- The paper presents a novel egocentric dataset that advances embodied AI through scalable, real-world human task recordings.
- It introduces the JoyEgoCam platform with dual high-res cameras and a 200Hz IMU, coupled with a precise multimodal annotation pipeline ensuring 6-DoF and depth accuracy.
- The work demonstrates superior ecological validity and diverse task coverage, enabling robust skill transfer and generalist robot policy learning in real-world environments.
A Comprehensive Expert Overview of "EgoLive: A Large-Scale Egocentric Dataset from Real-World Human Tasks"
Introduction
The paper "EgoLive: A Large-Scale Egocentric Dataset from Real-World Human Tasks" (2604.23570) presents a substantial advancement in the resources available for robotics and embodied AI, specifically in human-in-the-loop robot learning, manipulation, and skill transfer. EgoLive addresses pervasive limitations in scale, ecological validity, and annotation quality exhibited by extant egocentric datasets, positioning itself as a cornerstone for scalable, generalist robot policy learning in real-world domains.

Figure 1: EgoLive is a large-scale high-quality and diverse egocentric dataset. It records human daily manipulation tasks with stereo vision.
Technical Contributions
The primary contributions are the dataset's unprecedented scale, the collection apparatus, and the multimodal high-fidelity annotation pipeline.
EgoLive employs JoyEgoCam, a custom head-mounted capture device configured with dual 2160×2160 resolution RGB cameras (60Hz) for wide-angle human-like stereo vision, augmented by a 200Hz IMU. This platform enables minimally intrusive, natural, and unconstrained data collection across homes, retail, and service environments, overcoming spatial and interaction constraints inherent to laboratory or VR-based setups.

Figure 2: JoyEgoCam head-mounted device captures synchronized stereo RGB (wide FoV) and inertial data for robust large-scale egocentric data acquisition.
Annotation Pipeline
EgoLive's automated annotation system incorporates:
- High-precision 6-DoF camera and hand/wrist trajectory tracking via fusion of stereo vision and IMU (ORB-SLAM3, HaMeR, and MANO pipelines).
- Hierarchical semantic understanding—object/hand/action detection, temporal sub-task segmentation, and language annotation using LLM pipelines (e.g., Qwen3-VL-32B).
- Dense depth and 3D scene reconstructions using state-of-the-art stereo models (FoundationStereo) and robust synchronizations for point cloud generation.

Figure 3: Overview of the automated annotation pipeline producing calibrated views, precise hand and object trajectories, 3D reconstructions, sub-task segmentation, and instruction-level captions.
Dataset Analysis and Diversity
EgoLive comprises 1,680 hours, 65,866 episodes, and 346 real-world tasks, setting a new benchmark versus prior egocentric and manipulation-centric datasets.
Discrete semantic analysis, as illustrated through task category coverage and word clouds, demonstrates broader domain applicability—spanning household, logistics, organization, cleaning, and more.
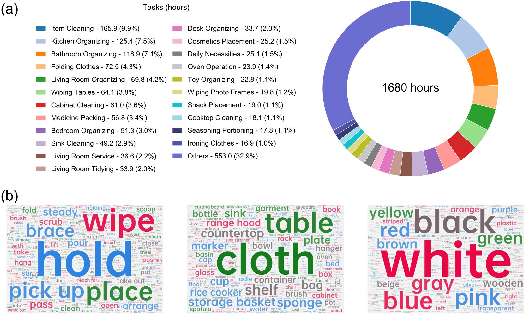
Figure 4: EgoLive achieves wide task category coverage; instruction caption word clouds reflect extensive action, object, and attribute semantics.
EgoLive exhibits a pronounced long-tail distribution in object, action, and attribute lexicons relative to concurrent datasets (e.g., EgoDex, Xperience-10M), reinforcing its utility for studying compositional generalization and rare action representation.
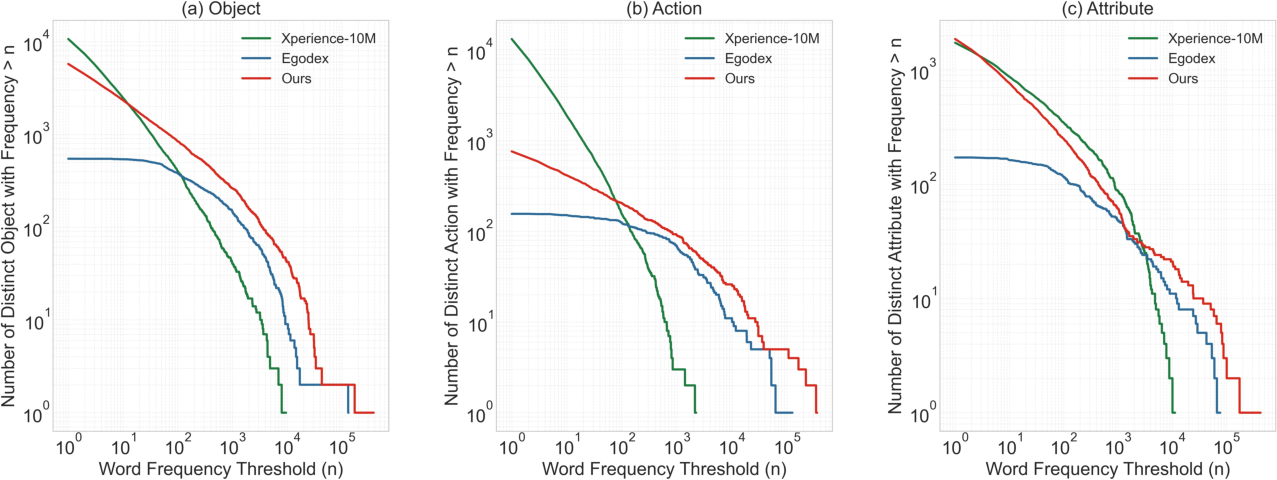
Figure 5: Long-tail behavior in semantic label distributions (object, action, attribute) measured across frequency thresholds; EgoLive sustains superior coverage and rare-class representation.
In continuous feature space, t-SNE visualization of multimodal embeddings reveals EgoLive's superior representation breadth and local semantic coherence compared to alternatives—indicative of strong generalization potential and richly compositional data.
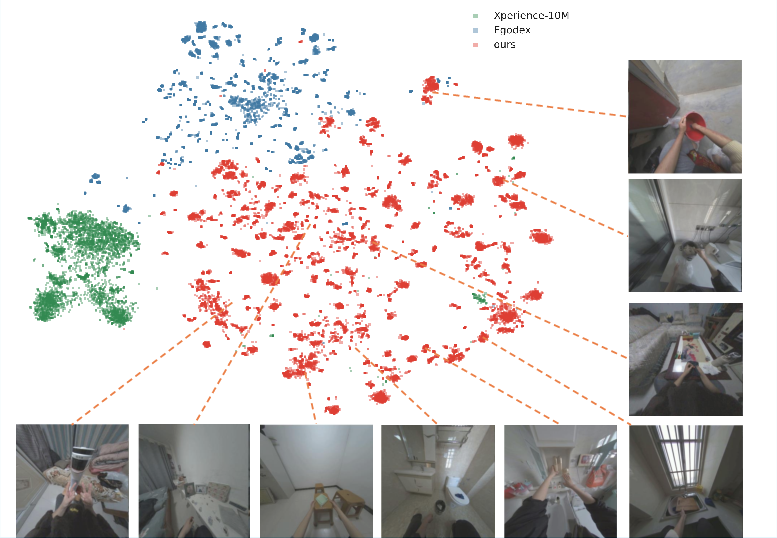
Figure 6: t-SNE of joint object, environment, and action embeddings; EgoLive covers a broader manifold with more interpretable local clusters than prior datasets.
Annotation Quality and Sensing Precision
Keypoint and Depth Accuracy
Qualitative and quantitative evaluations highlight robust improvements over predecessor datasets:
- EgoLive delivers accurate and spatially consistent 2D hand keypoints, virtually eliminating misalignments and errors prevalent in EgoDex and others.
- EgoLive's 3D hand keypoint estimations maintain minimal wrist drift and strong spatial fidelity across multiview projections.

