- The paper demonstrates that partitioning static and dynamic LLM operations using JIT and CUDA Graph reduces TTFT latency by up to 66%.
- It implements a hybrid runtime architecture leveraging asynchronous CUDA Graph capture and JIT for dynamic segments, ensuring low tail latency and variance.
- Empirical results on LLaMA-2 7B show improvements in TTFT and a reduction in P99 latency by up to 43.5% compared to existing frameworks.
Hybrid JIT--CUDA Graph Optimization for Low-Latency LLM Inference
Autoregressive LLMs deployed for interactive, incremental-generation workloads are critically constrained by inference latency, especially at small batch sizes. Kernel launch overhead, CPU dispatch, and dynamic tensor management during decoding steps contribute significantly to tail latency and variance. Previous optimizations via operator fusion, quantization, and specialized kernels (e.g., FlashAttention) mitigate throughput bottlenecks but do not fully address launch and dispatch inefficiencies for latency-sensitive inference. This paper proposes a hybrid runtime to combine deterministic CUDA Graph replay for statically-structured segments with JIT compilation for dynamic operations, aiming to simultaneously deliver low-latency and runtime flexibility.
System Architecture and Design
The proposed hybrid runtime partitions LLM inference into static and dynamic domains. Static operations—such as matrix multiplications, norm layers, and attention score computation with fixed shapes—are encapsulated within CUDA Graphs for replay, eliminating kernel launch overhead. Dynamic operations—including sequence-length adaptation, KV-cache updates, and stochastic sampling—remain under JIT compilation. Execution proceeds through asynchronous coordination between two processes: the Context Generator (JIT) and the Graph Generator (CUDA Graph), linked via IPC. CUDA streams enable concurrent graph capture and replay, amortizing overhead and minimizing CPU involvement.
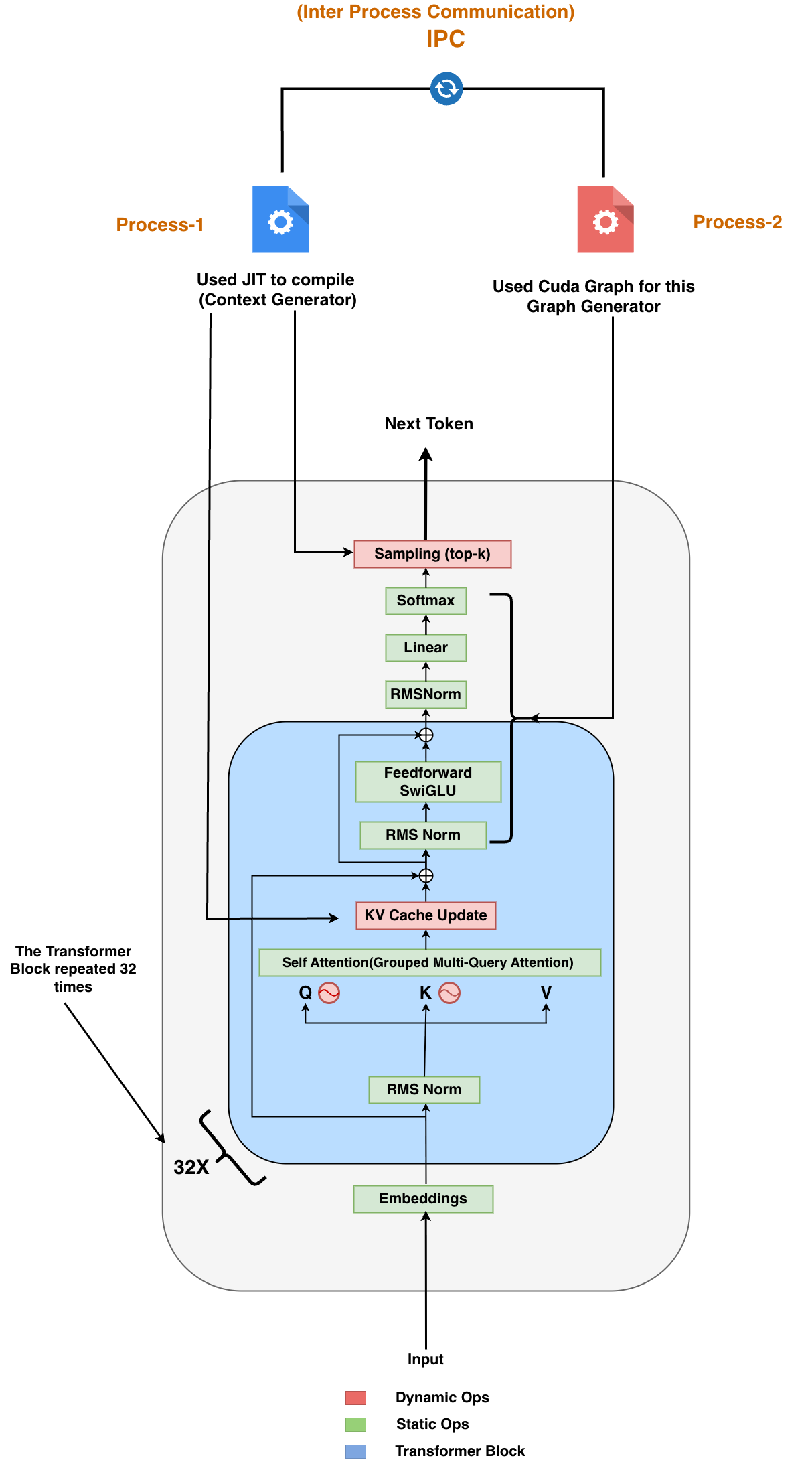
Figure 1: High-level architecture of the Hybrid JIT--CUDA Graph Runtime, illustrating asynchronous interplay and separation between JIT and CUDA Graph domains.
