- The paper confirms that personality cues significantly alter gender bias in narrative generation, with Dark Triad traits amplifying male stereotypes.
- The study employs a factorial design across 50 occupations and two languages using a centroid-based bias metric validated through substantial human annotation.
- Cross-linguistic results reveal a stronger baseline male bias in Hindi, while prosocial traits like Openness and Emotionality attenuate biases differently across models.
Personality Modulates Gender Bias in Persona-Conditioned LLM Narratives Across English and Hindi
Introduction and Motivation
This work presents a large-scale, controlled investigation into how personality cues interact with gender bias in persona-conditioned LLM story generation, systematically comparing effects across English and Hindi (2604.23600). Unlike prior studies that focus on demographic attributes or occupation, this study rigorously manipulates persona gender, occupation, and psychological traits (HEXACO and Dark Triad) to quantify how personality traits function as bias amplifiers or attenuators in contextualized occupational narratives. The multilingual setting directly tests whether bias mechanisms and prompt-driven effects in English persist under Indian socio-cultural and morphosyntactic conditions (grammatical gender, social hierarchy). The analytic pipeline combines a curated Indian-relevant occupation-scenario matrix, prompt-based conditioning, and a validated, sentence-level semantic bias metric.

Figure 1: Illustration of personality modulation of gender-stereotypical language in LLM-generated occupational artifacts for male and female personas, contrasting baseline and personality-conditioned responses.
Experimental Methods
The experimental protocol instantiates a factorial corpus: 50 occupations paired with contextually plausible artifacts and scenarios, assigned persona gender (male, female, neutral), and personality specification (9 traits × 2 levels, HEXACO + Dark Triad), yielding 23,400 artifact generations from 6 diverse LLMs (GPT-5 nano, Llama-3.3, Deepseek-R1, Mixtral, Gemma, Falcon-Mamba). Both English and Hindi outputs are generated via parallel prompt templates, ensuring cross-linguistic comparability.
A stepwise pipeline organizes data collection, centroid construction, and bias quantification:
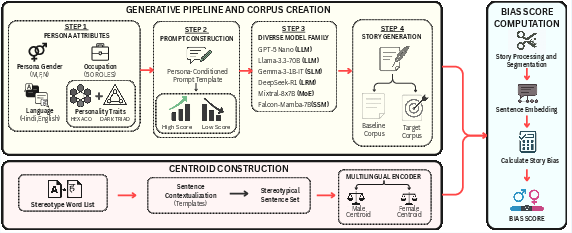
Figure 2: Experimental pipeline illustrating persona-attribute prompt generation, model artifact sampling, semantic embedding, and centroid-based bias computation.
Centroid-based bias scoring is implemented using IndicSBERT multilingual sentence embeddings. Manually curated, native-validated gender-stereotypical lexicons for both languages define reference centroids, against which each artifact’s sentence alignment is cosine-measured. The bias metric captures maximum absolute alignment per story, with human annotation (substantial Fleiss’ κ in both languages) confirming the metric’s validity.
Main Empirical Results
Baseline and Amplification Effects
All models exhibit a baseline male-stereotypical bias (cosine difference > 0), accentuated in Hindi due to grammatical gender and sociocultural salience. Personality conditioning systematically increases the generation of male-stereotypical sentences compared to the no-personality baseline, across all architectures and languages.
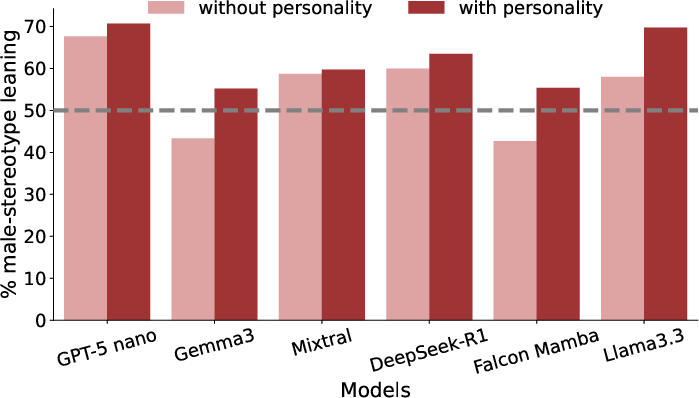
Figure 3: Percentage of generated sentences leaning toward male stereotypes for baselines (no personality) and persona-conditioned prompts, averaged across model and language.
Personality as a Systematic Bias Modulator
Regression analyses isolate the direction and magnitude of personality effects. Dark Triad conditions (Machiavellianism, Psychopathy; Narcissism variably) robustly amplify male-stereotypical language alignment, in some cases surpassing gender label main effects. Among HEXACO traits, Honesty-Humility, Agreeableness, and Conscientiousness weakly amplify, while Openness and, to a lesser degree, Emotionality attenuate bias—more commonly driving female-stereotypical alignment.