Figure 7: Visual comparison evidences substantial improvements in 2D keypoint annotation accuracy versus EgoDex.

Figure 8: 3D keypoints projected from four perspectives, preserving spatial consistency and scale correctness without drift.
Depth estimation, validated via checkerboard protocols, achieves sub-centimeter mean errors (<9mm) up to 90cm and maintains below 2cm error up to 1.5m, within typical manipulation ranges.

Figure 9: Calibration board-based point cloud reconstructions across operational distances underscore accurate depth recovery.

Figure 10: Dataset-level qualitative depth and point cloud reconstruction in diverse scenes validates fidelity and robustness of spatial annotations.
Instruction Captioning
Instruction segmentation and language annotation modules accurately capture atomic actions—including hand-specific usage, manipulated objects, and action semantics—a necessity for grounding egocentric demonstration to hierarchical task policies.

Figure 11: Instruction-based annotation examples spanning glass wiping, clothes folding, refrigerator cleaning, and bedmaking—sub-tasks are robustly segmented and captioned.
Implications and Future Directions
EgoLive's scale, annotation precision, and ecological validity present immediate impacts and longer-term strategic utility:
- Foundation for Generalist VLA Model Pretraining: The extensiveness and compositionality of the dataset facilitate robust pretraining of vision-language-action models, supporting transfer and adaptation to diverse manipulation tasks and environments.
- Human-to-Robot Skill Alignment: Its accurate hand-object-action mapping and sub-task decomposition optimize transferability to robot control and bridge human-robot embodiment gaps in policy learning [Egodex; VITRA].
- Data-Centric Robotics Research: Enables principled investigations into data curation, active data selection, deduplication, scaling laws, and domain adaptation for embodied learning [openx2023rtx; Egoscale; zhang2026scizor].
- Benchmark for Real-World Policy Evaluation: The diversity and real-world focus position EgoLive as the reference testbed for evaluating generalization, compositionality, and robustness of embodied AI and robotic agents.
The dataset's design for continuous expansion (hardware, pipeline, annotation) ensures its relevance as both an evolving knowledge base and a scalable benchmark, supporting long-horizon study of both autonomous skill acquisition and human-to-robot transfer.
Conclusion
EgoLive constitutes the state-of-the-art in egocentric human demonstration datasets, delivering increases in scale, data quality, sensing precision, semantic richness, and annotation coverage over all relevant baselines. Its technical framework and annotation pipeline support robust, continuous growth and present vital infrastructure for generalist robot learning, policy transfer, and embodied AI research. As such, EgoLive will shape future advances in large-scale manipulation learning, cross-domain skill transfer, and deployment of capable, general-purpose robotics in uncontrolled real-world environments.