Exploration–exploitation trade-offs: How (and the KL to ) affect exploration and diversity versus correctness is not systematically studied; no diversity metrics or error-type analyses accompany the entropy plots.
- Generalization beyond math and code: OAPL is not tested on other reasoning domains (logical proofs, multi-hop QA), interactive/multi-turn tasks, tool-use, or non-verifiable objectives, leaving cross-domain robustness and applicability uncertain.
- Model-scale and architecture generality: Results are limited to Qwen3-4B-Thinking and DeepSeek-R1-Distill-14B. Scaling laws (across sizes), MoE architectures, long-context specialized models, and extreme-length settings are not examined.
- Resource and throughput measurements: While OAPL is claimed to be efficient and asynchronous, the paper does not report wall-clock time, GPU-hours, throughput, memory footprint, or system-level bottlenecks versus GRPO and inference-engine–modified baselines.
- Pass@k evaluation robustness: Pass@k is computed from 10–20 rollouts. No sensitivity analysis shows how conclusions change with more samples, different decoding strategies, or evaluation randomness; statistical significance across seeds and benchmarks is limited.
- Data filtering effects in code training: The code experiments filter prompts with zero correct responses and use a 4k subset due to resource constraints; the bias introduced by this filtering and its impact on generalization to harder or unseen tasks is not quantified.
- Distribution-shift diagnostics: The paper does not measure or report the evolving KL(π || π_{\text{vllm}}), entropy distributions, or advantage residuals over training to diagnose when off-policy drift becomes harmful.
- Stability under extreme off-policyness: Beyond L≈400 (code) and 100 (math), the failure modes (e.g., advantage-target mismatch, gradient explosion, collapse) are not explored, nor are safeguards (e.g., adaptive syncing, lag-aware β scheduling).
- Hyperparameter robustness: There are no ablation studies for L (sync interval), batch size, learning rates, optimizer choices, normalization strategies, or advantage-target smoothing that would help practitioners tune OAPL reliably.
- Handling long contexts and memory constraints: OAPL uses up to 64K generation lengths but does not analyze memory, KV-caching impacts, or interaction between long-context kernels and off-policy training stability.
- Potential for reward hacking or unintended behaviors: With no alignment regularizers, OAPL’s susceptibility to reward hacking, degenerate strategies, or adversarial reward misspecification remains unchecked.
- Combining OAPL with importance sampling when needed: Scenarios where mixed-policy buffers or highly stale data are unavoidable could benefit from lightweight IS correction; the paper does not examine hybrid designs or variance-reduction strategies compatible with OAPL.
- Theoretical basis for using distinct ’s: Using lacks a formal justification; deriving conditions where distinct temperatures improve convergence or stability would make the design principled.
- Leveraging human preference data: The conclusion suggests using human/offline data, but the mechanics (reward modeling, aggregation, preference-based rater noise, and integration with the OAPL objective) are unspecified.
- Release and reproducibility gaps: Math training checkpoints are “coming soon,” and some evaluations (e.g., DeepCoder discrepancy) note reproducibility issues; complete code, configs, and seeds for all experiments would strengthen replicability.
Practical Applications
Practical Applications of “LLMs Can Learn to Reason Via Off-Policy RL”
Below, we translate the paper’s findings and method (OAPL) into real-world applications. Each item is categorized as Immediate or Long-Term and, where relevant, mapped to sectors and potential tools or workflows. Assumptions and dependencies are noted per application to clarify feasibility.
Immediate Applications
These can be deployed now with current tooling (e.g., HuggingFace Transformers/TRL, vLLM, Databricks, standard RLHF stacks), using OAPL’s off-policy, asynchronous training design.
- Production-ready RL post-training without inference engine modifications
- Sector: software, platform/infra, AI DevOps
- Application: Replace GRPO/PPO-like objectives with OAPL to stabilize reasoning RL post-training in distributed setups where trainer and inference differ (e.g., vLLM vs. HF kernels), avoiding importance sampling ratios, token deletions, or inference customization.
- Tools/workflows: Integrate OAPL as a plugin module in existing RLHF pipelines; set policy lag
L(e.g., 50–400), maintain a shared data buffer, periodically sync trainer and inference weights, clear buffer on sync; monitor KL-to-inference and entropy. - Assumptions/dependencies: Access to inference engine log-probabilities; verifiable rewards; hyperparameter tuning for
β1,β2, andL; periodic synchronization between trainer and inference engines.
