- The paper proposes a hardware-in-the-loop architecture search using structured pruning and Bayesian optimization to achieve optimal latency-accuracy tradeoffs.
- It demonstrates that real-device latency measurements outperform theoretical proxies, guiding design choices such as shallow, wide architectures and native attention patterns.
- Empirical results show up to 1.8x speedup in prefill and 1.6x in decode speed on mobile devices while maintaining competitive accuracy across multiple benchmarks.
Latency-Guided Design of MobileLLM-Flash for Industry-Scale On-Device LLM Deployment
Motivation and High-Level Methodology
MobileLLM-Flash addresses the challenge of deploying LLMs on consumer devices with tight hardware and latency constraints. The design imperative is dual: deliver near-real-time responses—especially optimizing for low time-to-first-token (TTFT)—while maintaining compatibility with standard, cross-platform mobile runtimes (e.g., Executorch), thus enabling efficient industry-scale deployment. Previous works inadequately address on-device constraints, often relying on parameter/FLOP reductions or custom kernels incompatible with production mobile stacks.
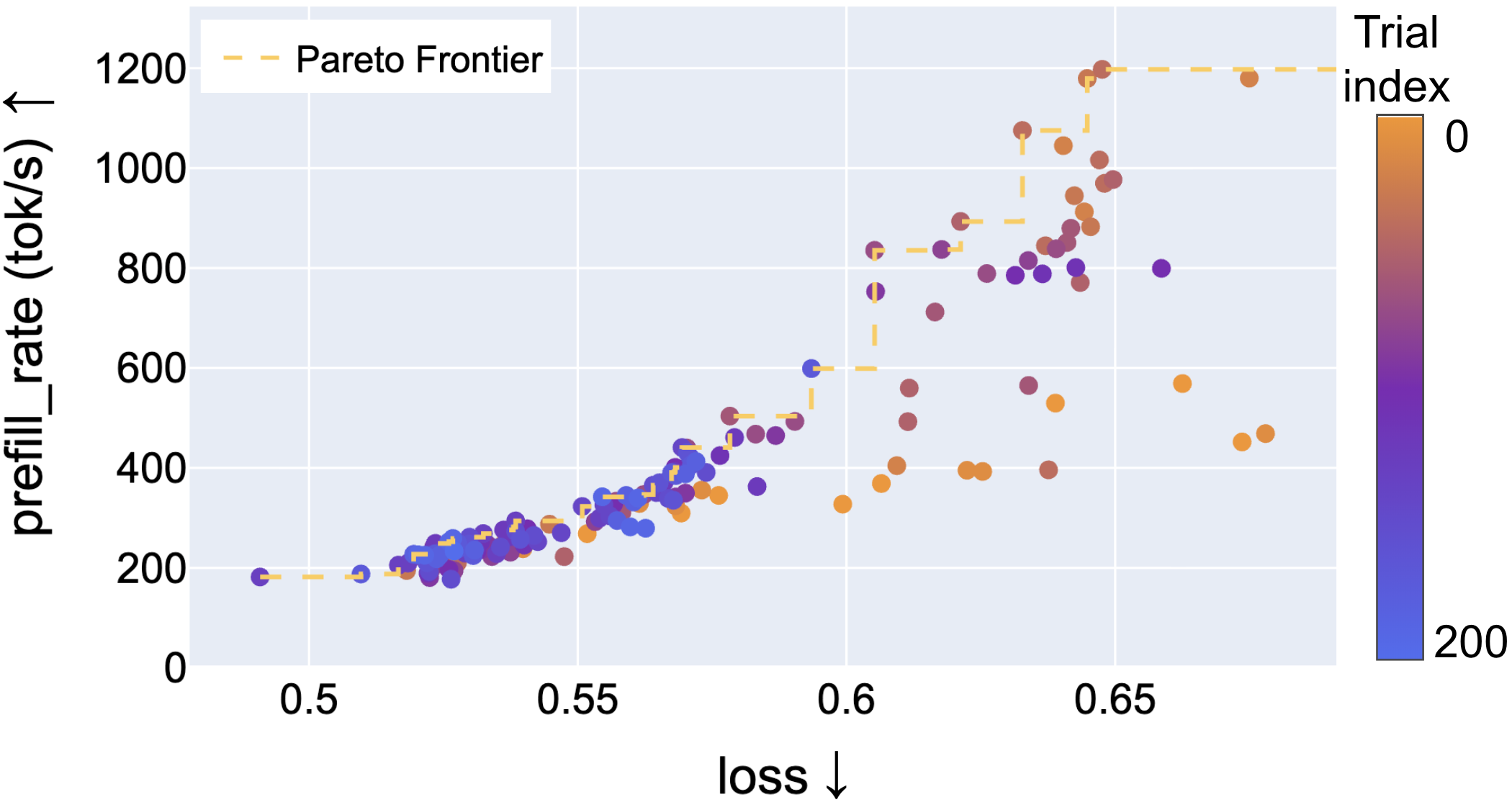
MobileLLM-Flash proposes a latency-aware, hardware-in-the-loop architecture search methodology that differs fundamentally from FLOP/parameter-count–centric optimization by directly searching the architecture–attention design space subject to measured real-world latency. The central approach utilizes structured pruning of pretrained backbones, coupled with joint search over key architectural parameters (layers, widths, attention patterns), exploiting Bayesian optimization to discover Pareto-efficient (latency vs. quality) model configurations.
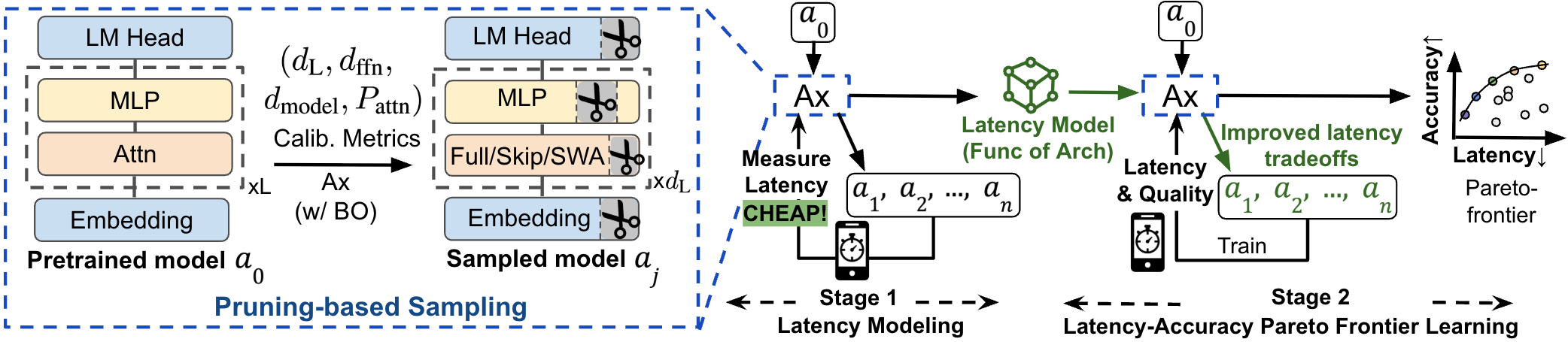
Figure 1: Overview of the two-stage OD-LLM design—joint search over architecture and attention pattern by pruning a pretrained backbone, using a hardware-in-the-loop latency model and Bayesian multi-objective optimization.
Hardware-in-the-Loop Optimization and Pareto Frontier Analysis
Unlike common practice that uses model size or theoretical FLOPs as proxies for latency, this work demonstrates empirically that such metrics are poor predictors of actual mobile inference speed. Real device measurement is thus critical for the search process.