Static and dynamic operation decomposition is central: static segments benefit from deterministic execution, while dynamic logic is confined to GPU-resident JIT regions. This separation ensures performance without sacrificing the expressiveness needed for autoregressive decoding.
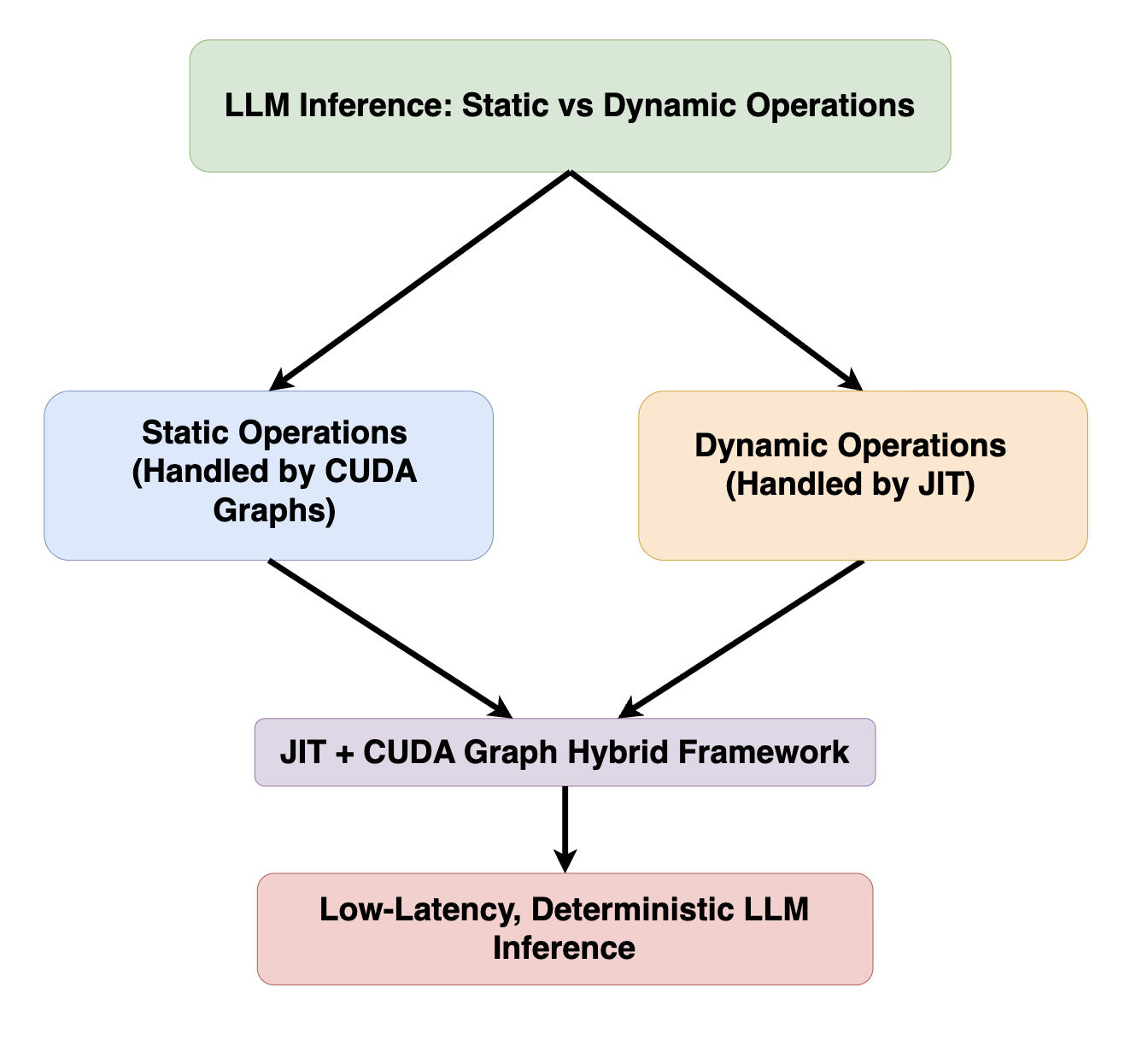
Figure 2: Decomposition of LLM inference pipeline, showing selective application of CUDA Graph replay for static blocks and JIT for dynamic operations.
Hybrid integration is achieved via a rolling graph buffer, capturing and evicting CUDA Graphs as new sequence lengths arise and maintaining device-resident data via pointer exchange. Memory management leverages shared activation workspaces and PyTorch’s caching allocator, while kernel integrations embed high-performance operator implementations (FlashAttention v2, nvFuser LayerNorm, paged KV-cache) for further reductions in computation and memory overhead.
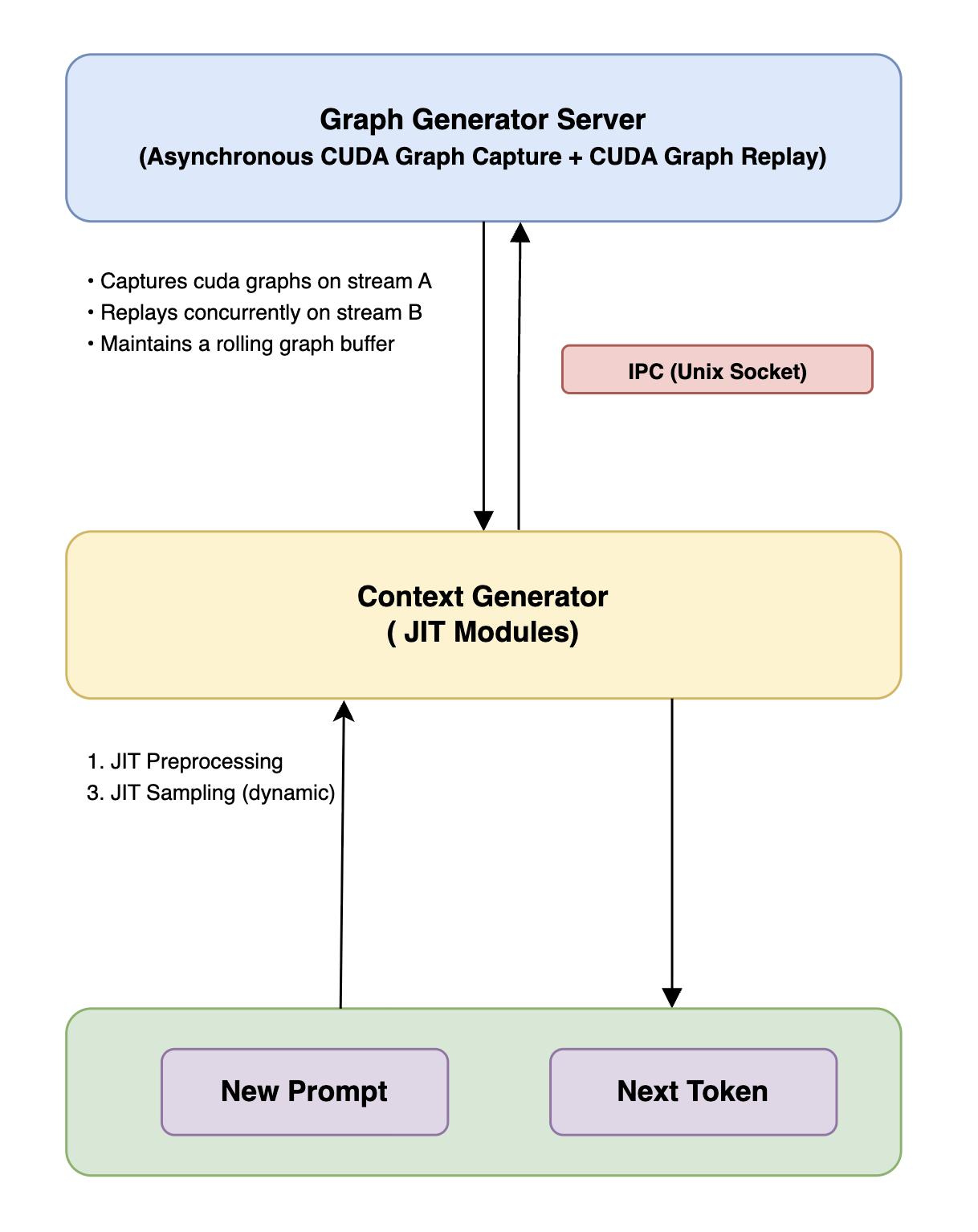
Figure 3: Hybrid runtime architecture detailing the inter-process communication and concurrency between the Context and Graph Generators.
Implementation Methodology
