- The paper introduces a novel CPU-GPU cooperative attention mechanism that alleviates memory pressure from KV cache growth.
- The approach leverages pipelined logit computation and semantic-aware KV caching to balance workload and reduce latency.
- Experimental results demonstrate 1.41×–3.2× latency improvements while maintaining accuracy with less than 0.02 absolute degradation.
HybridGen: Efficient LLM Generative Inference via CPU-GPU Hybrid Computing
Motivation and Problem Analysis
The expansion of LLM context lengths has created unprecedented memory pressure due to key-value (KV) cache growth. While model weights remain fixed, KV caches scale linearly with sequence length and batch size, quickly exceeding GPU memory capacity. Existing solutions such as pruning or offloading help alleviate resource constraints, but fundamentally fail to exploit the full computing potential of heterogeneous systems. Pruning often results in accuracy degradation by discarding context, and offloading—whether for computation or cache storage—, suffers from either overwhelming GPU transfer bottlenecks or CPU compute limitations at long sequences.
HybridGen proposes a novel CPU-GPU collaborative attention execution, where each processor operates on tokens in its local memory. This approach addresses: (1) multi-dimensional processor and memory dependencies within and across transformer layers; (2) CPU-GPU load imbalance, which becomes increasingly problematic as generation context length expands; and (3) NUMA penalties incurred by tiered memory systems (CXL, etc.). Figure 1 illustrates the explosive memory demand imposed by KV cache growth.
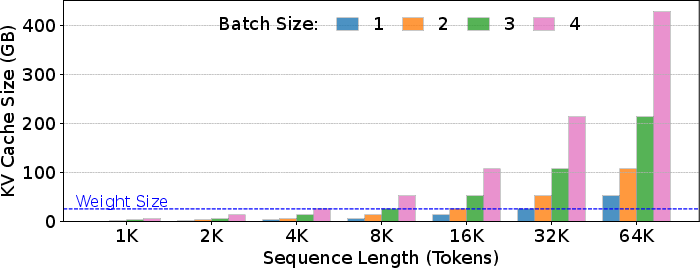
Figure 1: KV cache memory consumption of OPT-13B across varying sequence lengths and batch sizes. The dashed line indicates the model's weight size, highlighting the scalability issue of KV cache.
Through detailed breakdowns, HybridGen demonstrates that neither complete offloading to CPU nor full GPU attention computation suffices: CPU becomes compute-bound at long contexts; GPU is bottlenecked by memory transfers. Figures 4, 5, and 6 quantify the data movement, computation distribution, and latency under pure CPU or GPU affinity, with hybrid execution yielding more efficient outcomes.
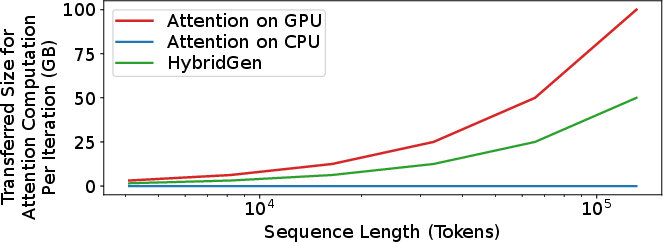
Figure 2: Estimated data traffic during attention layer computation per iteration under different KV cache management strategies.
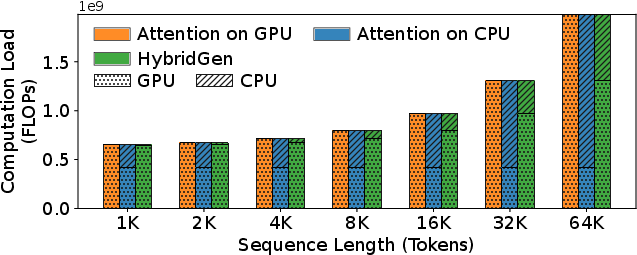
Figure 3: Computation distribution on transformer block computation per iteration under different strategies, revealing load imbalance in AoG and AoC.