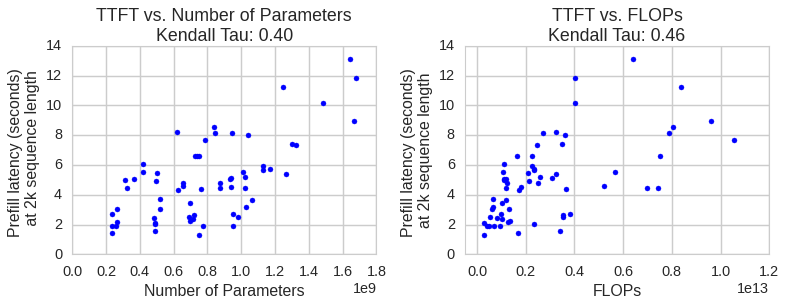
Figure 2: TTFT at 2k sequence length shows only moderate correlation with model parameter count and FLOPs; justifying the need for hardware-in-the-loop evaluation.
The architecture search is structured as follows:
Structured Pruning and Efficient Search
The search leverages pruning—instead of scratch training—dramatically reducing search-time computation. Empirical evidence establishes that continued pretraining (CPT) of pruned models maintains a stable ranking correlation with fully-trained variants, achieving near-converged losses with less than 1% of the data budget.
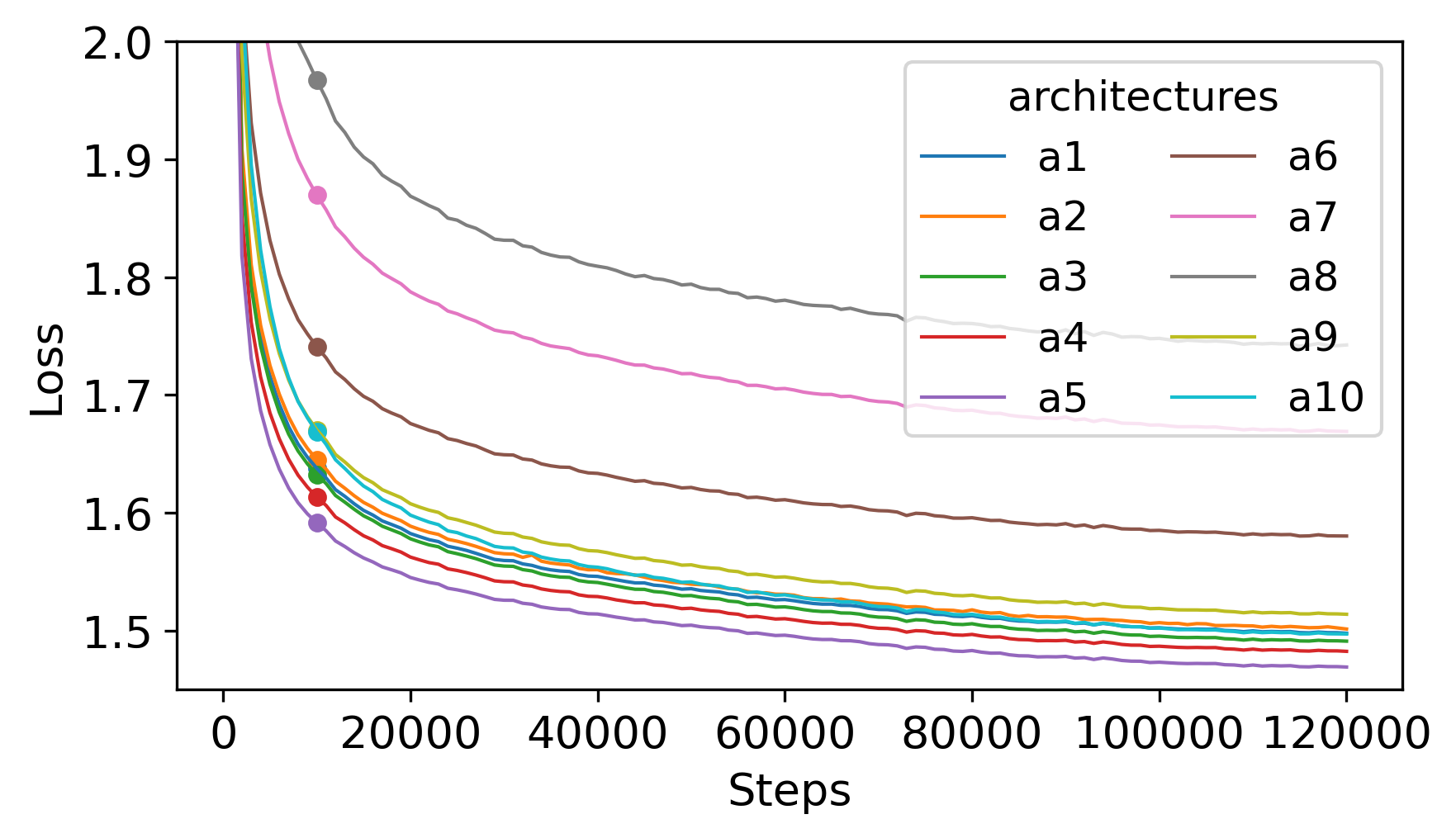
Figure 4: Evolution of pruned model loss demonstrating rapid convergence and stable candidate ranking under CPT versus full pretraining.