The runtime is built atop PyTorch 2.3, CUDA 12.4, and the torch.cuda.CUDAGraph API. Experiments utilize LLaMA-2 7B, batch size 1, and FP16 precision on NVIDIA H100. Prompt lengths span 10–500 tokens, reflecting operationally realistic interactive inference windows.
Asynchronous CUDA Graph generation is pre-captured for short lengths and handled via background threads, with synchronization enforced by CUDA events to enable safe overlap. The system benchmarks against PyTorch Eager and TensorRT–LLM for rigorous fairness.
Empirical Results
Quantitative evaluation demonstrates that the hybrid runtime consistently achieves the lowest Time-to-First-Token (TTFT) and P99 tail latency across all prompt sizes. TTFT speedups reach up to 66%, with average improvements from 1.02× to 5.90× versus PyTorch Eager and up to 5.42× versus TensorRT–LLM. TTFT scaling is nearly linear, reflecting stable kernel execution and absence of host-side dispatch variability.
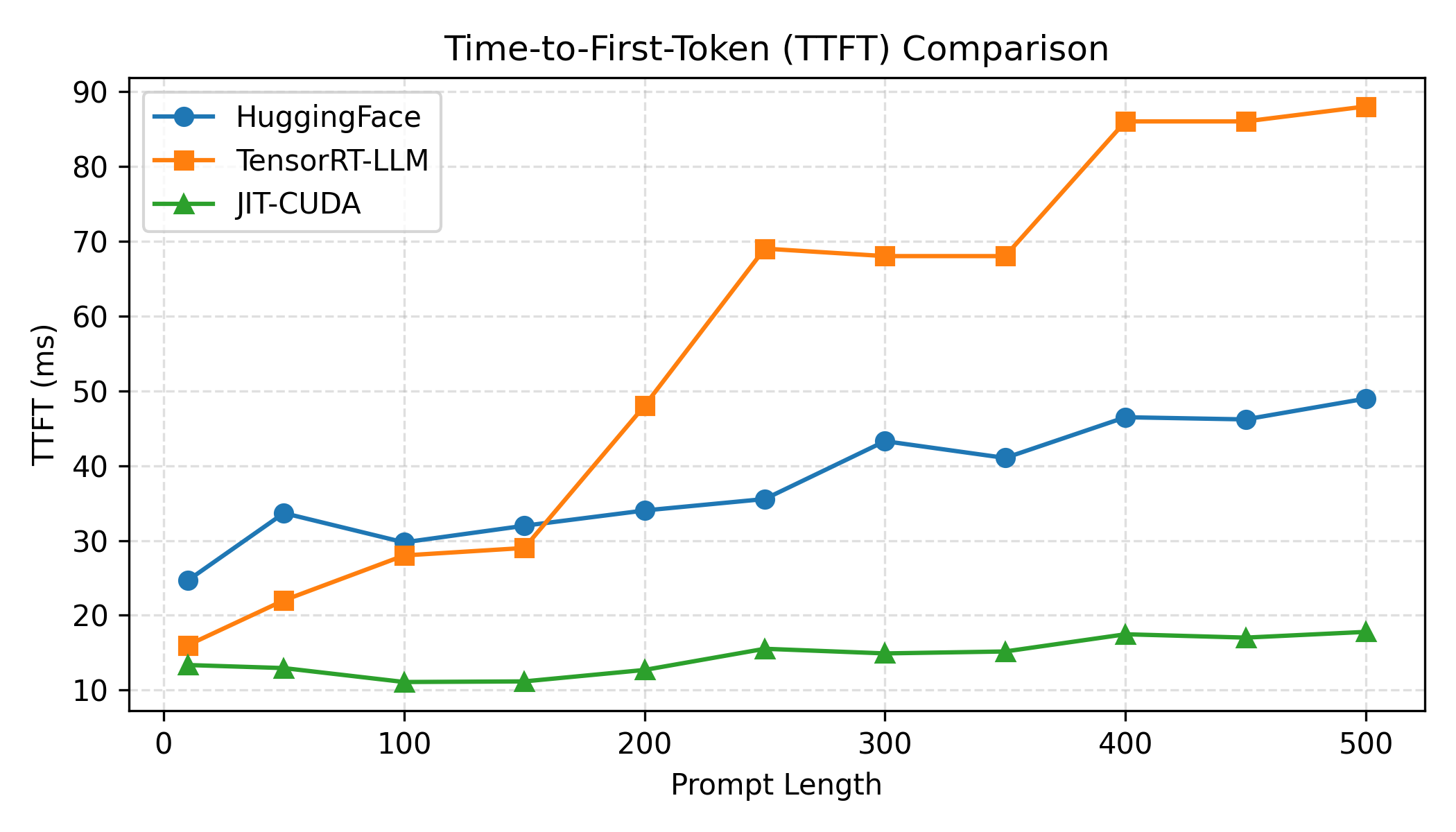
Figure 4: TTFT scaling as a function of prompt length, demonstrating smoother trend and lower latency for the hybrid runtime.