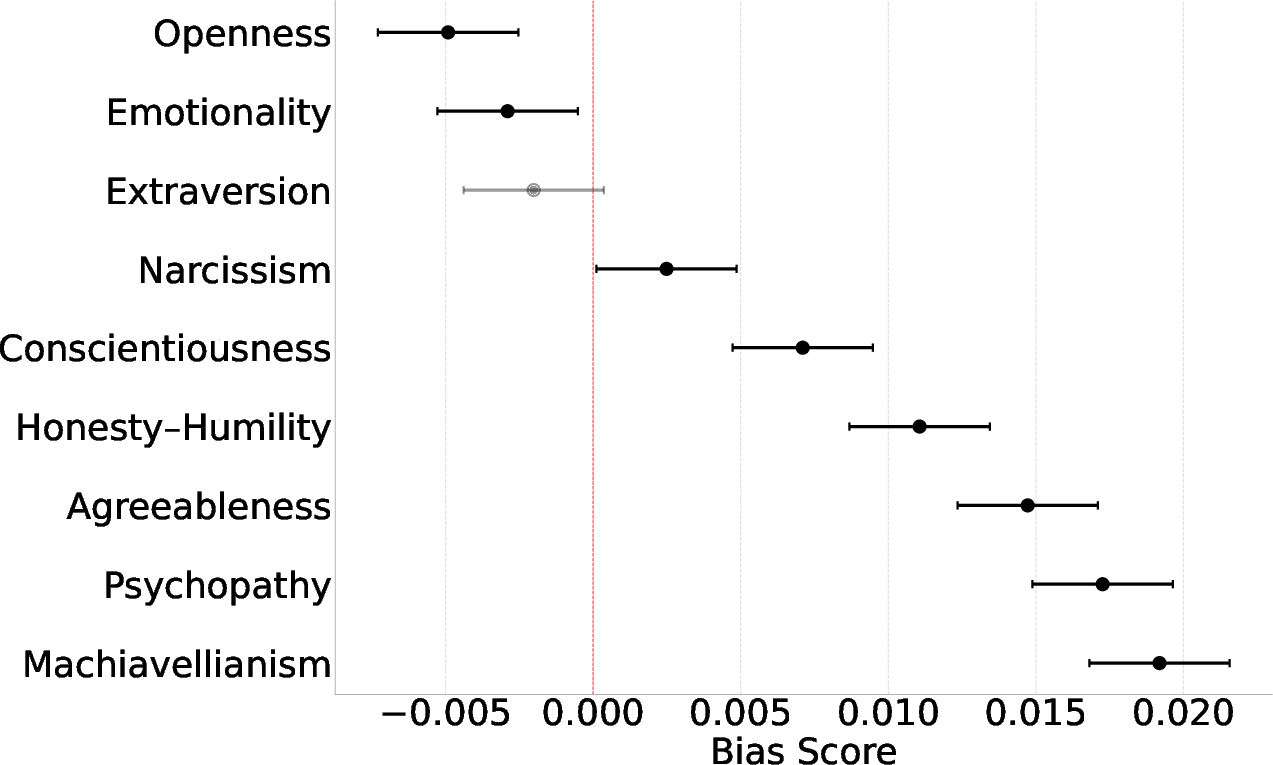
Figure 4: Personality trait coefficients on bias scores; Dark Triad traits consistently amplify male-stereotypical alignment, while Openness and Emotionality attenuate toward female.
Gender and Personality Interaction Effects
Explicit gender conditioning modulates bias direction: male personas shift the narrative toward male stereotypes, female toward female stereotypes, with the male effect larger in absolute magnitude. Crucially, specific personality traits (notably Dark Triad) exert stronger effect sizes than gender labels alone.
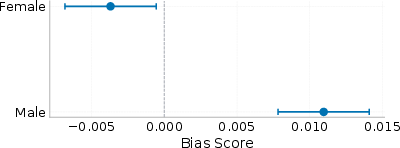
Figure 5: Gender main effects relative to neutral; male and female persona shifts are asymmetric, with personality coefficients often exceeding gender in magnitude.
Stratified analyses reveal that Dark Triad bias amplification is strongest when aligned with male personas, less so for female personas, indicating personality-by-gender interaction.
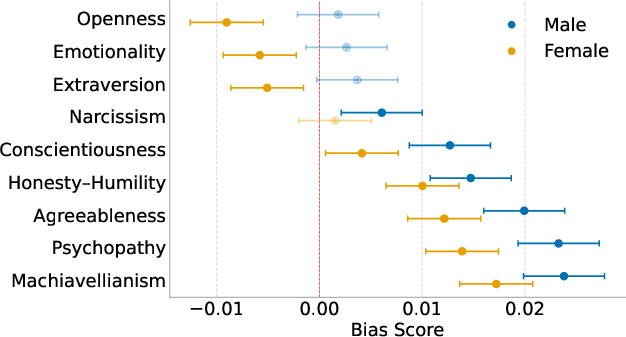
Figure 6: Gender stratified personality effects, with bias amplification by the Dark Triad more pronounced for male personas.