- Sample-efficient training of coding assistants for internal developer productivity
- Sector: software engineering
- Application: Fine-tune open-source base coders (e.g., Distill Qwen variants) via OAPL on curated task sets to match or exceed GRPO baselines with ~3x fewer generations (lower compute, faster iteration).
- Tools/workflows: Two-stage offline rollout training (generate G responses per prompt, filter for solvable prompts, run OAPL for 1–4 epochs, sync per epoch), evaluate Pass@k; deploy as IDE copilots or CI bots.
- Assumptions/dependencies: Tasks with verifiable rewards (unit tests); non-zero success rate in offline rollouts; long-context inference capability (e.g., 32K–64K tokens for complex benchmarks).
- Math/STEM reasoning tutors that benefit from improved Pass@k scaling
- Sector: education
- Application: Train small-to-mid LLMs (e.g., 4–14B) with OAPL on math datasets (AIME/HMMT-like tasks), then expose multi-sample inference (dynamic
k) for student help, practice exams, or step-by-step solvers. - Tools/workflows: Curriculum-specific prompt sets, group rollouts per prompt, OAPL regression update; test-time sampling budgets that adaptively increase
kfor harder items. - Assumptions/dependencies: Binary/verifiable reward functions; stable long-context generation; acceptance of multi-sample inference cost.
- Asynchronous RL training pipelines that re-use stale/off-policy data safely
- Sector: MLOps/platforms, cloud
- Application: Decouple data generation and optimization (trainer and vLLM can run asynchronously), leverage buffers even with policy lag >100 steps without deleterious variance or collapse.
- Tools/workflows: Queue-based rollout generation, OAPL loss on buffered batches; scheduled syncs (e.g., every
Ltrainer steps); entropy and Pass@k monitoring dashboards. - Assumptions/dependencies: Controlled lag settings; buffer hygiene (clear on sync); reward computation integrated into pipelines.
- Cost- and energy-efficient RL for public and enterprise teams
- Sector: policy (green AI), enterprise IT, academia
- Application: Use OAPL’s improved sample efficiency to achieve target accuracy with fewer generations, reducing compute budgets and carbon footprint; support grant-funded research with limited resources.
- Tools/workflows: Compute budgeting with per-epoch syncs (
L), offline datasets, Pass@k-based evaluation; carbon tracking integrated into training runs. - Assumptions/dependencies: Availability of benchmarks with verifiable rewards; institutional acceptance of off-policy RL methods; monitoring for distribution drift (no fixed KL-to-reference in OAPL).
- Better inference-time strategies leveraging improved Pass@k
- Sector: cross-sector (software, healthcare admin, finance ops)
- Application: Adopt multi-sample inference workflows where raising
kpredictably increases task success (enabled by OAPL’s entropy behavior and scaling). - Tools/workflows: “Budgeted inference” logic: start with
k=1, escalate tokin {5, 10, 64, 256} based on task difficulty or target SLA; result verification hooks (tests/validators). - Assumptions/dependencies: Access to verifiers; acceptance of increased inference cost on harder items; product UX for multi-sample aggregation.
- Open-source training baselines for off-policy RL in LLMs
- Sector: academia, open-source community
- Application: Use OAPL as a reproducible baseline for studies on reasoning RL, policy lag, and training stability; simplify experiments by avoiding IS/clipping variants.
- Tools/workflows: Shared offline datasets; OAPL loss implementation; standardized logging of KL-to-inference, entropy, Pass@k.
- Assumptions/dependencies: Public model weights and datasets; agreed-upon evaluation protocols (e.g., unbiased Pass@k estimators).
- Internal code-quality agents with verifiable rewards
- Sector: software/product engineering
- Application: Train review/refactor agents to produce code meeting style/tests (binary reward via unit tests or static analysis); deploy in pull-request workflows.
- Tools/workflows: Automated test suites as reward functions; OAPL training; multi-sample suggestions ranked by test pass rate.
- Assumptions/dependencies: Robust test coverage; access to repo and CI pipeline; privacy/security constraints.