The architecture search space encompasses:
- Depth (dL): Number of Transformer layers
- Model/FFN hidden dimensions
- Attention pattern per layer: full attention, skip attention, sliding window attention (SWA)—all deployable in standard runtimes.
Skip attention is natively supported and, per search results, offers a superior latency-quality tradeoff versus SWA in mobile settings. The search reveals optimal architectures interleave skip and global attention, explicitly forbidding long runs of skip/SWA to avoid degradation in long-range contextual capacity.
MobileLLM-Flash consists of 350M, 650M, and 1.4B parameter variants, each Pareto-optimized for mobile inference. These models achieve state-of-the-art measured speeds and capability.
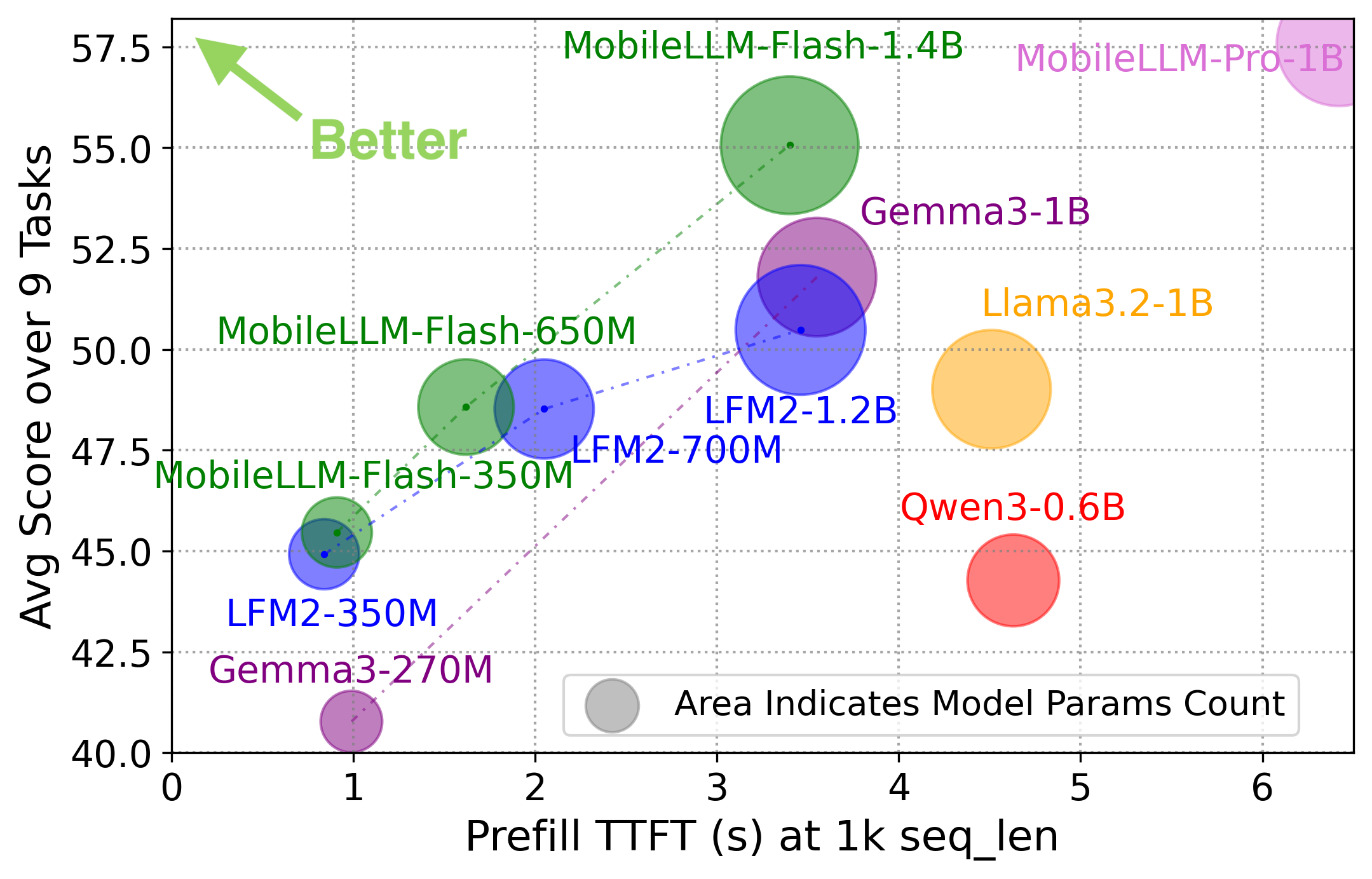
Figure 5: MobileLLM-Flash outperforms state-of-the-art OD-LLMs in both prefill and decode speed, with up to 1.8× (prefill) and 1.6× (decode) speedup, at competitive or superior accuracy.
For a 2k context window on a flagship mobile device, MobileLLM-Flash delivers TTFT and decode rates that substantially exceed prior baselines (e.g., LFM2) while achieving equal or higher accuracy across benchmarks. This is obtained through architectural efficiency (shallow-and-wide layouts) and meticulously optimized attention patterns. Notably, the design employs a 202k token vocabulary, increasing per-token information density and reducing effective sequence length per task.