Cross-Linguistic Variation
Hindi generations display stronger overall male-stereotypical bias, but personality-driven modulation is more pronounced in English, especially for Dark Triad traits. Attenuating effects of prosocial HEXACO traits are compressed in Hindi, plausibly due to distributed gender encoding via verb/adjective agreement.
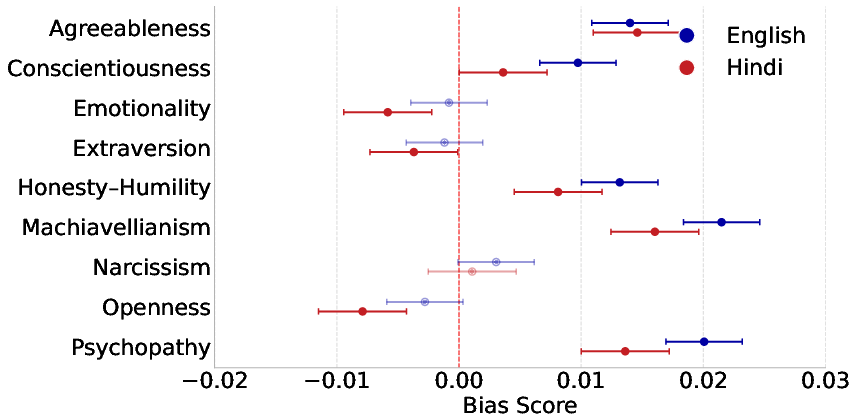
Figure 7: Language stratified personality effects; English exhibits stronger personality-dependent amplification and attenuation compared to Hindi.
Model Family and Scaling Effects
Across model families, GPT-5 nano anchors the strongest male-leaning bias. Smaller SSM models (Gemma, Falcon) show reversals toward female-stereotypical alignments at baseline, but the relative impact of personality conditioning (amplification/attenuation) patterns holds across scale and architecture.
Qualitative Analysis of Narrative Realization
Qualitative audit reveals non-trivial interactions between personality, gender, occupation, and language. For Dark Triad–conditioned female narratives, antisociality is often rendered covertly (e.g., deception, relational aggression), whereas male antisociality is realized overtly (self-indulgence, authority challenges). Morphosyntactic gender marking in Hindi constrains explicit lexical stereotype deployment, with personality effects surfacing as narrative-level strategy rather than only through lexical markers.
Implications
The study establishes that personality cues in prompt conditioning are not stylistic surface effects but primary determinants of context-dependent gender bias. This effect is robust to model family, persists across occupational stereotypes, and varies nontrivially by language, thus raising substantial concerns for persona-driven deployment in human-facing LLM applications. These findings indicate that fairness cannot be assured simply by restricting demographic prompt attributes; personality dimension interaction can reintroduce or obscure stereotypical harms.
From a theoretical perspective, the results suggest that LLMs internalize human-like stereotype context dependencies, reproducing documented psychological interaction effects (dark traits amplify, prosocial traits attenuate). Crosslinguistic divergence further demonstrates that mitigation strategies must be language-adapted and that centroid-based, semantically grounded metrics are essential for bias detection in morphologically rich languages.
Practical implications include the necessity for explicit fairness audits whenever LLMs are persona- or personality-conditioned, especially for education, HR, and customer support use-cases. Adjusting or restricting personality prompt spaces may act as a low-cost control for bias reduction—as established for toxicity [wang-etal-2025-exploring-impact-toxicity-bias].
Speculation on Future AI Developments
Emergent bias from trait conditioning suggests future LLM deployments must model persona as a structured, multi-dimensional latent variable, where prompt combinations can be explicitly diagnosed for bias interactions. Extending current work to multi-turn dialog, spontaneous code-switching, and compound stereotypes (e.g., caste, religion × gender × personality) will be required for robust fairness evaluation in real-world, multilingual systems. Tooling for prompt auditing should integrate context-dependent, language-adaptive embedding metrics. Further, as LLMs increasingly model human psychological regularities, systematic testing for stereotype amplification and attenuation in response to prompt space navigation is a critical path for safety and social acceptance.
Conclusion
This paper provides a comprehensive empirical demonstration that personality cues systematically modulate the magnitude, direction, and realization of gender bias in persona-conditioned LLM narrative generation, with pronounced effects for Dark Triad traits, cross-linguistically robust baseline skew, and critical architecture- and persona-interactional nuance. These findings recommend a shift from static to contextually dynamic conceptualizations of LLM social bias—prompt parameterization functions as a fairness-critical axis, requiring ongoing, high-resolution analytic attention in responsible LLM deployment.