- Reasoning assistants for document-centric domains with verifiable checks
- Sector: finance (report reconciliation), legal ops (citation consistency), healthcare admin (coding/claims)
- Application: Use OAPL to fine-tune assistants on tasks with definable pass/fail criteria (e.g., coding ICD-10 with standard rule validators).
- Tools/workflows: Task-specific validators (schemas, rule engines), group rollouts and OAPL updates, Pass@k at inference for difficult cases.
- Assumptions/dependencies: High-quality reward validators; domain data access; guardrails for compliance and privacy (since OAPL does not enforce KL-to-reference safety by default).
Long-Term Applications
These require further research, scaling, domain-specific reward design, or integration into broader systems.
- Unified off-policy RLHF across heterogeneous feedback sources
- Sector: platform/infra, alignment
- Application: Extend OAPL to integrate human preference data, synthetic reasoning traces, and offline corpora in a single off-policy framework; increase sample efficiency and throughput without IS variance.
- Tools/workflows: Multi-reward aggregation pipelines; off-policy value learning for better credit assignment; reward model calibration.
- Assumptions/dependencies: Reliable, well-calibrated reward models; safety constraints; scalable data orchestration.
- Continual learning systems with periodic syncs and buffer hygiene
- Sector: enterprise AI, SaaS platforms
- Application: Deploy OAPL for continuous post-training on live logs, with scheduled syncs and buffer clearing, while minimizing catastrophic drift and maintaining entropy.
- Tools/workflows: Live data collection, drift monitoring, entropy/KL dashboards, rolling Pass@k audits.
- Assumptions/dependencies: Robust data governance; real-time reward computation or proxies; drift mitigation without fixed KL-to-reference.
- Reasoning agents for complex domains with composite rewards
- Sector: healthcare (clinical decision support), finance (risk analysis), energy (grid operations), robotics (language-to-action planning)
- Application: Combine verifiable subtasks into composite or hierarchical rewards; train OAPL-enhanced agents that plan, verify, and adapt strategies in long-horizon tasks.
- Tools/workflows: Task decomposers, multi-stage validators, off-policy value functions for credit assignment, long-context models with efficient attention.
- Assumptions/dependencies: High-quality domain validators; safe reward design to avoid gaming; long-context hardware support.
- Adaptive inference budgeting strategies optimized for Pass@k
- Sector: product/UX across industries
- Application: Learn policies that explicitly optimize for test-time scaling so systems choose
kdynamically based on difficulty, cost, and user SLAs (e.g., auto-escalation fromk=1tok=64when confidence is low). - Tools/workflows: Confidence estimators, cost-aware inference orchestrators, A/B testing for user satisfaction vs. latency.
- Assumptions/dependencies: Accurate difficulty/confidence estimates; user-acceptable latency trade-offs; cost controls.
- Safety-aware OAPL variants with KL-to-reference and constraint handling
- Sector: alignment, regulation
- Application: Introduce explicit regularization to a trusted reference policy and constraint checks to ensure safety/harmfulness bounds while preserving off-policy efficiency.
- Tools/workflows: Dual-KL objectives (to inference and reference), constraint-based reward shaping, safety audits.
- Assumptions/dependencies: Reliable safety reference models; agreed safety standards; monitoring for distribution shifts.
- Low-compute RL democratization for public research and startups
- Sector: policy, academia, startup ecosystem
- Application: Establish best-practice “efficient RL” playbooks that standardize OAPL pipelines for limited budgets, enabling broader participation in reasoning LLM research.
- Tools/workflows: Shared datasets/benchmarks, reproducible training recipes (offline rollouts,
Lschedules), transparent energy/carbon metrics. - Assumptions/dependencies: Community governance for benchmarks; access to long-context models and inference logs; lightweight auditing.
- Cross-modal extensions (vision, speech) with off-policy reasoning training
- Sector: multimodal AI, robotics
- Application: Train multimodal models using OAPL-like off-policy objectives with verifiers (e.g., programmatic checks for scene understanding or action success), reducing the need for on-policy sampling.
- Tools/workflows: Modality-specific reward verifiers; buffered rollouts from mixed sensors; per-modality syncs.
- Assumptions/dependencies: Verifiable, robust rewards in non-text domains; consistent log-probability access across modalities.