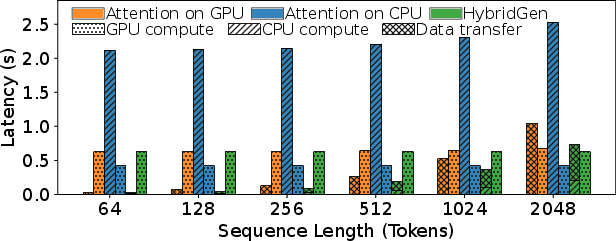
Figure 4: Estimated latency under CPU, GPU, and hybrid strategies; hybrid achieves lowest end-to-end runtime.
HybridGen Architecture and Core Methodology
HybridGen introduces a lightweight framework for pipelined CPU-GPU parallel attention. The architecture (Figure 5) supports decoupling of attention logit computation, enabling CPU to process attention logits for offloaded tokens and GPU for those resident in local memory.
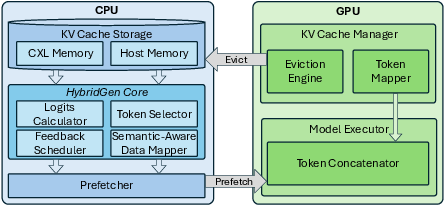
Figure 5: Architecture of HybridGen, illustrating components for logit calculation, token mapping, and feedback scheduling.
Attention logit computation is parallelized; softmax and value aggregation are globally dependent but logit calculations are independently performed. HybridGen leverages high cosine similarity of layer inputs (Figure 6) to pipeline logit computations across layers, allowing CPU to proactively prepare attention logits for the next layer concurrently with GPU computation.
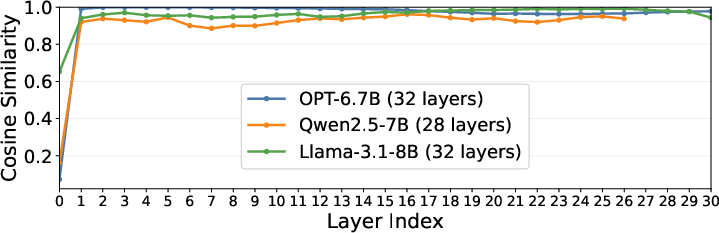
Figure 6: Cosine similarity between inputs of consecutive transformer layers for OPT-6.7B, Qwen2.5-7B, and Llama-3.1-8B, validating input reuse across layers for hybrid scheduling.
Workflow details (Figure 7) show CPU and GPU stages overlapping; CPU selects or computes logits for important tokens based on scheduler policy and token mapping, then transfers compact logits and value vectors to GPU, where global softmax and aggregation are completed.
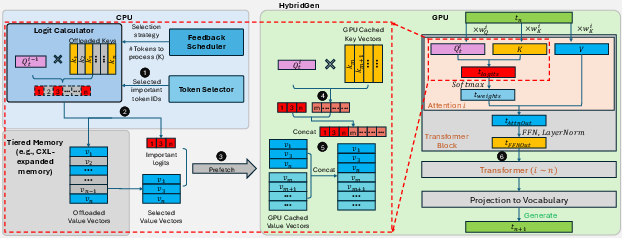
Figure 7: Workflow of HybridGen illustrating computational pipeline and DMA-based fusion of CPU and GPU outputs.
HybridGen’s feedback scheduler (Figure 8 and Algorithm in the paper) dynamically adapts CPU workload and token selection strategy, maintaining balance and maximizing throughput while enforcing accuracy constraints. Top-K token selection is executed either post- or pre-logit computation, depending on bottleneck analysis.
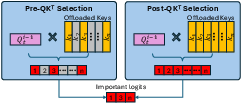
Figure 8: Attention logits computation under post- and pre-token selection mechanisms; the feedback scheduler selects appropriate strategy according to runtime metrics.
Semantic-aware KV cache mapping is introduced for tiered memory (CXL): K vectors are retained in CPU DRAM, while V vectors are evicted to CXL by design, removing NUMA latency from the critical path. This is a distinct departure from hotness-based mapping—the token selection logic is driven by attention semantics, not runtime memory profiling.
Experimental Results and Numerical Evidence
HybridGen was evaluated across eleven LLMs of various sizes and three GPU platforms, including CXL memory pools. As context length and batch grow, HybridGen preserves low inference latency and superior throughput, consistently outperforming six state-of-the-art baselines (pruning, selective offloading, etc.) by 1.41×–3.2× on average.