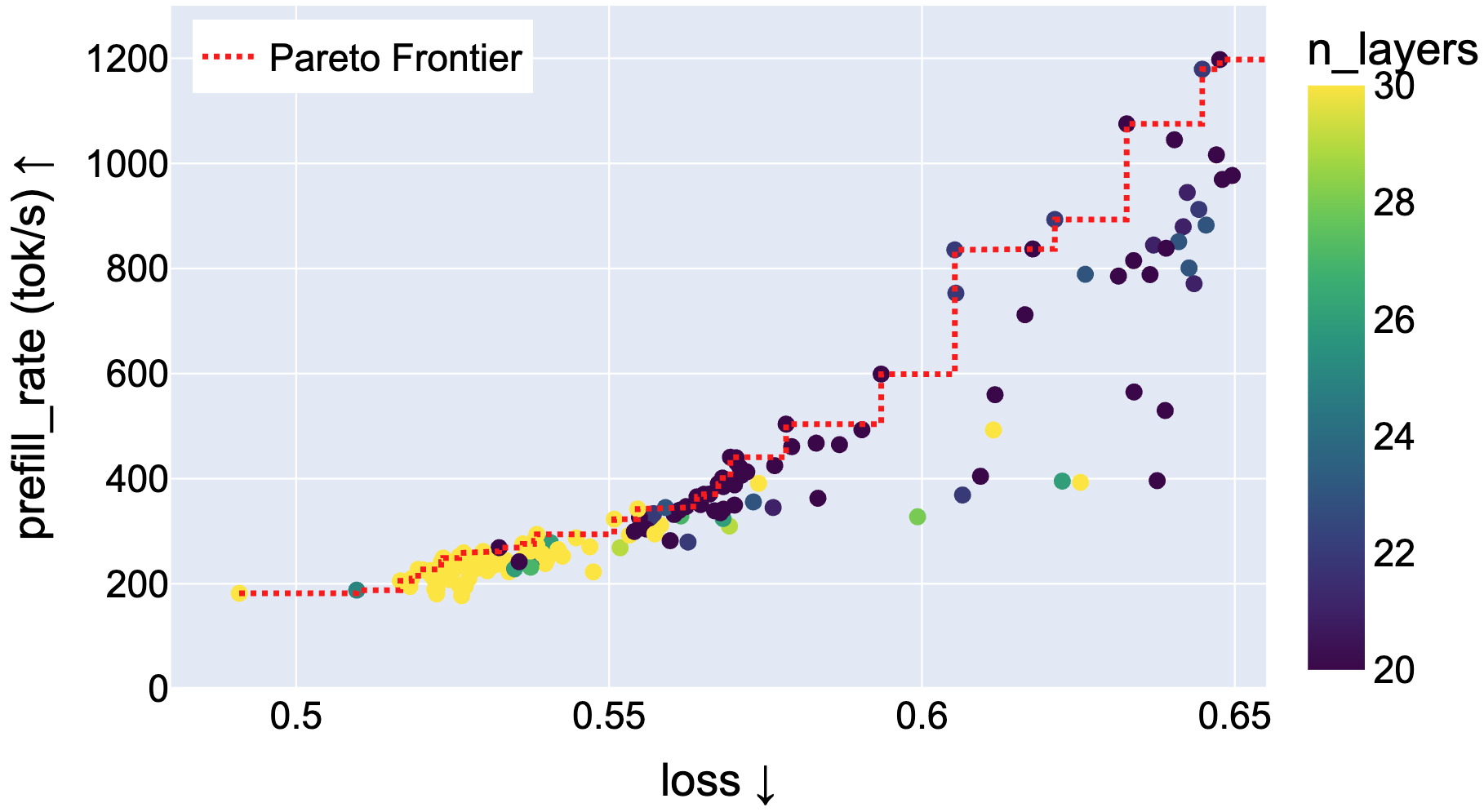
Figure 6: Different model depths along the Pareto curve indicate that, for fixed latency targets, shallower/wider architectures can deliver superior latency-accuracy tradeoff versus deeper models.
Additional task evaluations—including MMLU, coding, rewriting, and summarization—attest that the instruction-finetuned MobileLLM-Flash models match or surpass comparably sized baselines in downstream quality and robustness.
Analysis of Latency Proxies and Design Principles
The study includes a comprehensive analysis of commonly used efficiency proxies:
- Parameter count and FLOPs demonstrate only moderate correlation with real TTFT and decode latency on mobile devices, underscoring the inadequacy of proxy-guided search (cf. Figures 6–9).
- Hardware-in-the-loop evaluation is mandatory for actionable latency optimization.
- Structured pruning offers data- and compute-efficiency for search-phase optimization.
- For practical mobile deployment, attention pattern selection must be constrained to natively-supported ops; skip attention, judiciously interleaved with global attention, yields superior tradeoffs.
- Shallow/wide architectures are generally preferred once tight latency targets are enforced, contradicting the deep/thin designs prevalent in proxy-optimized LLM distillation.
Implications and Future Directions
MobileLLM-Flash’s methodology carries several practical and theoretical implications:
- It establishes a scalable pipeline for designing edge-deployable LLMs compatible with standard runtimes (i.e., no reliance on custom CUDA/DSP/GPU kernels).
- The hardware-in-the-loop Pareto-frontier approach enables direct navigation of real-world tradeoffs, rather than relying on misleading proxies—critical for time-sensitive and resource-constrained applications (e.g., industry-grade mobile AI assistants, wearables).
- The demonstrated efficacy of CPT plus structured pruning motivates further reduction in tuning compute budgets.
- Current limitations include restriction to supported attention variants; future progress may hinge on maturing runtime support for sub-quadratic/SSM-based modules and dynamic expansion of the architectural search space.
- The approach contributes to "Green AI" objectives by reducing both search-and-deploy energy costs.
Conclusion
MobileLLM-Flash exemplifies a principled latency-guided design paradigm for OD-LLMs, leveraging practical constraints and real-device evaluation to inform architectural choices. The resulting models deliver superior speed and comparable or better quality on flagship mobile devices relative to all contemporary alternatives. The framework outlined by this work offers a replicable path for efficient edge LLM development and sets the stage for future progress as mobile inference runtimes evolve and new efficient operations become compatible with on-device AI deployment at scale.