- Enterprise-grade monitoring and governance for off-policy RL
- Sector: compliance, risk management
- Application: Build dashboards to track policy lag, KL-to-inference, entropy, and Pass@k scaling; trigger guardrails when training instability (e.g., entropy collapse) is detected.
- Tools/workflows: Observability stacks, anomaly detection on training dynamics, policy rollback mechanisms.
- Assumptions/dependencies: Instrumentation in training loops; standards for acceptable divergence; organizational processes for intervention.
- Domain-specific validators and reward libraries
- Sector: healthcare, law, finance, engineering
- Application: Create reusable validation modules (tests, rule engines, simulators) for task verifiability that plug into OAPL pipelines (e.g., claims adjudication rules, contract citation checks, risk metric thresholds).
- Tools/workflows: Validator registries, reward definition SDKs, benchmark suites with pass/fail scoring.
- Assumptions/dependencies: Domain expert input; maintenance of evolving rule sets; auditability and transparency requirements.
- Research into off-policy value learning and credit assignment for LLMs
- Sector: academia, advanced R&D
- Application: Extend OAPL with explicit value-function training to improve credit assignment on long sequences and weakly verifiable settings, inspired by SAC/DDPG methods.
- Tools/workflows: New loss formulations combining
ln(π/π_vLLM)with learnedV*; exploration of distributional/value methods; large-scale ablation studies. - Assumptions/dependencies: Additional compute for value training; careful stability controls; open datasets for reproducibility.
In summary, OAPL enables practical, stable, and efficient off-policy RL for LLM reasoning under real-world system constraints (trainer–inference mismatch, asynchronous pipelines, large policy lag). Immediate wins include replacing fragile on-policy objectives and building cost-effective coding/math assistants. Long-term gains involve robust, safety-aware, multimodal, and continual learning systems with adaptive inference budgets and domain-specific reward ecosystems.
Glossary
- Advantage (optimal advantage): The difference between a trajectory’s reward and a baseline value; measures how much better an action is than expected. "optimal advantage "
- A*PO (PO): An optimization objective that regresses the log-policy ratio onto an estimate of the optimal advantage. "We adopt the PO objective"
- Asynchronous RL training: Training where data generation and parameter updates occur out of sync, often causing policy lag. "an asynchronous RL training framework"
- Clipping operator: A PPO/GRPO mechanism that limits the policy update by clipping the likelihood ratio to a range. "GRPO uses a clipping operator on $\frac{\pi(y|x)}{\pi_{\text{old}(y|x)}$"
- Closed-form solution (of KL-regularized RL): An analytical expression for the optimal policy/value under KL regularization. "Leveraging the closed-form solution of KL-regularized RL"
- Conservative policy iteration: A policy improvement scheme that constrains changes to ensure stability. "This is motivated by conservative policy iteration"
- Credit assignment: The problem of attributing reward to actions or tokens to guide learning. "for better credit assignment"
- Data buffer: A storage of generated rollouts used for off-policy updates. "Data buffer "
- DDPG (Deep Deterministic Policy Gradient): An off-policy actor-critic algorithm for continuous control. "off-policy algorithms such as DDPG and SAC"
- Distribution sharpening: A phenomenon where RL narrows the output distribution without improving broader sampling performance. "does not just perform base model distribution sharpening."
- Entropy collapse: A degradation where the policy becomes overconfident and loses diversity. "does not cause entropy collapse"
- Fisher information: A measure of the amount of information that observed data carries about parameters; used for masking/variance control. "estimate Fisher information for token masking"
- GRPO (Group Relative Policy Optimization): An RL objective for LLM post-training that uses group-relative baselines and PPO-style clipping. "GRPO uses a clipping operator"
- Group-relative baselines: Baselines computed across groups of rollouts to reduce variance. "group-relative baselines for variance reduction"
- Importance sampling (IS): A technique that reweights off-policy data by likelihood ratios to correct distribution mismatch. "importance sampling (IS)"
- Importance weights: The ratios used in importance sampling to reweight samples. "introducing additional importance weights"
- Inference engine: The serving/generation backend that produces rollouts and log-probabilities (e.g., vLLM). "the inference engine (e.g. a vLLM model \citep{kwon2023efficient}) may produce different log-probabilities"
- KL divergence: A measure of difference between two probability distributions; used to quantify train–inference mismatch. "measure the KL divergence between the inference engine and trainer"
- KL-regularized RL: Reinforcement learning that adds a KL penalty to keep the policy close to a reference. "KL-regularized RL formulation"
- KL reference: The policy used as the reference distribution inside the KL term. "serves as the KL reference"
- KL term: The regularization component penalizing divergence from a reference policy. "where the KL term explicitly prevents the training policy from moving too far away from the inference policy."