Figure 9 summarizes normalized end-to-end latency across models, with HybridGen dominating all baselines.

Figure 9: End-to-end latency of different models (normalized to baseline); HybridGen achieves lowest latency under all configurations.
Performance scaling with sequence length and batch size further demonstrates HybridGen’s robustness. Figure 10 presents latency breakdowns for OPT-13B under variable batch sizes.
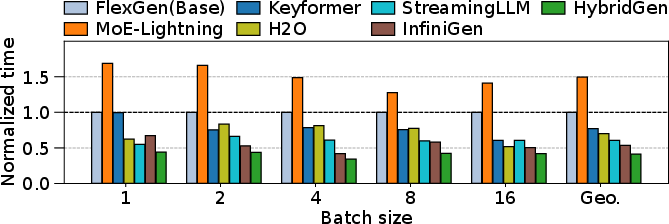
Figure 10: Performance of OPT-13B across batch sizes, showing HybridGen’s advantage, particularly at scale.
Semantic-aware mapping (Figure 11) achieves measurable speedup over default page interleaving, especially as model size grows and KV cache consumes non-local memory tiers.
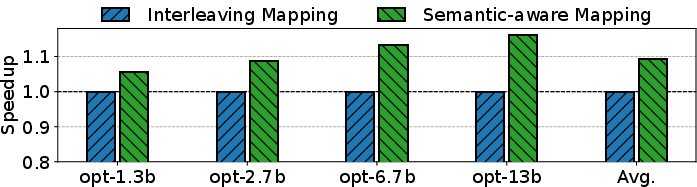
Figure 11: Speedup attained by semantic-aware mapping vs. standard page mapping for large KV cache scenarios.
Accuracy is maintained due to the feedback scheduler’s enforcement of per-model Kmin thresholds, mitigating pruning-induced degradation. Across standard benchmarks, HybridGen exhibits less than 0.02 absolute accuracy gap compared to full-context baselines, outperforming static pruning and offloading methods where long-range contextual dependencies are critical.
Practical and Theoretical Implications
HybridGen’s hybrid scheduling and semantic awareness unlock efficient long-context inference for LLMs even as context sizes reach hundreds of thousands or millions of tokens. This enables realistic deployment scenarios where inference must scale beyond GPU memory, leveraging expanded CPU and CXL resources without sacrificing accuracy or throughput.
The design is framework-agnostic and extends to vLLM, SGLang, and other modern serving stacks. The introduction of feedback-driven scheduling establishes a principled approach to dynamic resource management, inherently supporting new hardware architectures (Grace-Hopper, etc.) and emerging system topologies.
HybridGen challenges the traditional boundaries of attention computation affinity, demonstrating that decoupling logit calculation and embracing pipelined, collaborative execution on heterogeneous processors is fundamentally superior to monolithic or static approaches. The semantic-aware KV cache mapping lays groundwork for future NUMA-optimized memory hierarchies tailored specifically to LLM inference primitives.
Future Considerations
Potential future directions include:
- Further exploitation of CXL-expanded memory, including deep integration with persistent memory devices.
- Algorithmic extension to support even greater concurrency across multiple CPUs/GPUs per node.
- Integration with speculative decoding and multi-turn dialogue systems for low-latency interactive inference.
- Exploration of continuous batching, prefix caching, and paged KV-cache metadata for seamless scaling.
The architecture is well-suited for adaptation to evolving hardware landscapes and for inclusion in system-level scheduling frameworks that optimize for both throughput and latency under resource constraints.
Conclusion
HybridGen introduces a CPU-GPU hybrid attention framework for efficient generative inference in LLMs, leveraging pipelined execution, feedback-driven load balancing, and semantic-aware tiered memory mapping. The approach yields substantial performance improvements without sacrificing accuracy, robustly scaling across model sizes, sequence lengths, batch sizes, and memory configurations. HybridGen sets a new technical standard for resource-efficient, scalable LLM inference on modern heterogeneous systems (2604.18529).