Tail latency (P99) analysis reveals substantial reductions in both absolute values and variance. The hybrid runtime reduces P99 per-token latency by 20.2% relative to TensorRT–LLM and 43.5% relative to PyTorch Eager. Variance is markedly suppressed, underscoring the efficacy of deterministic CUDA Graph replay.
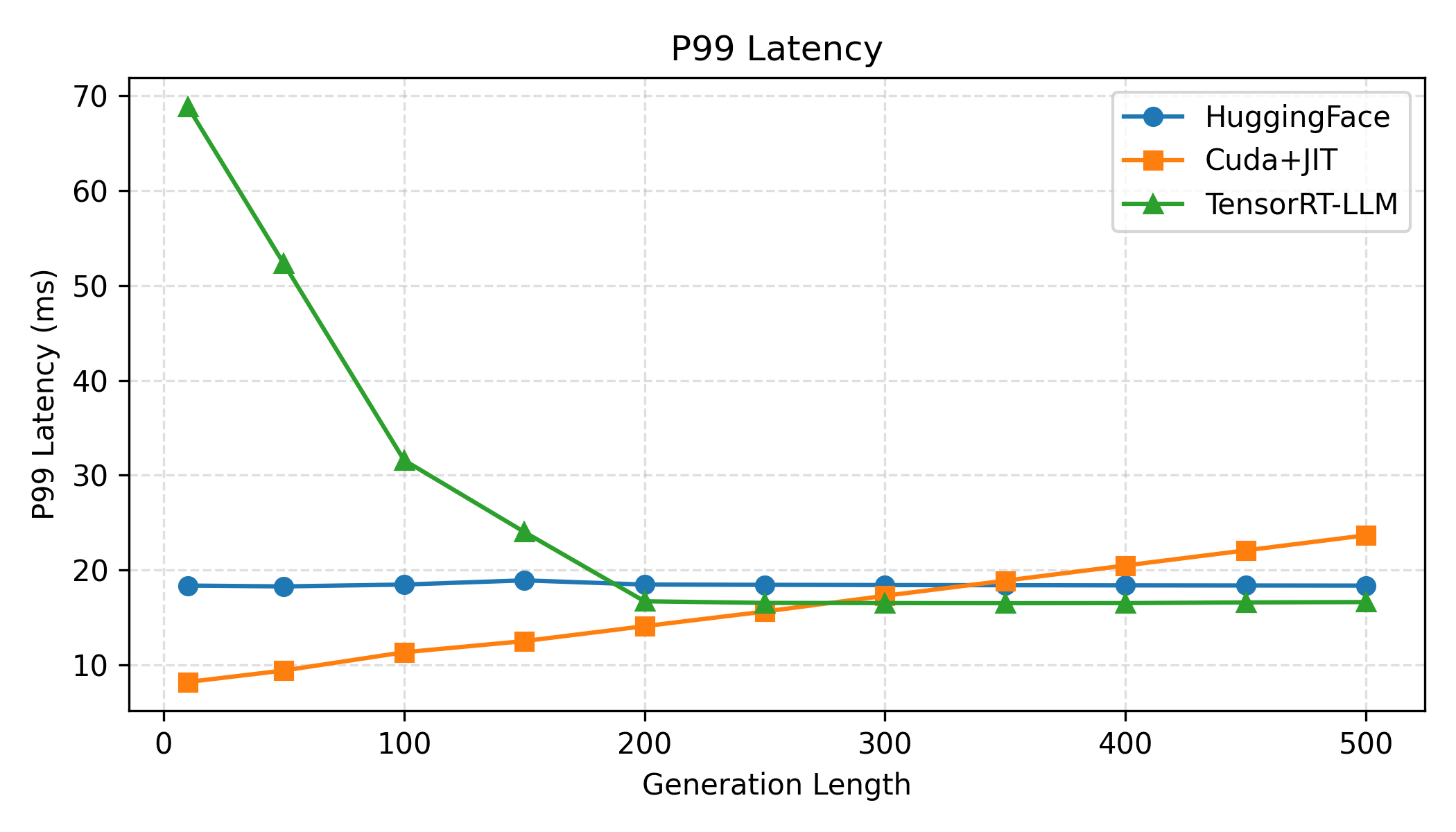
Figure 5: P99 per-token latency versus context length, highlighting minimized tail latency and jitter for the hybrid architecture.
Ablation experiments validate that disabling asynchronous graph regeneration or JIT compilation leads to 17.5%–28% latency regressions, confirming their critical synergistic roles.
Comparative and Practical Implications
Unlike TensorRT–LLM or FasterTransformer, this hybrid runtime does not require custom C++ plugin operator implementations, thus facilitating streamlined integration and maintainability. Compared to TorchDynamo or TorchInductor, which focus on fusion within dynamic compilation boundaries, the hybrid approach explicitly separates deterministic static replay, yielding superior latency characteristics in token-by-token decoding.
Reduction in TTFT and tail latency directly impacts end-user responsiveness in conversational, code, and decision-support applications, which predominantly issue short- to medium-length generations.
Limitations and Future Directions
Key limitations include the need for shape-specific CUDA Graphs, leading to memory buffer proliferation as sequence length support expands; capture parallelism limited by cuBLAS integration; stochastic operation isolation outside graph boundaries; and single-GPU scope. Future optimizations may include graph shape bucketing, thread-safe linear algebra backends for concurrent capture, hierarchical graph composition for distributed inference, and improved integration of pseudo-random state.
Conclusion
The hybrid JIT--CUDA Graph runtime presented achieves significant reductions in inference latency and variance for interactive LLM scenarios. By strategically partitioning transformer inference into static and dynamic domains and leveraging concurrent CUDA Graph replay and JIT compilation, deterministic low-latency execution is realized without loss of runtime flexibility. The practical benefits are manifested in real-time AI applications, and the architectural paradigm points toward scalable optimizations for GPU-resident scheduling in multimodal and multi-device settings.