- Lagged Inference policy: An inference policy that is behind the trainer’s parameters due to asynchronous updates. "Optimal Advantage-based Policy Optimization with Lagged Inference policy"
- Least-squares regression loss: A squared-error objective used here to fit log-policy ratios to estimated advantages. "reduces to a simple least-squares regression loss"
- Likelihood ratio: The ratio of target-policy to behavior-policy probabilities used in IS and PPO-type updates. "computes the likelihood ratio $\frac{\pi(a|x)}{\pi_{\text{vllm}(a|x)}$"
- OAPL: The proposed off-policy algorithm that regresses optimal advantages against log-policy ratios using a lagged inference policy. "abbreviated OAPL."
- Off-by-one asynchronous training: A setup where the behavior policy lags the trainer by at most one iteration. "we use off-by-one asynchronous training."
- Off-policy: Training on data generated by a different policy (e.g., a lagged or mismatched inference engine). "making the data off-policy by design."
- On-policy: Training on data generated by the current policy being optimized. "not truly on-policy."
- Pass@k: The probability that at least one of k samples solves a task, typically estimated from multiple rollouts. "test time scaling under the Pass@k metric."
- Policy collapse: A failure mode where the policy degenerates, often associated with instability or excessive KL. "training instability and policy collapse in GRPO."
- Policy gradient methods: RL algorithms that optimize policies via gradients of expected return (e.g., REINFORCE, PPO). "classic policy gradient methods (e.g., REINFORCE)"
- Policy lag: The delay in parameters between the trainer and inference policy during asynchronous pipelines. "the policy lag (off-policyness) can be as large as 400 gradient updates"
- PPO (Proximal Policy Optimization): A policy gradient method using clipped objectives to constrain updates. "its predecessor PPO"
- PPO-style likelihood ratio: The ratio between current and previous policy probabilities used by PPO/GRPO. "is the PPO-style likelihood ratio"
- Q-function: The expected return from a state-action pair; alternatives to policy-gradient approaches learn a Q-function. "learning a Q-function"
- REINFORCE: A classic Monte Carlo policy gradient algorithm using log-likelihood gradients. "REINFORCE"
- Reference policy (): A fixed policy used as a baseline for KL regularization in some methods. "this is not the usual KL regularization to $\pi_{\text{ref}$"
- RLOO estimator: A leave-one-out group baseline estimator to reduce variance in RL for sequence models. "similar to the RLOO estimator"
- Rollouts: Complete trajectories or sequences generated by a policy for training/evaluation. "throwing away entire rollouts that are too off-policy."
- Sample efficiency: Performance achieved per unit of training data; higher efficiency means fewer samples to reach a target. "significant increases in sample efficiency"
- Soft Actor-Critic (SAC): An off-policy actor-critic algorithm maximizing entropy-regularized return. "DDPG and SAC"
- Synchronization interval (L): The number of trainer updates between synchronizations with the inference engine. "Every iterations of the trainer"
- Test-time scaling: How performance improves as the number of sampled outputs at inference increases. "improved test time scaling under the Pass@k metric."
- Token-level ratio: Importance ratio computed per token to correct off-policy sampling at a finer granularity. "delete tokens whose token-level ratio is too large or too small."
- Truncated importance sampling: Importance sampling where extreme ratios are clipped/truncated for stability. "has used truncated importance sampling"
- vLLM: A fast inference system for LLMs used as the rollout engine. "a vLLM model"
- Value function (): The expected regularized return at a context; used to define optimal advantages. "the optimal value function "
- Unbiased estimator: An estimator whose expected value equals the true quantity, used here for Pass@k. "using the unbiased estimator from \citep{chen2021evaluatinglargelanguagemodels}."
Collections
Sign up for free to add this paper to one or more collections.

